






vllm启动qwen32b的模型:
配置yml参数:
root@node37:/disk1/models/TeleChat2-7B# cd /disk1/Qwen2.5-32B-Instruct-GPTQ-Int4/
root@node37:/disk1/Qwen2.5-32B-Instruct-GPTQ-Int4# cat docker-compose.yml
version: '3.3'
services:
# vllm
vllm-openai:
image: vllm/vllm-openai:v0.6.6.post1
container_name: vllm-openai
restart: always
runtime: nvidia
ports:
- 8001:8000
volumes:
- /disk1/:/models
command: >
--model /models/Qwen2.5-32B-Instruct-GPTQ-Int4
--tokenizer_mode="auto"
--dtype=bfloat16
--tensor_parallel_size=2
--gpu-memory-utilization=1
--max-model-len=2048
--served-model-name=Qwen2.5-32B-Instruct-GPTQ-Int4
deploy:
resources:
reservations:
devices:
- driver: nvidia
capabilities: [gpu]
device_ids: [ "2", "3" ]
ipc: host
networks:
vllm:
root@node37:/disk1/Qwen2.5-32B-Instruct-GPTQ-Int4# docker ps|grep llm
root@node37:/disk1/Qwen2.5-32B-Instruct-GPTQ-Int4#
启动容器:
root@node37:/disk1/Qwen2.5-32B-Instruct-GPTQ-Int4# docker compose -f docker-compose.yml up -d
[+] Running 2/2
? Network qwen25-32b-instruct-gptq-int4_default Created 0.1s
? Container vllm-openai Started 1.0s
检查日志:
root@node37:/disk1/Qwen2.5-32B-Instruct-GPTQ-Int4# docker ps|grep llm
54e73d38d80d vllm/vllm-openai:v0.6.6.post1 "python3 -m vllm.ent…" 9 seconds ago Up 7 seconds 0.0.0.0:8001->8000/tcp, :::8001->8000/tcp vllm-openai
root@node37:/disk1/Qwen2.5-32B-Instruct-GPTQ-Int4# docker logs -f 54e7
INFO 01-08 17:37:10 api_server.py:712] vLLM API server version 0.6.6.post1
INFO 01-08 17:37:10 api_server.py:713] args: Namespace(host=None, port=8000, uvicorn_log_level='info', allow_credentials=False, allowed_origins=['*'], allowed_methods=['*'], allowed_headers=['*'], api_key=None, lora_modules=None, prompt_adapters=None, chat_template=None, chat_template_content_format='auto', response_role='assistant', ssl_keyfile=None, ssl_certfile=None, ssl_ca_certs=None, ssl_cert_reqs=0, root_path=None, middleware=[], return_tokens_as_token_ids=False, disable_frontend_multiprocessing=False, enable_request_id_headers=False, enable_auto_tool_choice=False, tool_call_parser=None, tool_parser_plugin='', model='/models/Qwen2.5-32B-Instruct-GPTQ-Int4', task='auto', tokenizer=None, skip_tokenizer_init=False, revision=None, code_revision=None, tokenizer_revision=None, tokenizer_mode='auto', trust_remote_code=False, allowed_local_media_path=None, download_dir=None, load_format='auto', config_format=<ConfigFormat.AUTO: 'auto'>, dtype='bfloat16', kv_cache_dtype='auto', quantization_param_path=None, max_model_len=2048, guided_decoding_backend='xgrammar', logits_processor_pattern=None, distributed_executor_backend=None, worker_use_ray=False, pipeline_parallel_size=1, tensor_parallel_size=2, max_parallel_loading_workers=None, ray_workers_use_nsight=False, block_size=None, enable_prefix_caching=None, disable_sliding_window=False, use_v2_block_manager=True, num_lookahead_slots=0, seed=0, swap_space=4, cpu_offload_gb=0, gpu_memory_utilization=1.0, num_gpu_blocks_override=None, max_num_batched_tokens=None, max_num_seqs=None, max_logprobs=20, disable_log_stats=False, quantization=None, rope_scaling=None, rope_theta=None, hf_overrides=None, enforce_eager=False, max_seq_len_to_capture=8192, disable_custom_all_reduce=False, tokenizer_pool_size=0, tokenizer_pool_type='ray', tokenizer_pool_extra_config=None, limit_mm_per_prompt=None, mm_processor_kwargs=None, disable_mm_preprocessor_cache=False, enable_lora=False, enable_lora_bias=False, max_loras=1, max_lora_rank=16, lora_extra_vocab_size=256, lora_dtype='auto', long_lora_scaling_factors=None, max_cpu_loras=None, fully_sharded_loras=False, enable_prompt_adapter=False, max_prompt_adapters=1, max_prompt_adapter_token=0, device='auto', num_scheduler_steps=1, multi_step_stream_outputs=True, scheduler_delay_factor=0.0, enable_chunked_prefill=None, speculative_model=None, speculative_model_quantization=None, num_speculative_tokens=None, speculative_disable_mqa_scorer=False, speculative_draft_tensor_parallel_size=None, speculative_max_model_len=None, speculative_disable_by_batch_size=None, ngram_prompt_lookup_max=None, ngram_prompt_lookup_min=None, spec_decoding_acceptance_method='rejection_sampler', typical_acceptance_sampler_posterior_threshold=None, typical_acceptance_sampler_posterior_alpha=None, disable_logprobs_during_spec_decoding=None, model_loader_extra_config=None, ignore_patterns=[], preemption_mode=None, served_model_name=['Qwen2.5-32B-Instruct-GPTQ-Int4'], qlora_adapter_name_or_path=None, otlp_traces_endpoint=None, collect_detailed_traces=None, disable_async_output_proc=False, scheduling_policy='fcfs', override_neuron_config=None, override_pooler_config=None, compilation_config=None, kv_transfer_config=None, worker_cls='auto', generation_config=None, disable_log_requests=False, max_log_len=None, disable_fastapi_docs=False, enable_prompt_tokens_details=False)
INFO 01-08 17:37:10 api_server.py:199] Started engine process with PID 45
WARNING 01-08 17:37:10 config.py:2276] Casting torch.float16 to torch.bfloat16.
WARNING 01-08 17:37:17 config.py:2276] Casting torch.float16 to torch.bfloat16.
INFO 01-08 17:37:19 config.py:510] This model supports multiple tasks: {'score', 'reward', 'embed', 'classify', 'generate'}. Defaulting to 'generate'.
INFO 01-08 17:37:20 gptq_marlin.py:109] The model is convertible to gptq_marlin during runtime. Using gptq_marlin kernel.
INFO 01-08 17:37:20 config.py:1310] Defaulting to use mp for distributed inference
INFO 01-08 17:37:26 config.py:510] This model supports multiple tasks: {'generate', 'reward', 'classify', 'score', 'embed'}. Defaulting to 'generate'.
INFO 01-08 17:37:27 gptq_marlin.py:109] The model is convertible to gptq_marlin during runtime. Using gptq_marlin kernel.
INFO 01-08 17:37:27 config.py:1310] Defaulting to use mp for distributed inference
INFO 01-08 17:37:27 llm_engine.py:234] Initializing an LLM engine (v0.6.6.post1) with config: model='/models/Qwen2.5-32B-Instruct-GPTQ-Int4', speculative_config=None, tokenizer='/models/Qwen2.5-32B-Instruct-GPTQ-Int4', skip_tokenizer_init=False, tokenizer_mode=auto, revision=None, override_neuron_config=None, tokenizer_revision=None, trust_remote_code=False, dtype=torch.bfloat16, max_seq_len=2048, download_dir=None, load_format=LoadFormat.AUTO, tensor_parallel_size=2, pipeline_parallel_size=1, disable_custom_all_reduce=False, quantization=gptq_marlin, enforce_eager=False, kv_cache_dtype=auto, quantization_param_path=None, device_config=cuda, decoding_config=DecodingConfig(guided_decoding_backend='xgrammar'), observability_config=ObservabilityConfig(otlp_traces_endpoint=None, collect_model_forward_time=False, collect_model_execute_time=False), seed=0, served_model_name=Qwen2.5-32B-Instruct-GPTQ-Int4, num_scheduler_steps=1, multi_step_stream_outputs=True, enable_prefix_caching=False, chunked_prefill_enabled=False, use_async_output_proc=True, disable_mm_preprocessor_cache=False, mm_processor_kwargs=None, pooler_config=None, compilation_config={"splitting_ops":["vllm.unified_attention","vllm.unified_attention_with_output"],"candidate_compile_sizes":[],"compile_sizes":[],"capture_sizes":[256,248,240,232,224,216,208,200,192,184,176,168,160,152,144,136,128,120,112,104,96,88,80,72,64,56,48,40,32,24,16,8,4,2,1],"max_capture_size":256}, use_cached_outputs=True,
WARNING 01-08 17:37:28 multiproc_worker_utils.py:312] Reducing Torch parallelism from 16 threads to 1 to avoid unnecessary CPU contention. Set OMP_NUM_THREADS in the external environment to tune this value as needed.
INFO 01-08 17:37:28 custom_cache_manager.py:17] Setting Triton cache manager to: vllm.triton_utils.custom_cache_manager:CustomCacheManager
INFO 01-08 17:37:28 selector.py:120] Using Flash Attention backend.
(VllmWorkerProcess pid=190) INFO 01-08 17:37:28 selector.py:120] Using Flash Attention backend.
(VllmWorkerProcess pid=190) INFO 01-08 17:37:28 multiproc_worker_utils.py:222] Worker ready; awaiting tasks
(VllmWorkerProcess pid=190) INFO 01-08 17:37:29 utils.py:918] Found nccl from library libnccl.so.2
INFO 01-08 17:37:29 utils.py:918] Found nccl from library libnccl.so.2
INFO 01-08 17:37:29 pynccl.py:69] vLLM is using nccl==2.21.5
(VllmWorkerProcess pid=190) INFO 01-08 17:37:29 pynccl.py:69] vLLM is using nccl==2.21.5
INFO 01-08 17:37:29 custom_all_reduce_utils.py:204] generating GPU P2P access cache in /root/.cache/vllm/gpu_p2p_access_cache_for_0,1.json
INFO 01-08 17:37:47 custom_all_reduce_utils.py:242] reading GPU P2P access cache from /root/.cache/vllm/gpu_p2p_access_cache_for_0,1.json
(VllmWorkerProcess pid=190) INFO 01-08 17:37:47 custom_all_reduce_utils.py:242] reading GPU P2P access cache from /root/.cache/vllm/gpu_p2p_access_cache_for_0,1.json
INFO 01-08 17:37:48 shm_broadcast.py:255] vLLM message queue communication handle: Handle(connect_ip='127.0.0.1', local_reader_ranks=[1], buffer_handle=(1, 4194304, 6, 'psm_9da468d9'), local_subscribe_port=40403, remote_subscribe_port=None)
INFO 01-08 17:37:48 model_runner.py:1094] Starting to load model /models/Qwen2.5-32B-Instruct-GPTQ-Int4...
(VllmWorkerProcess pid=190) INFO 01-08 17:37:48 model_runner.py:1094] Starting to load model /models/Qwen2.5-32B-Instruct-GPTQ-Int4...
INFO 01-08 17:37:48 gptq_marlin.py:200] Using MarlinLinearKernel for GPTQMarlinLinearMethod
(VllmWorkerProcess pid=190) INFO 01-08 17:37:48 gptq_marlin.py:200] Using MarlinLinearKernel for GPTQMarlinLinearMethod
Loading safetensors checkpoint shards: 0% Completed | 0/5 [00:00<?, ?it/s]
Loading safetensors checkpoint shards: 20% Completed | 1/5 [00:03<00:14, 3.52s/it]
Loading safetensors checkpoint shards: 40% Completed | 2/5 [00:06<00:08, 2.91s/it]
Loading safetensors checkpoint shards: 60% Completed | 3/5 [00:12<00:09, 4.65s/it]
Loading safetensors checkpoint shards: 80% Completed | 4/5 [00:14<00:03, 3.52s/it]
Loading safetensors checkpoint shards: 100% Completed | 5/5 [00:16<00:00, 2.88s/it]
Loading safetensors checkpoint shards: 100% Completed | 5/5 [00:16<00:00, 3.25s/it]
INFO 01-08 17:38:05 model_runner.py:1099] Loading model weights took 9.0394 GB
(VllmWorkerProcess pid=190) INFO 01-08 17:38:05 model_runner.py:1099] Loading model weights took 9.0394 GB
(VllmWorkerProcess pid=190) INFO 01-08 17:38:11 worker.py:241] Memory profiling takes 5.87 seconds
(VllmWorkerProcess pid=190) INFO 01-08 17:38:11 worker.py:241] the current vLLM instance can use total_gpu_memory (44.31GiB) x gpu_memory_utilization (1.00) = 44.31GiB
(VllmWorkerProcess pid=190) INFO 01-08 17:38:11 worker.py:241] model weights take 9.04GiB; non_torch_memory takes 0.48GiB; PyTorch activation peak memory takes 0.31GiB; the rest of the memory reserved for KV Cache is 34.48GiB.
INFO 01-08 17:38:11 worker.py:241] Memory profiling takes 6.01 seconds
INFO 01-08 17:38:11 worker.py:241] the current vLLM instance can use total_gpu_memory (44.31GiB) x gpu_memory_utilization (1.00) = 44.31GiB
INFO 01-08 17:38:11 worker.py:241] model weights take 9.04GiB; non_torch_memory takes 0.48GiB; PyTorch activation peak memory takes 1.41GiB; the rest of the memory reserved for KV Cache is 33.38GiB.
INFO 01-08 17:38:11 distributed_gpu_executor.py:57] # GPU blocks: 17092, # CPU blocks: 2048
INFO 01-08 17:38:11 distributed_gpu_executor.py:61] Maximum concurrency for 2048 tokens per request: 133.53x
(VllmWorkerProcess pid=190) INFO 01-08 17:38:15 model_runner.py:1415] Capturing cudagraphs for decoding. This may lead to unexpected consequences if the model is not static. To run the model in eager mode, set 'enforce_eager=True' or use '--enforce-eager' in the CLI. If out-of-memory error occurs during cudagraph capture, consider decreasing `gpu_memory_utilization` or switching to eager mode. You can also reduce the `max_num_seqs` as needed to decrease memory usage.
INFO 01-08 17:38:16 model_runner.py:1415] Capturing cudagraphs for decoding. This may lead to unexpected consequences if the model is not static. To run the model in eager mode, set 'enforce_eager=True' or use '--enforce-eager' in the CLI. If out-of-memory error occurs during cudagraph capture, consider decreasing `gpu_memory_utilization` or switching to eager mode. You can also reduce the `max_num_seqs` as needed to decrease memory usage.
(VllmWorkerProcess pid=190) INFO 01-08 17:38:47 custom_all_reduce.py:224] Registering 4515 cuda graph addresses
Capturing CUDA graph shapes: 100%|██████████| 35/35 [00:36<00:00, 1.03s/it]
INFO 01-08 17:38:52 custom_all_reduce.py:224] Registering 4515 cuda graph addresses
INFO 01-08 17:38:52 model_runner.py:1535] Graph capturing finished in 36 secs, took 0.39 GiB
(VllmWorkerProcess pid=190) INFO 01-08 17:38:52 model_runner.py:1535] Graph capturing finished in 37 secs, took 0.39 GiB
INFO 01-08 17:38:52 llm_engine.py:431] init engine (profile, create kv cache, warmup model) took 47.38 seconds
INFO 01-08 17:38:53 api_server.py:640] Using supplied chat template:
INFO 01-08 17:38:53 api_server.py:640] None
INFO 01-08 17:38:53 launcher.py:19] Available routes are:
INFO 01-08 17:38:53 launcher.py:27] Route: /openapi.json, Methods: GET, HEAD
INFO 01-08 17:38:53 launcher.py:27] Route: /docs, Methods: GET, HEAD
INFO 01-08 17:38:53 launcher.py:27] Route: /docs/oauth2-redirect, Methods: GET, HEAD
INFO 01-08 17:38:53 launcher.py:27] Route: /redoc, Methods: GET, HEAD
INFO 01-08 17:38:53 launcher.py:27] Route: /health, Methods: GET
INFO 01-08 17:38:53 launcher.py:27] Route: /tokenize, Methods: POST
INFO 01-08 17:38:53 launcher.py:27] Route: /detokenize, Methods: POST
INFO 01-08 17:38:53 launcher.py:27] Route: /v1/models, Methods: GET
INFO 01-08 17:38:53 launcher.py:27] Route: /version, Methods: GET
INFO 01-08 17:38:53 launcher.py:27] Route: /v1/chat/completions, Methods: POST
INFO 01-08 17:38:53 launcher.py:27] Route: /v1/completions, Methods: POST
INFO 01-08 17:38:53 launcher.py:27] Route: /v1/embeddings, Methods: POST
INFO 01-08 17:38:53 launcher.py:27] Route: /pooling, Methods: POST
INFO 01-08 17:38:53 launcher.py:27] Route: /score, Methods: POST
INFO 01-08 17:38:53 launcher.py:27] Route: /v1/score, Methods: POST
INFO: Started server process [1]
INFO: Waiting for application startup.
INFO: Application startup complete.
INFO: Uvicorn running on http://0.0.0.0:8000 (Press CTRL+C to quit)
新开窗口观察显存占用:
root@node37:~# nvidia-smi
Thu Jan 9 09:39:23 2025
+-----------------------------------------------------------------------------------------+
| NVIDIA-SMI 550.54.15 Driver Version: 550.54.15 CUDA Version: 12.4 |
|-----------------------------------------+------------------------+----------------------+
| GPU Name Persistence-M | Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap | Memory-Usage | GPU-Util Compute M. |
| | | MIG M. |
|=========================================+========================+======================|
| 0 NVIDIA L40 Off | 00000000:02:00.0 Off | 0 |
| N/A 46C P0 82W / 300W | 39502MiB / 46068MiB | 0% Default |
| | | N/A |
+-----------------------------------------+------------------------+----------------------+
| 1 NVIDIA L40 Off | 00000000:03:00.0 Off | 0 |
| N/A 48C P0 83W / 300W | 38943MiB / 46068MiB | 0% Default |
| | | N/A |
+-----------------------------------------+------------------------+----------------------+
| 2 NVIDIA L40 Off | 00000000:82:00.0 Off | 0 |
| N/A 45C P0 79W / 300W | 44909MiB / 46068MiB | 0% Default |
| | | N/A |
+-----------------------------------------+------------------------+----------------------+
| 3 NVIDIA L40 Off | 00000000:83:00.0 Off | 0 |
| N/A 45C P0 81W / 300W | 44909MiB / 46068MiB | 0% Default |
| | | N/A |
+-----------------------------------------+------------------------+----------------------+
+-----------------------------------------------------------------------------------------+
| Processes: |
| GPU GI CI PID Type Process name GPU Memory |
| ID ID Usage |
|=========================================================================================|
| 0 N/A N/A 1570 G /usr/lib/xorg/Xorg 4MiB |
| 0 N/A N/A 12908 C /usr/bin/python3.10 544MiB |
| 0 N/A N/A 164261 C python3 38480MiB |
| 0 N/A N/A 166600 C ray::RayWorkerVllm 424MiB |
| 1 N/A N/A 1570 G /usr/lib/xorg/Xorg 4MiB |
| 1 N/A N/A 164261 C python3 424MiB |
| 1 N/A N/A 166600 C ray::RayWorkerVllm 38470MiB |
| 2 N/A N/A 1570 G /usr/lib/xorg/Xorg 4MiB |
| 2 N/A N/A 657309 C /usr/bin/python3 44880MiB |
| 3 N/A N/A 1570 G /usr/lib/xorg/Xorg 4MiB |
| 3 N/A N/A 657508 C /usr/bin/python3 44880MiB |
+-----------------------------------------------------------------------------------------+
root@node37:/disk1/Qwen2.5-32B-Instruct-GPTQ-Int4# docker ps|grep llm
54e73d38d80d vllm/vllm-openai:v0.6.6.post1 "python3 -m vllm.ent…" 2 minutes ago Up 2 minutes 0.0.0.0:8001->8000/tcp, :::8001->8000/tcp vllm-openai
root@node37:/disk1/Qwen2.5-32B-Instruct-GPTQ-Int4# netstat -tunlp|grep LISTEN|grep 8001
tcp 0 0 0.0.0.0:8001 0.0.0.0:* LISTEN 657107/docker-proxy
tcp6 0 0 :::8001 :::* LISTEN 657120/docker-proxy
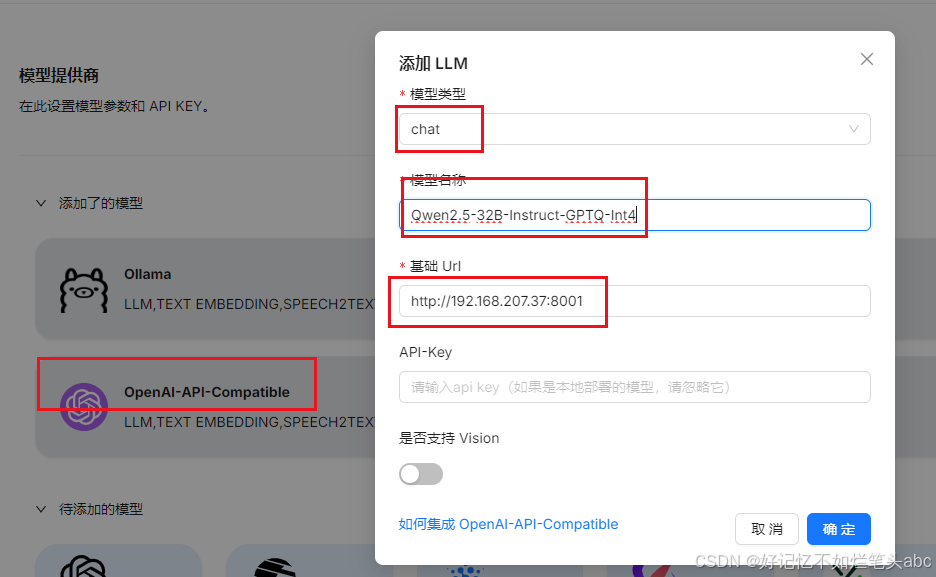
ragflow配置模型参考:

















 9115
9115

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









