




VIT(Vision Transformer)
之前的transformer都是应用于文字,有没有方法应用到图片上。图片不是token
把图片离散化,把四万多像素(224*224)离散成token
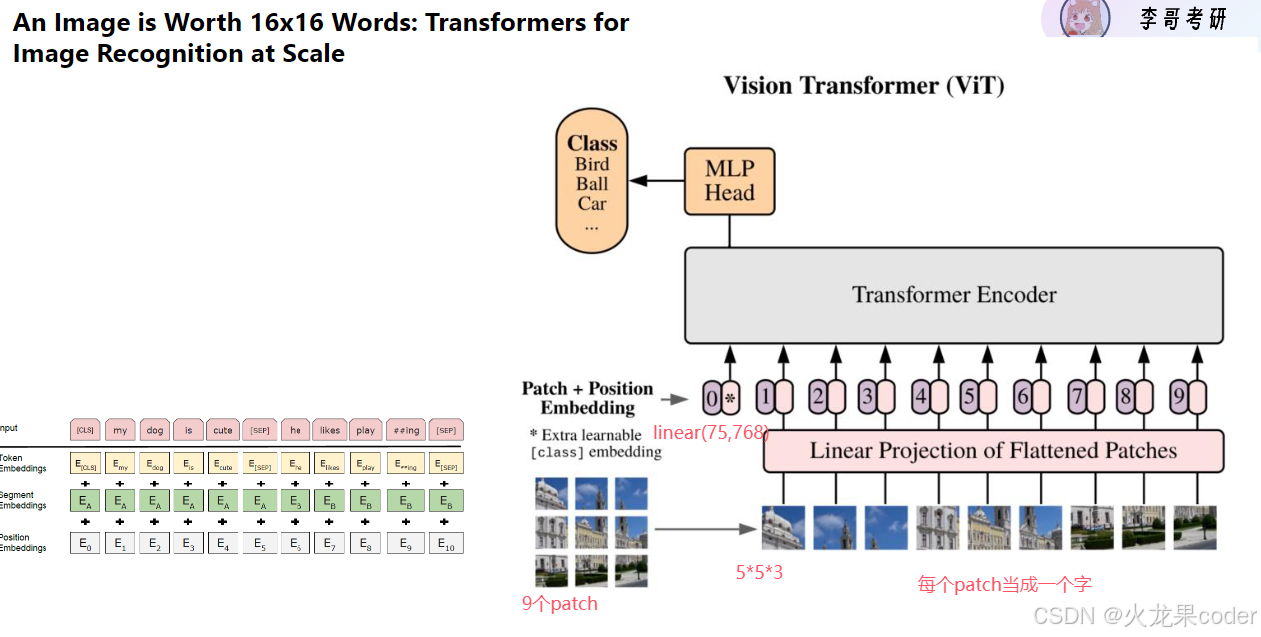
复试的道(领域,知道哪些模型)和术(动手能力)
多模态

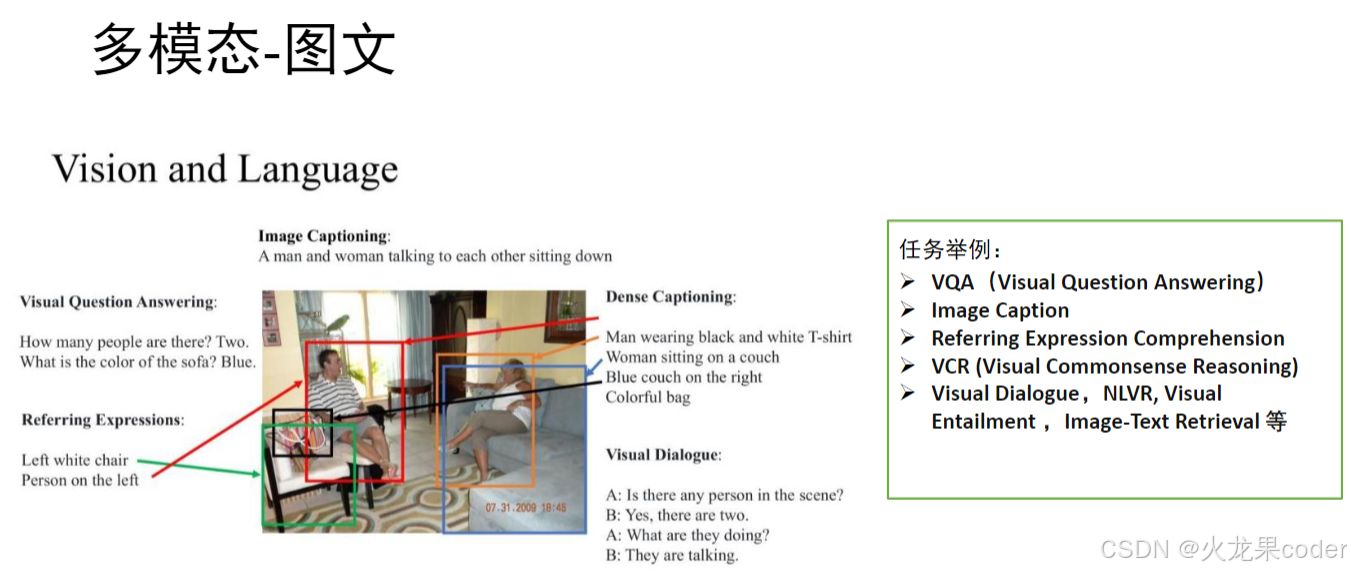
多模态-图文(clip模型)
BERT天然为多模态而生
只要输入维度一样,就可以进行self-attention交互

只要你的输入是一个向量,我不管它原来是什么,我只管让他与其他向量交互。
ViltBERT多模态模型
明明有transformer就可以了,为什么还要有这个
假如选了BERT,预训练都是文字,没有文字参数,把预训练参数拿过来不好用
而这个预训练参数既有图片也有文字
预训练时考虑了很多图片和文字的交互
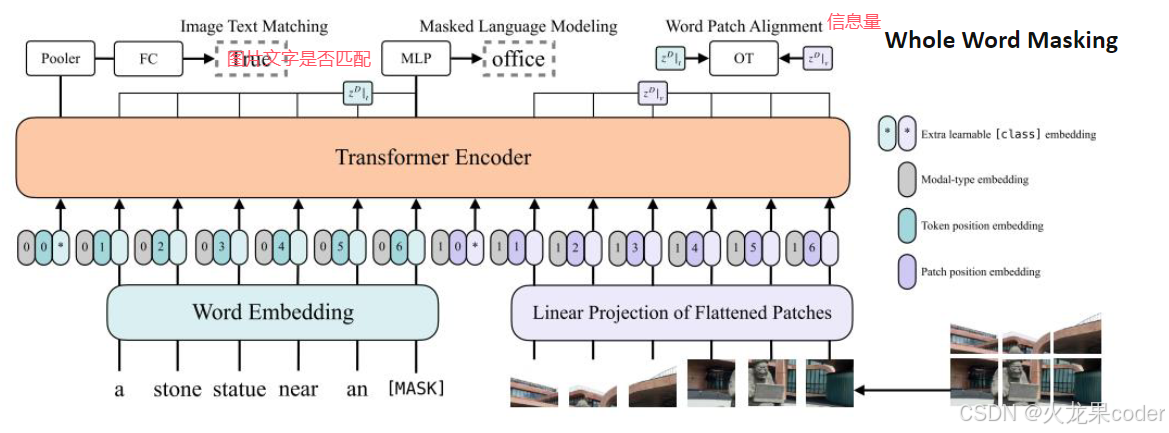

VisualBERT
之前的几个模型平均分成几块,文字和图片间不能一一匹配
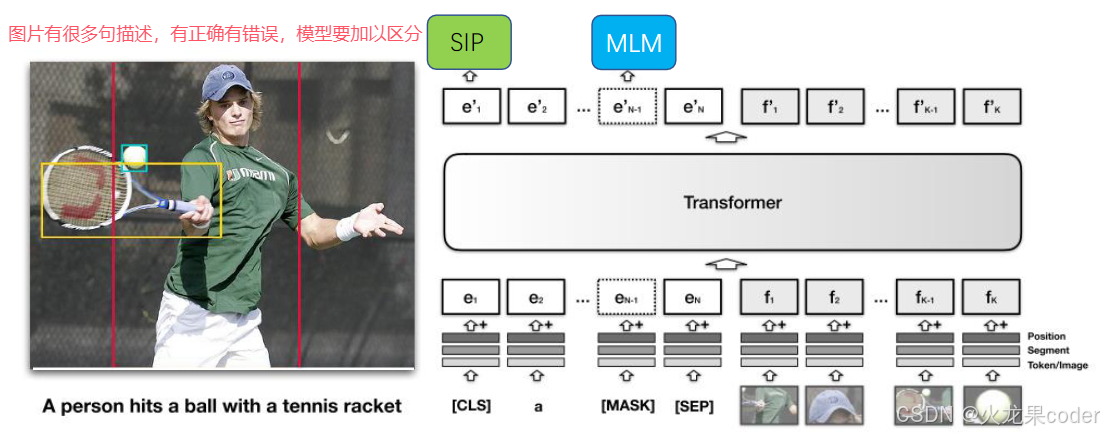
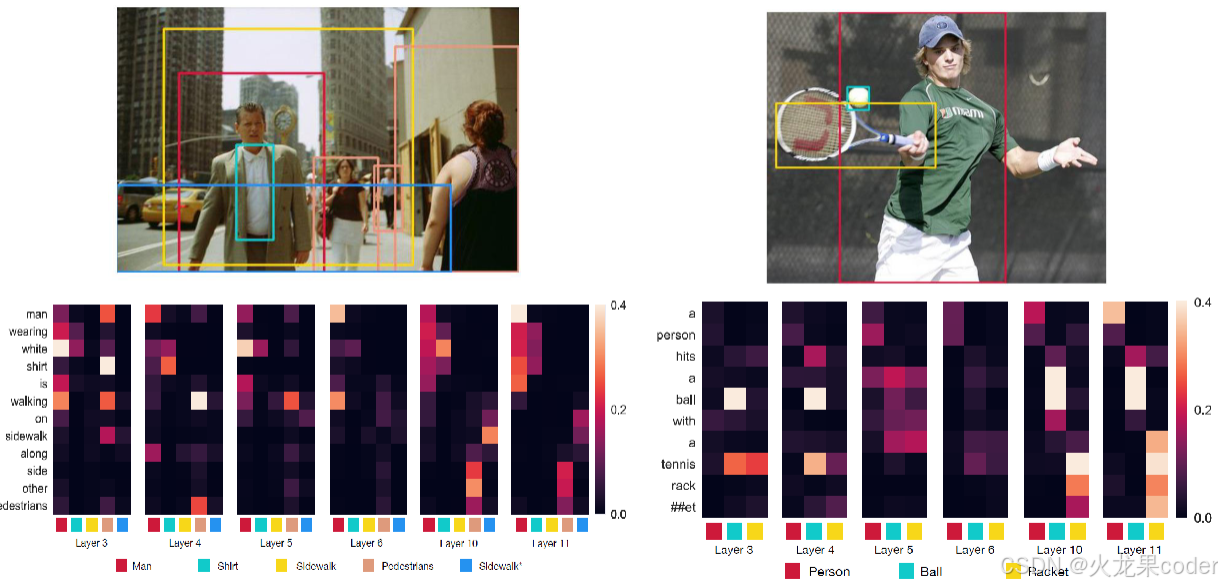
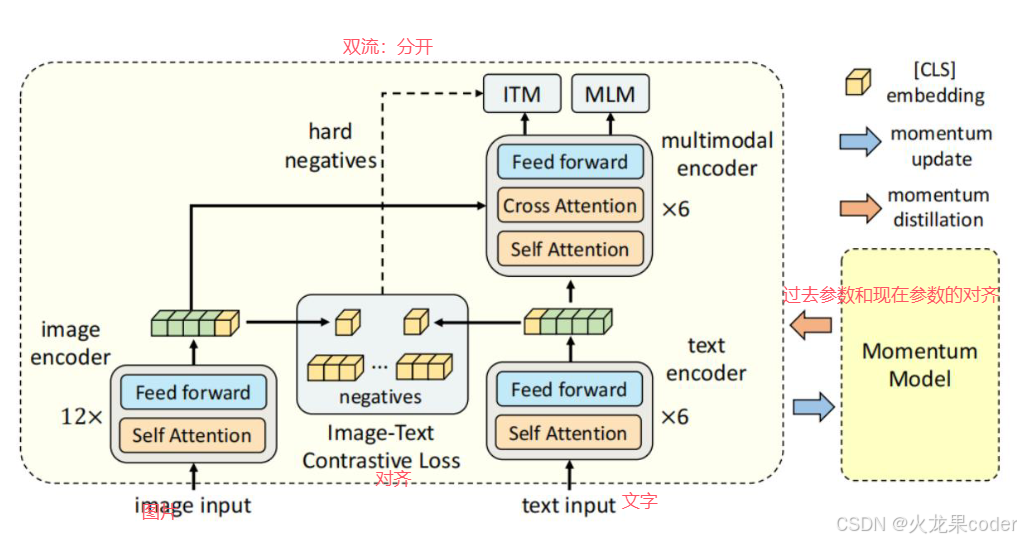
ALBEF
深度学习常见研究方向
文字生成类


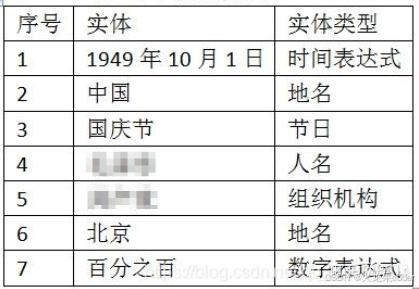
命名实体识别(NER)
判断句子中的某一段是什么类别的
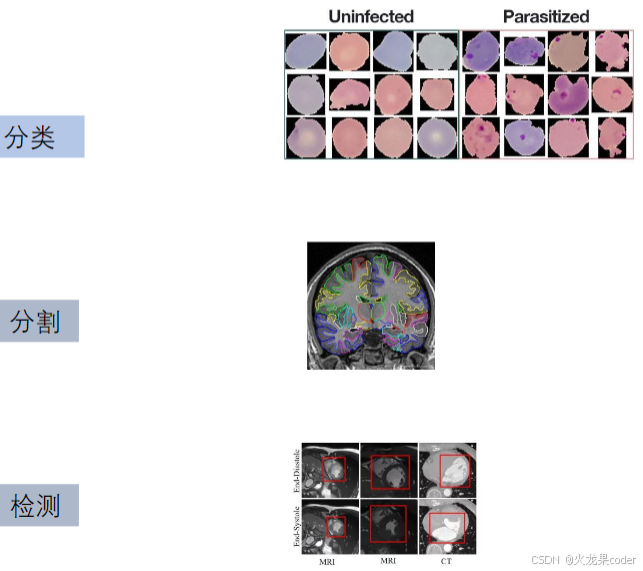
医学图像分类,分割,检测
小样本
训练数据只有二十个,如何达到很好的效果?
方法1:迁移学习。
方法2:数据增广。
等等。
异常检测
银行里交易正常的占百分之99.9,不正常的占百分之0.01。
模型全部推测为正常 loss依然很低
可解释性
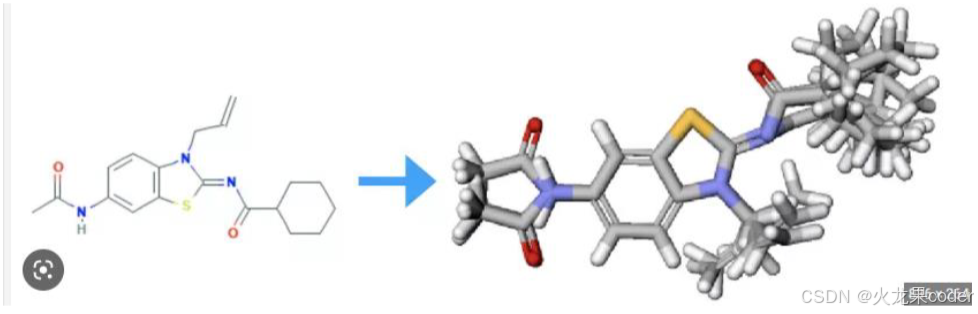
 分子结构预测(NERF)
分子结构预测(NERF)
解微分方程
颅面复原到人脸
还有之前的
普通图片分类
文字情感分类。
半监督,无监督, 自监督。
分布式训练
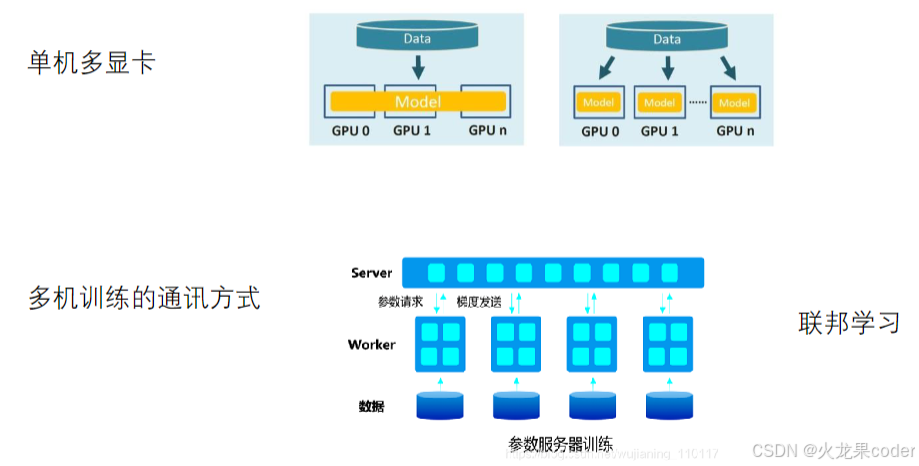
大语言模型:LLM(Large Language Model)
transformer发展过来的。少了交互部分 crossattention部分
大模型是一个自回归的生成模型
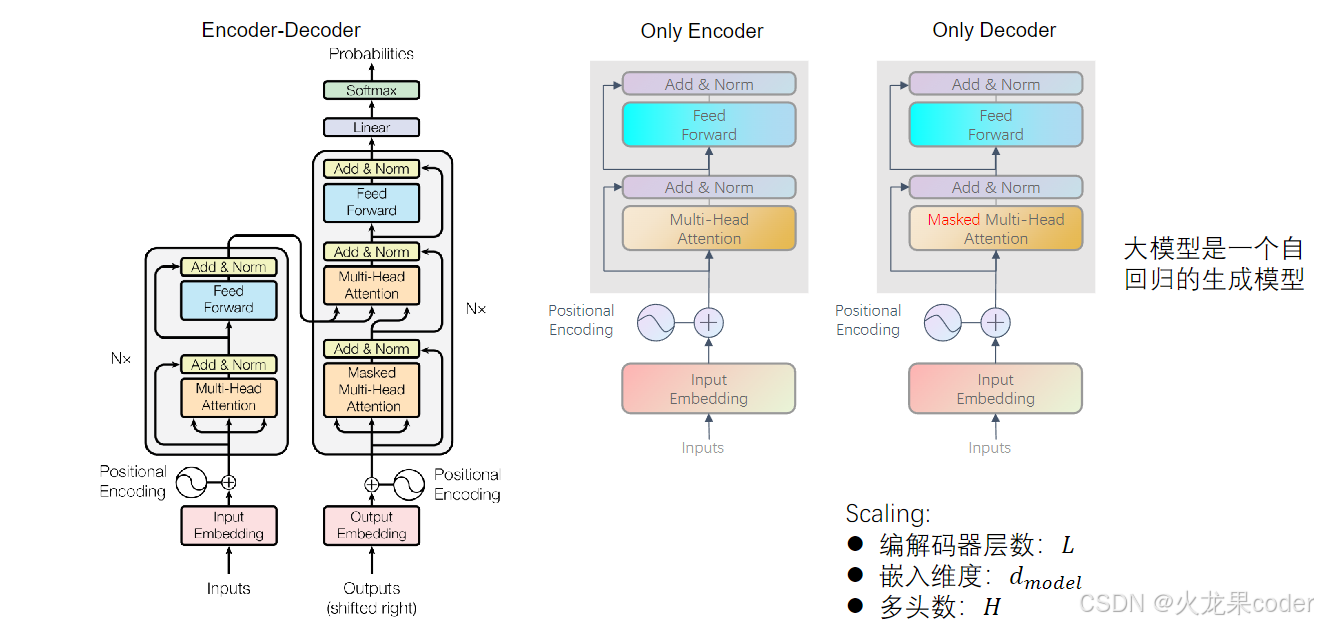
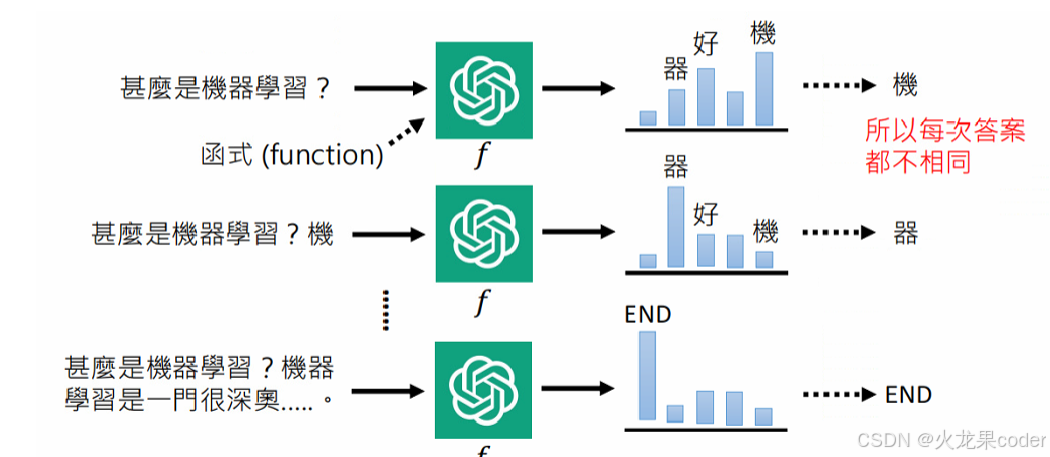
大模型的训练方式
only decoder所以不能进行MLM训练。prompt给大模型的输入

强化学习是最终方向,未来
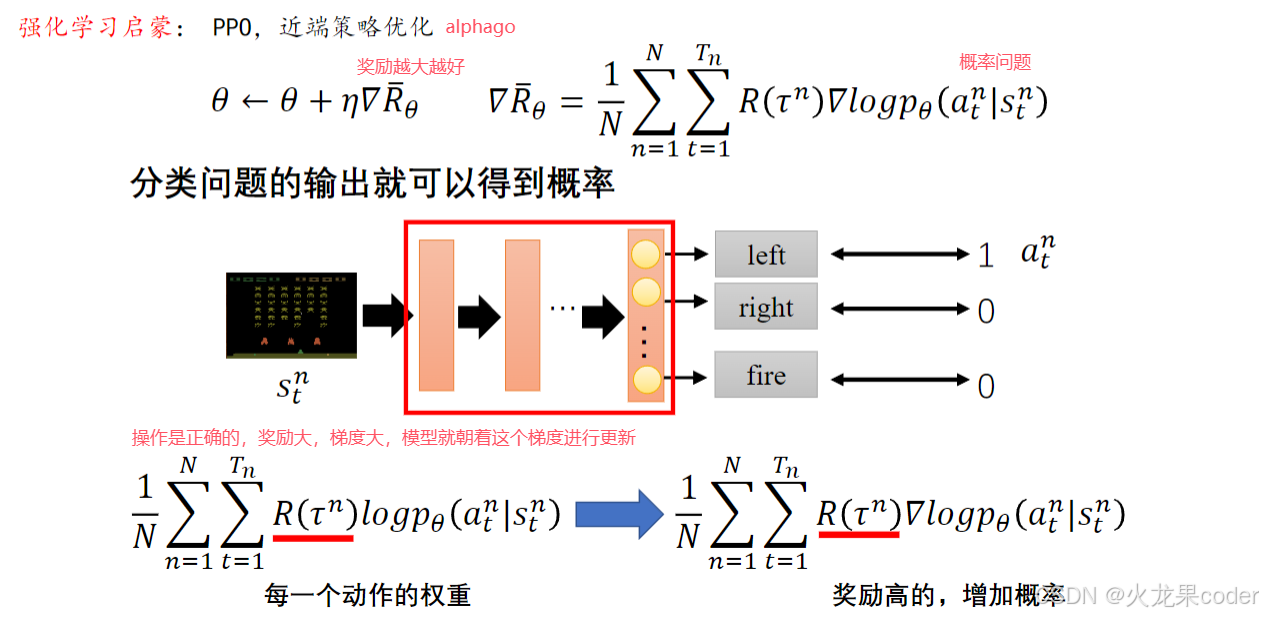
代码中用的细节之处。
- 设计更好的学习率。
- 设计更好的优化器。
- 设计更好的loss。
- 设计更好的模型架构
- 更快的计算方法
- 更少的模型参数
如何把学的内容写到简历之中?
实例1:回归

实例2:分类
-
我在一个分类数据集上, 尝试了不同的模型。 我对不同模型的理解。(resNet为什么这么深,vgg和resnet区别?)
-
我根据不同的数据集, 设计了不同的模型。 我是如何设计的?
-
我对数据做了什么处理? 使用了哪些数据增广方式?为什么mnist数据集不适合用翻转?和其他增广方式对比。
-
翻转 上下翻转6翻过来为9
-
数据增广雨天加雨 雾天加雾
-
-
我是如何处理无标签数据的? 半监督的实现原理。
-
我是如何使用迁移学习方法的。是否迁移的对比。
实例3:自然语言处理
我们使用Bert用法很简单, 但是Bert本身就够复杂。
- 我对自然语言处理很感兴趣, 我将来想做这个方向。所以提前学习了self-attention并且使用Bert处理了情感分类任务。
- 我对自然语言处理模型架构的理解,我尝试了不同的架构。RNN, LSTM的优势和缺陷。 Self-attention 为什么这么流行?SA的架构细节。
- Bert的原理是什么, 为什么Bert能够这么有效? 他是如何训练的? 简述预训练任务。
- 使用BERT进行了什么分类任务,达到了什么效果
- 预训练才有效
- Bert的训练。你使用了什么优化器?你训练了多少epoch?(3-4个很快)
- bert的输出是如何处理的? Bert最后的输出有几种不同的方式?各准确率多少?
- 128*768 -> 768 直接取第一个/取最大/平均
实例4:生成任务
-
Bart是什么模型啊喂?你和谁做了比较选了它?
-
Bart是摘要生成模型,和我们任务比较贴切
-
-
Bart的预训练任务是什么?和bert的区别是什么?
-
医学数据集比赛,一个生成数据集根据CT图像生成医生描述。
-
-
生成任务的原理,细节,如何生成结束?如何输入?测试和训练有什么不同?
-
输入需要masked
-
-
你是如何处理生成任务的输入的?
写两个就可以
其他
- 我对对比学习很感兴趣。 自监督是一个很迷人的方向。所以我XXXX, 自监督和无监督的原理是什么。 你研究了什么?
- 我对多模态很感兴趣, 所以我XXXXX, 几个多模态模型的架构和原理。
- 不同的激活函数有什么不同, 各有什么优缺点? 不同的有优化器有什么不同, 原理, 有什么优缺点?

















 956
956

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









