







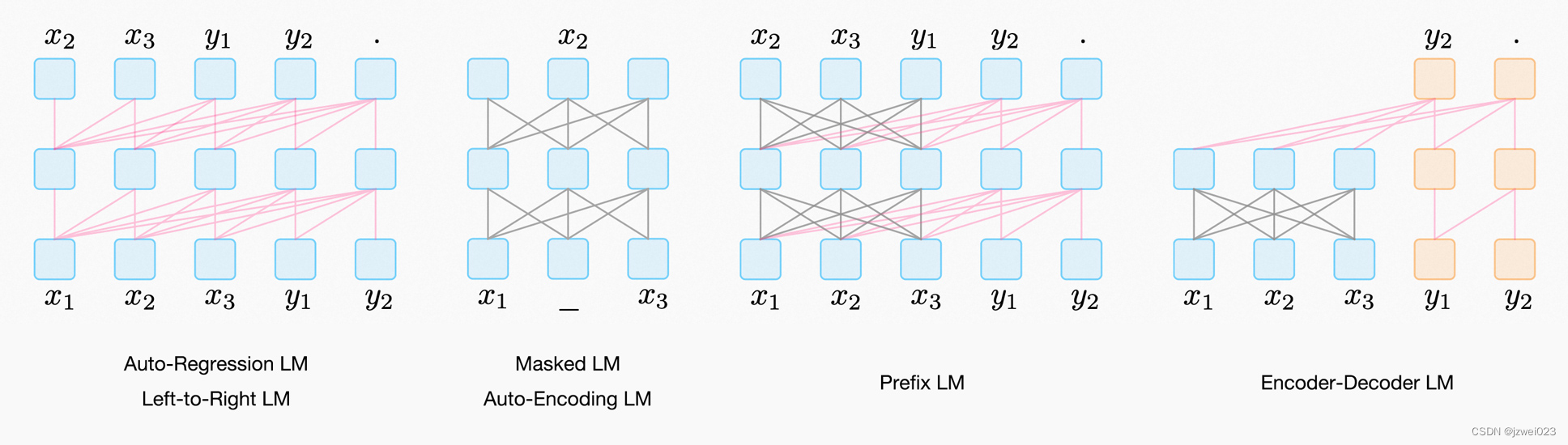
Encoder-AE 结构
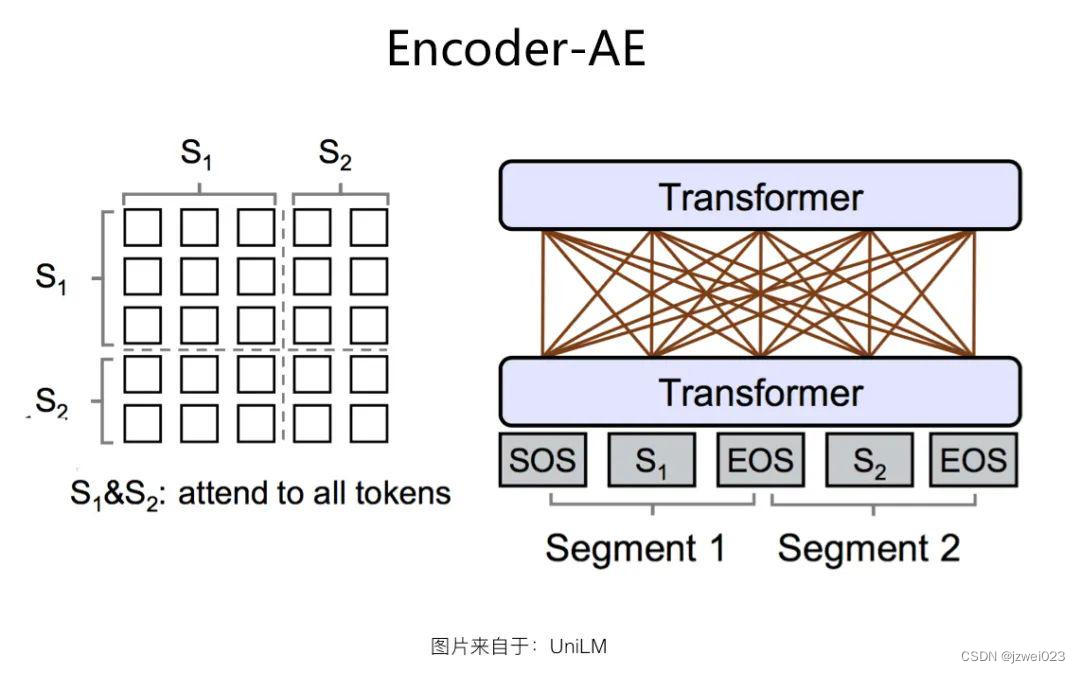
特点:可以同时看到上文和下文
代表:BERT
优点:适合语言理解类的任务
缺点:不适合语言生成类的任务
Encoder-AR 结构

特点:只能看到上文或者下文
代表: GPT1/2/3
优点:适合语言生成类的任务
缺点:不适合语言理解类的任务
Encoder-Decoder 结构
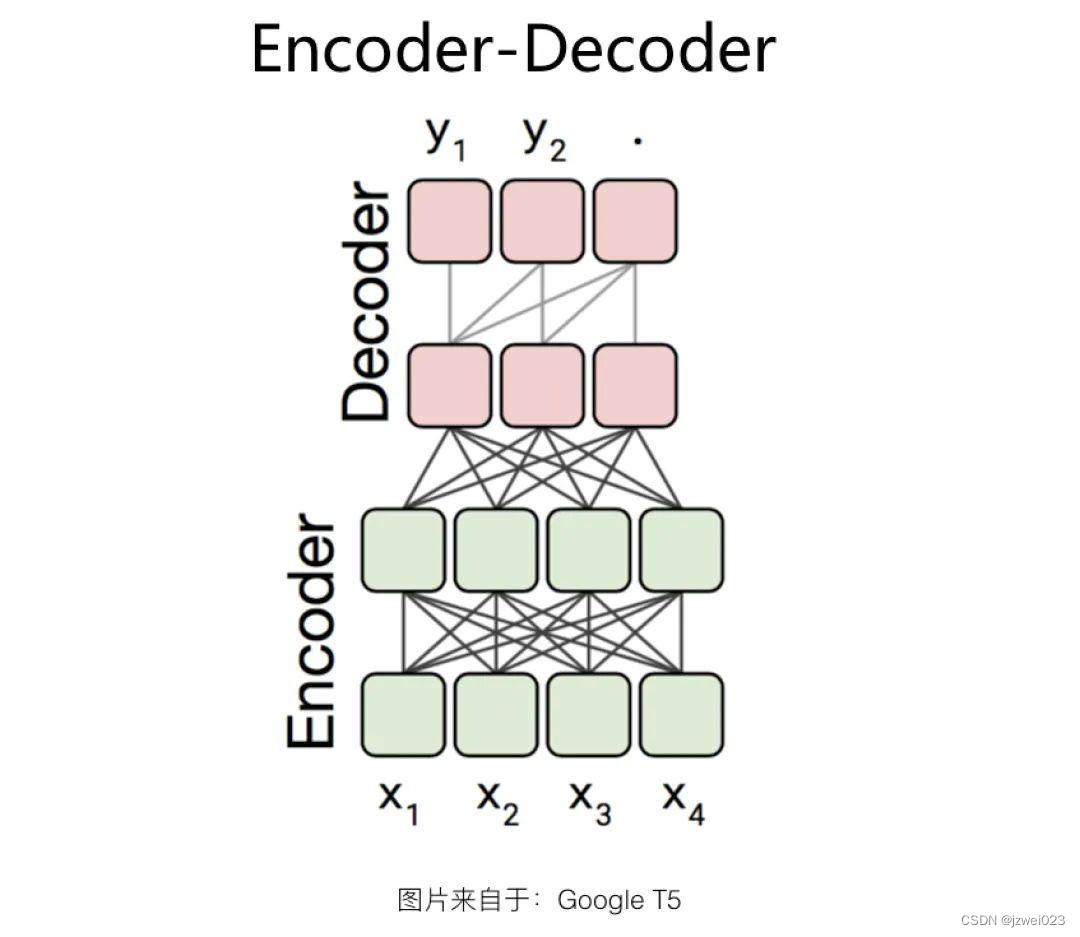
特点:encoder时采用AE模式,decoder时采用AR模式
代表: BART、Google T5
优点:同时适合语言理解类的任务和语言生成类的任务
Prefix LM结构
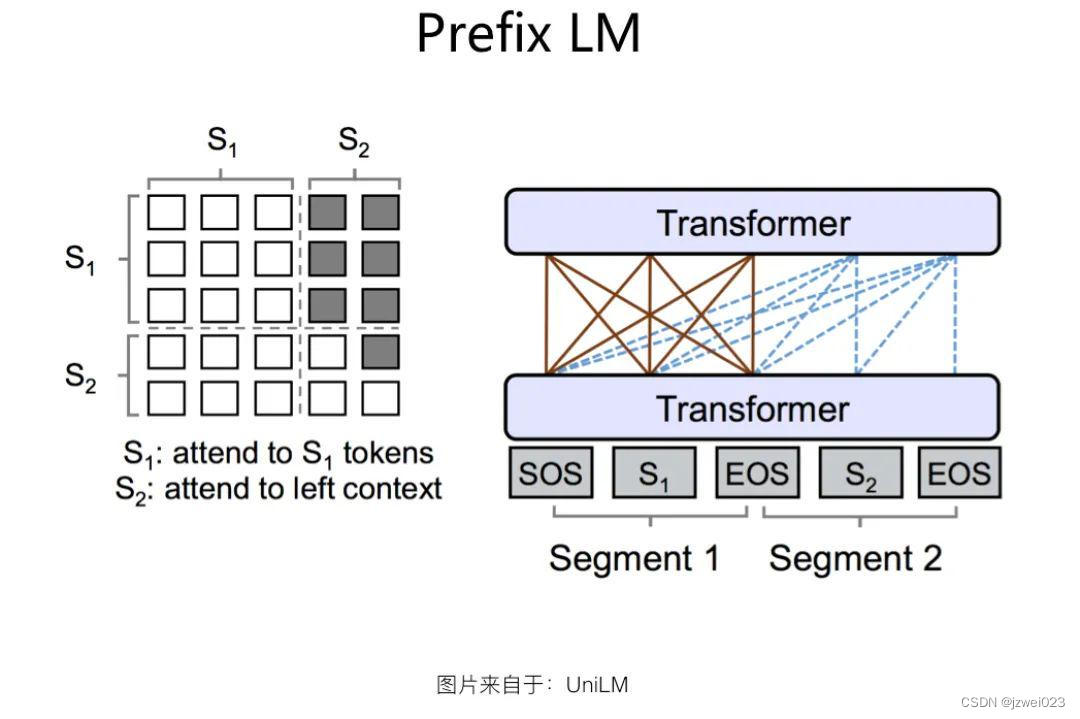
特点:
Prefix LM 结构是 Google T5 论文中给出的叫法,这种结构最早由 UniLM 模型提出,我们沿用 Google T5 的这种称谓。如果深入分析的话,Prefix LM 其实是 Encoder-Decoder 模型的变体:标准的 Encoder-Decoder 模型,Encoder 和 Decoder 各自使用一个独立的 Transformer;而 Prefix LM,相当于 Encoder 和 Decoder 通过分割的方式,分享了同一个 Transformer 结构,Encoder 部分占用左部,Decoder 部分占用右部,这种分割占用是通过在 Transformer 内部使用 Attention Mask 来实现的。与标准 Encoder-Decoder 类似,Prefix LM 在 Encoder 部分采用 AE 模式,就是任意两个单词都相互可见,Decoder 部分采用 AR 模式,即待生成的单词可以见到 Encoder 侧所有单词和 Decoder 侧已经生成的单词,但是不能看未来尚未产生的单词,就是说是从左到右生成。
Prefix LM 因为是 Encoder-Decoder 的变体,所以可以看出,它的优势也在于可以同时进行语言理解和语言生成类任务,而且相对 Encoder-Decoder 来说,因为只用了一个 Transformer,所以模型比较轻,这是 Prefix LM 的优势。缺点则是在效果方面,貌似要弱于 Encoder-Decoder 模型的效果,语言理解类任务相对有明显差距,生成类任务的效果相差不大。
代表: UniLM
Permuted LM结构
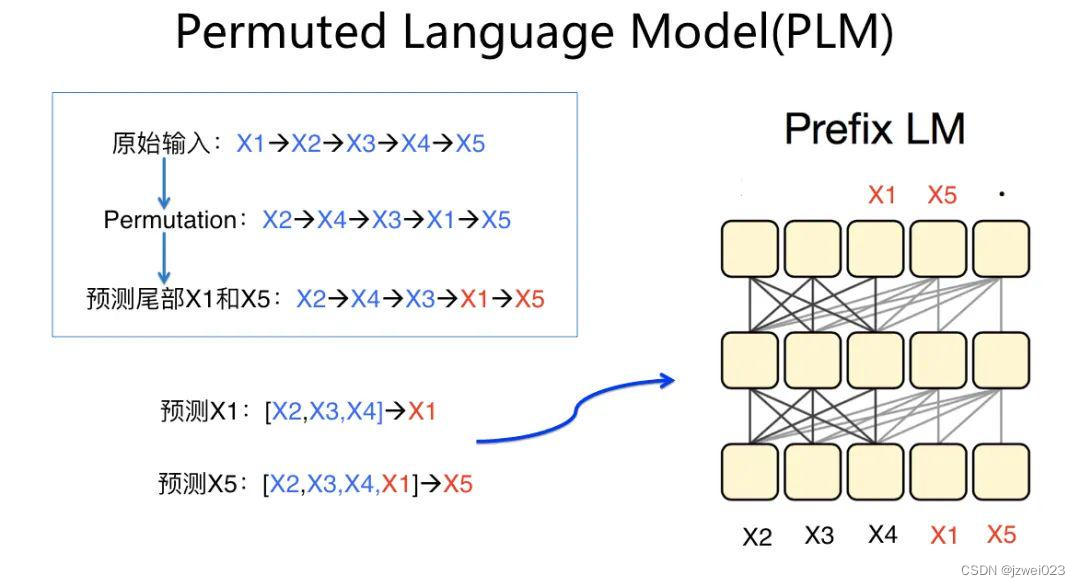
特点:形为 AR,实为 AE(通过Attention Mask处理,本质上是prefix lm的一种变体)
代表: XLNet

















 4482
4482

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









