










- Paper:https://arxiv.org/abs/2312.08914
- Github:https://github.com/THUDM/CogAgent
- Huggingface:https://huggingface.co/THUDM/cogagent-9b-20241220
- ModelScope:https://modelscope.cn/models/ZhipuAI/cogagent-9b-20241220
- Author:Wenyi Hong et al. 智谱,清华大学,CVPR2024(Highlight)
CogAgent核心:
- CogAgent是一个18B的视觉语言模型(VLM),支持GUI界面理解和导航,开源了9B的模型
- 支持1120x1120分辨率的输入,能识别微小的页面元素和文本
- 在5个文本丰富的benchmark和4个通用VQA benchmark上取得了SOTA
1 模型结构

- 高分辨率Image Encoder:EVA2-CLIP-L
- 低分辨率Image Encoder:EVA2-CLIP-E
- 基础VLM:GLM-4V-9B

高分辨率的图像编码参与到visual language decoder的过程中,在每层MSA(Multi-Self-Attention)层之后,再添加一个cross-attn层,原MSA的输出作为q,高分辨率的图像编码作为k-v,参与运算,最后cross-attn的输出维度与原MSA的输出维度保持一致。通过这种方式将高分辨率的信息引入到解码过程中。
1.1 Pre-training
目标:增强模型对高分辨率图片的理解能力,并将这种能力引入到GUI应用界面场景, 主要关注以下几个能力:
-
识别不同尺寸、方向和字体的文本
-
文本和其他目标的grounding能力
-
对于GUI界面(如Web界面)的特殊的理解能力
-
GUI Refering Expression Generation(REG):引用表达生成;根据图片上指定区域,生成HTML代码或者DOM(Document Object Model)元素的能力
-
GUI Refering Expression Comprehension(REC):引用表达理解;对指定的DOM元素生成bounding box的能力
-
所以预训练数据分成三个部分:
| 名称 | Text recognition | Visual grounding | GUI imagery |
|---|---|---|---|
| 数据集 | 1、合成数据(80M):不同字体、大小、颜色、方向的文本和不同背景的图片 2、OCR(18M):COYO,LAION-2B,Paddle-OCR 3、学术文档(9M):arXiv开源的latex文档 | 1、grounding dataset(40M):LAION-115M,image-caption pairs,包含bounding box | 1、CCS400K (Common Crawl Screenshot 400k):使用playwright解析DOM元素,并补充了140M的REG和REC的QA对,并随机resize图片大小 2、text-image datasets:LAION-2B、COYO-700M,清晰有问题的URL、描述和又政治偏见的数据 |
训练细节:
-
训练参数:前20000 steps只训练high-resolution cross-attention模块,再增加CogVLM中的visual expert训练40000 steps
-
batch size:4608
-
learning rate:2e-5
1.1 Multi-task微调与对齐
目标:增强模型处理各种任务的能力,并确保与人类各种格式的指令对齐。
-
手动采集2k:从手机、电脑界面采集2000张屏幕截图,通过人工对每张图用问答的格式进行标注,标注内容包括屏幕元素、潜在的任务、操作方法
-
开源网页、手机屏幕截图数据:Mind2Web、AITW,并使用GPT-4将其转化为自然语言问答的格式
-
开源VQA数据
训练细节:
-
训练参数:全参微调
-
迭代轮数:10k
-
batch size:1024
-
learning rate:2e-5
2 模型输入与输出
2.1 输入
模型输入部分分成4个字段:task、platform、format、history。
2.1.1 Task字段
用户输入的任务描述,类似文本格式的prompt,该输入可以指导 CogAgent 模型完成用户任务指令。
该字段前面必须增加 Task:关键词。例如,用户的任务是打开微信。则该部分提示词是:
Task: 打开微信
2.1.2 Platform字段
CogAgent 支持在多个平台上执行可操作Agent功能, 支持的带有图形界面的操作系统有三个系统:
-
Windows 10,11,使用
WIN字段。 -
Mac 14,15,使用
MAC字段。 -
Android 13,14,15 以及其他GUI和UI操作方式几乎相同的安卓UI发行版,请使用
Mobile字段。
该部分提示词表示为:
(Platform: WIN)
2.1.3 Format字段
返回的数据格式:
-
Answer in Action-Operation-Sensitive format.: 返回模型的行为,对应的操作,以及对应的敏感程度。 -
Answer in Status-Plan-Action-Operation format.: 返回模型的装题,行为,以及相应的操作。 -
Answer in Status-Action-Operation-Sensitive format.: 返回模型的状态,行为,对应的操作,以及对应的敏感程度。 -
Answer in Status-Action-Operation format.: 返回模型的状态,行为。 -
Answer in Action-Operation format.返回模型的行为,对应的操作。
该部分提示词表示为:
(Answer in Status-Plan-Action-Operation-Sensitive format.)
2.1.4 History字段
对于模型的每个回复,仅仅保留模型输出的Action以及Grounded Operation字段信息。
该字段示例:
History steps:
0. TYPE(box=[[102,058,882,087]], text=‘https://www.taobao.com’, element_type=‘文本输入框’, element_info=‘在 Google 中搜索,或输入网址’) 在浏览器顶部的地址和搜索栏中输入淘宝的网址,以便打开淘宝网站。
- CLICK(box=[[626,262,647,310]], element_type=‘图标按钮’, element_info=‘关闭’) 在当前弹窗的右上角找到关闭按钮,左键单击以关闭弹窗,从而可以继续浏览淘宝页面。
- TYPE(box=[[286,273,641,315]], text=‘机械键盘’, element_type=‘文本输入框’, element_info=‘请 输入搜索文字’) 在页面顶部中央的搜索框中输入“机械键盘”作为搜索关键词。
2.1.5 完整输入示例
Task: 用户需要完成的任务
History steps:
0. xxx
1. xxx
(Platform: WIN)
(Answer in Status-Plan-Action-Operation-Sensitive format.)
2.2 输出
CogAgent的输出包含以下4个部分:
-
思考过程(Status & Plan)。
CogAgent-9B-20241220显式输出理解 GUI 截图、决定下一步操作的思考过程。思考过程包含状态(Status)和计划(Plan)两个部分,可以通过参数控制实际的输出内容; -
对下一步动作的自然语言描述(Action)。自然语言形式的动作描述会被加入到历史操作记录中,方便模型理解已经执行的动作步骤;
-
对下一步动作的结构化描述(Grounded Operation)。
CogAgent-9B-20241220以类似于函数调用的形式,结构化地描述下一步操作及其参数。结构化的动作描述方便 CogAgent 端侧应用解析并执行模型的输出。CogAgent-9B-20241220的动作空间包含GUI 操作(基础动作)和拟人行为(高级动作)两类,前者包括左键单击、文本输入等,后者包括应用启动、调用语言模型等。 -
对下一步动作的敏感性判断,包括“一般操作”和“敏感操作”两类。敏感操作是指可能会带来难以挽回后果的动作,例如在“发送邮件”任务中的动作“点击发送按钮”。
2.2.1 完整输出示例
这里展现了不同格式要求下的返回结果:
- Answer in Action-Operation-Sensitive format
Action: 点击页面顶部工具栏中的“全部标为已读”按钮,将所有邮件标记为已读。
Grounded Operation: CLICK(box=[[219,186,311,207]], element_type=‘可点击文本’, element_info=‘全部标为已读’)
<<一般操作>>
- Answer in Status-Plan-Action-Operation format
Status: None
Plan: None.
Action: 点击收件箱页面顶部中间的“全部标记为已读”按钮,将所有邮件标记为已读。
Grounded Operation: CLICK(box=[[219,186,311,207]], element_type=‘可点击文本’, element_info=‘全部标为已读’)
- Answer in Status-Action-Operation-Sensitive format
Status: 当前处于邮箱界面[[0, 2, 998, 905]],左侧是邮箱分类[[1, 216, 144, 570]],中间是收件箱[[144, 216, 998, 903]],已经点击“全部标为已读”按钮[[223, 178, 311, 210]]。
Action: 点击页面顶部工具栏中的“全部标为已读”按钮,将所有邮件标记为已读。
Grounded Operation: CLICK(box=[[219,186,311,207]], element_type=‘可点击文本’, element_info=‘全部标为已读’)
<<一般操作>>
- Answer in Status-Action-Operation format
Status: None
Action: 在收件箱页面顶部,点击“全部标记为已读”按钮,将所有邮件标记为已读。
Grounded Operation: CLICK(box=[[219,186,311,207]], element_type=‘可点击文本’, element_info=‘全部标为已读’)
- Answer in Action-Operation format
Action: 在左侧邮件列表中,右键单击第一封邮件,以打开操作菜单。
Grounded Operation: RIGHT_CLICK(box=[[154,275,343,341]], element_info=‘[AXCell]’)
2.3 CogAgent支持的操作空间
2.3.1 4种鼠标操作
鼠标操作包含:左键单击(CLICK)、左键双击(DOUBLE_CLICK)、右键单击(RIGHT_CLICK)、鼠标悬停(HOVER),例如 CLICK(box=[[387,248,727,317]], element_type='可点击文本', element_info='Click to add Title')。这四种动作所支持的参数如下表所示:
| 参数名 | 可选与否 | 解释 |
|---|---|---|
| box | 必选 | 以[[a,b,c,d]]表示屏幕上的一个矩形,其中 a/b/c/d 均为 000 到 999 之间的三位数字。 假设屏幕的宽度为 w,高度为 h。屏幕左上角坐标为(0, 0)。矩形的左上角坐标为 (a / 1000 * w, b / 1000 * h),矩形的右下角坐标为 (c / 1000 * w, d / 1000 * h)。 实际操作的位置为矩形的中点。 |
| element_type | 可选 | 对被操作元素的类型描述,例如“可点击文本” |
| element_info | 可选 | 对被操作元素的内容描述,例如“Click to add Title” |
2.3.2 文本输入(TYPE)
文本输入是指在给定位置输入文本,例如 TYPE(box=[[387,249,727,317]], text='CogAgent', element_type='文本输入框', element_info='CogAgent') 。它所支持的参数如下表所示:
| 参数名 | 可选与否 | 解释 |
|---|---|---|
| box | 必选 | 请参考“四种鼠标操作”中的解释。 |
| element_type | 可选 | 请参考“四种鼠标操作”中的解释。 |
| element_info | 可选 | 请参考“四种鼠标操作”中的解释。 |
| text | 必选 | 需要被输入的文本内容。该参数取值中可能包含形如__CogName_xxx__的变量。在实际执行“文本输入”动作时,变量应该被替换成实际的取值。详情请参考这里。 |
2.3.3 4种滚动操作
滚动操作包含:向上滚动(SCROLL_UP)、向下滚动(SCROLL_DOWN)、向左滚动(SCROLL_LEFT)、向右滚动(SCROLL_DOWN),例如 SCROLL_DOWN(box=[[000,086,999,932]], element_type='滚动', element_info='滚动', step_count=5)。这四种动作所支持的参数如下表所示:
| 参数名 | 可选与否 | 解释 |
|---|---|---|
| box | 必选 | 请参考“四种鼠标操作”中的解释。 |
| element_type | 可选 | 请参考“四种鼠标操作”中的解释。 |
| element_info | 可选 | 请参考“四种鼠标操作”中的解释。 |
| step_count | 必选 | 滚动的步骤数,滚动一步对应于鼠标滚轮滚动一格。注意:系统设置和应用类型均会影响滚动一步的实际效果,因此模型难以准确预测所需的滚动步骤数。 |
2.3.4 敲击键盘(KEY_PRESS)
敲击键盘是指按下并抬起依次给定的按钮,例如KEY_PRESS(key='F11')。这一操作类型仅有一个必选的参数key ,表示需要被敲击的按键名称,例如数字键(0~9)、字母(A-Z)。除此之外,KEY_PRESS同时支持以下常用按键,如下表所示。
| Windows | macos | |
|---|---|---|
| 换行/回车 | Return | Return |
| 空格 | Space | Space |
| ctrl 键(左/右) | Lcontrol / Rcontrol | N/A |
| alt 键(左/右) | Lmenu / Rmenu | N/A |
| control 键(左/右) | N/A | Control / Right Control |
| command 键(左/右) | N/A | Command / Right Command |
| Shift 键(左/右) | Lshift / Rshift | Shift / Right Shift |
| 方向键-上 | Up | Up Arrow |
| 方向键-下 | Down | Down Arrow |
| 方向键-左 | Left | Left Arrow |
| 方向键-右 | Right | Right Arrow |
2.3.5 手势(组合键)(GESTURE)
使用组合键,例如ctrl+f来进行查找。对应的结构化表达为 GESTURE(actions=[KEY_DOWN(key='Lcontrol'), KEY_PRESS(key='A'), KEY_UP(key='Lcontrol')])。GESTURE仅包含一个参数 actions,该参数的取值为一个列表,列表中的每一个元素为以下三个动作之一:
-
KEY_DOWN:按下某一个键,但不抬起; -
KEY_PRESS:敲击某一个按键,即按下并抬起; -
KEY_UP:松开某一个已经按下的按键。
2.3.6 启动应用或链接(LAUNCH)
直接打开某个应用,或者在浏览器中打开某个链接。LAUNCH操作接收app和url两个参数,前者表示需要打开的应用名,后者表示需要打开的链接。如果同时给定两个参数,则仅有 url生效。例如:
-
LAUNCH(app='设置', url='None'):打开系统设置; -
LAUNCH(app='None', url='``baidu.com``'):打开百度首页。
2.3.7 引用文本内容(QUOTE_TEXT)
识别并处理给定区域中的文本内容,将结果存储在变量中供后续使用。例如:
QUOTE_TEXT(box=[[387,249,727,317]], element_type='文本', element_info='券后价:17.00', output='__CogName_商品价格__', result='17.00');
QUOTE_TEXT(box=[[000,086,999,932]], auto_scroll=True, element_type='窗口', element_info='CogAgent技术报告博客', output='__CogName_技术报告__')。
它所支持的参数如下表所示:
| 参数名 | 可选与否 | 解释 |
|---|---|---|
| box | 必选 | 请参考“四种鼠标操作”中的解释。 |
| element_type | 可选 | 请参考“四种鼠标操作”中的解释。 |
| element_info | 可选 | 请参考“四种鼠标操作”中的解释。 |
| output | 必选 | 变量名,表示引用结果的存储位置。格式为__CogName_xxx__。 |
| result | 可选 | 表示文本引用的结果。如果文本引用结果过长,则result取值中会带有省略号,甚至没有这一参数。在这种情况下,CogAgent 端侧应用需要自行调用 OCR 服务来获取引用结果。 |
| auto_scroll | 可选 | 默认值为False。如果auto_scroll为真,则 CogAgent 端侧应用需要自行向下滚动列表直到列表底部,同时获取列表内容作为医用文本的结果。当需要被引用的文本很长的时候,需要设置auto_scroll为真。 |
2.3.8 调用LLM与变量使用
组织提示词并调用大预言模型来计算结果。这一动作所接收的参数如下所示:
| 参数名 | 可选与否 | 解释 |
|---|---|---|
| prompt | 必选 | 调用大语言模型所使用的 prompt,其中使用到的变量名会被替换成实际的取值。 |
| output | 必选 | 变量名,表示调用大语言模型的结果所存储的位置。格式为__CogName_xxx__。 |
| result | 可选 | 表示调用大语言模型的结果。如果结果过长,则result取值中会带有省略号,甚至没有这一参数。在这种情况下,CogAgent 端侧应用需要自行调用大语言模型服务来获取结果。 |
例如,通过以下两个操作,可以总结本页面的全部内容:
1. 引用本页面的全部内容。由于页面中内容很多,需要在引用时设置auto_scroll=True
QUOTE_TEXT(box=[[000,086,999,932]], auto_scroll=True, element_type='窗口', element_info='CogAgent技术报告博客', output='__CogName_技术报告__')
2. 调用大预言模型,总结技术报告的内容。技术报告的内容已经存储在变量__CogName_技术报告__中,因此应该在参数 prompt中直接使用这一变量;在调用大语言模型生成总结内容时,__CogName_技术报告__需要被替换成实际的取值。
LLM(prompt='总结以下内容:__CogName_技术报告__', output='__CogName_技术报告总结__')
2.3.9 引用剪贴板内容(QUOTE_CLIPBOARD)
将剪贴板中的内容存储在某一个变量中,供后续步骤使用。很多网页/应用会提供“点击复制到剪贴板”的功能。QUOTE_CLIPBOARD 可以让模型快速获得并使用剪贴板的内容。
以下是一个结构化表达的例子: QUOTE_CLIPBORAD(output='__CogName_快速排序代码__', result='def quick_sort(arr):\n\tif len(arr) <= 1:\n\t\treturn arr\n\t...')
2.3.10 结束(END)
一个特殊的操作,表示任务已经完成。
3 评测
3.1 执行过程
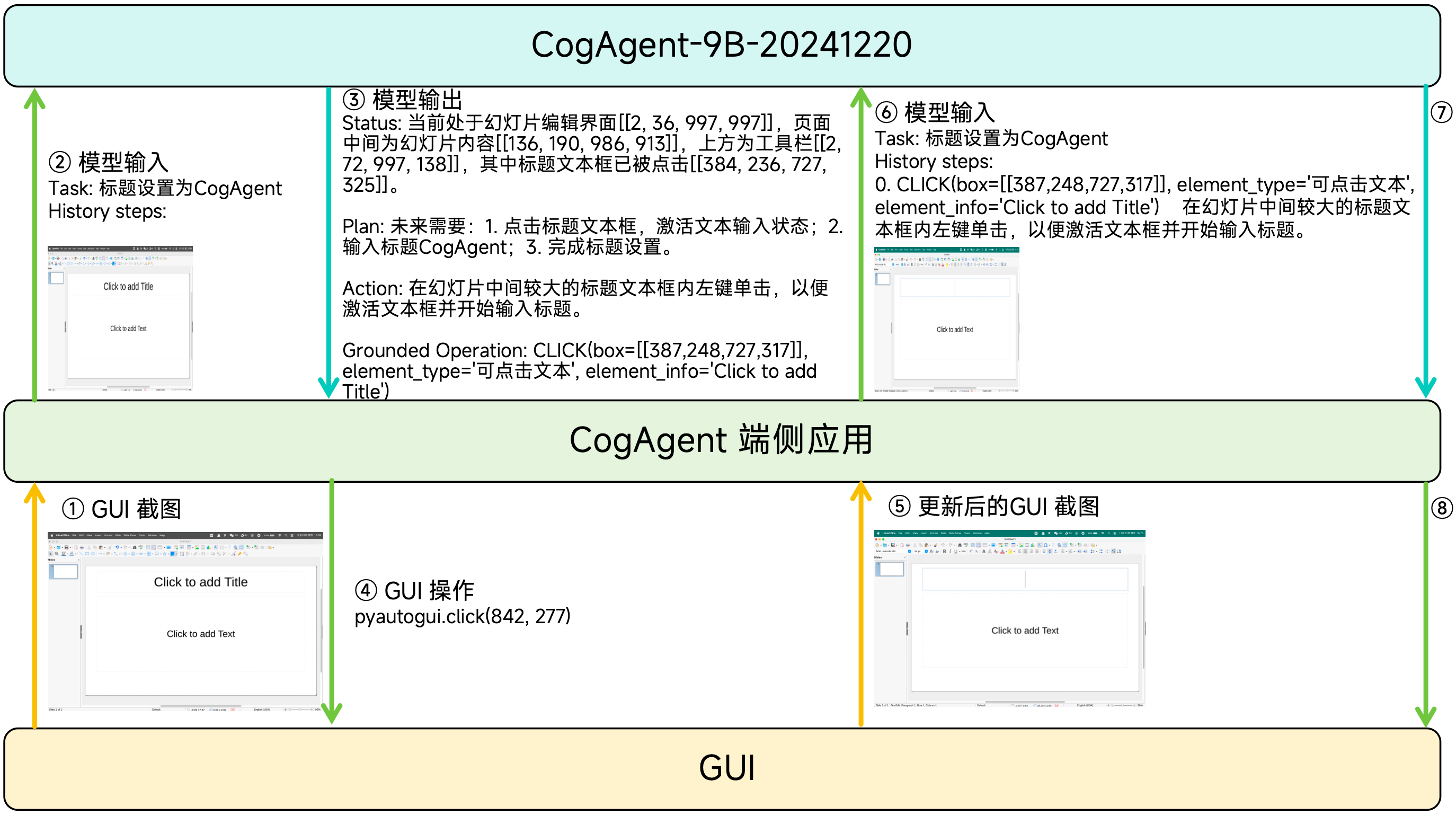
下图是执行用户指令的过程。CogAgent-9B-20241220以 GUI 截图为唯一的环境输入,结合已经完成的动作历史,计算当前 GUI 截图中最合适的动作。
3.2 评测结果
-
Screenspot。Screenspot 衡量模型进行 GUI 元素定位的能力。
-
OmniAct。模型在 OmniAct 任务中第一步操作的准确率,即使OmniAct 任务可能需要多步操作才能完成。这是因为 OmniAct 没有提供每一步操作之后的屏幕截图。
-
CogAgentBench-basic-cn。CogAgentBench-basic-cn是作者团队自行收集并内部使用的中文测试集,每个测试样本是完成一条指令过程中的一个步骤,测试样本的输入与 CogAgent 所接收的输入相同。值得注意的是,在给定相同的截图、用户指令、历史操作的情况下,可能会有多个正确的输入,例如点击“发送”按钮和按下回车键都可以发送消息。我们人工为每一条测试样本标记出所有可能的正确输出。CogAgentBench-basic-cn包含了 147 个任务对应的 1100 个步骤,涉及微信、淘宝、小红书、12306、携程等常见中文应用和网站。表格中的数字为单步操作的正确率。
-
OSworld。表格中的数字为多步任务的完成率。
| 模型 | Screenspot (Grounding) | OmniAct (First-step) | CogAgentBench-basic-cn (Single-Step) | OSworld (Multi-step) |
|---|---|---|---|---|
| 基于API的商业模型 | ||||
| GPT-4o-20240806 | 18.3 [4] | 47.0 [3] | 19.7 | 4.25 |
| Claude-3-5-sonnet-20241022 | 83.0 | 56.8 | 56.6 | 14.9 [1] |
| 商业API + GUI grounding模型 | ||||
| GPT-4o + UGround | 81.4 [4] | 32.8 [4] | - | - |
| GPT-4o + OS-ATLAS | 85.1 [3] | 57.3 [3] | - | 14.6 [3] |
| 开源GUI agent模型 | ||||
| SeeClick | 53.4 [5] | - | - | - |
| ShowUI | 75.1 [2] | 44.0 | - | - |
| Qwen2-VL | 69.1 [3] | 46.6 | 27.6 | 4.44 |
| CogAgent-9B-20241220 | 85.4 | 58.3 | 74.1 | 8.12 |
3.3 实测体验
官方代码只开放了PC端的demo,实际运行体验来看,CogAgent的grounding和plan能力都非常好,对于一般简单的任务,比如打开某个文件夹里的某个文件,打开浏览器搜索某个内容,查询路线、机票等基本上都可以完成。不过对于复杂的任务,或者打开一个冷门没见过的应用就不太行了。
不过比较惊喜的是,在手机端的grounding和plan能力也非常强,结合ADB就能实现与手机的联动。如打开微信给指定联系人发送消息,或者打开某个应用都可以。不过针对图标不在桌面的应用就不知道怎么打开了。
总体而言,效果还是非常惊艳的!感谢智谱团队开源!
参考资料
[1] CogAgent-9B-20241220 技术报告
[2] CogAgent操作空间
[3] 提示词拼接

















 1563
1563

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









