






 本文介绍了fMRI数据的预处理流程,包括从原始数据的dcm2niigui格式转换,时间层校正,头动校正(realign),空间标准化(normalize和coregister),以及平滑和滤波等步骤。重点讨论了spm软件中的操作方法和参数设置,如slicetiming和realign的细节。此外,提到了restplus工具在批量处理预处理中的应用。
本文介绍了fMRI数据的预处理流程,包括从原始数据的dcm2niigui格式转换,时间层校正,头动校正(realign),空间标准化(normalize和coregister),以及平滑和滤波等步骤。重点讨论了spm软件中的操作方法和参数设置,如slicetiming和realign的细节。此外,提到了restplus工具在批量处理预处理中的应用。
新手学习,记录学习笔记,欢迎交流~
1.基本概念
Volume(容积/体积)/frame/time point(因为4d文件是包含时间的,可以称为时间点)/scan/一个TR即一帧(frame)采集到的图像称为一个volume,每一帧图像都是一个3D全脑
TR:重复时间,即得到一个完整大脑所需时间
TA:一次全脑扫描中,最后一层与第一层的时间间隔;
TA=TR-(TR/扫描层数)
slice timing:扫描层数。扫描大脑是一层一层扫描的,通常是隔层扫描,因为信号可能会受到相邻层的影响,所以需要隔层扫,比如先扫1 3 5 7再倒回去扫2 4 6 8层这样。然后再把这些层重建成一个完整的3D大脑。
Run/Session: 一次4D-fMRI数据采集,整个4D-fMRI的采集时间;推荐参数:至少6分钟,8分钟及以上最优。一般静息态是1个,如果是任务态,那么可能中途要休息一次分两次扫描,session就是2个。
Reference slice:时间层校正的参考层,也就是TR/2对应的层数
时间层校正后的文件带有a开头,表示校正后。
2.预处理流程--NARWSDCF
N:格式转换,把存储原始fMRI信息的数据转换为NIFTI格式
A:时间层校正,变为a开头文件
R:realign--estimate&res头动校正:统计分析需要假设每个体素在各个时间点都对应大脑的同一个位置。头动校正是去除头动的干扰
W:分为一步配准和两步配准,这里是两步配准:
·normalize--estimate&write空间标准化:将个体的BOLD图像转化到标准空间
·coregister配准:把高分辨率、高灰质/白质对比度的T1像配准到BOLD空间,结构像与功能像配准
·segement:分割灰质,白质和脑脊液
S:smooth:空间平滑
D:detrend去除线性趋势:去除大时间尺度上,非神经活动引起的BOLD信号的偏移
C:nuisance coviriates regression 回归协变量
F:filter 滤波:滤出BOLD信号所处的频率段的数据。目的是降噪。BOLD信号所处0.01~0.08hz
然后
(1)首先是格式转换:使用dcm2niigui,将原始数据文件夹整个拖进去
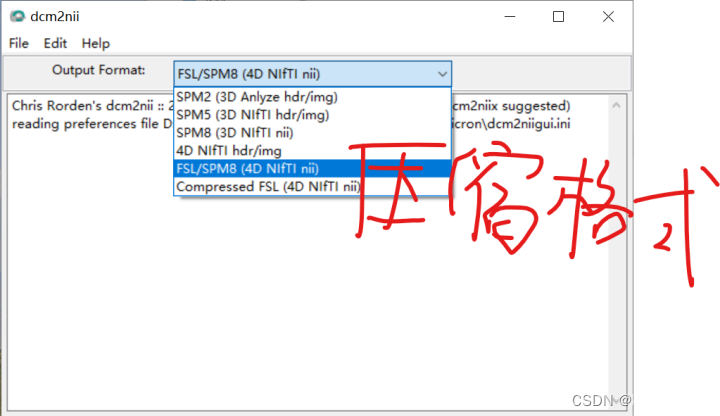
或者使用microGL(既可看图又可转换文件)
(2)第二步是A:时间层校正,
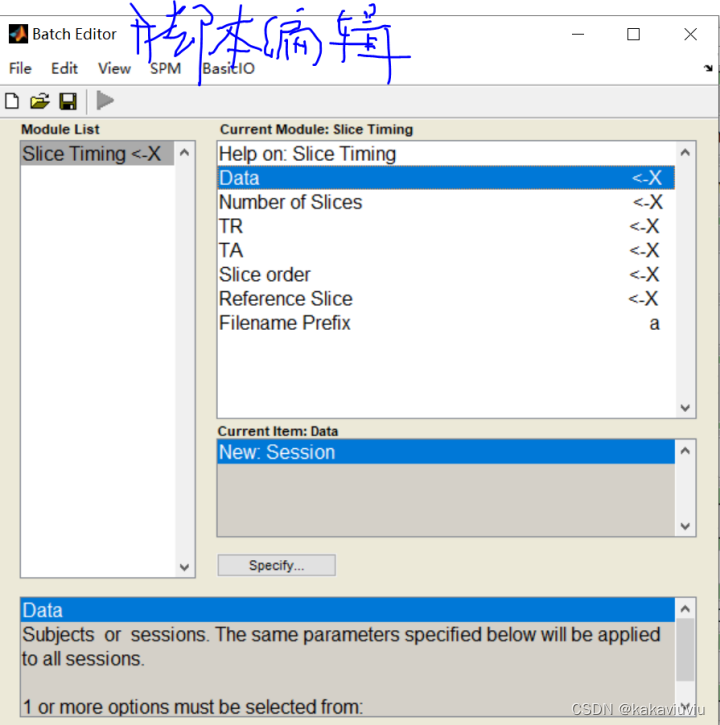
打开spm,点击slice timing--data--点击session
导入进nii文件,注意把右下角的1换为inf(无限的意思),然后右键--select all
(可以提前把matlab的路径设置成存放文件的路径,这样方便选择)
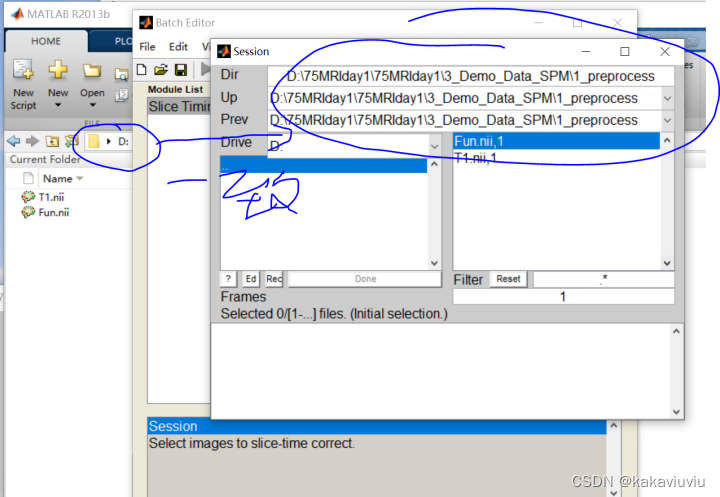
frame:1 --第一帧的图像 ,一般写成inf(无穷,可以包含所有的图像)
filter旁边的白色长空格可以输入文件名来筛选文件
选完点done
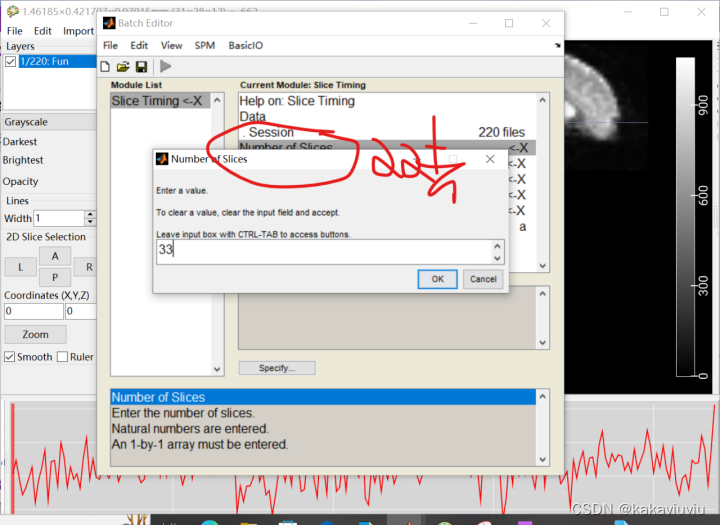
扫描层数:33层
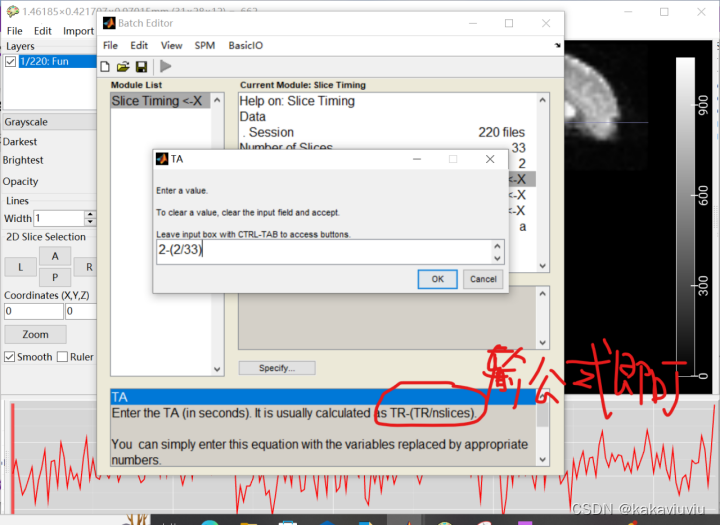
填写TA
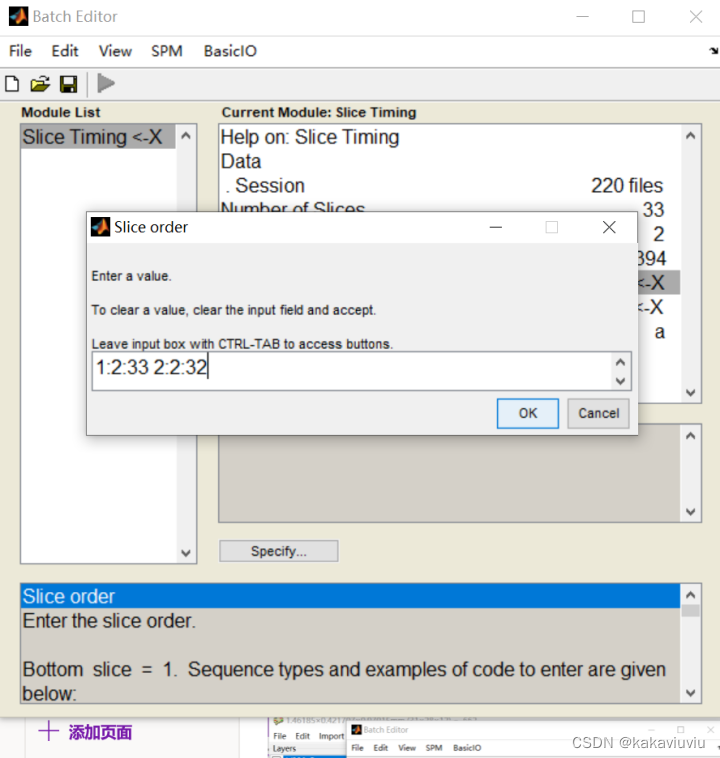
扫描顺序:1是首项,2是步长,33是尾项;两个等差数列之间用空格隔开(会自动判断是否结束)。翻译过来就是1 3 5 7层 ... 2 4 6 8层...这样的扫描顺序
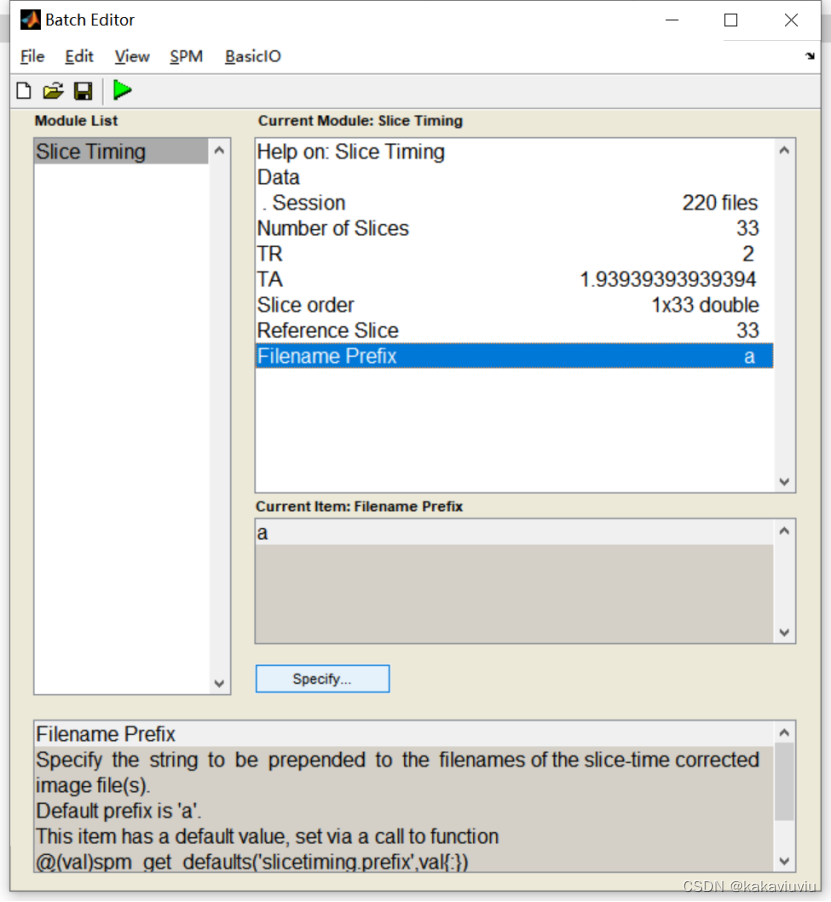
参考层:中间层的层数(第33层)
填好了然后点绿色的符号开run!
(3)R:realign 头动校正
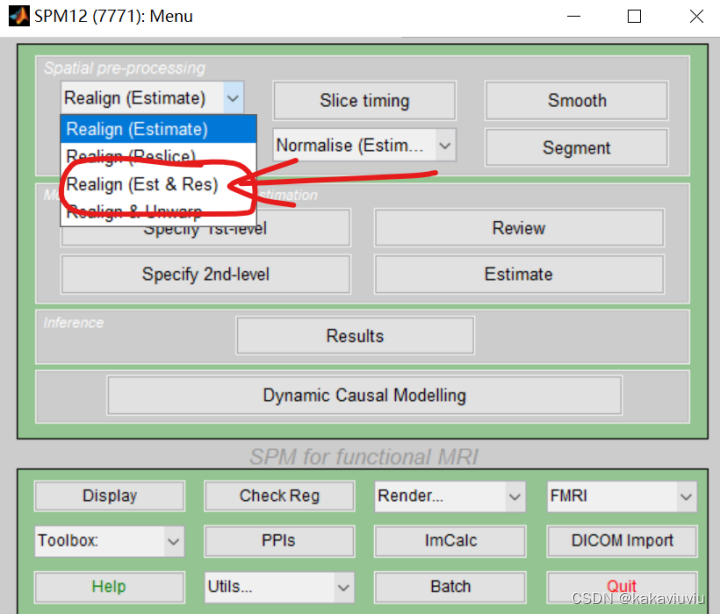
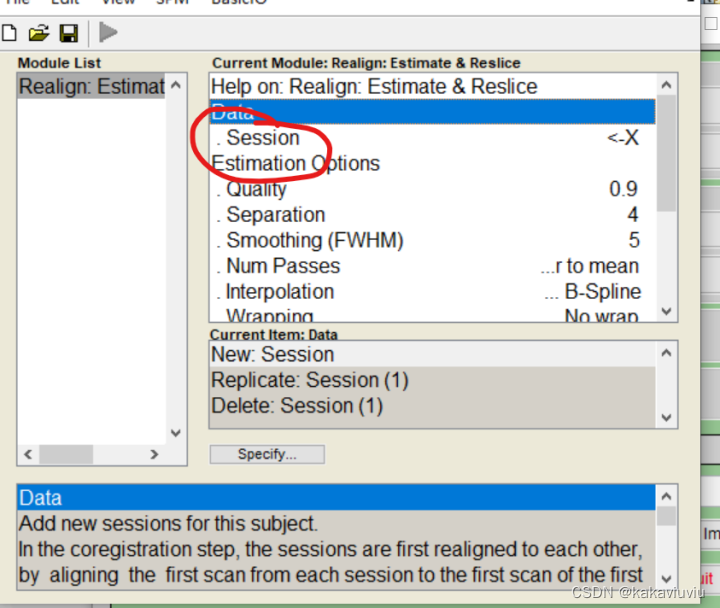
双击
只筛选以a为开头的文件(上一步生成的时间校正后的文件)
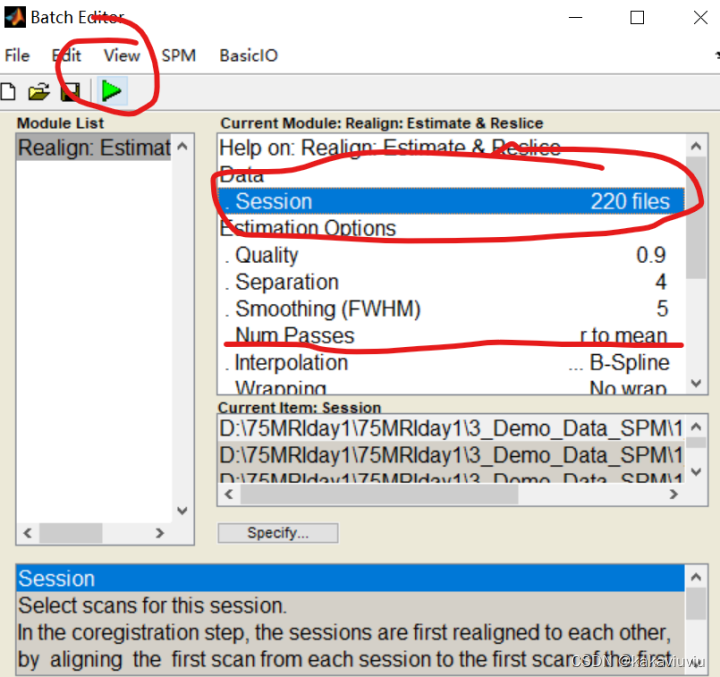
文件选中就可以运行了。Num passes 后面的register to mean:选中to fist 与第一张图象对齐,to mean,就是与平均的对齐
 处理完一共多了这三个文件,txt的Rotation parameter:头动参数;看它有没有超过2的(控制)但spm不做处理,只有原始数据,一般不会人工手动筛选。(用restplus可以自动筛选)
处理完一共多了这三个文件,txt的Rotation parameter:头动参数;看它有没有超过2的(控制)但spm不做处理,只有原始数据,一般不会人工手动筛选。(用restplus可以自动筛选)
(4)W:两步配准法
一步配准法(EPI配准):个体fMRI---线性+非线性--->标准空间fMRI(Normalize(Est&Wri))
两步配准法(T1配准)(EPI distortion):
1.个体T1---线性---->配准到个体fMRI的个体T1(Coregister(Estimate))
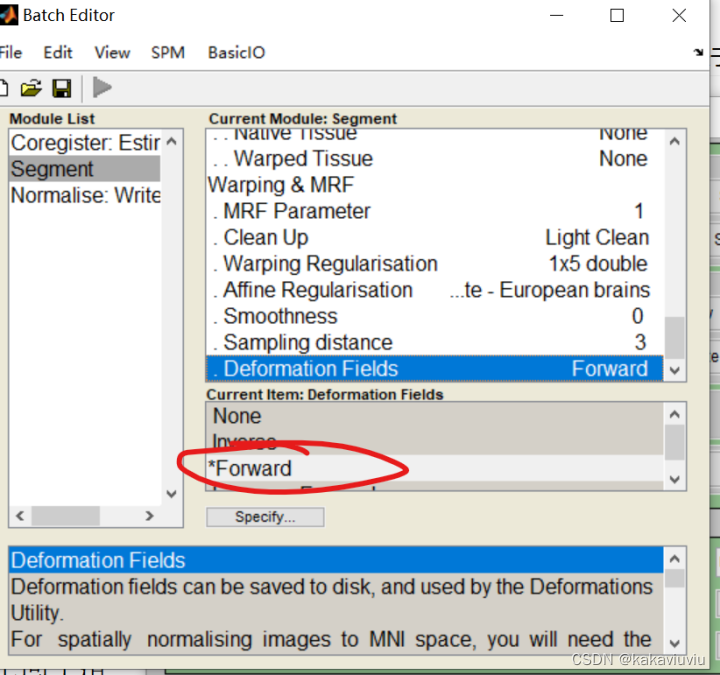
2.配准到个体fMRI的个体T1--->线性+非线性---->个体到标准空间的形变场(Segment)--形变场记录了卷纸是如何变成和抽纸一样形状的过程
3.个体fMRI---应用第二步的形变场--->标准空间fMRI(Normaliz&Write)
根据情况选择不同的配准法,这里介绍两步配准法

T1选为source image
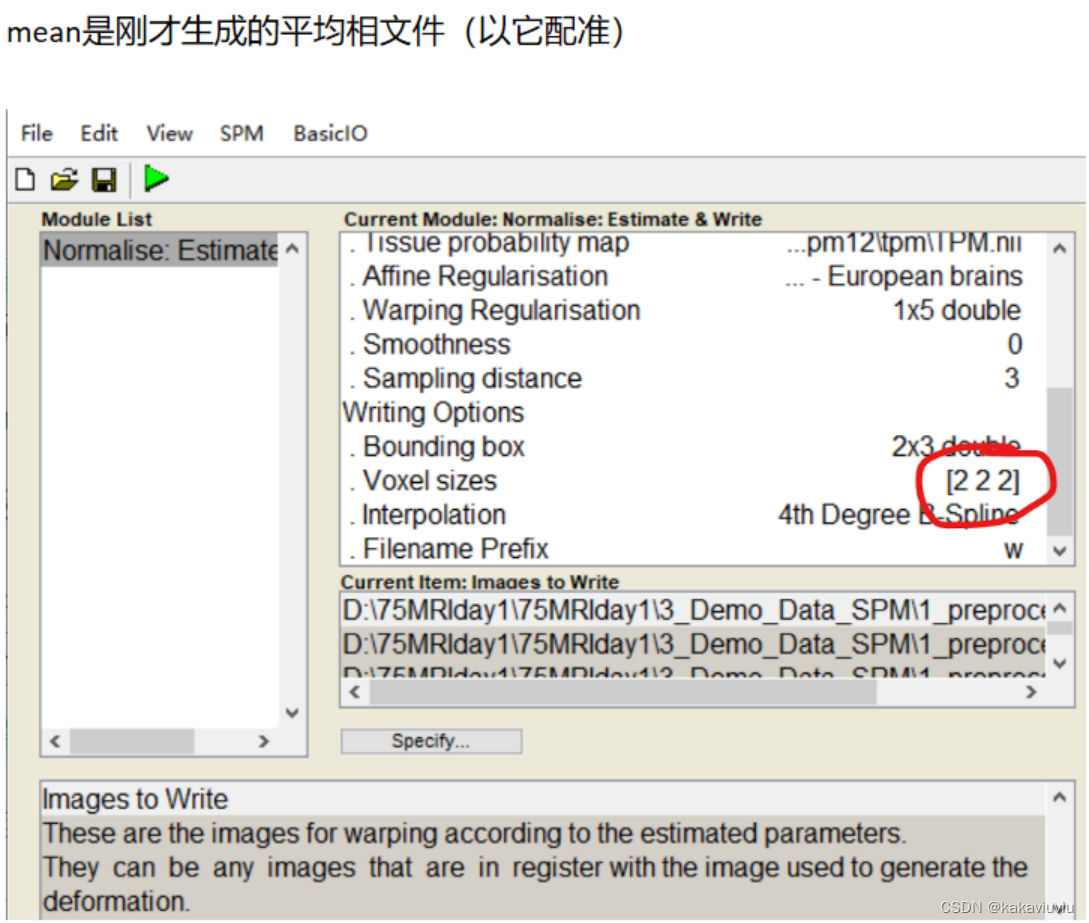
voxel改为3 3 3
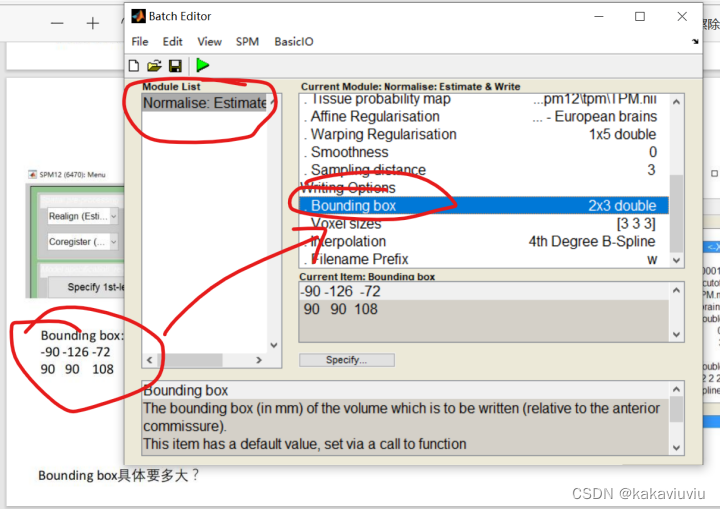
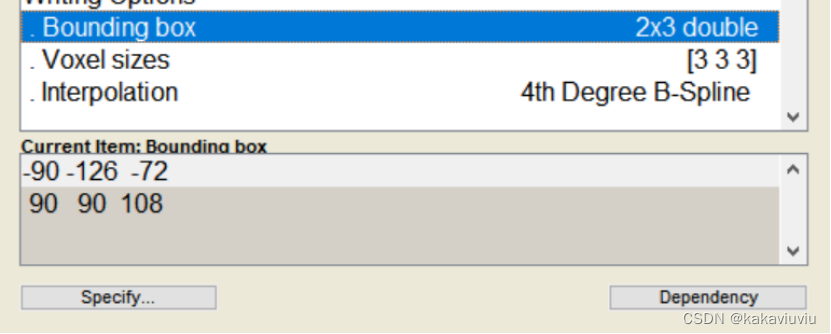
设置bounding box边界框:固定值,代表生成文件图像整体的范围是多少
然后点segment(也可以先选,之后来设置这些参数)
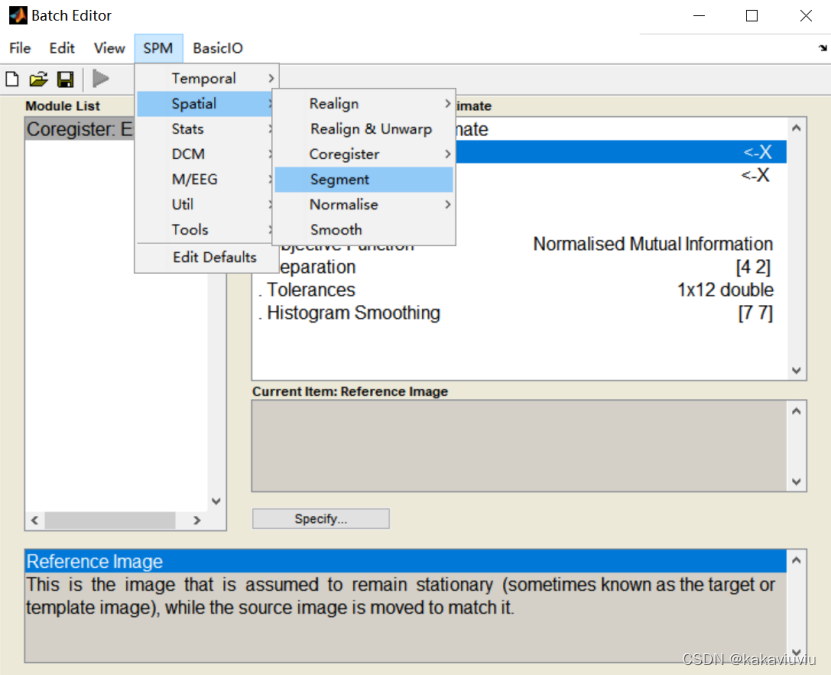
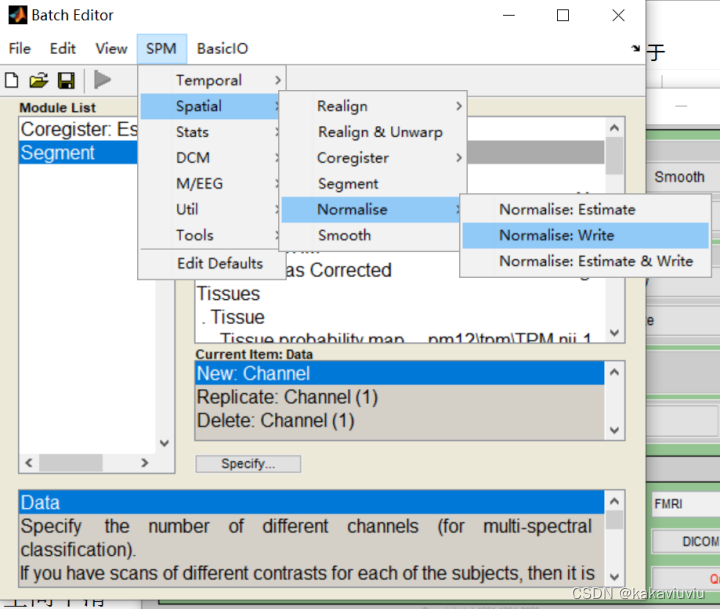
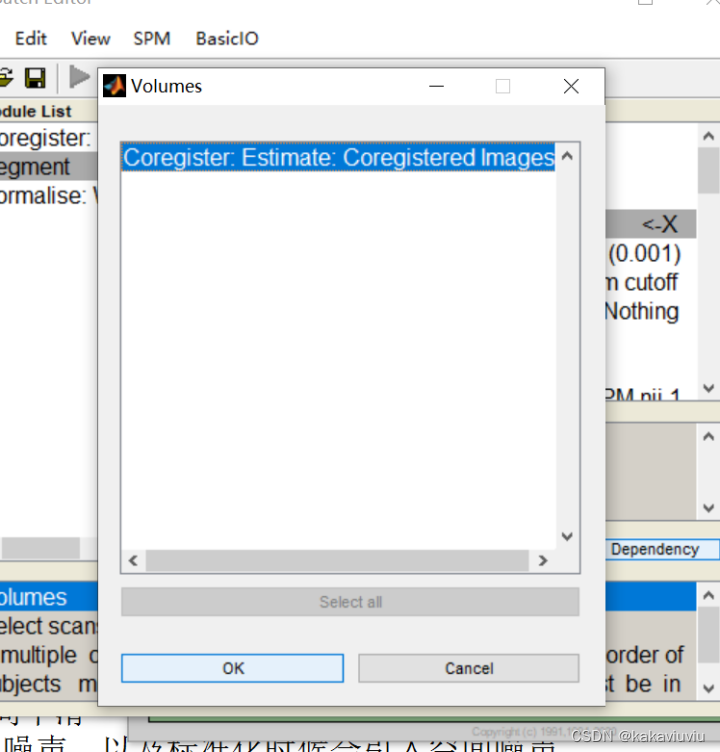
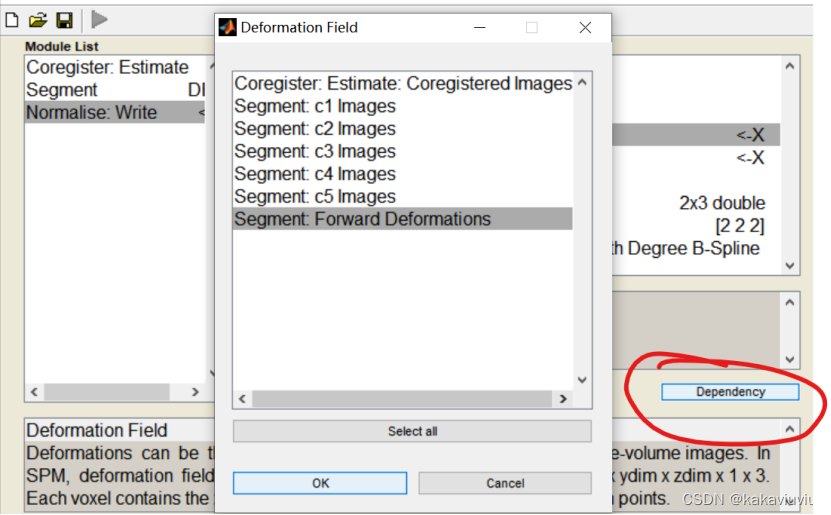
再选择normalise
点dependency
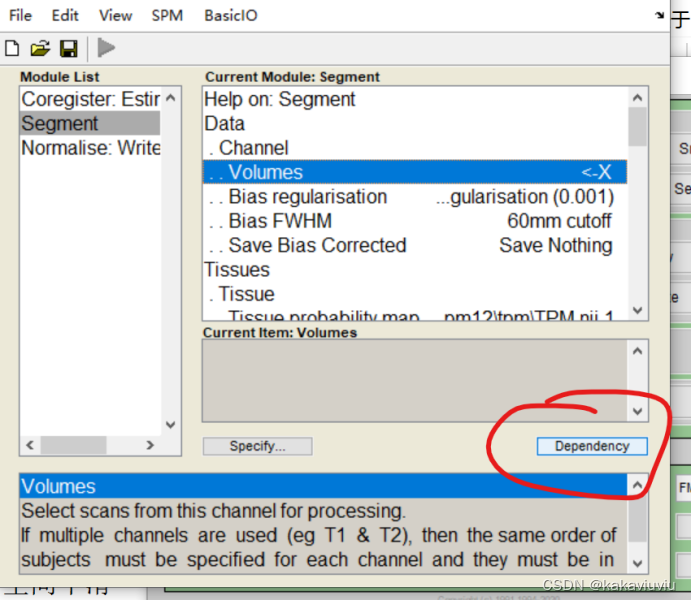
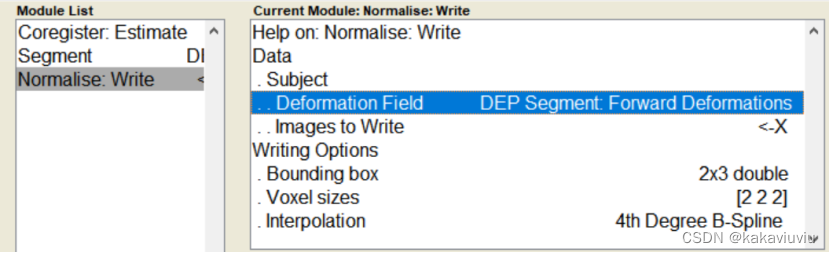
修改boundingbox和体素3 3 3
Run
生成wra开头的文件
(5)平滑
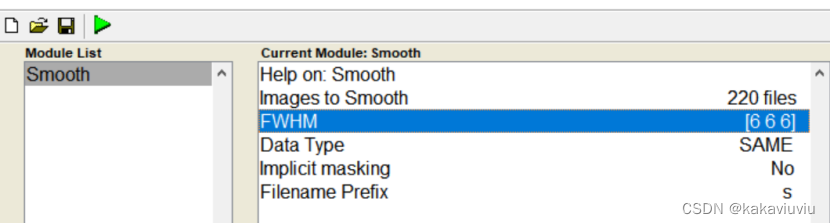
把上一步的文件wra开头的导入,平滑核6 6 6(体素的2-3倍,一般就用2倍)
run
得到swra开头文件
剩下几步用restplus做(实际上上述步骤都可以用restplus批量处理)
Restplus
Set path--add with subfolders-添加restplus的文件夹
打开pipeline
Matlab切路径到restplus
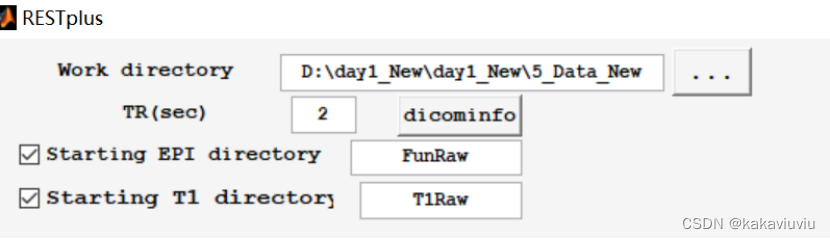
work directory选择所用文件的上一级文件夹
EPI directory选择功能像,T1 directory选择T1的文件夹(原始数据)
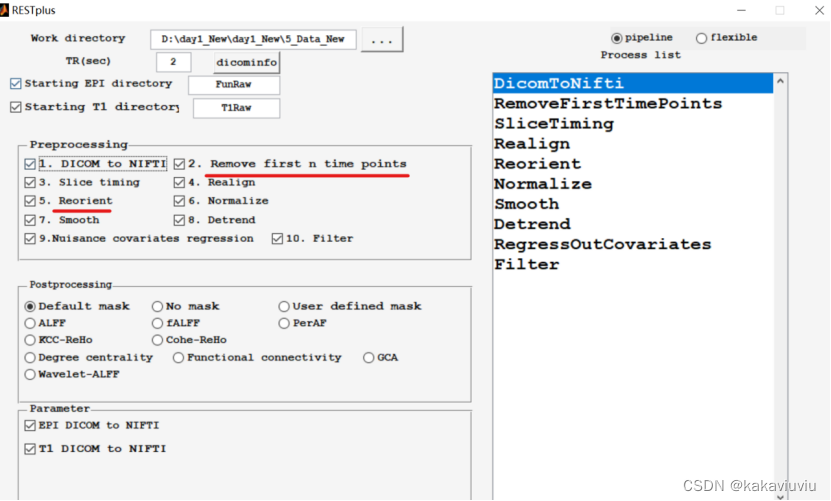
其中,2和5可选可不选
每一项的参数根据自己实际需要来调整即可(略)

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









