









- CVPR2023
- https://github.com/Ree1s/IDM
- 问题引入:
– LIIF方法可以实现任意分辨率的输出,但是因为是regression-based方法,所以得到的结果缺少细节,而生成的方法(gan-based,flow-based,diffusion-based等)可以生成细节,但是只能是固定的放大倍率;
– 所以本文提出IDM(implicit diffusion model)来同时实现任意分辨率(implicit image function)和生成高保真图片(diffusion model) - 方法:
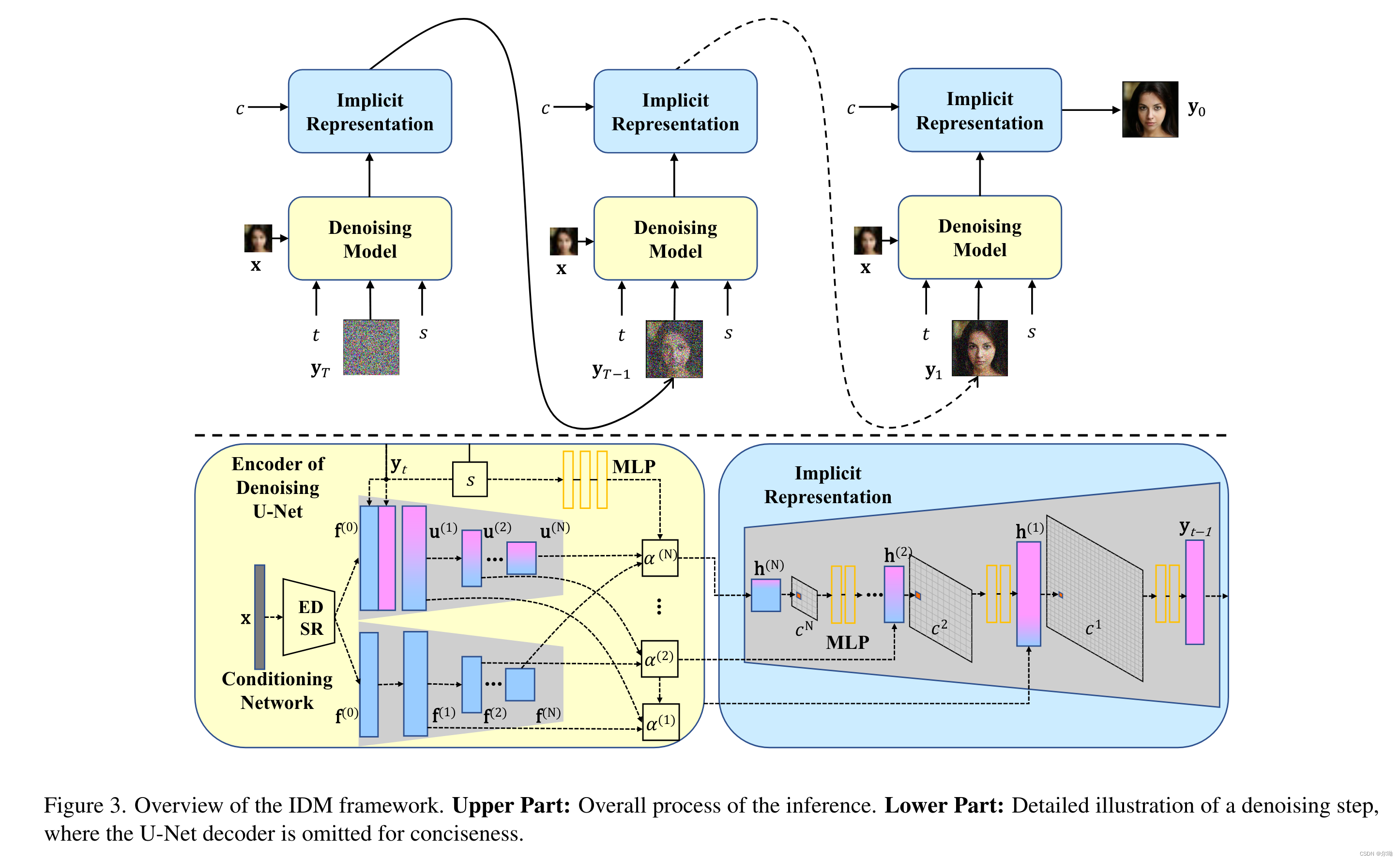
– LR-HR数据对 ( x i , y i ) (x_i,y_i) (xi,yi),缩放倍率 s s s,所以本质上模型就是学习一个分布 p ( y i t − 1 ∣ y i t , x i ) p(y^{t-1}_i|y^t_i,x_i) p(yit−1∣yit,xi),其中 y 0 y^0 y0表示sample的HR图像, y T y^T yT表示纯噪声,整体就是一个diffusion model的训练,主要不同点在于condition(LR+s)的引入以及implicit representation
– 条件的引入:LR分辨率图像经过EDSR得到feature f 0 f^0 f0并差值到和HR latent相同大小,之后和noised latent进行concat作为模型输入,同时 f 0 f^0 f0跟随U-Net进行同步downsample,之后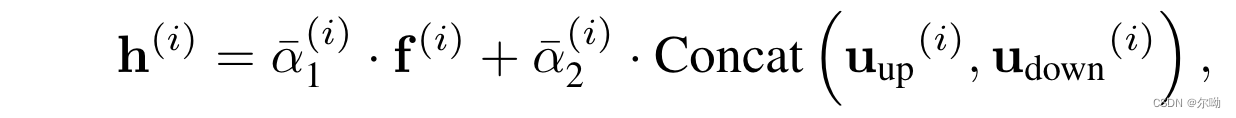
其中系数是scale s s s经过MLP和归一化得到的, u u u是U-Net中间输出,此时得到的 h h h还需要经过implicit image function(和LIIF类似)得到最终的结果















04-17
 1479
1479
1479
10-31
3万+
3万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









