







本文转自蘑菇书强化学习基础,是根据《强化学习纲要》整理而来。
1.1强化学习基础
强化学习(RL)是智能体在复杂、不确定环境下最大化获得奖励的过程。所以RL有两个必需的部分:智能体和环境,智能体处在与环境不断交互的过程中,智能体的目的就是从环境中获得更多的奖励。
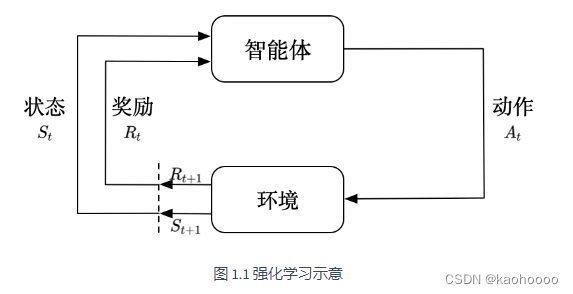
智能体在环境中获得某个状态,会利用改状态输出动作,环境会给予动作相应的奖励,同时输出下一个状态。
1.1.1强化学习与监督学习
在监督学习过程中,有两个假设:
- 输入的数据(标注的数据)都应是没有关联的。因为如果输入的数据有关联,学习器(learner)是不好学习的。
- 需要反馈,告诉学习器正确的标签是什么,这样它可以通过正确的标签来修正自己的预测。
而在强化学习中:
- 数据不是独立同分布的(通常假设样本空间中全体样本服从一个未知分布,我们获得的每个样本都是独立地从这个分布上采样获得的,通俗来说就是样本之间没有关联),上下帧有很强的关联性,得到的数据是时间序列数据。
- 没有即时反馈,得到延时奖励(最后才知道比赛结果是赢是输)。
- 智能体不断自己探索试错,通过探索环境来获取对环境的理解,可以超越人类能力,比如 DeepMind 的 AlphaGo 这样一个强化学习的算法可以把人类顶尖的棋手打败。
1.1.2强化学习的例子
在强化学习里面,我们让智能体尝试玩 Pong 游戏,对动作进行采样,直到游戏结束,然后对每个动作进行惩罚。预演是指我们从当前帧对动作进行采样,生成很多局游戏。我们将当前的智能体与环境交互,会得到一系列观测。每一个观测可看成一个轨迹(trajectory)。 轨迹就是当前帧以及它采取的策略,即状态和动作的序列:
![]()
最后结束时,我们会知道到底有没有把这个球拍到对方区域,对方有没有接住,我们是赢了还是输了。我们可以通过观测序列以及最终奖励(eventual reward)来训练智能体,使它尽可能地采取可以获得最终奖励的动作。一场游戏称为一个回合(episode)或者试验(trial)。
1.1.3强化学习的历史
DRL=DL+RL,即深度强化学习 = 深度学习 + 强化学习。
-
标准强化学习:比如 TD-Gammon 玩 Backgammon 游戏的过程,其实就是设计特征,然后训练价值函数的过程。标准强化学习先设计很多特征,这些特征可以描述现在整个状态。 得到这些特征后,我们就可以通过训练一个分类网络或者分别训练一个价值估计函数来采取动作。
-
深度强化学习:自从我们有了深度学习,有了神经网络,就可以把智能体玩游戏的过程改进成一个端到端训练(end-to-end training)的过程。我们不需要设计特征,直接输入状态就可以输出动作。我们可以用一个神经网络来拟合价值函数或策略网络,省去特征工程(feature engineering)的过程。
1.2序列决策
智能体与环境不断交互,智能体发出的动作给环境,环境给出相应的观测结果(奖励)。
强化学习里面一个重要的课题就是近期奖励和远期奖励的权衡 (trade-off),研究怎么让智能体取得更多的远期奖励。
在与环境的交互过程中,智能体会获得很多观测。针对每一个观测,智能体会采取一个动作,也会得到一个奖励。所以历史是观测、动作、奖励的序列:
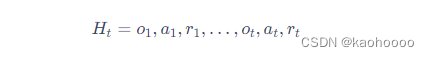
智能体在采取当前动作的时候会依赖于它之前得到的历史,所以我们可以把整个游戏的状态看成关于这个历史的函数:
![]()
状态是对世界的完整描述,不会隐藏世界的信息。
观测是对状态的部分描述,可能会遗漏一些信息
1.3动作空间
离散动作空间:智能体的动作数量数有限的,比如往东、往南、往西、往北这 4 种移动方式。
连续动作空间 :在物理世界控制一个智能体,动作是实值的向量,比如机器人可以向 360 ◦ 中的任意角度进行移动。
1.4强化学习中的组成与分类
1.4.1强化学习的组成
策略:智能体会用策略来选取下一步的动作。它其实是一个函数,用于把输入的状态变成动作。策略可分为两种:随机性策略和确定性策略。
常用随机性策略:这个概率是智能体所有动作的概率,然后对这个概率分布进行采样,可得到智能体将采取的动作。比如可能是有 0.7 的概率往左,0.3 的概率往右,那么通过采样就可以得到智能体将采取的动作。
确定性策略:智能体直接采取最有可能的动作。
价值函数:其值是对未来奖励的预测,我们用它来评估状态的好坏。
价值函数里面有一个折扣因子(discount factor),我们希望在尽可能短的时间里面得到尽可能多的奖励。还有一种价值函数:Q 函数。Q 函数里面包含两个变量:状态和动作。其定义为
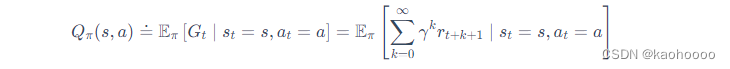 模型:模型决定了下一步的状态。下一步的状态取决于当前的状态以及当前采取的动作。它由状态转移概率和奖励函数两个部分组成。状态转移概率即
模型:模型决定了下一步的状态。下一步的状态取决于当前的状态以及当前采取的动作。它由状态转移概率和奖励函数两个部分组成。状态转移概率即
![]()
奖励函数是指我们在当前状态采取了某个动作,可以得到多大的奖励,即
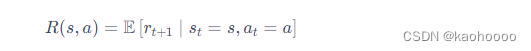
当我们有了策略、价值函数和模型3个组成部分后,就形成了一个马尔可夫决策过程。
1.4.2强化学习类型
根据智能体学习的事物不同,将其分为:
基于价值的智能体(value-based agent):每一个状态会返回一个价值(智能体会比较附近的方格,寻找使得最终值最高的路径),用在连续环境中,例如策略梯度PG算法。
基于策略的智能体(policy-based agent):每一个状态会得到一个最佳动作(第一个方格向左,第二个方格向右),只能用在离散环境中,例如Q学习(Q-learning)、 Sarsa 等。
演员-评论员算法(Actor-Critic)同时使用策略和价值评估来做出决策。其中,智能体会根据策略做出动作,而价值函数会对做出的动作给出价值,这样可以在原有的策略梯度算法的基础上加速学习过程,取得更好的效果。
此外,可以通过智能体到底有没有学习环境模型来对智能体进行分类。
有模型(model-based)强化学习智能体通过学习状态的转移来采取动作。其构建一个虚拟世界,同时在真实环境和虚拟世界中学习,并能对下一步的状态和奖励进行预测。
免模型(model-free)强化学习通过学习价值函数和策略函数进行决策,模型里面没有环境转移的模型。只能一步一步采取策略,等待真实环境的反馈。
1.5学习与规划
学习(learning)和规划(planning)是序列决策的两个基本问题。
学习:环境初始时是未知的,智能体不知道环境如何工作,它通过不断地与环境交互,逐渐改进策略。
规划:智能体不需要实时地与环境交互就能知道未来环境,只需要知道当前的状态,就能够开始思考,来寻找最优解。
一般解决问题:先学习得到一个模型,然后利用这个模型进行规划。
1.6探索与利用
在强化学习里面,探索和利用是两个很核心的问题。
探索,探索环境,通过尝试不同的动作来得到最佳的策略(带来最大奖励的策略)。
利用,利用已知动作。
1.7实验
很多深度学习的包可以使用:PyTorch、TensorFlow、Keras,熟练使用其中的两三种,就可以实现非常多的功能。
OpenAI是一家非营利性的人工智能研究公司,其公布了非常多的学习资源以及算法资源。其之所以叫作 OpenAI,他们把所有开发的算法都进行了开源。OpenAI 的 Gym库是一个环境仿真库,里面包含很多现有的环境。
例子1:CartPole小车杆
import gym # 导入 Gym 的 Python 接口环境包
env = gym.make('CartPole-v0') # 构建实验环境
env.reset() # 重置一个回合
for _ in range(500):
env.render() # 显示图形界面
action = env.action_space.sample() # 从动作空间中随机选取一个动作
print(action)
observation, reward, done, info=env.step(action) # 用于提交动作,括号内是具体的动作
print(reward,observation)
env.close() # 关闭环境
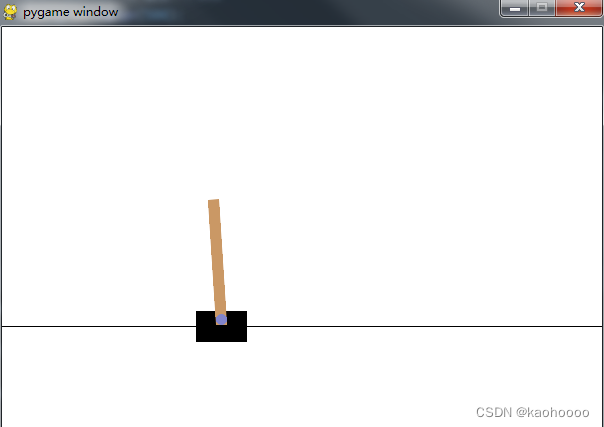
通过小车的运动,极力让杆保持在小车上的竖直,给予值为1的奖励,否则为0,当小车冲出界面时,奖励也为0。
输出action、reward、observation的值如下图所示。切忌不要直接关闭图形窗口,可能会造成死机,通过env.close()命令来关闭,等待迭代结束后自动关闭即可。

例子2:MountainCar小车上山
import gym
env = gym.make("MountainCar-v0")
class BespokeAgent:
def __init__(self, env):
pass
def decide(self, observation): # 决策
position, velocity = observation
lb = min(-0.09 * (position + 0.25) ** 2 + 0.03,
0.3 * (position + 0.9) ** 4 - 0.008)
ub = -0.07 * (position + 0.38) ** 2 + 0.07
if lb < velocity < ub:
action = 2
else:
action = 0
return action # 返回动作
def learn(self, *args): # 学习
pass
agent = BespokeAgent(env)
def play_montecarlo(env, agent, render=False, train=False):
episode_reward = 0. # 记录回合总奖励,初始化为0
observation = env.reset() # 重置游戏环境,开始新回合
while True: # 不断循环,直到回合结束
if render: # 判断是否显示
env.render() # 显示图形界面,图形界面可以用 env.close() 语句关闭
action = agent.decide(observation)
next_observation, reward, done, _ = env.step(action) # 执行动作
episode_reward += reward # 收集回合奖励
if train: # 判断是否训练智能体
agent.learn(observation, action, reward, done) # 学习
if done: # 回合结束,跳出循环
break
observation = next_observation
return episode_reward # 返回回合总奖励
env.seed(2) # 设置随机数种子,只是为了让结果可以精确复现,一般情况下可删去 指定环境下的随机数种子
episode_reward = play_montecarlo(env, agent, render=True)
print('回合奖励 = {}'.format(episode_reward))
env.close() # 此语句可关闭图形界面
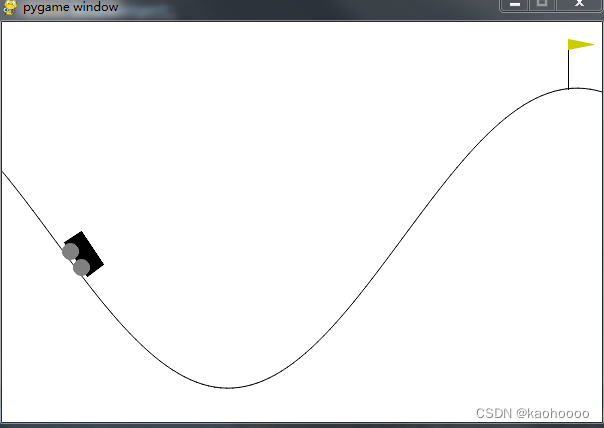
习题:
1-1强化学习的基本结构是什么?
本质上是智能体与环境的交互。具体而言就是智能体从环境中得到一个状态,基于此状态输出一个动作,环境根据动作给予相应的奖励,同时输出给智能体下一个状态。智能体的目标就是在环境中获得最大奖励。
1-2 强化学习相对于监督学习为什么训练过程会更加困难?
(1)强化学习处理的大多是序列数据,其很难像监督学习的样本一样满足独立同分布条件。
(2)强化学习有奖励的延迟,即智能体的动作作用在环境中时,环境对于智能体状态的奖励存在延迟,使得反馈不实时。
(3)监督学习有正确的标签,模型可以通过标签修正自己的预测来更新模型,而强化学习相当于一个“试错”的过程,其完全根据环境的“反馈”更新对自己最有利的动作。
1-3 强化学习的基本特征有哪些?
(1)有试错探索过程,即需要通过探索环境来获取对当前环境的理解。
(2)强化学习中的智能体会从环境中获得延迟奖励。
(3)强化学习的训练过程中时间非常重要,因为数据都是时间关联的,而不是像监督学习中的数据大部分是满足独立同分布的。
(4)强化学习中智能体的动作会影响它从环境中得到的反馈。
1-4 近几年强化学习发展迅速的原因有哪些?
(1)算力的提升使我们可以更快地通过试错等方法来使得智能体在环境里面获得更多的信息,从而取得更大的奖励。
(2)我们有了深度强化学习这样一个端到端的训练方法,可以把特征提取、价值估计以及决策部分一起优化,这样就可以得到一个更强的决策网络。
1-5 状态和观测有什么关系?
状态是对环境的完整描述,不会隐藏环境信息。观测是对状态的部分描述,可能会遗漏一些信息。在深度强化学习中,我们几乎总是用同一个实值向量、矩阵或者更高阶的张量来表示状态和观测。
1-6 一个强化学习智能体由什么组成?
(1)策略函数,智能体会用策略函数来选取它下一步的动作,策略包括随机性策略和确定性策略。
(2)价值函数,我们用价值函数来对当前状态进行评估,即进入现在的状态可以对后面的奖励带来多大的影响。价值函数的值越大,说明进入该状态越有利。
(3)模型,其表示智能体对当前环境状态的理解,它决定系统是如何运行的。
1-7 根据强化学习智能体的不同,我们可以将其分为哪几类?
(1)基于价值的智能体。显式学习的是价值函数,隐式地学习智能体的策略。因为这个策略是从学到的价值函数里面推算出来的。
(2)基于策略的智能体。其直接学习策略,即直接给智能体一个状态,它就会输出对应动作的概率。当然在基于策略的智能体里面并没有去学习智能体的价值函数。
(3)另外还有一种智能体,它把以上两者结合。把基于价值和基于策略的智能体结合起来就有了演员-评论员智能体。这一类智能体通过学习策略函数和价值函数以及两者的交互得到更佳的状态。
1-8 基于策略迭代和基于价值迭代的强化学习方法有什么区别?
(1)基于策略迭代的强化学习方法,智能体会制定一套动作策略,即确定在给定状态下需要采取何种动作,并根据该策略进行操作。强化学习算法直接对策略进行优化,使得制定的策略能够获得最大的奖励;基于价值迭代的强化学习方法,智能体不需要制定显式的策略,它维护一个价值表格或价值函数,并通过这个价值表格或价值函数来选取价值最大的动作。
(2)基于价值迭代的方法只能应用在离散的环境下,例如围棋或某些游戏领域,对于行为集合规模庞大或是动作连续的场景,如机器人控制领域,其很难学习到较好的结果(此时基于策略迭代的方法能够根据设定的策略来选择连续的动作)。
(3)基于价值迭代的强化学习算法有 Q-learning、Sarsa 等,基于策略迭代的强化学习算法有策略梯度算法等。
(4)此外,演员-评论员算法同时使用策略和价值评估来做出决策。其中,智能体会根据策略做出动作,而价值函数会对做出的动作给出价值,这样可以在原有的策略梯度算法的基础上加速学习过程,从而取得更好的效果。
1-9 有模型学习和免模型学习有什么区别?
针对是否需要对真实环境建模,强化学习可以分为有模型学习和免模型学习。有模型学习是指根据环境中的经验,构建一个虚拟世界,同时在真实环境和虚拟世界中学习;免模型学习是指不对环境进行建模,直接与真实环境进行交互来学习到最优策略。总体来说,有模型学习相比免模型学习仅仅多出一个步骤,即对真实环境进行建模。免模型学习通常属于数据驱动型方法,需要大量的采样来估计状态、动作及奖励函数,从而优化动作策略。免模型学习的泛化性要优于有模型学习,原因是有模型学习需要对真实环境进行建模,并且虚拟世界与真实环境之间可能还有差异,这限制了有模型学习算法的泛化性。
1-10 如何通俗理解强化学习?
环境和奖励函数不是我们可以控制的,两者是在开始学习之前就已经事先确定的。我们唯一能做的事情是调整策略,使得智能体可以在环境中得到最大的奖励。另外,策略决定了智能体的行为,策略就是给一个外界的输入,然后它会输出现在应该要执行的动作。
面试题:
1-1 友善的面试官: 看来你对于强化学习还是有一定了解的呀,那么可以用一句话谈一下你对于强化学习的认识吗?
强化学习包含环境、动作和奖励3部分,其本质是智能体通过与环境的交互,使其做出的动作对应的决策得到的总奖励最大,或者说是期望最大。
1-2 友善的面试官: 请问,你认为强化学习、监督学习和无监督学习三者有什么区别呢?
首先强化学习和无监督学习是不需要有标签样本的,而监督学习需要许多有标签样本来进行模型的构建和训练。其次对于强化学习与无监督学习,无监督学习直接基于给定的数据进行建模,寻找数据或特征中隐藏的结构,一般对应聚类问题;强化学习需要通过延迟奖励学习策略来得到模型与目标的距离,这个距离可以通过奖励函数进行定量判断,这里我们可以将奖励函数视为正确目标的一个稀疏、延迟形式。另外,强化学习处理的多是序列数据,样本之间通常具有强相关性,但其很难像监督学习的样本一样满足独立同分布条件。
1-3 友善的面试官: 根据你的理解,你认为强化学习的使用场景有哪些呢?
7个字总结就是“多序列决策问题”,或者说是对应的模型未知,需要通过学习逐渐逼近真实模型的问题。并且当前的动作会影响环境的状态,即具有马尔可夫性的问题。同时应满足所有状态是可重复到达的条件,即满足可学习条件。
1-4 友善的面试官: 请问强化学习中所谓的损失函数与深度学习中的损失函数有什么区别呢?
深度学习中的损失函数的目的是使预测值和真实值之间的差距尽可能小;(负反馈)
而强化学习中的损失函数的目的是使总奖励的期望尽可能大。(正反馈)
1-5 友善的面试官: 你了解有模型和免模型吗?两者具体有什么区别呢?
我认为两者的区别主要在于是否需要对真实的环境进行建模,免模型方法不需要对环境进行建模,直接与真实环境进行交互即可,所以其通常需要较多的数据或者采样工作来优化策略,这也使其对于真实环境具有更好的泛化性能;而有模型方法需要对环境进行建模,同时在真实环境与虚拟环境中进行学习,如果建模的环境与真实环境的差异较大,那么会限制其泛化性能。现在通常使用有模型方法进行模型的构建工作。















 9163
9163











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









