







Paper Reading Note
URL: https://zpascal.net/cvpr2017/Wang_Residual_Attention_Network_CVPR_2017_paper.pdf
TL;DR
该文章提出了一种残差注意力网络用于图像分类任务,在当时的多个分类数据集取得了SOTA结果。
Dataset/Algorithm/Model/Experiment Detail
数据集
使用的数据集包括CIFAR-10、CIFAR-100、IMAGENET三个经典分类任务数据集,其中CIFAR-10和CIFAR-100数据量偏少,IMAGENET代表这图像分类最大的数据集。
实现方式
-
attention效果展示图,可明显看出基于soft attention mask,在低层次的特征图中天空的噪声被滤除掉,高层次中的有效热气球特征得到加强

-
作者所提出的模型的整体架构,包含三个attention module,每个module包含mask(掩码)分支和trunk(主干)分支。

-
mask分支采用bottom-up加上top-down的方式来生成和trunk分支出来的特征图尺寸一致的mask,然后通过以下公式得到经过attention操作的输出
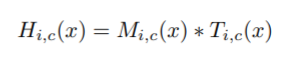
-
同时,作者认为mask分支在反向传播训练过程中对梯度的attention能够一定程度降低错误label所带来的影响
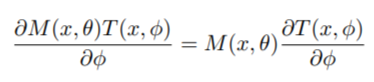
-
更详细看两个分支的结构,左边的mask分支其实就是生成一个掩码作用于右边主干分支提取的feature上

-
该方法比较重要的贡献就在于平常的用于attention的mask掩码往往经过sigmoid操作到0-1之间后不便于多个attention module进行叠加,这会导致feature map值越来越小,导致精度降低,而像以下引用resnet恒等映射的方式可以缓解这个问题
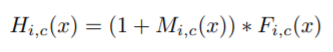
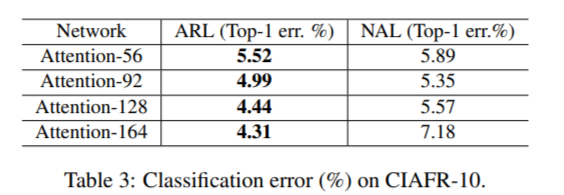
实验结果
- 在三个主要分类数据集上都取得了SOTA结果,同事随着attention module的层数不断增加,精度也不断提升


Thoughts
Attention机制在某种层面来看是符合人类大脑分析视觉信息时的方式,在基于attention的神经网络中,它使用顶部信息来指导自下而上的前馈过程。其实我们需要attention最希望能够看到的就是它能够滤出feature中不重要的噪声信息,同时加强feature中的有用信息,这篇文章就通过引入了mask branch 和trunk branch结合的方式达到了这个需求。同时它整合spatial attention和channel attention的方式也值得借鉴。但是如果进一步减低对于模型计算量的提升还需要进一步研究。















 1869
1869











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









