







Paper name
A Discriminative Feature Learning Approach for Deep Face Recognition
Paper Reading Note
URL: https://ydwen.github.io/papers/WenECCV16.pdf
TL;DR
该文章提出了center loss用于增强模型生成的人脸feature的可判别性,center loss与softmax loss共同监督训练模型可以使人脸识别精度有一定提升。
Introduction
- 在传统的基于深度卷积神经网络的分类任务中,如通用物体识别、场景识别、动作识别等,都是在训练集中就包含了所有需要测试的样本的类别,也就是说测试集中有的label在训练集中也会出现,在这种情况下,如下图所示,label prediction的过程可以看作是一个线性分类器,并且学习到的特征也通常是容易被分开的。但是在人脸识别任务中,基于softmax loss计算得到的feature仅仅是separable的,而需要下图所示的discriminative的feature则需要对loss function进行改进。作者提出了新的center loss来增加模型生成的feature的可判别性。

Dataset/Algorithm/Model/Experiment Detail
数据集
-
LFW
包含5749个id的13233张网络收集图片,经典人脸识别数据集。

-
YTF
包含1595个不同人的3425个视频,平均每个人有大约2.15段视频数据,视频的长度分布从48帧到6070帧,平均每个视频有181.3帧。

-
MegaFace
人脸识别领域最大的公开数据集之一,包含底库数据集(Gallery set)和待搜索数据集(Probe set)。底库数据集包含69万不同人的一百万张人脸图片,是雅虎Flickr photo数据集的一个子集。待搜索数据集中包含两个已存的公开数据集Facescrub和FGNet,其中Facescrub数据集包含530个不同人的十万张照片,其中55742张男性与52076张女性。另外FGNet数据集是人脸年龄数据集,包含82个人的1002张图片。

实现方式
-
center loss的提出:
其实这篇文章的创新点就是center loss的提出。作者首先在mnist数据集上做了简单的实验来测试基于softmax损失训练得到的特征的可辨别性,如下图所示,作者将模型输出的feature控制在两个维度,即可将不同类别的feature在二维空间上进行可视化, 可以看出不管是在训练集还是测试集上,不同类别在特征空间上仅仅是separable而不是discriminative enough,也就是说不同类别的样本在映射到特征空间上时类间距离不够明显,类内距离也不够紧凑。

作者因此想到使用center loss来对模型生成的feature做进一步约束。center loss的定义如下:
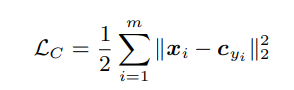
其中Cyi代表类别为yi的所有feature的中心,具体来说即在训练过程中对每个类别在minibatch尺度上统计出该类别feature的中心,希望所有feature离中心的距离都尽量小。
计算Lc对于xi的梯度的公式如下(3)式所示,就是简单求导;类别中心的更新距离方式如(4)所示,具体来说就是对于每个类别j,将j类别中心减去每个j类别feature的值取平均,以此作为类别中心更新的步进值:
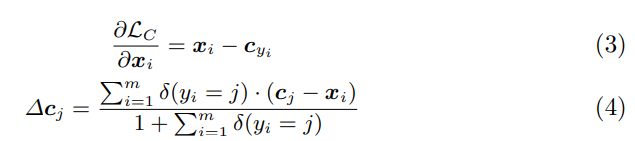
-
center loss 与softmax loss联合监督优化
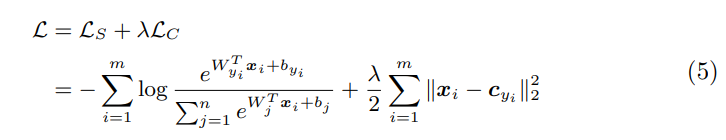
-
基于上述center loss的特征学习算法:

-
在之前所述的在mnist数据集上测试特征在空间上的可判别性试验中,加入了center loss后可明显增加样本在特征空间中的可判别性,如下图所示:

-
用于人脸识别训练的具体模型结构,其中后面三个卷积层使用local conv

实验结果
-
实验细节
作者使用了基于5点人脸关键点(人脸关键点检测和对齐方法,也是该论文作者的工作)给训练集中的人脸进行对齐,值得注意的是作者会在训练集中去除人脸关键点检测失败的图片(可能是通过卡置信度阈值?),但是在测试集中作者会选择使用已标注好的关键点。 -
LFW 和 YTF数据集上实验结果,取得了优异的成绩,比该论文结果高的使用了更多的训练数据集,比如说FaceNet。
- 其中model A是仅使用softmax loss
- model B是使用softmax loss加上contrastive loss
- model C是使用softmax loss加上centerloss

-
MegaFace数据集上的实验结果,取得了优异的效果



Thoughts
该论文思路很简单,就是发现了softmax loss存在的生成feature可判别力不强的情况所以提出了新的center loss用于进一步提升生成的feature的可判别性。其中在mnist数据集上做的实验可视化效果很好,这是在未来做实验中展示idea时可以借鉴的地方。















 449
449











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









