







资源
相关的Paper请看这两篇
Batch Normalization Accelerating Deep Network Training by Reducing Internal Covariate Shift
How Does Batch Normalization Help Optimization?
启发来源
BN不是凭空拍脑袋拍出来的好点子,它是有启发来源的:之前的研究表明如果在图像处理中对输入图像进行白化(Whiten)操作的话——所谓白化 , 就是对输入数据分布变换到0均值,单位方差的正态分布 ——那么神经网络会较快收敛,那么BN作者就开始推论了:图像是深度神经网络的输入层,做白化能加快收敛,那么其实对于深度网络来说,其中某个隐层的神经元是下一层的输入,意思是其实深度神经网络的每一个隐层都是输入层,不过是相对下一层来说而已,那么能不能对每个隐层都做白化呢?这就是启发BN产生的原初想法,而BN也确实就是这么做的,可以理解为对深层神经网络每个隐层神经元的激活值做简化版本的白化操作。
BatchNorm的本质思想
BN的基本思想其实相当直观:因为深层神经网络在做非线性变换前的激活输入值(就是那个x=WU+B,U是输入)随着网络深度加深或者在训练过程中,其分布逐渐发生偏移或者变动,之所以训练收敛慢,一般是整体分布逐渐往非线性函数的取值区间的上下限两端靠近(对于Sigmoid函数来说,意味着激活输入值WU+B是大的负值或正值),所以这导致反向传播时低层神经网络的梯度消失,这是训练深层神经网络收敛越来越慢的本质原因,而BN就是通过一定的规范化手段,把每层神经网络任意神经元这个输入值的分布强行拉回到均值为0方差为1的标准正态分布,其实就是把越来越偏的分布强制拉回比较标准的分布,这样使得激活输入值落在非线性函数对输入比较敏感的区域,这样输入的小变化就会导致损失函数较大的变化,意思是这样让梯度变大,避免梯度消失问题产生,而且梯度变大意味着学习收敛速度快,能大大加快训练速度。
THAT’S IT。其实一句话就是:对于每个隐层神经元,把逐渐向非线性函数映射后向取值区间极限饱和区靠拢的输入分布强制拉回到均值为0方差为1的比较标准的正态分布,使得非线性变换函数的输入值落入对输入比较敏感的区域,以此避免梯度消失问题。因为梯度一直都能保持比较大的状态,所以很明显对神经网络的参数调整效率比较高,就是变动大,就是说向损失函数最优值迈动的步子大,也就是说收敛地快。BN说到底就是这么个机制,方法很简单,道理很深刻。
上面说得还是显得抽象,下面更形象地表达下这种调整到底代表什么含义。

假设某个隐层神经元原先的激活输入x取值符合正态分布,正态分布均值是-2,方差是0.5,对应上图中最左端的浅蓝色曲线,通过BN后转换为均值为0,方差是1的正态分布(对应上图中的深蓝色图形),意味着什么,意味着输入x的取值正态分布整体右移2(均值的变化),图形曲线更平缓了(方差增大的变化)。这个图的意思是,BN其实就是把每个隐层神经元的激活输入分布从偏离均值为0方差为1的正态分布通过平移均值压缩或者扩大曲线尖锐程度,调整为均值为0方差为1的正态分布。
那么把激活输入x调整到这个正态分布有什么用?首先我们看下均值为0,方差为1的标准正态分布代表什么含义:

这意味着在一个标准差范围内,也就是说64%的概率x其值落在[-1,1]的范围内,在两个标准差范围内,也就是说95%的概率x其值落在了[-2,2]的范围内。那么这又意味着什么?我们知道,激活值x=WU+B,U是真正的输入,x是某个神经元的激活值,假设非线性函数是sigmoid,那么看下sigmoid(x)其图形:

及sigmoid(x)的导数为:G’=f(x)*(1-f(x)),因为f(x)=sigmoid(x)在0到1之间,所以G’在0到0.25之间**,其对应的图如下:

假设没有经过BN调整前x的原先正态分布均值是-6,方差是1,那么意味着95%的值落在了[-8,-4]之间,那么对应的Sigmoid(x)函数的值明显接近于0,这是典型的梯度饱和区,在这个区域里梯度变化很慢,为什么是梯度饱和区?请看下sigmoid(x)如果取值接近0或者接近于1的时候对应导数函数取值,接近于0,意味着梯度变化很小甚至消失。而假设经过BN后,均值是0,方差是1,那么意味着95%的x值落在了[-2,2]区间内,很明显这一段是sigmoid(x)函数接近于线性变换的区域,意味着x的小变化会导致非线性函数值较大的变化,也即是梯度变化较大,对应导数函数图中明显大于0的区域,就是梯度非饱和区。
从上面几个图应该看出来BN在干什么了吧?其实就是把隐层神经元激活输入x=WU+B从变化不拘一格的正态分布通过BN操作拉回到了均值为0,方差为1的正态分布,即原始正态分布中心左移或者右移到以0为均值,拉伸或者缩减形态形成以1为方差的图形。什么意思?就是说经过BN后,目前大部分Activation的值落入非线性函数的线性区内,其对应的导数远离导数饱和区,这样来加速训练收敛过程。
但是很明显,看到这里,稍微了解神经网络的读者一般会提出一个疑问:如果都通过BN,那么不就跟把非线性函数替换成线性函数效果相同了?这意味着什么?我们知道,如果是多层的线性函数变换其实这个深层是没有意义的,因为多层线性网络跟一层线性网络是等价的。这意味着网络的表达能力下降了,这也意味着深度的意义就没有了。所以BN为了保证非线性的获得,对变换后的满足均值为0方差为1的x又进行了scale加上shift操作(y=scale*x+shift),每个神经元增加了两个参数scale和shift参数,这两个参数是通过训练学习到的,意思是通过scale和shift把这个值从标准正态分布左移或者右移一点并长胖一点或者变瘦一点,每个实例挪动的程度不一样,这样等价于非线性函数的值从正中心周围的线性区往非线性区动了动。核心思想应该是想找到一个线性和非线性的较好平衡点,既能享受非线性的较强表达能力的好处,又避免太靠非线性区两头使得网络收敛速度太慢**。当然,这是我的理解,论文作者并未明确这样说。但是很明显这里的scale和shift操作是会有争议的,因为按照论文作者论文里写的理想状态,就会又通过scale和shift操作把变换后的x调整回未变换的状态,那不是饶了一圈又绕回去原始的“Internal Covariate Shift”问题里去了吗,感觉论文作者并未能够清楚地解释scale和shift操作的理论原因。
训练阶段如何做BatchNorm
上面是对BN的抽象分析和解释,具体在Mini-Batch SGD下做BN怎么做?其实论文里面这块写得很清楚也容易理解。为了保证这篇文章完整性,这里简单说明下。
假设对于一个深层神经网络来说,其中两层结构如下:

要对每个隐层神经元的激活值做BN,可以想象成每个隐层又加上了一层BN操作层,它位于X=WU+B激活值获得之后,非线性函数变换之前,其图示如下:

对于Mini-Batch SGD来说,一次训练过程里面包含m个训练实例,其具体BN操作就是对于隐层内每个神经元的激活值来说,进行如下变换:
E 期望, Var 是方差
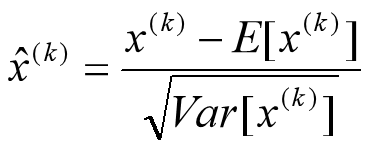
要注意,这里t层某个神经元的x(k)不是指原始输入,就是说不是t-1层每个神经元的输出,而是t层这个神经元的线性激活x=WU+B,这里的U才是t-1层神经元的输出。变换的意思是:某个神经元对应的原始的激活x通过减去mini-Batch内m个实例获得的m个激活x求得的均值E(x)并除以求得的方差Var(x)来进行转换。
上文说过经过这个变换后某个神经元的激活x形成了均值为0,方差为1的正态分布,目的是把值往后续要进行的非线性变换的线性区拉动,增大导数值,增强反向传播信息流动性,加快训练收敛速度。但是这样会导致网络表达能力下降,为了防止这一点,每个神经元增加两个调节参数(scale和shift),这两个参数是通过训练来学习到的,用来对变换后的激活反变换,使得网络表达能力增强,即对变换后的激活进行如下的scale和shift操作,这其实是变换的反操作:
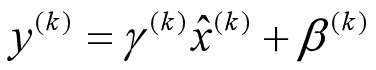
BN其具体操作流程,如论文中描述的一样:

过程非常清楚,就是上述公式的流程化描述,这里不解释了,直接应该能看懂。
BatchNorm的推理(Inference)过程
BN在训练的时候可以根据Mini-Batch里的若干训练实例进行激活数值调整,但是在推理(inference)的过程中,很明显输入就只有一个实例,看不到Mini-Batch其它实例,那么这时候怎么对输入做BN呢?因为很明显一个实例是没法算实例集合求出的均值和方差的。这可如何是好?
既然没有从Mini-Batch数据里可以得到的统计量,那就想其它办法来获得这个统计量,就是均值和方差。可以用从所有训练实例中获得的统计量来代替Mini-Batch里面m个训练实例获得的均值和方差统计量,因为本来就打算用全局的统计量,只是因为计算量等太大所以才会用Mini-Batch这种简化方式的,那么在推理的时候直接用全局统计量即可。
决定了获得统计量的数据范围,那么接下来的问题是如何获得均值和方差的问题。很简单,因为每次做Mini-Batch训练时,都会有那个Mini-Batch里m个训练实例获得的均值和方差,现在要全局统计量,只要把每个Mini-Batch的均值和方差统计量记住,然后对这些均值和方差求其对应的数学期望即可得出全局统计量,即:
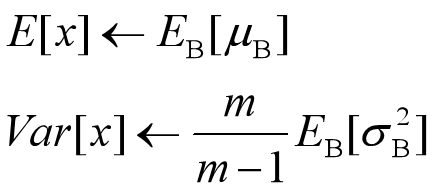
有了均值和方差,每个隐层神经元也已经有对应训练好的Scaling参数和Shift参数,就可以在推导的时候对每个神经元的激活数据计算NB进行变换了,在推理过程中进行BN采取如下方式:
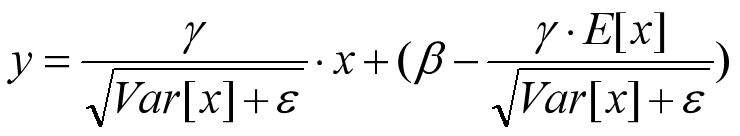
这个公式其实和训练时
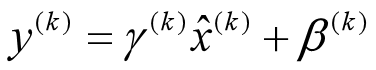
是等价的,通过简单的合并计算推导就可以得出这个结论。那么为啥要写成这个变换形式呢?我猜作者这么写的意思是:在实际运行的时候,按照这种变体形式可以减少计算量,为啥呢?因为对于每个隐层节点来说:
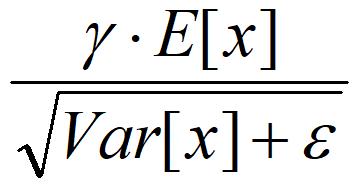
都是固定值,这样这两个值可以事先算好存起来,在推理的时候直接用就行了,这样比原始的公式每一步骤都现算少了除法的运算过程,乍一看也没少多少计算量,但是如果隐层节点个数多的话节省的计算量就比较多了。
BatchNorm的好处
BatchNorm为什么NB呢,关键还是效果好。①不仅仅极大提升了训练速度,收敛过程大大加快;②还能增加分类效果,一种解释是这是类似于Dropout的一种防止过拟合的正则化表达方式,所以不用Dropout也能达到相当的效果;③另外调参过程也简单多了,对于初始化要求没那么高,而且可以使用大的学习率等。总而言之,经过这么简单的变换,带来的好处多得很,这也是为何现在BN这么快流行起来的原因。
What is BN
Normalization是数据标准化(归一化,规范化),Batch 可以理解为批量,加起来就是批量标准化。
先说Batch是怎么确定的。在CNN中,Batch就是训练网络所设定的图片数量batch_size。
Normalization过程,引用论文中的解释:

输入:输入数据x1…xm(这些数据是准备进入激活函数的数据)
计算过程中可以看到,
1.求数据均值;
2.求数据方差;
3.数据进行标准化(个人认为称作正态化也可以)
4.训练参数γ,β
5.输出y通过γ与β的线性变换得到新的值
在正向传播的时候,通过可学习的γ与β参数求出新的分布值
在反向传播的时候,通过链式求导方式,求出γ与β以及相关权值

Why is BN
解决的问题是梯度消失与梯度爆炸。
关于梯度消失,以sigmoid函数为例子,sigmoid函数使得输出在[0,1]之间。
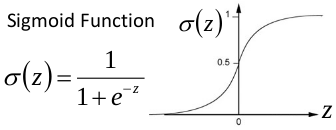
事实上x到了一定大小,经过sigmoid函数的输出范围就很小了,参考下图
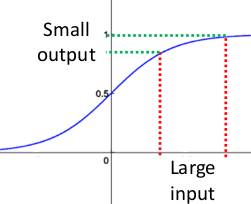
如果输入很大,其对应的斜率就很小,我们知道,其斜率(梯度)在反向传播中是权值学习速率。所以就会出现如下的问题,

在深度网络中,如果网络的激活输出很大,其梯度就很小,学习速率就很慢。假设每层学习梯度都小于最大值0.25,网络有n层,因为链式求导的原因,第一层的梯度小于0.25的n次方,所以学习速率就慢,对于最后一层只需对自身求导1次,梯度就大,学习速率就快。
这会造成的影响是在一个很大的深度网络中,浅层基本不学习,权值变化小,后面几层一直在学习,结果就是,后面几层基本可以表示整个网络,失去了深度的意义。
关于梯度爆炸,根据链式求导法,
第一层偏移量的梯度=激活层斜率1x权值1x激活层斜率2x…激活层斜率(n-1)x权值(n-1)x激活层斜率n
假如激活层斜率均为最大值0.25,所有层的权值为100,这样梯度就会指数增加。
How to use BN
先解释一下对于图片卷积是如何使用BN层。

这是文章卷积神经网络CNN(1)中5x5的图片通过valid卷积得到的3x3特征图(粉红色)。特征图里的值,作为BN的输入,也就是这9个数值通过BN计算并保存γ与β,通过γ与β使得输出与输入不变。假设输入的batch_size为m,那就有m9个数值,计算这m9个数据的γ与β并保存。正向传播过程如上述,对于反向传播就是根据求得的γ与β计算梯度。
这里需要着重说明2个细节:
1.网络训练中以batch_size为最小单位不断迭代,很显然,新的batch_size进入网络,机会有新的γ与β,因此,在BN层中,有总图片数/batch_size组γ与β被保存下来。
2.图像卷积的过程中,通常是使用多个卷积核,得到多张特征图,对于多个的卷积核需要保存多个的γ与β。
结合论文中给出的使用过程进行解释

输入:待进入激活函数的变量
输出:
1.对于K维的输入,假设每一维包含m个变量,所以需要K个循环。每个循环中按照上面所介绍的方法计算γ与β。这里的K维,在卷积网络中可以看作是卷积核个数,如网络中第n层有64个卷积核,就需要计算64次。
需要注意,在正向传播时,会使用γ与β使得BN层输出与输入一样。
2.在反向传播时利用γ与β求得梯度从而改变训练权值(变量)。
3.通过不断迭代直到训练结束,求得关于不同层的γ与β。如网络有n个BN层,每层根据batch_size决定有多少个变量,设定为m,这里的mini-batcherB指的是特征图大小batch_size,即m=特征图大小batch_size,因此,对于batch_size为1,这里的m就是每层特征图的大小。
4.不断遍历训练集中的图片,取出每个batch_size中的γ与β,最后统计每层BN的γ与β各自的和除以图片数量得到平均直,并对其做无偏估计直作为每一层的E[x]与Var[x]。
5.在预测的正向传播时,对测试数据求取γ与β,并使用该层的E[x]与Var[x],通过图中11:所表示的公式计算BN层输出。
注意,在预测时,BN层的输出已经被改变,所以BN层在预测的作用体现在此处
def batch_norm(X, gamma, beta, moving_mean, moving_var, eps, momentum):
# 通过 autograd 来判断当前模式为训练模式或预测模式。
if not autograd.is_training():
# 如果是在预测模式下,直接使用传入的移动平均所得的均值和方差。
X_hat = (X - moving_mean) / nd.sqrt(moving_var + eps)
else:
assert len(X.shape) in (2, 4)
if len(X.shape) == 2:
# 使用全连接层的情况,计算特征维上的均值和方差。
mean = X.mean(axis=0)
var = ((X - mean) ** 2).mean(axis=0)
else:
# 使用二维卷积层的情况,计算通道维上(axis=1)的均值和方差。这里我们需要
# 保持 X 的形状以便后面可以做广播运算。
mean = X.mean(axis=(0, 2, 3), keepdims=True)
var = ((X - mean) ** 2).mean(axis=(0, 2, 3), keepdims=True)
# 训练模式下用当前的均值和方差做标准化。
X_hat = (X - mean) / nd.sqrt(var + eps)
# 更新移动平均的均值和方差。
# 应用指数加权平均(Exponentially weighted average)的方法近似计算平均值
moving_mean = momentum * moving_mean + (1.0 - momentum) * mean
moving_var = momentum * moving_var + (1.0 - momentum) * var
Y = gamma * X_hat + beta # 拉升和偏移。
return Y, moving_mean, moving_var
TensorFlow相关函数
1.tf.nn.moments(x, axes, shift=None, name=None, keep_dims=False)
x是输入张量,axes是在哪个维度上求解, 即想要 normalize的维度, [0] 代表 batch 维度,如果是图像数据,可以传入 [0, 1, 2],相当于求[batch, height, width] 的均值/方差,注意不要加入channel 维度。该函数返回两个张量,均值mean和方差variance。
2.tf.identity(input, name=None)
返回与输入张量input形状和内容一致的张量。
3.tf.nn.batch_normalization(x, mean, variance, offset, scale, variance_epsilon,name=None)
计算公式为scale(x - mean)/ variance + offset。
这些参数中,tf.nn.moments可得到均值mean和方差variance,offset和scale是可训练的,offset一般初始化为0,scale初始化为1,offset和scale的shape与mean相同,variance_epsilon参数设为一个很小的值如0.001。
TensorFlow代码实现
- 完整代码
"""
visit https://morvanzhou.github.io/tutorials/ for more!
Build two networks.
1. Without batch normalization
2. With batch normalization
Run tests on these two networks.
"""
#https://morvanzhou.github.io/tutorials/machine-learning/tensorflow/
# 23 Batch Normalization
import numpy as np
import tensorflow as tf
import matplotlib.pyplot as plt
ACTIVATION = tf.nn.relu
N_LAYERS = 7
N_HIDDEN_UNITS = 30
def fix_seed(seed=1):
# reproducible
np.random.seed(seed)
tf.set_random_seed(seed)
def plot_his(inputs, inputs_norm):
# plot histogram for the inputs of every layer
for j, all_inputs in enumerate([inputs, inputs_norm]):
for i, input in enumerate(all_inputs):
plt.subplot(2, len(all_inputs), j*len(all_inputs)+(i+1))
plt.cla()
if i == 0:
the_range = (-7, 10)
else:
the_range = (-1, 1)
plt.hist(input.ravel(), bins=15, range=the_range, color='#FF5733')
plt.yticks(())
if j == 1:
plt.xticks(the_range)
else:
plt.xticks(())
ax = plt.gca()
ax.spines['right'].set_color('none')
ax.spines['top'].set_color('none')
plt.title("%s normalizing" % ("Without" if j == 0 else "With"))
plt.draw()
plt.pause(0.01)
def built_net(xs, ys, norm):
def add_layer(inputs, in_size, out_size, activation_function=None, norm=False):
# weights and biases (bad initialization for this case)
Weights = tf.Variable(tf.random_normal([in_size, out_size], mean=0., stddev=1.))
biases = tf.Variable(tf.zeros([1, out_size]) + 0.1)
# fully connected product
Wx_plus_b = tf.matmul(inputs, Weights) + biases
# normalize fully connected product
if norm:
# Batch Normalize
fc_mean, fc_var = tf.nn.moments(
Wx_plus_b,
axes=[0], # the dimension you wanna normalize, here [0] for batch
# for image, you wanna do [0, 1, 2] for [batch, height, width] but not channel
)
scale = tf.Variable(tf.ones([out_size]))
shift = tf.Variable(tf.zeros([out_size]))
epsilon = 0.001
# apply moving average for mean and var when train on batch
ema = tf.train.ExponentialMovingAverage(decay=0.5)
def mean_var_with_update():
ema_apply_op = ema.apply([fc_mean, fc_var])
with tf.control_dependencies([ema_apply_op]):
return tf.identity(fc_mean), tf.identity(fc_var)
mean, var = mean_var_with_update()
Wx_plus_b = tf.nn.batch_normalization(Wx_plus_b, mean, var, shift, scale, epsilon)
# similar with this two steps:
# Wx_plus_b = (Wx_plus_b - fc_mean) / tf.sqrt(fc_var + 0.001)
# Wx_plus_b = Wx_plus_b * scale + shift
# activation
if activation_function is None:
outputs = Wx_plus_b
else:
outputs = activation_function(Wx_plus_b)
return outputs
fix_seed(1)
if norm:
# BN for the first input
fc_mean, fc_var = tf.nn.moments(
xs,
axes=[0],
)
scale = tf.Variable(tf.ones([1]))
shift = tf.Variable(tf.zeros([1]))
epsilon = 0.001
# apply moving average for mean and var when train on batch
ema = tf.train.ExponentialMovingAverage(decay=0.5)
def mean_var_with_update():
ema_apply_op = ema.apply([fc_mean, fc_var])
with tf.control_dependencies([ema_apply_op]):
return tf.identity(fc_mean), tf.identity(fc_var)
mean, var = mean_var_with_update()
xs = tf.nn.batch_normalization(xs, mean, var, shift, scale, epsilon)
# record inputs for every layer
layers_inputs = [xs]
# build hidden layers
for l_n in range(N_LAYERS):
layer_input = layers_inputs[l_n]
in_size = layers_inputs[l_n].get_shape()[1].value
output = add_layer(
layer_input, # input
in_size, # input size
N_HIDDEN_UNITS, # output size
ACTIVATION, # activation function
norm, # normalize before activation
)
layers_inputs.append(output) # add output for next run
# build output layer
prediction = add_layer(layers_inputs[-1], 30, 1, activation_function=None)
cost = tf.reduce_mean(tf.reduce_sum(tf.square(ys - prediction), reduction_indices=[1]))
train_op = tf.train.GradientDescentOptimizer(0.001).minimize(cost)
return [train_op, cost, layers_inputs]
# make up data
fix_seed(1)
x_data = np.linspace(-7, 10, 2500)[:, np.newaxis]
np.random.shuffle(x_data)
noise = np.random.normal(0, 8, x_data.shape)
y_data = np.square(x_data) - 5 + noise
# plot input data
plt.scatter(x_data, y_data)
plt.show()
xs = tf.placeholder(tf.float32, [None, 1]) # [num_samples, num_features]
ys = tf.placeholder(tf.float32, [None, 1])
train_op, cost, layers_inputs = built_net(xs, ys, norm=False) # without BN
train_op_norm, cost_norm, layers_inputs_norm = built_net(xs, ys, norm=True) # with BN
sess = tf.Session()
if int((tf.__version__).split('.')[1]) < 12 and int((tf.__version__).split('.')[0]) < 1:
init = tf.initialize_all_variables()
else:
init = tf.global_variables_initializer()
sess.run(init)
# record cost
cost_his = []
cost_his_norm = []
record_step = 5
plt.ion()
plt.figure(figsize=(7, 3))
for i in range(250):
if i % 50 == 0:
# plot histogram
all_inputs, all_inputs_norm = sess.run([layers_inputs, layers_inputs_norm], feed_dict={xs: x_data, ys: y_data})
plot_his(all_inputs, all_inputs_norm)
# train on batch
sess.run([train_op, train_op_norm], feed_dict={xs: x_data[i*10:i*10+10], ys: y_data[i*10:i*10+10]})
if i % record_step == 0:
# record cost
cost_his.append(sess.run(cost, feed_dict={xs: x_data, ys: y_data}))
cost_his_norm.append(sess.run(cost_norm, feed_dict={xs: x_data, ys: y_data}))
plt.ioff()
plt.figure()
plt.plot(np.arange(len(cost_his))*record_step, np.array(cost_his), label='no BN') # no norm
plt.plot(np.arange(len(cost_his))*record_step, np.array(cost_his_norm), label='BN') # norm
plt.legend()
plt.show()
运行结果


参考资料
https://www.cnblogs.com/guoyaohua/p/8724433.html
https://blog.csdn.net/zqnnn/article/details/88106591
https://www.jianshu.com/p/a78470f521dd
https://www.cnblogs.com/ranjiewen/articles/7748232.html
全面解读Group Normalization,对比BN,LN,IN















 5396
5396











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











