







思路:
给定带有标签的训练样本集,我们想要测试一个类别位置的样本,将该未知样本的属性特征与训练样本集中数据对应的特征进行比较,然后提取出其中k个最相似的样本,统计这k个样本中的类标情况,出现次数最多的类别就是未知样本的类别。关键是如何度量未知样本与训练样本集中的样本的相似性,便于理解可以采用欧式距离的方法。
伪代码:

优点:能进行多分类,对异常值不敏感,计算简单,没有训练过程。
缺点:计算复杂度和空间复杂度较高。
代码:
#
#
#kNN测试
#param:测试向量,数据集,类标,近邻个数
def classify0(inX, dataSet, labels, k):
dataSetSize = dataSet.shape[0]
#构造和数据集相同维度大小的列表
diffMat = tile(inX, (dataSetSize,1)) - dataSet
#计算欧式距离
sqDiffMat = diffMat**2
#按照行统计和
sqDistances = sqDiffMat.sum(axis=1)
distances = sqDistances**0.5
#获得排序后的索引
sortedDistIndicies = distances.argsort()
classCount={}
#k个近邻和对应的类标的统计
for i in range(k):
voteIlabel = labels[sortedDistIndicies[i]]
classCount[voteIlabel] = classCount.get(voteIlabel,0) + 1
sortedClassCount = sorted(classCount.iteritems(), key=operator.itemgetter(1), reverse=True)
return sortedClassCount[0][0]数据的归一化处理
通常由于不同的属性的取值范围不一样,为了避免在程序中计算时数量级之间差异导致的各属性之间的权重的差异性,一般都要讲数据进行归一化的处理,可以将任意取值范围的特征值转化到0到1区间内的值。
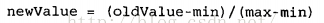
#
#归一化数据集
#param:数据集
def autoNorm(dataSet):
#每一列的最小和最大值
minVals = dataSet.min(0)
maxVals = dataSet.max(0)
ranges = maxVals - minVals
normDataSet = zeros(shape(dataSet))
m = dataSet.shape[0]
#利用tile函数扩展到和数据集相同的维度
normDataSet = dataSet - tile(minVals, (m,1))
normDataSet = normDataSet/tile(ranges, (m,1)) #element wise divide
return normDataSet, ranges, minVals统计错误率
#
#
#测试KNN的分类准确率-基于约会网站的数据集
#param:
def datingClassTest():
#测试数据占的比例,前面的比例作为测试
hoRatio = 0.10
datingDataMat,datingLabels = file2matrix('datingTestSet2.txt')
normMat, ranges, minVals = autoNorm(datingDataMat)
m = normMat.shape[0]
#测试数据的个数
numTestVecs = int(m*hoRatio)
errorCount = 0.0
for i in range(numTestVecs):
classifierResult = classify0(normMat[i,:],normMat[numTestVecs:m,:],datingLabels[numTestVecs:m],3)
#print "the classifier came back with: %d, the real answer is: %d" % (classifierResult, datingLabels[i])
if (classifierResult != datingLabels[i]): errorCount += 1.0
print "the total error rate is: %f" % (errorCount/float(numTestVecs))
print errorCount关于约会网站和手写识别系统的完整代码:
#-*- coding:utf-8 -*-
#
#
from numpy import *
import operator
from os import listdir
#
#
#构造简单的数据集
#
def createDataSet():
group = array([[1.0,1.1],[1.0,1.0],[0,0],[0,0.1]])
labels = ['A','A','B','B']
return group, labels
#
#
#kNN测试
#param:测试向量,数据集,类标,近邻个数
def classify0(inX, dataSet, labels, k):
dataSetSize = dataSet.shape[0]
#构造和数据集相同维度大小的列表
diffMat = tile(inX, (dataSetSize,1)) - dataSet
#计算欧式距离
sqDiffMat = diffMat**2
#按照行统计和
sqDistances = sqDiffMat.sum(axis=1)
distances = sqDistances**0.5
#获得排序后的索引
sortedDistIndicies = distances.argsort()
classCount={}
#k个近邻和对应的类标的统计
for i in range(k):
voteIlabel = labels[sortedDistIndicies[i]]
classCount[voteIlabel] = classCount.get(voteIlabel,0) + 1
sortedClassCount = sorted(classCount.iteritems(), key=operator.itemgetter(1), reverse=True)
return sortedClassCount[0][0]
#
#
#简单测试KNN
#
def ceshi1():
data, label=createDataSet()
result=classify0(array([0.1,0]),data,label,2)
print result
#
#
#加载数据集
#param:文件名
def file2matrix(filename):
fr = open(filename)
numberOfLines = len(fr.readlines())
returnMat = zeros((numberOfLines,3))
classLabelVector = []
fr = open(filename)
index = 0
for line in fr.readlines():
#分割每一行和每一个元组
line = line.strip()
listFromLine = line.split('\t')
returnMat[index,:] = listFromLine[0:3]
classLabelVector.append(int(listFromLine[-1]))
index += 1
return returnMat,classLabelVector
#
#
#归一化数据集
#param:数据集
def autoNorm(dataSet):
#每一列的最小和最大值
minVals = dataSet.min(0)
maxVals = dataSet.max(0)
ranges = maxVals - minVals
normDataSet = zeros(shape(dataSet))
m = dataSet.shape[0]
#利用tile函数扩展到和数据集相同的维度
normDataSet = dataSet - tile(minVals, (m,1))
normDataSet = normDataSet/tile(ranges, (m,1)) #element wise divide
return normDataSet, ranges, minVals
#
#
#查看数据集的正规化结果
#param:
def ceshi2():
data, label=file2matrix("datingTestSet2.txt")
normDataSet, ranges, minVals=autoNorm(data)
print normDataSet[0:10,:]
#
#
#测试KNN的分类准确率-基于约会网站的数据集
#param:
def datingClassTest():
#测试数据占的比例,前面的比例作为测试
hoRatio = 0.10
datingDataMat,datingLabels = file2matrix('datingTestSet2.txt')
normMat, ranges, minVals = autoNorm(datingDataMat)
m = normMat.shape[0]
#测试数据的个数
numTestVecs = int(m*hoRatio)
errorCount = 0.0
for i in range(numTestVecs):
classifierResult = classify0(normMat[i,:],normMat[numTestVecs:m,:],datingLabels[numTestVecs:m],3)
#print "the classifier came back with: %d, the real answer is: %d" % (classifierResult, datingLabels[i])
if (classifierResult != datingLabels[i]): errorCount += 1.0
print "the total error rate is: %f" % (errorCount/float(numTestVecs))
print errorCount
#
#
#将数字图像文本转化成特征向量
#param:图像名
def img2vector(filename):
returnVect = zeros((1,1024))
fr = open(filename)
for i in range(32):
lineStr = fr.readline()
for j in range(32):
returnVect[0,32*i+j] = int(lineStr[j])
return returnVect
#
#
#测试手写体数字分类
#param:
def handwritingClassTest():
#加载数据集
hwLabels = []
trainingFileList = listdir('trainingDigits')
m = len(trainingFileList)
trainingMat = zeros((m,1024))
for i in range(m):
fileNameStr = trainingFileList[i]
fileStr = fileNameStr.split('.')[0]
#分割出类标 1_11.txt,最前面的代码数字类别
classNumStr = int(fileStr.split('_')[0])
hwLabels.append(classNumStr)
trainingMat[i,:] = img2vector('trainingDigits/%s' % fileNameStr)
#加载测试集
testFileList = listdir('testDigits')
errorCount = 0.0
mTest = len(testFileList)
for i in range(mTest):
fileNameStr = testFileList[i]
fileStr = fileNameStr.split('.')[0]
classNumStr = int(fileStr.split('_')[0])
vectorUnderTest = img2vector('testDigits/%s' % fileNameStr)
classifierResult = classify0(vectorUnderTest, trainingMat, hwLabels, 3)
#print "the classifier came back with: %d, the real answer is: %d" % (classifierResult, classNumStr)
if (classifierResult != classNumStr): errorCount += 1.0
print "\nthe total number of errors is: %d" % errorCount
print "\nthe total error rate is: %f" % (errorCount/float(mTest))
#
#handwritingClassTest()
















 392
392

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









