







 https://www.bilibili.com/video/BV1Vf4y1P7pq
https://www.bilibili.com/video/BV1Vf4y1P7pq强烈推荐这个课程,老师讲得太好了,无论是小白还是熟手都适合学习。
g++编译文件
1、编译 hello.cpp 文件:
g++ hello.cpp2、使用 c++11:
g++ hello.cpp --std=c++113、编译默认生成文件名为:a.out,自定义生成文件名:
g++ hello.cpp --std=c++11 -o hello4、运行生成的文件:
./hello编译和链接

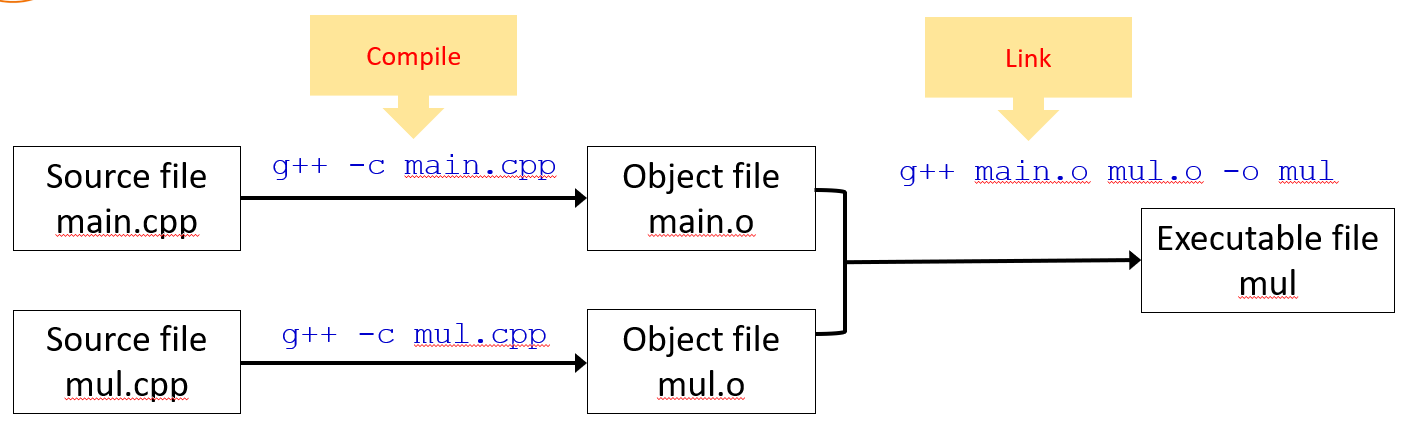
注:g++ 的 -c 选项表示只编译不链接。
程序预处理
预处理指令是以“#”开头的指令。
编译之前先由预处理器处理。
char(8位)
c++标准并没有规定char(-128~127)表示unsigned char(0~255)还是signed char。不同平台不一样。
从c++11开始增加了 char16_t(16位的char)、char32_t(32位的char) 类型。
浮点数
#include <iostream>
#include <iomanip>
using namespace std;
int main(int argc, char *argv[])
{
float f1 = 1.2f;
float f2 = f1 * 1000000000000000; //1.0e15
cout << std::fixed << std::setprecision(15) << f1 << endl;
cout << std::fixed << std::setprecision(15) << f2 << endl;
}这段代码是输出:

原因在于小数是无限的,计算机表示数据有位数限制。写一个很长的小数,计算机不一定能表示出来。所以计算机表示浮点数的时候进行了采样。比如上面要表示一个15位有效数字的1.2,得到的是计算机在那段范围进行了采样后的结果。
int main(int argc, char *argv[])
{
float f1 = 2.34E+10f;
float f2 = f1 + 10; // but f2 = f1
cout << std::fixed << std::setprecision(15) << f1 << endl;
cout << std::fixed << std::setprecision(15) << f2 << endl;
} 
这段代码,一个很大的浮点数加上一个比较小的数10得到的结果不变,原因和上面一样,加上10后采样得到值还是原来的值。
所以两个浮点数比较大小时,只要它们的差值很小就认为相等。
#include <stdio.h>
#include<math.h>
#define EPS 1e-7 //判断浮点数是否位于0的一个很小的邻域内[-EPS,EPS]内
main()
{
/*判断一个浮点数是否等于0*/
float a;
scanf("%f",&a);
if(fabs(a) <= EPS) //a=0
...
else if(a > EPS) //a>0
...
else //a<0
...
/*比较两个浮点数大小*/
float a,b;
scanf("%f%f",&a,&b);
if(fabs(a-b) <= EPS) //a=b
...
else if((a-b) > EPS) //a>b
...
else //a<b
...
}double 类型的数据操作比 float 更慢。
除法
float f = 17 / 5; //整数除法,结果是整数3,再转成float类型 3.f
float f = 17 / 5.f; //有一个操作数是浮点数,是浮点数除法,实际上是 17.f / 5.f,结果是3.4f加法
uchar a = 255;
uchar b = 1;
int c = a + b; // c = 256,而不是0,因为256无法用uchar表示,a和b会转成int再相加老师的金句之一
c和c++的编译器、语法假定程序员非常熟悉计算机底层原理,假设程序员足够聪明,假定程序员真正知道每一行代码的意思。如果你不知道,那可能导致结果不是你想要的,这也是c和c++编程非常容易出错的原因。所以建议程序员对每一个操作、每一个符号都要深刻理解它到底做了什么。如果深刻理解了那么你的程序就会变得稳定很多、很少出错了。
赋值表达式的值
if(int * p = get())
{
}赋值表达式的值是等号右边的内容。
goto 语句的建议使用场景
在函数的末尾进行错误处理、清理等操作。当程序出错时跳转到错误处理的相关代码,其他情况不建议使用 goto 语句。
数组

一个小技巧
这是一个打印数组的宏:

宏里面的参数加上括号是为了更加安全,因为此宏的参数可以是一个表达式的的结果,表达式的优先级可能会对宏的内容造成影响。
size_t
一个无符号整型,表示当前系统内存中可以存储的最大对象的大小。
程序内存的类型
- 代码区:存放程序的执行指令,试图对这块进行写操作会被系统 kill。
- 静态变量区:初始化的、未初始化的分开存放。
- 堆内存区:动态申请的内存会存放此处,
- 栈内存区:临时、局部变量存放在此区。
void* malloc( size_t size )
- 单位是字节。
- 分配的内存是未初始化的,原来里面装着什么内容分配后不变。
- 存在内存对齐机制,比如:int * p1 = (int*) malloc (4);只想分配4字节,但是不同操作系统分配的是不同的,有的会最小分配4字节,有的会最小分配16字节。
- 当程序结束后操作系统会把分配给该程序的所有内存回收。
申请1T内存:
for(int i = 0;i < 1024;++i)
{
int * p = (int*)malloc(1024 * 1024 * 1024);
}new
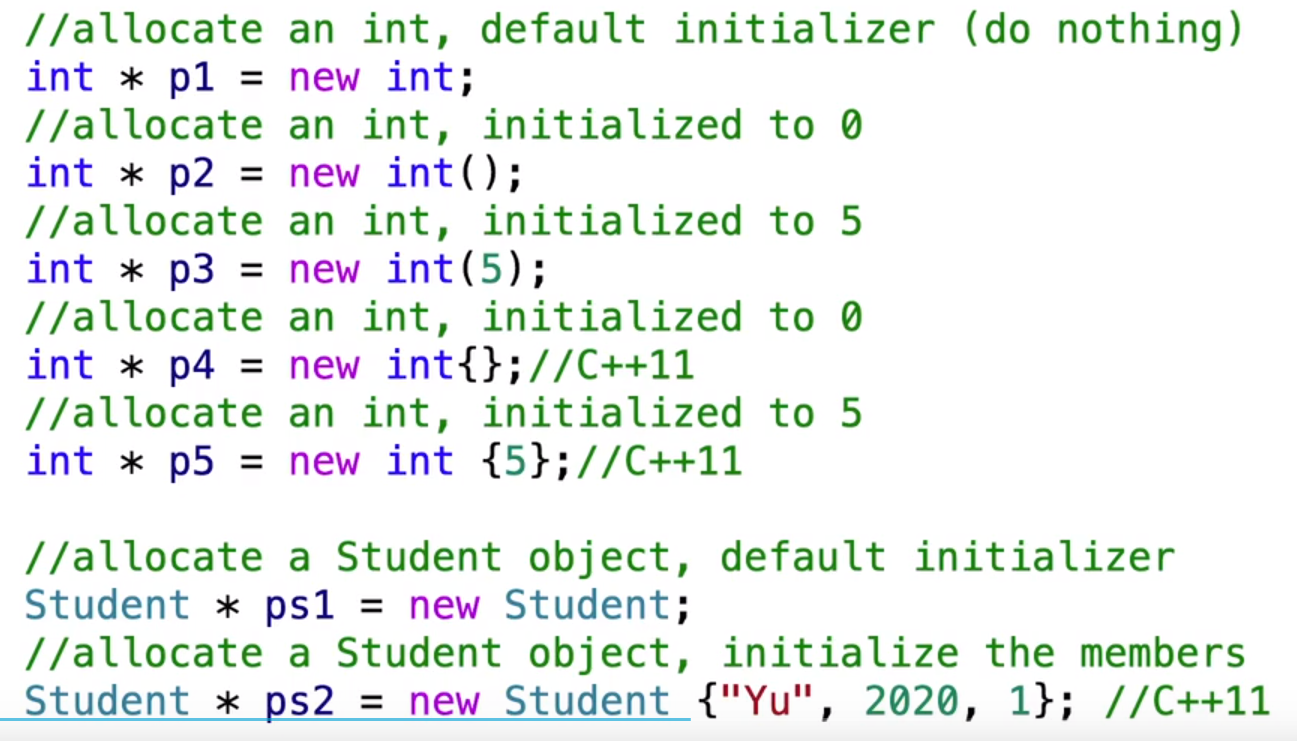

delete

函数是怎么调用的
- 应用程序执行的时候实际上是二进制指令一条条地往CPU里面搬,每一段代码都是一条条指令。
- 当碰到函数时,因为函数的指令不一定和当前执行的指令放在一起的,那么在执行函数时会跳到其他位置去执行,在跳之前一般要保存当前的状态,即各种数据入栈。
- 执行完函数之后从栈中取出各种数据。拿到函数返回值(如果有),继续执行原来的代码。
- 程序执行的代价就是各种数据的出入栈的花费,如果函数非常复杂那么代价可以忽略不计,如果是简单的函数又频繁调用代价就大了,这时候可以设为内联函数。
内联函数示例


重载函数
返回值不参与比较,两个参数列表相同但返回值不同的函数被认为是同一个函数。
函数模板
编译器不会为模板函数生成机器指令,因为不知道具体的类型,只有模板实例化时才会生成机器指令。
函数模板实例化的几种形式:
template<typename T>
T sum(T x, T y)
{
cout << "输入类型是:" << typeid(T).name() << endl;
return x + y;
}
int main(int argc, char *argv[])
{
//实例化的几种形式
double s1 = sum<double>(3.5, 5.9);
char s2 = sum<>('c', 'd');
int s3 = sum(8, 9);
}
模板函数的特例化
上面的代码,如果有一个类型:
struct Point
{
int x;
int y;
};执行:
Point s1 = sum<Point>(Point{1,2}, Point{3,4});编译会报错,因为这个类型没有定义加操作。这时候可以针对此类型特例化实现 sum() 操作:
template<typename T>
T sum(T x, T y)
{
cout << "输入类型是:" << typeid(T).name() << endl;
return x + y;
}
struct Point
{
int x;
int y;
};
template<>
Point sum<Point>(Point pt1, Point pt2)
{
cout << "输入类型是:" << typeid(pt1).name() << endl;
Point pt;
pt.x = pt1.x + pt2.x;
pt.y = pt1.y + pt2.y;
return pt;
}
int main(int argc, char *argv[])
{
Point s1 = sum<Point>(Point{1,2}, Point{3,4});
}
函数指针
指向的是指令区的数据,指向指令的地址。
编程基本原则
“Simple is Beautiful”。代码应该尽可能短、尽可能简洁。
代码优化常用策略
- 优化算法,从算法的时间复杂度、空间复杂度方面考虑优化算法。
- 现在的编译器非常强大,把代码写得简洁以便编译器可以优化。
- 考虑内存操作的影响。计算机的储存机制是分层的,最慢的、储存量最大的是磁盘,读取数据时会(计时用户只需要读取少量数据也会)一次性读取大量数据到内存,再一层层读到 cache 里面,所以读写数据时如果数据的地址是连续的就会很快。
- 避免拷贝大的对象。
- 尽可能不要再循环里面打印内容。
- 查表法。比如 sin()、cos() 这些计算很费时间,可以计算出其常用的值存到数组,可以大大提高效率。处理复杂操作可以考虑使用。
运算符重载
运算符重载可以实现很多方便的操作,比如一个类型转成int:
struct Point
{
int x;
int y;
operator int()const
{
return x + y;
}
};
int main(int argc, char *argv[])
{
Point p1{22,33};
int x = p1;
int x2 = static_cast<int>(p1);
qDebug()<<x<<x2;//55 55
}类似的还可以转成float、bool等。
反过来 int 转 Point 可以定义一个int类型的构造函数来实现。
一段关于动态内存的险恶代码
#include <QDebug>
class MyString
{
private:
int buf_len;
char * characters;
public:
MyString(int buf_len = 64, const char * data = NULL)
{
qDebug() << "构造(int, char*)";
this->buf_len = 0;
this->characters = nullptr;
create(buf_len, data);
}
~MyString()
{
delete []this->characters;
}
bool create(int buf_len, const char * data)
{
this->buf_len = buf_len;
if( this->buf_len != 0)
{
this->characters = new char[this->buf_len]{};
if(data)
strncpy(this->characters, data, this->buf_len);
}
return true;
}
friend QDebug operator<<(QDebug dbg, const MyString & ms)
{
dbg.nospace() << "字符串长度 = " << ms.buf_len;
dbg.nospace() << "字符串地址 = " << static_cast<void*>(ms.characters);
dbg.nospace() << " [" << ms.characters << "]";
return dbg;
}
};
int main()
{
MyString str1(10, "Shenzhen");
qDebug() << "str1: " << str1 ;
MyString str2 = str1;
qDebug() << "str2: " << str2 ;
MyString str3;
qDebug() << "str3: " << str3 ;
str3 = str1;
qDebug() << "str3:" << str3 ;
return 0;
}
分析:
MyString str1(10, "Shenzhen");正常构造一个字符串对象。
MyString str2 = str1;调用拷贝构造函数,但是类里面没有定义拷贝构造函数,会使用编译器默认创建的拷贝构造函数,默认创建的拷贝构造函数执行成员变量赋值操作。所以上面的图,str1 和 str2 的内容一样。
两个对象的 characters 指针指向同一个内存地址。
析构的时候该地址存放的字符串对象先被一个对象销毁了,但是另一个对象的 characters 指针还指着该地址且也要去释放,程序就会出错。
MyString str3;
str3 = str1;str3 先执行了默认构造函数,即先构造了一个长度为64的字符串。然后又执行赋值操作,但是类里面没有定义“=”的重载操作,所以执行的是编译器默认创建的,默认创建的赋值操作也是成员变量的值拷贝,所以现在 str1、str2、str3 三个对象的 characters 指向同一个内存,见上图。而且原先创建的长度为64的字符串没有指针指着无法自行释放了,即内存泄漏了。
解决此问题的方式:
- 自定义拷贝构造函数、自定义拷贝运算符重载使指针指向自己申请的内存。
- 浅拷贝,使用引用计数。
老师金句之二
当你做一件事情的时候感觉很笨、很啰嗦的时候,大概率你的方法错了。
编程技巧
当写一个函数时,第一件事一定是数据检查,这是减少程序调试时间最重要的一点。
类的继承
对基类数据的保护程度:public < protected < private
- 基类中的私有数据:三种方式都不能访问。
- 基类中的 protected 数据:以 public、protected 方式继承,该数据在子类还是 protected 的;以private 方式继承,该数据在子类中是不可直接访问的(可以通过父类间接访问)。
- 基类中的 public 数据:以 public 方式继承,该数据在子类是 public 的,以 protected 方式继承,该数据在子类中是 protected 的,以 private 方式继承,该数据在子类中是不可直接访问的。
关于Virtual
class Person
{
public:
QString name;
Person(QString n): name(n){}
void print()
{
qDebug() <<"Person::print";
qDebug() << "Name: " << name;
}
};
class Student: public Person
{
public:
QString id;
Student(QString n, QString i): Person(n), id(i){}
void print()
{
qDebug() <<"Student::print";
qDebug() << "Name: " << name;
qDebug() << ". ID: " << id;
}
};
void printObjectInfo(Person & p)
{
p.print();
}
int main()
{
{
Student stu("yu", "2019");
printObjectInfo(stu);
stu.print();
}
{
Person * p = new Student("xue", "2020");
p->print();
delete p;
}
return 0;
}
子类对象传入此函数:
void printObjectInfo(Person & p)
{
p.print();
}实际上调用父类 print() 的合理性:编译的时候确定要执行父类的 print() 对应的指令。
给父类的 print() 加上 virtual 就不一样了:
class Person
{
public:
QString name;
Person(QString n): name(n){}
virtual void print()
{
qDebug() <<"Person::print";
qDebug() << "Name: " << name;
}
};
执行的是实际类型的 print()。
静态绑定:编译时确定该执行的函数。
动态绑定:执行时候根据实际的类型确定执行的函数。
动态绑定原理:一旦定义了虚函数,类的成员变量会多出一个指向自身函数表的指针,这个成员变量是类的第一个成员变量。执行时查虚函数表确定实际执行的函数。
析构函数一定要是虚函数,否则调用析构函数时只会调用父类的析构函数。
模板的无类型参数
template<typename T, size_t rows, size_t cols>
class Mat
{
T data[rows][cols];
public:
Mat(){}
T getElement(size_t r, size_t c);
bool setElement(size_t r, size_t c, T value);
};上面的代码 rows、cols 在编译的时候就确定了:
Mat<int, 3, 3> vec;异常处理
函数层层调用,最离层的函数抛出异常,如果外层的函数不捕获异常,那么异常会层层往外扔直到主函数,如果到最后异常没有被捕获那么程序会被kill。
float ratio(float a, float b)
{
if (a < 0)
throw 1;
if (b < 0)
throw 2;
if (fabs(a + b) < FLT_EPSILON)
throw "The sum of the two arguments is close to zero.";
return (a - b) / (a + b);
}
float ratio_wrapper(float a, float b)
{
try{
return ratio(a, b);
}
catch(int eid)
{
if (eid == 1)
std::cerr << "Call ratio() failed: the 1st argument should be positive." << std::endl;
else if (eid == 2)
std::cerr << "Call ratio() failed: the 2nd argument should be positive." << std::endl;
else
std::cerr << "Call ratio() failed: unrecognized error code." << std::endl;
}
return 0;
}
int main()
{
float x = 0.f;
float y = 0.f;
float z = 0.f;
std::cout << "Please input two numbers <q to quit>:";
while (std::cin >> x >> y)
{
try{
z = ratio_wrapper(x,y);
std::cout << "ratio(" << x << ", " << y<< ") = " << z << std::endl;
}
catch(const char * msg)
{
std::cerr << "Call ratio() failed: " << msg << std::endl;
std::cerr << "I give you another chance." << std::endl;
}
std::cout << "Please input two numbers <q to quit>:";
}
std::cout << "Bye!" << std::endl;
return 0;
}匹配任何异常:
int main()
{
runSomething1();
try
{
runSomething2();
}
runSomeOthers();
catch(...)
{
std::cerr << "Unrecognized Exception" << std::endl;
}
return 0;
}三个点表示匹配任何异常,即任何扔到主函数的异常都被捕获,可防止程序被kill。
当new申请内存失败时,默认会抛出异常。
int main()
{
int * p;
try {
p = new int[10];
}
catch (std::bad_alloc & ba)//处理抛出的异常
{
qDebug() << ba.what();
}
//使用std::nothrow将在new申请内存失败后不抛出内存且将p置为nullptr
p = new(std::nothrow) int[10];
if(p)
{
}
return 0;
}友元类
友元类可以访问类的私有成员。
#include <iostream>
using namespace std;
class Sniper
{
private:
int bullets;
public:
Sniper(int bullets = 0): bullets(bullets){}
friend class Supplier;
};
class Supplier
{
int storage;
public:
Supplier(int storage = 1000): storage(storage){}
bool provide(Sniper & sniper)
{
// bullets is a private member
if (sniper.bullets < 20) //no enough bullets
{
if (this->storage > 100 )
{
sniper.bullets += 100;
this->storage -= 100;
}
else if(this->storage > 0)
{
sniper.bullets += this->storage;
this->storage = 0;
}
else
return false;
}
cout << "sniper has " << sniper.bullets << " bullets now." << endl;
return true;
}
};
int main()
{
Sniper sniper(2);
Supplier supplier(2000);
supplier.provide(sniper);
return 0;
}限制友元类只有一部分函数可以访问类的私有成员:
#include <iostream>
using namespace std;
class Supplier;
class Sniper;
class Supplier
{
int storage;
public:
Supplier(int storage = 1000): storage(storage){}
bool provide(Sniper & sniper);
};
class Sniper
{
private:
int bullets;
public:
Sniper(int bullets = 0): bullets(bullets){}
friend bool Supplier::provide(Sniper &);
};
bool Supplier::provide(Sniper & sniper)
{
// bullets is a private member
if (sniper.bullets < 20) //no enough bullets
{
if (this->storage > 100 )
{
sniper.bullets += 100;
this->storage -= 100;
}
else if(this->storage > 0)
{
sniper.bullets += this->storage;
this->storage = 0;
}
else
return false;
}
cout << "sniper has " << sniper.bullets << " bullets now." << endl;
return true;
}
int main()
{
Sniper sniper(2);
Supplier supplier(2000);
supplier.provide(sniper);
return 0;
}vadim pisarevsky 大佬提到的几个关于c++的建议
- (长久来看)建议关注算法、概念、技术,而不是特定的特性或者编程语言本身。
- 不要尝试把你学到的花哨功能全部用到开发上,因为过一段时间你可以就都不懂你的代码了。
- “当程序员避免使用原始指针而使用智能指针等封装好的结构,内存泄漏的问题就降到几乎为零”
- c++语言变得越来越复杂,但应该形成自己的提高程序稳定性的方法论,比如:
- 尽量不要手动管理内存,使用已有的容器。
- 在重构和优化之前要进行回归测试。
- 写代码时应注意让程序更容易调试,不要用复杂的语言结构(代码应该越简单越好)。















 1743
1743











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









