






做算力的人天又塌了!!!
(这个正月,塌好几次了

)
https://arxiv.org/pdf/2501.19393
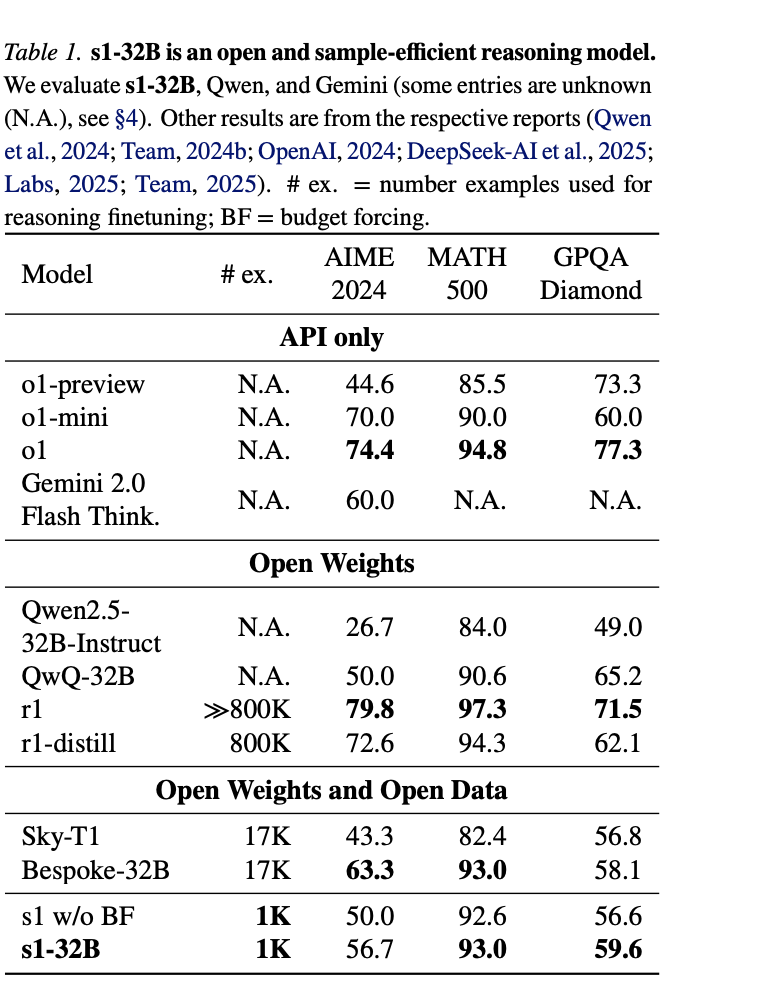
李飞飞团队刚刚发布的论文,仅仅用了 1000 个样本,用了 16 块 H100,在 26 分钟就训练完成了可以匹敌 o1-preview 的模型。
但是具体的情况?
本着本 blog 一贯认真负责的追求事实真相的原则,我抽丝剥茧展开说一下。
S1 这个模型的训练方法
简单说就 SFT
基础模型性能很好 Qwen2.5-instrut,用过的都知道 32B 模型里的最强者,没有之一(闭源也没有 32B 的)。
S1 模型就是基于这样的一个模型 SFT 产生的。
那它的 SFT 为什么能有比较好的提升呢?
主要是数据工程。
s1 模型,具体来说是 s1-32B 模型,是通过以下步骤创建的:
数据收集
首先,研究人员从 16 个不同的来源 收集了 59,029 个问题。
这些数据集的来源包括 NuminaMATH、MATH、OlympicArena(全是数学)以及一些原创数据集,如:
- s1-prob
(来自斯坦福大学统计系博士资格考试的概率问题)
- s1-teasers
(定量交易职位面试中常用的脑筋急转弯)
收集数据的指导原则是 质量、难度和多样性。
-
研究人员会检查样本,并忽略格式较差的数据集。
-
他们确保数据集具有挑战性,需要大量的推理能力,并且涵盖不同的领域,以包含不同的推理任务。
数据清洗与筛选
收集到的问题经过 去重 和 去污染 处理,以避免与评估问题(如 MATH500、GPQA Diamond、AIME24)重复。
-
通过 问题编号减少,数据集减少到 51,581 个样本。
-
研究人员从他们认为高质量且无需进一步过滤的数据集中选出了 384 个样本,这就是最终保留下来的有价值的。
384 个肯定是不够的,剩余的怎么办呢?
研究人员使用 Qwen2.5-7B-Instruct 和 Qwen2.5-32B-Instruct 两个模型来评估每个问题的难度。
-
如果这两个模型中的任何一个能够正确解决某个问题,那么该问题就被认为太简单而被 移除。
-
研究人员还考虑了 推理轨迹的长度,认为 更难的问题需要更长的推理过程,因此也会过滤掉一些推理轨迹过短的问题。
经过这一轮筛选,数据集进一步减少到 24,496 个样本。
s1K 数据集的构建(三阶段筛选)
-
第一阶段:领域选择
-
他们从 50 个不同的领域 中 随机选择一个领域。
-
-
第二阶段:问题选择
-
在选定的领域中,研究人员会 根据一个偏好较长推理链的分布,抽取一个问题。
-
这意味着,那些 需要更多推理步骤的问题更有可能被选中。
-
-
第三阶段:重复以上步骤
-
直到收集到 1000 个样本(包含之前的 384 个)。
-
目的是确保 s1K 数据集的多样性和高质量,并使其包含各种难度的问题。
-
s1K 数据集包含了各种数学和其他科学领域的难题,并具有高质量的 推理轨迹(抽数,即大家常说的蒸馏

,但其实和蒸馏训练没啥关系)。
-
这些轨迹是通过使用 Google Gemini Flash Thinking API 生成的。
-
这些推理轨迹和最终答案被用于训练。
-
为了确保多样性,每个问题都使用 Claude 3.5 Sonnet 根据数学学科分类 (MSC) 系统进行分类。
模型训练
s1-32B 模型是在构建好的 s1K 数据集 上进行 SFT 训练 的。
**看到这大家基本也能看出个7788了,总结一下就是找一些认可的特别优秀的问答对(数学居多)然后让Gemini 2 flash think来生成解题的中间过程**
所以,我们在回过头看一下数据
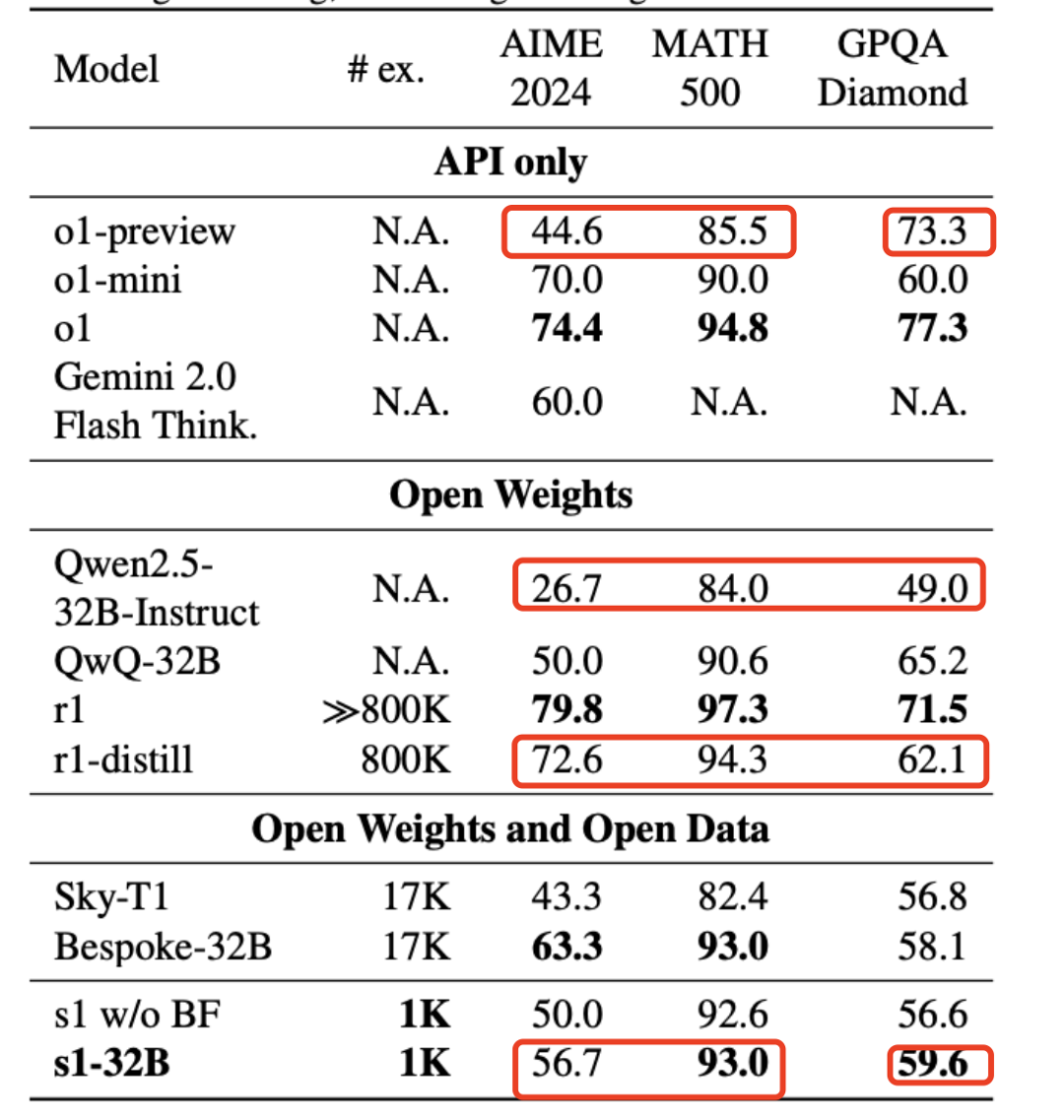
论文主要打o1-preview,坦率说,o1 preview的数学部分一直不咋滴,甚至不如o1-mini,主要他也不是正式产品。从S1和O1-preview对比的话,似乎数学能力提升不错,尤其是奥数
但是看一下它的训练集
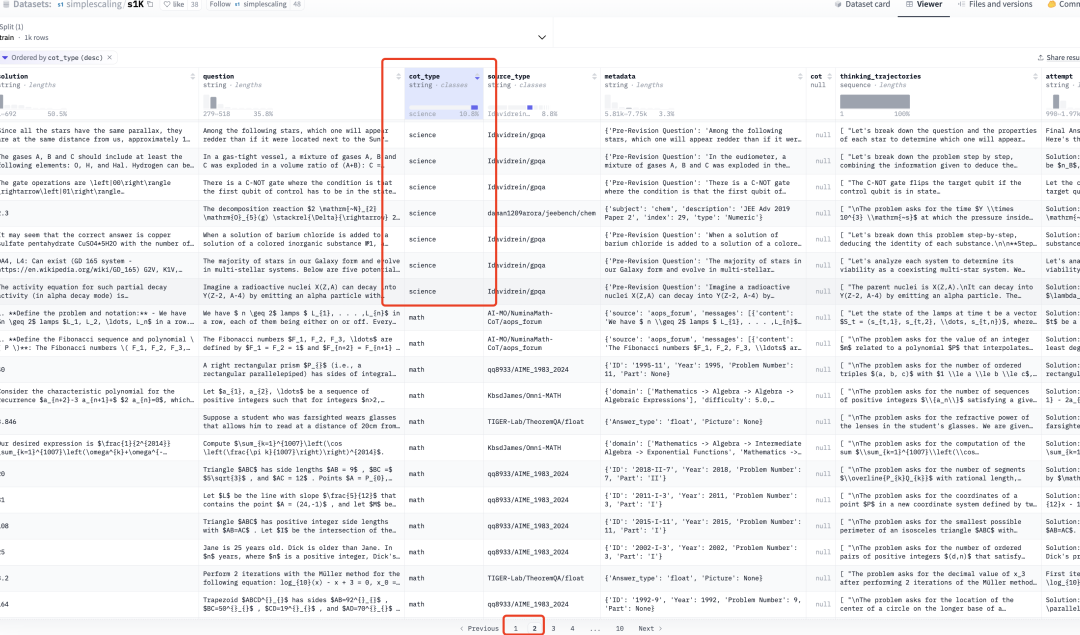
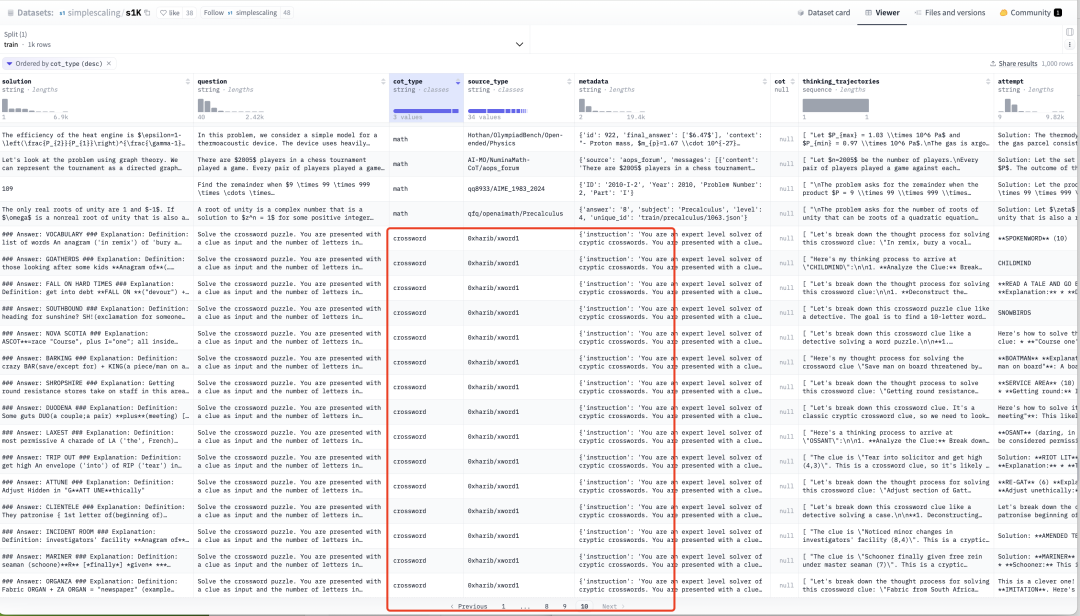
它训练集,全是math。。。 就一页science,20几道cross,所以....

而测试标准
AIME
American Invitational Mathematics Examination 全美数学竞赛
MATH
这就不用怎么解释了
GPQA
General Purpose Question Answering 通用问题解答
但是看一下测试的报告,GPQA的提升比起数学来讲,不算特别明显,提升最明显的是奥数
我个人对这个测试持保留意见,建议要测试就把所有通用任务都测试了,也好证明无原始数据分布的SFT对模型本身的原有任务没有影响,就拿一版发布模型的任务来测试就好了
-
MMLU
-
MMLU-Pro
-
BBH
-
C-Eval
-
CMMLU
-
HumanEval
-
MBPP
-
CRUX-I
-
CRUX-O
-
GSM8K
-
MATH
所以我对使用1000个高级数据样本能达到R1(80万样本,但是推理部分主要是自产自销)的水准这个评论持保留意见,只用这几个任务,还是高度和训练任务拟合的下游任务来测试,不太reasonable
如果只是从Gemini抽取数学题的中间解题思路来SFT达到一个比较好的目标,除了数据要好以外
另外一个我觉得本篇论文相对有价值的地方就是延长了test time scaling 的时间
测试时干预 (Test-time intervention)
测试时干预是在模型推理阶段,通过特定技术手段调整模型行为,以提高模型性能或实现特定目标。在 s1-32B 模型中,测试时干预主要通过 “预算强制 (Budget forcing)” 和 “拒绝采样 (Rejection sampling)” 两种方法来实现。
1. 预算强制 (Budget forcing)
核心思想
通过强制模型在推理时生成特定数量的 "思考 (Thinking)" token,来控制推理过程。
具体实现
-
强制最大 token 数量
-
在模型生成文本时,附加 "结束思考 (end-of-thinking)" token 和 "最终答案 (Final Answer:)",提前终止模型推理。
-
当模型生成的 token 数量达到预设的最大值时,强制其停止思考并输出最终答案。
-
-
强制最小 token 数量
- 抑制 "结束思考" token
,强制模型继续生成 "思考" token,直到满足最小 token 数量的要求。
-
例如,当模型试图提前停止时,系统阻止 "结束思考" token 出现,并附加 "Wait" 等词,引导模型继续思考并进行自我修正。
- 抑制 "结束思考" token
目的
- 控制推理长度
避免模型生成过长或过短的推理链。
- 提高推理质量
强制模型更深入思考,有助于其发现初始推理中的错误并进行自我修正。
示例
在一个测试中,模型生成了 "....is 2",但由于附加了 "Wait",模型继续推理并自我纠正,最终得出正确答案。
2. 拒绝采样 (Rejection sampling)
核心思想
通过多次采样,选择满足特定长度要求的推理轨迹。
具体实现
-
设定一个最大 token 数量。
- 模型多次生成推理轨迹
,直到生成的轨迹 token 数量小于设定的最大值。
- 如果生成的轨迹 token 数量超出阈值,则拒绝该轨迹,并重新采样。
目的
- 控制推理长度
通过拒绝不符合长度要求的推理轨迹来限制推理过程。
- 探索不同推理路径
多次采样可帮助模型探索不同推理方式,并找到更优解。
问题
研究发现,简单地使用拒绝采样来强制推理轨迹的长度,反而可能导致性能下降。
原因
- 更短的推理轨迹
模型一开始就走在正确道路上,较少回溯和错误修正。
- 更长的推理轨迹
可能包含模型犯错和回溯的过程,导致推理质量下降。(这个我在R1的COT不是越长就一定越好的部分讲过)
| 方法 | 控制方式 | 主要特点 | 可能问题 |
|---|---|---|---|
| 预算强制 (Budget forcing) | 直接在解码时强制添加或抑制特定 token | 更加直接、可控 | 可能影响自然性 |
| 拒绝采样 (Rejection sampling) | 通过多次生成并筛选推理轨迹 | 可以探索不同路径 | 可能导致性能下降 |
通过这两种测试时干预手段,s1-32B 模型能够更好地控制推理行为,提高问题解决能力。
说人话就是人为的干预让模型有更长的COT能力,这个R1期时拒绝采样的时候也是争取选最长的,理论上越长效果越好,因为比如得出了一个错误答案,当模型发现没有收到stop think或者end of token的singale,它还会继续生成token,这时候有可能完成了self-correct 的反思过程,把答案给纠正过来(但是事实我们在实际玩的过程中,往往是反思完了,错到别的地方去了


















 1824
1824

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









