






我开年时候说Reasoning会火,但是我每想到火这么快
和2023年预测MOE一样,2024年年底预测reasoning基本也是年度AI热词了,我跟迪亚波罗的绯红之王有一拼

但是确实最近没什么东西值得写,也收到了兄弟的吐槽
于是今天就决定一次讲两篇论文
不是为了凑数,是真的一次讲两篇,因为这两篇说的事,有关联!
第一篇

这篇讲的啥呢
我还是先给个结论,LLM并不会做数学题,它能做出来纯粹是题海战术
解释一下这个论文的验证方法
就是对原始问题进行修改和干预,也不是乱干预,是真的改到看似差不多,但是解法应该完全不同的题
干预的方式分为simple和hard
simple就是简单干预,比如分母x+1,它给改成x+2
hard干预就是猛干,比如把第一题的x+1的分母给改成x

你可别小看x+1变x+2和x,这可是完全不同
拿第一题举例子,x+1变x+2但是解体方法其实还是因式分解对吧
但是你要改x,你能因式分解吗?
你得上Cauchy-Schwarz Inequality来整
对于大模型的pretrain数据,如果它有 CSI的能力,或者说以前见过这种题型狠多
第一:知识学到了
第二:内化推理激发出来了
那它就可以做
但是,如果没有(可能math500的这种训练集里面,还是因式分解多一点),那它是不是不做?
还真不是,结果就是它死犟,按着因式分解的类似的COT给你硬来
结果就是做错
总结一下,就是模型肯定是可以学到训练集里解决问题的技巧,也就是COT范式,COT也是有范式的,或者说学到了解决问题的思路,但是它总是盲目的使用,也不去考虑比如类似问题被修改了以后,还用这套COT范式,是不是合适
再比如说这个问题

左侧:原始问题 (Original)
-
问题:
求所有整数 n。
-
解决方案:
-
当 n是偶数时,化简后得到 0=00 ,无解。
-
当 n 是奇数时,设 n=2m+1n ,经过推导,得到唯一解:n=
5
-
右侧:困难扰动 (MATH-P-Hard)
-
问题:
经过 扰动 (Perturbation) 后要求最小的整数值 n。
-
模型推理过程:
-
题目要求的是最小的整数值 n,但模型输出了所有整数解 n=10,13
,而不是最小解 n=10
所以有时候我不同意压缩即智能的看法,当然我并不是针对谁说啊

-
结论: LLM其实做数学题也是玩概率
那有人就说那为什么O系列,R1啥的能提升不少数学能力呢?那是因为它学到了pattern,或者不一样的COT pattern,随着你的训练方法更有效,它就能学到,为什么能学到?
看下面这个论文

简单说这文章干啥了就可以了
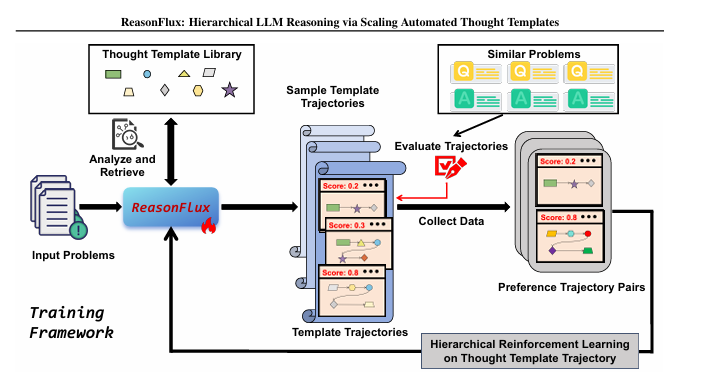
就是把一些COT的思考范式,给内聚成一系列pattern,好像500个
然后把COT的pattern也给训到模型里
这样模型就知道啥问题,用哪个COT pattern去解了
就这么简单
但是思路挺牛B啊
这其实是啥啊?
这不就是把连续的动作空间,给变成离散的了吗?变成离散的,有限的空间,你就好训练啊
至于文章说用什么mcts,BON还是文章自己的训,我到觉得都不重要,mcts+个reward model的变形一样可以训,只要你把COT的pattern给内化到模型里,基本就可以干这个事了
那么推理的时候
第一反应是读完题,看你这个题符合我哪种COT pattern,然后按着这个来解你,我说的够简单了吧?
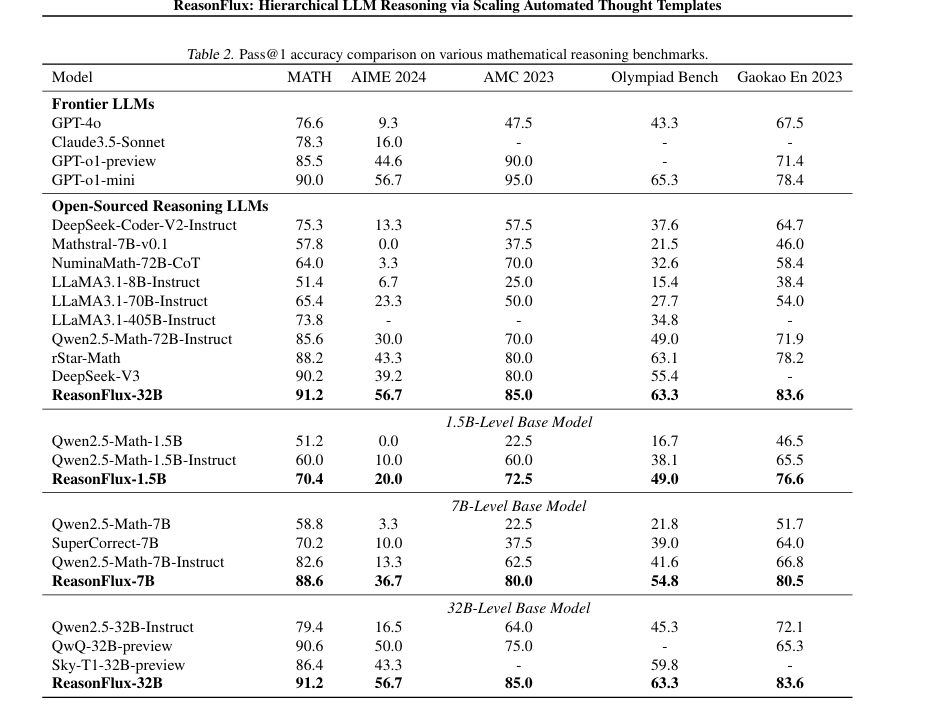
消融也多少做了些,在每个size的模型上,都能看到进步,虽然也只是数学,因为也没训别的东西
但是我认为把pattern给训进去,解别的场景也会有涌现的,就看多与少了,因为数学题套路,500个的话,其实就不少了
至于说它是gemini抽数做的,还是怎么合成的,不重要,你能弄出来500个就行
这是我最近读的两篇非常有意思的论文
也对以后的训练模式上狠有启发,而且对我来说,从原理能说服我的论文,才有价值
另一个角度上讲,其实让我乐观了一些,我一直担心,LLM要取代人类,但是我也没什么确实的证据或者反证
这俩论文让我看着挺好,给了我一定的信心
LLM要取代人类,至少这个版本不太现实,500个COT的pattern template就能打遍天下了吗?
笑话!
什么时候LLM能自动产生推理规划路径,什么时候在跟人类PK,我还能折腾几年



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









