







K-means
我们将实施和应用K-means到一个简单的二维数据集,以获得一些直观的工作原理。 K-means是一个迭代的,无监督的聚类算法,将类似的实例组合成簇。 该算法通过猜测每个簇的初始聚类中心开始,然后重复将实例分配给最近的簇,并重新计算该簇的聚类中心。
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sb
from scipy.io import loadmat
我们要实现的第一部分是找到数据中每个实例最接近的聚类中心的函数。
def find_closest_centroids(X, centroids):
m=X.shape[0] #m个样本
k=centroids.shape[0] #k个聚类
idx=np.zeros(m)
for i in range(m):
min_dist=100000
for j in range(k):
dist=np.sum((X[i,:]-centroids[j,:])**2) #求样本和哪个聚类中心距离最小
if dist<min_dist:
min_dist=dist
idx[i]=j
return idx
data=loadmat('E:/shujuji/ex7data2.mat')
X=data['X']
#让我们来测试这个函数,以确保它的工作正常
initial_centroids=np.array([[3, 3], [6, 2], [8, 5]])
idx = find_closest_centroids(X, initial_centroids)
idx[0:3]
原始图
#画图
data2=pd.DataFrame(X,columns=['X1','X2'])
plt.scatter(data2['X1'],data2['X2'])
plt.show()

将新划分的聚类 ,找到新的聚类中心
def compute_centroids(X,idx,k):
m,n=X.shape
centroids=np.zeros((k,n))
for i in range(k):
indices=np.where(idx==i)
#np.where满足条件就返回索引值,将每一类样本分别划分到indices中
centroids[i,:]=(np.sum(X[indices,:],axis=1)/len(indices[0])).ravel()
#每一类求和计算平均值,作为新的聚类中心
return centroids
#练习
compute_centroids(X, idx, 3)
总函数
#总函数
def run_k_means(X,initial_centroids,max_iters):
m,n=X.shape
k = initial_centroids.shape[0]
idx = np.zeros(m)
centroids = initial_centroids
for i in range(max_iters):
idx=find_closest_centroids(X, centroids)
centroids = compute_centroids(X, idx, k)
return idx,centroids
idx, centroids = run_k_means(X, initial_centroids, 10)
#分别取出三个聚类的点,
cluster1=X[np.where(idx==0)[0],:]
cluster2 = X[np.where(idx == 1)[0],:]
cluster3 = X[np.where(idx == 2)[0],:]
#画图
fig, ax = plt.subplots(figsize=(12,8))
ax.scatter(cluster1[:,0], cluster1[:,1], s=30, color='r', label='Cluster 1')
ax.scatter(cluster2[:,0], cluster2[:,1], s=30, color='g', label='Cluster 2')
ax.scatter(cluster3[:,0], cluster3[:,1], s=30, color='b', label='Cluster 3')
ax.legend()
plt.show()

我们跳过的一个步骤是初始化聚类中心的过程。 这可以影响算法的收敛。
我们现在来是创建一个选择随机样本并将其用作初始聚类中心的函数。
def init_centroids(X,k):
m, n = X.shape
centroids = np.zeros((k, n))
idx = np.random.randint(0, m, k)#随机生成k个0~m的数
for i in range(k):
centroids[i,:]=X[idx[i],:] #用idx随机选出k个(x1,x2)个作为起始聚类中心
return centroids
init_centroids(X, 3)
emmm…还有个图片压缩,不过我好害怕那个鸟,待更新。。。。
降维
PCA是在数据集中找到“主成分”或最大方差方向的线性变换。 它可以用于降维。 在本练习中,我们首先负责实现PCA并将其应用于一个简单的二维数据集,以了解它是如何工作的。
我们从加载和可视化数据集开始。
data = loadmat('E:/shujuji/ex7data1.mat')
X = data['X']
fig, ax = plt.subplots(figsize=(12,8))
ax.scatter(X[:, 0], X[:, 1])
plt.show()


def pca(X):
X=(X-X.mean())/X.std()#归一化
X=np.matrix(X)
cov=(X.T*X)/X.shape[0]#计算sigma
U,S,V=np.linalg.svd(cov)#计算协方差矩阵
return U, S, V
U, S, V = pca(X)
U, S, V

得到 n × n维度的矩阵U之后,如果我们希望将数据从n维降至k维,我们只需要从U中选取前k个向量,获得一个n × k维度的矩阵,我们用U(reduce) 表示,然后通过如下计算获得要求的新特征向量z(i) :
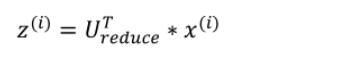
def project_data(X,U,k):
U_reduced=U[:,:k] #降至k维
return np.dot(X,U_reduced) #求z
Z = project_data(X, U, 1)
Z
数据重构
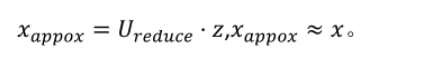
def recover_data(Z,U,k):
U_reduced=U[:,:k]
return np.dot(Z,U_reduced.T)
X_recovered = recover_data(Z, U, 1)
X_recovered















 1063
1063











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









