







一、最优化问题概括
1.1.1 最优化问题的一般形式
最优化问题一般可以描述为:
min f ( x ) s . t . x ∈ X ( 1.1.1 ) \min\quad f(x)\quad\quad\quad\quad\quad\quad\quad\quad\\s.t.\quad x\in\mathcal{X}\quad\quad\quad\quad\quad(1.1.1) minf(x)s.t.x∈X(1.1.1)
其中 x = ( x 1 , x 2 , … , x n ) T ∈ R n x=(x_1,x_2,\dots,x_n)^T\in\mathbb{R}^n x=(x1,x2,…,xn)T∈Rn是决策变量, f : R n → R f:\mathbb{R}^n\to\mathbb{R} f:Rn→R是目标函数, X ⊆ R n \mathcal{X}\subseteq\mathbb{R}^n X⊆Rn是约束集合或可行域,可行域包含的点称为可行解或可行点。当 X = R n \mathcal{X}=\mathbb{R}^n X=Rn时,问题 (1.1.1) 称为无约束优化问题。集合 X \mathcal{X} X通常可以由约束函数 c i ( x ) : R n → R , i = 1 , 2 … , m + l c_i(x):\mathbb{R}^n\to\mathbb{R},i=1,2\dots,m+l ci(x):Rn→R,i=1,2…,m+l表达为如下形式:
X = { x ∈ R n ∣ c i ( x ) ≤ 0 , i = 1 , 2 , … , m , c i ( x ) = 0 , i = m + 1 , m + 2 , … , m + l } \mathcal{X}=\{x\in\mathbb{R}^n|c_i(x)\le0,\quad i=1,2,\dots,m,\\\quad\quad\quad\quad\quad\quad c_i(x)=0,\quad i=m+1,m+2,\dots,m+l\} X={x∈Rn∣ci(x)≤0,i=1,2,…,m,ci(x)=0,i=m+1,m+2,…,m+l}
在所有满足约束条件的决策变量中,使目标函数取最小值的变量 x ∗ x^* x∗ 称为优化问题 (1.1.1) 的最优解,即对任意 x ∈ X x\in\mathcal{X} x∈X都有 f ( x ) ≥ f ( x ∗ ) f(x)\ge f(x^*) f(x)≥f(x∗)。如果我们求解在约束集合 X \mathcal{X} X上目标函数 f ( x ) f(x) f(x) 的最大值,则问题 (1.1.1) 的“ m i n min min”应相应地替换为“ m a x max max”。注意到在集合 X \mathcal{X} X上,函数 f f f 的最小(最大)值不一定存在,但是其下(上)确界“ inf f ( sup f ) \inf\ f(\sup \ f) inf f(sup f)”总是存在的.因此,当目标函数的最小 (最大)值不存在时,我们便关心其下(上)确界,即将问题 (1.1.1)中的“ min ( max ) \min(\max) min(max)”改为“ inf ( sup ) \inf(\sup) inf(sup)”.为了叙述简便,问题 (1.1.1) 中 x x x 为 R n \mathbb{R}^n Rn空间中的向量.实际上,根据具体应用和需求, x x x还可以是矩阵、多维数组或张量等。
注意,在整个介绍过程中,向量一般用小写英文字母或希腊字母表示,矩阵一般用大写英文字母或希腊字母表示。
1.1.2 最优化问题的类型与应用背景
最优化问题 (1.1.1) 的具体形式非常丰富,我们可以按照目标函数、约束函数以及解的性质将其分类.按照目标函数和约束函数的形式来分:当目标函数和约束函数均为线性函数时,问题(1.1.1) 称为线性规划;当目标函数和约束函数中至少有一个为非线性函数时,相应的问题称为非线性规划;如果目标函数是二次函数而约束函数是线性函数则称为二次规划;包含非光滑函数的问题称为非光滑优化;不能直接求导数的问题称为无导数优化;变量只能取整数的问题称为整数规划;在线性约束下极小化关于半正定矩阵的线性函数的问题称为半定规划,其广义形式为锥规划.按照最优解的性质来分:最优解只有少量非零元素的问题称为稀疏优化;最优解是低秩矩阵的问题称为低秩矩阵优化.此外还有几何优化、二次锥规划、张量优化、鲁棒优化、全局优化、组合优化、网络规划、随机优化、动态规划、带微分方程约束优化、微分流形约束优化、分布式优化等.
二、实例:稀疏优化
考虑线性方程组求解问题:
A x = b , ( 1.2.1 ) Ax=b,\quad\quad\quad\quad\quad(1.2.1) Ax=b,(1.2.1)
其中向量 x ∈ R n x\in\mathbb{R}^n x∈Rn, b ∈ R m b\in\mathbb{R}^m b∈Rm,矩阵 A ∈ R m × n A\in\mathbb{R}^{m\times n} A∈Rm×n,且向量 b b b 的维数远小于向量 x x x 的维数,即 m ≪ n m ≪ n m≪n。常见的情况是已知向量 b b b 和矩阵 A A A,想要重构向量 x x x 。注意到由于 m ≪ n m ≪ n m≪n,方程组 (1.2.1) 是欠定的,因此存在无穷多个解,重构出原始信号是很难的.但这个问题有一个切入点是这些解当中大部分是我们不感兴趣的,真正有用的解是所谓的“稀疏解”,即原始信号中有较多的零元素.如果加上稀疏性这一先验信息,且矩阵 A A A 以及原问题的解 u u u 满足某些条件,那么我们可以通过求解稀疏优化问题把 u u u 与方程组 (1.2.1) 的其他解区别开。
观察一个具体的例子,按照矩阵乘法构造 A , u , b A,u,b A,u,b:
import scipy
import numpy as np
m=128
n=256
A=np.random.rand(m,n)
u=scipy.sparse.random(n,1,0.1).toarray()
A=np.dot(A,u)
上面的例子中构造了一个 128 × 256 128\times256 128×256 矩阵 A A A ,它的每个元素都服从高斯随机分布。精确解 u u u 只有%10的元素非零,这些特征可以在理论上保证 u u u 是方程组 (1.2.1) 唯一的非零元素最少的解(怎么在理论上保证唯一解?),即 u u u 是如下 l 0 l_0 l0 范数问题的最优解:
min x ∈ R n ∥ x ∥ 0 s . t . A x = b ( 1.2.2 ) \min\limits_{x\in\mathbb{R}^n}\quad\Vert x\Vert_0\quad\quad\quad\quad\quad\quad\quad\\s.t.\quad Ax=b\quad\quad\quad\quad(1.2.2) x∈Rnmin∥x∥0s.t.Ax=b(1.2.2)
其中 ∥ x ∥ 0 \Vert x\Vert_0 ∥x∥0是指 x x x 中非零元素的个数.由于 ∥ x ∥ 0 \Vert x\Vert_0 ∥x∥0是不连续的函数,且取值只可能是整数,问题 (1.2.2) 实际上是 NP(non-deterministic polynomial)难的(为啥l0范数优化问题是NP难的?),求解起来非常困难.因此当 n 较大时通过直接求解问题 (1.2.2) 来恢复出原始信号 u 是行不通的.我们可以使用 l 1 l_1 l1范数进行替换: ∥ x ∥ 1 = ∑ i = 1 n ∣ x i ∣ \Vert x\Vert_1=\sum\limits_{i=1}^n|x_i| ∥x∥1=i=1∑n∣xi∣,此时我们得到了另一个形式上非常相似的问题(又称 ℓ1 范数优化问题,基追踪问题):
min x ∈ R n ∥ x ∥ 1 s . t . A x = b ( 1.2.3 ) \min\limits_{x\in\mathbb{R}^n}\quad\Vert x\Vert_1\quad\quad\quad\quad\quad\quad\quad\\s.t.\quad Ax=b\quad\quad\quad\quad(1.2.3) x∈Rnmin∥x∥1s.t.Ax=b(1.2.3)
令人惊讶地是,可以从理论上证明:若 A , b A, b A,b 满足一定的条件(例如使用前面随机产生的 A A A 和 b b b),向量 u u u 也是 l 1 l_1 l1 范数优化问题 (1.2.3) 的唯一最优解.这一发现的重要之处在于,虽然问题 (1.2.3) 仍没有显式解(?),但与问题(1.2.2) 相比难度已经大大降低.虽然 l 0 l_0 l0范数优化问题是 NP 难问题,但 l 1 l_1 l1 范数优化问题的解可以非常容易地通过现有优化算法得到。既然有如上令人兴奋的结果,我们是否能使用其他更容易求解的范数替代 l 0 l_0 l0 范数呢?事实并非如此.如果简单地把 l 1 l_1 l1 范数修改为 l 2 l_2 l2 范数 ∥ x ∥ 2 = ( ∑ i = 1 n x i 2 ) 1 2 \Vert x\Vert_2=(\sum\limits_{i=1}^nx_i^2)^{\frac{1}{2}} ∥x∥2=(i=1∑nxi2)21,即求解如下优化问题:
min x ∈ R n ∥ x ∥ 2 s . t . A x = b ( 1.2.4 ) \min\limits_{x\in\mathbb{R}^n}\quad\Vert x\Vert_2\quad\quad\quad\quad\quad\quad\\s.t.\quad Ax=b\quad\quad\quad(1.2.4) x∈Rnmin∥x∥2s.t.Ax=b(1.2.4)
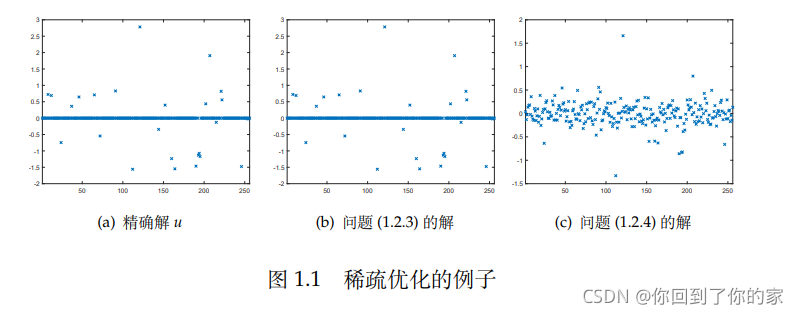
几何学的知识证明,问题(1.2.4) 实际上就是原点到仿射集 A x = b Ax=b Ax=b 的投影(?),我们可以直接写出它的显式表达式(?).但遗憾的是,u 并不是问题 (1.2.4) 的解.事实上,图 1.1(a)-© 分别给出了一组随机数据下的 u,以及问题 (1.2.3) 和问题 (1.2.4) 的数值解.可以看出图 1.1(a) 和 (b) 是完全一样的,而 © 则与u 相去甚远,虽然隐约能看出数据点的大致趋势,但已经不可分辨非零元素的具体位置.
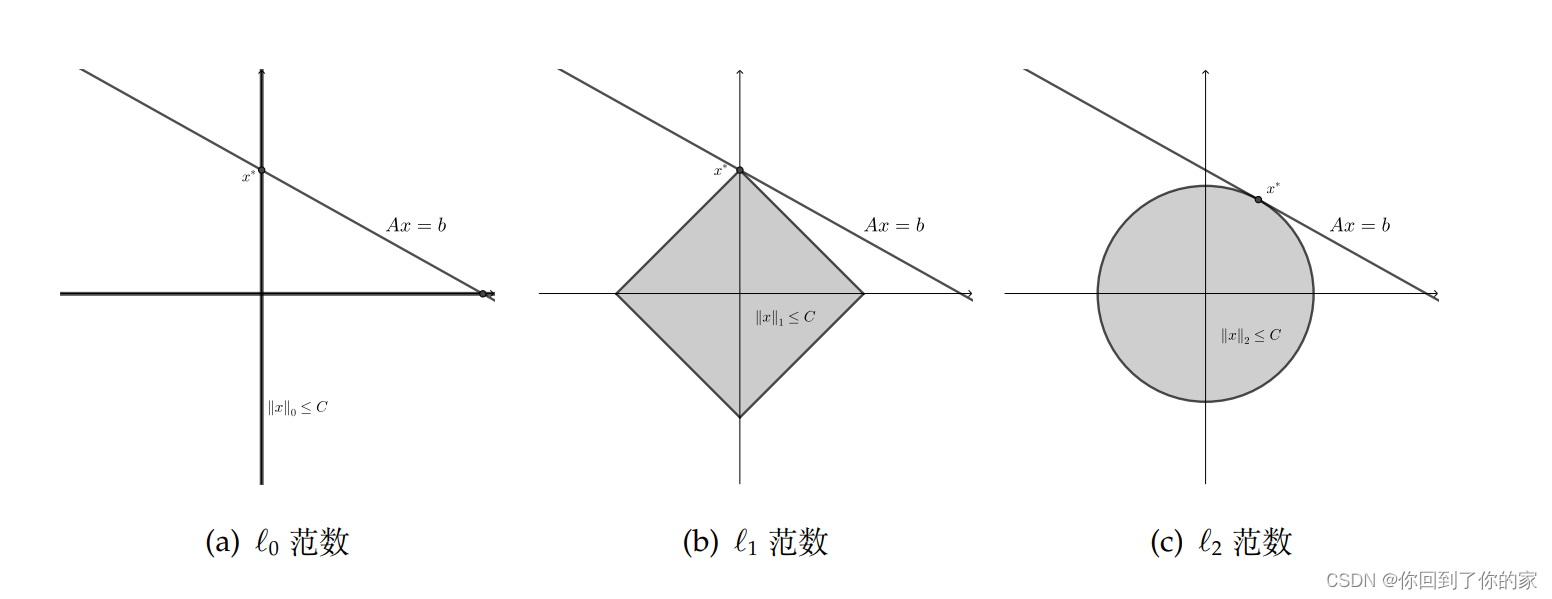
为什么会出现这种情况呢?这要追溯到
ℓ
0
,
ℓ
1
,
ℓ
2
\ell_0, \ell_1, \ell_2
ℓ0,ℓ1,ℓ2 范数的性质.下面用图示的方式来直观说明为什么 ℓ1 范数优化问题的解具有稀疏性而 ℓ2 范数优化问题的解不具有该性质.为了方便起见,我们在二维空间上讨论求解欠定方程组 Ax = b,此时 Ax = b 是一条直线.在几何上,三种优化问题实际上要找到最小的 C,使得“范数球”
{
x
∣
∥
x
∥
≤
C
}
\{x|\Vert x\Vert \le C\}
{x∣∥x∥≤C}(
∥
⋅
∥
\Vert\cdot\Vert
∥⋅∥表示任何一种范数)恰好与
A
x
=
b
Ax = b
Ax=b 相交.而图 1.2 里分别展示了三种范数球的几何直观:对 ℓ0范数,当
C
=
2
C = 2
C=2 时
{
x
∣
∥
x
∣
0
≤
C
}
\{x|\Vert x\vert_0 \le C\}
{x∣∥x∣0≤C} 是全平面,它自然与
A
x
=
b
Ax = b
Ax=b 相交,而当
C
=
1
C = 1
C=1时退化成两条直线(坐标轴),此时问题的解是
A
x
=
b
Ax = b
Ax=b 和这两条直线的交点;对 ℓ1 范数,根据 C 不同
{
x
∣
∥
x
∥
1
≤
C
}
\{x|\Vert x\Vert_1 \le C\}
{x∣∥x∥1≤C} 为一系列正方形,这些正方形的顶点恰好都在坐标轴上,而最小的 C 对应的正方形和直线
A
x
=
b
Ax = b
Ax=b 的交点一般都是顶点,因此 ℓ1 范数的解有稀疏性;对 ℓ2 范数,当 C 取值不同时
{
x
∣
∥
x
∥
2
⩽
C
}
\{x|\Vert x\Vert_2 ⩽ C\}
{x∣∥x∥2⩽C} 为一系列圆,而圆有光滑的边界,它和直线
A
x
=
b
Ax = b
Ax=b 的切点可以是圆周上的任何一点,所以 ℓ2 范数优化问题一般不能保证解的稀疏性(为什么切点可以是圆周上的任何一点?)。
三种范数优化问题求解示意图如下:
待补充 22
4 深度学习
4.1 多层感知机
多层感知机(multi-layer perceptron, MLP)也叫作深度前馈网络(deep feedforward network)或前馈神经网络(feedforward neural network),它通过已有的信息或者知识来对未知事物进行预测.在神经网络中,已知的
信息通常用数据集来表示.数据集一般分为训练集和测试集:训练集是用来训练神经网络,从而使得神经网络能够掌握训练集上的信息;测试集是用来测试训练完的神经网络的预测准确性.一个常见的任务是分类问题.假设我们有一个猫和狗的图片集,将其划分成训练集和测试集(保证集合中猫和狗图片要有一定的比例).神经网络是想逼近一个从图片到 {0, 1} 的函数,这里 0 表示猫,1 表示狗.因为神经网络本身的结构和大量的训练集信息,训练得到的函数与真实结果具有非常高的吻合性.
具体地,给定训练集 D = { a 1 , b 1 } , { a 2 , b 2 } , ⋯ , { a m , b m } D=\{a_1,b_1\},\{a_2,b_2\},\cdots,\{a_m,b_m\} D={a1,b1},{a2,b2},⋯,{am,bm},假设数据 a i ∈ R p , b i ∈ R q a_i\in\mathbb{R}^p,b_i\in\mathbb{R}^q ai∈Rp,bi∈Rq。为了方便处理模型里的偏差项(偏差项是个什么玩意?),还假设 a i a_i ai 的第一个元素等于 1,即 a i 1 = 1 a_{i1}=1 ai1=1.图 1.4 给出了一种由 p 个输入单元和 q 个输出单元构成的(L + 2) 层感知机,其含有一个输入层,一个输出层,和 L 个隐藏层.
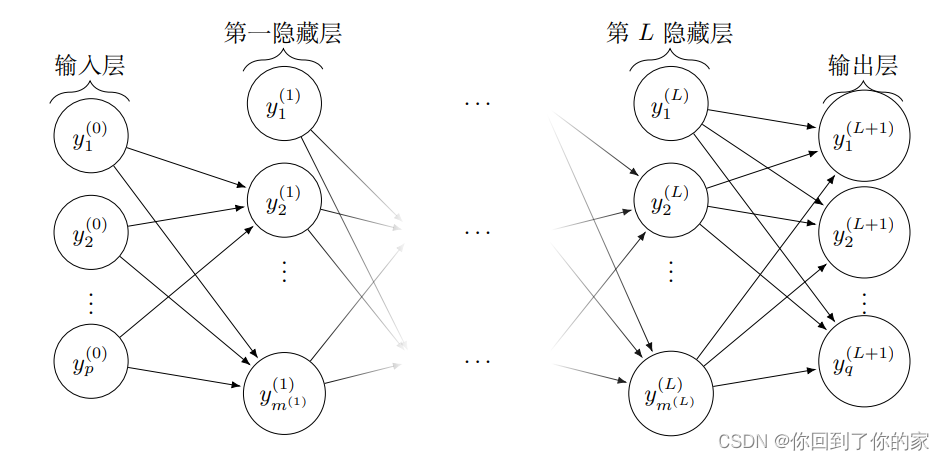
该感知机的第 l l l 个隐藏层共有 m ( l ) m^{(l)} m(l) 个神经元,为了方便我们用 l = 0 l=0 l=0 表示输入层, l = L + 1 l=L+1 l=L+1 表示输出层,并定义 m ( 0 ) = p m^{(0)}=p m(0)=p 和 m L + 1 = q m^{L+1}=q mL+1=q.设 y ( l ) ∈ R m ( l ) y^{(l)}\in\mathbb{R}^{m^{(l)}} y(l)∈Rm(l) 为第 l l l 层的所有神经元,同样地,为了能够处理每一个隐藏层的信号偏差,除输出层外,我们令 y ( l ) y^{(l)} y(l) 的第一个元素等于 1,即 y 1 ( l ) = 1 , 0 ≤ l ≤ L y_1^{(l)}=1,0\le l\le L y1(l)=1,0≤l≤Ly,而其余的元素则是通过上一层的神经元的值进行加权求和得到.令参数 x = ( x ( 1 ) , x ( 2 ) , ⋯ , x ( L + 1 ) ) x=(x^{(1)},x^{(2)},\cdots,x^{(L+1)}) x=(x(1),x(2),⋯,x(L+1)) 表示网络中所有层之间的权重,其中 x i , k ( l ) x_{i,k}^{(l)} xi,k(l) 是第 ( l − 1 ) (l-1) (l−1) 隐藏层的第 k k k 个单元连接到第 l l l 隐藏层的第 i i i 个单元对应的权重,则在第 l l l 隐藏层中,第 i i i 个单元 (i > 1,当 l = L + 1 时可取为 i ⩾ 1)计算输出信息 y i ( l ) y_i^{(l)} yi(l) 为:
y i ( l ) = t ( z i ( l ) ) , z i ( l ) = ∑ k = 1 m ( l − 1 ) x i , k ( l ) y k ( l − 1 ) y_i^{(l)}=t(z_i^{(l)}),\quad z_i^{(l)}=\sum\limits_{k=1}^{m^{(l-1)}}x_{i,k}^{(l)}y_k^{(l-1)} yi(l)=t(zi(l)),zi(l)=k=1∑m(l−1)xi,k(l)yk(l−1)
这里 t ( ⋅ ) t(\cdot) t(⋅)被称为激活函数,常见的类型有Sigmoid函数:
$$$$
待补充 25
5 最优化的基本概念
一般来说,最优化算法研究可以分为:构造最优化模型、确定最优化问题的类型和设计算法、实现算法或调用优化算法软件包进行求解.最优化模型的构造和实际问题紧密相关,比如说,给定二维欧几里得(Euclid)空间的若干个离散点,假定它们可以通过一条直线分成两部分,也可以通过一条曲线分成两部分.那么分别使用直线与曲线所得到的最优化模型是不同的.在问题 (1.1.1) 中,目标函数
f
f
f 和约束函数
c
i
c_i
ci 都是由模型来确定的.在确定模型之后,我们需要对模型对应的优化问题进行分类.这里,分类的必要性是因为不存在对于所有优化问题的一个统一的算法.因此我们需要针对具体优化问题所属的类别,来设计或者调用相应的算法求解器.最后就是模型的求解过程.同一类优化问题往往存在着不同的求解算法.对于具体的优化问题,我们需要充分利用问题的结构,并根据问题的需求(求解精度和速度
等)来设计相应的算法.另外,根据算法得到的结果,我们可以来判别模型构造是否合理或者进一步地改进模型.如果构造的模型比较复杂,那么算法求解起来相对困难(时间慢或者精度差).此时算法分析可以帮助我们设计替代模型,以确保快速且比较精确地求出问题的解.
5.1 连续和离散优化问题
最优化问题可以分为连续和离散优化问题两大类.连续优化问题是指
决策变量所在的可行集合是连续的,比如平面、区间等.如稀疏优化问题(1.2.2) — (1.2.5) 的约束集合就是连续的.离散优化问题是指决策变量能在离散集合上取值,比如离散点集、整数集等.常见的离散优化问题有整数规划,其对应的决策变量的取值范围是整数集合.
在连续优化问题中,基于决策变量取值空间以及约束和目标函数的连
续性,我们可以从一个点处目标和约束函数的取值来估计该点可行邻域内的取值情况.进一步地,可以根据邻域内的取值信息来判断该点是否最优.离散优化问题则不具备这个性质,因为决策变量是在离散集合上取值.因此在实际中往往比连续优化问题更难求解.实际中的离散优化问题往往可以转化为一系列连续优化问题来进行求解.比如线性整数规划问题中著名的分支定界方法,就是松弛成一系列线性规划问题来进行求解.因此连续优化问题的求解在最优化理论与算法中扮演着重要的角色.本书后续的内容也将围绕连续优化问题展开介绍.
5.2 无约束和约束优化问题
最优化问题的另外一个重要的分类标准是约束是否存在.无约束优化问
题的决策变量没有约束条件限制,即可行集合
X
=
R
n
\mathcal{X}=\mathbb{R}^n
X=Rn.相对地,约束优化问题是指带有约束条件的问题.在实际应用中,这两类优化问题广泛存在.无约束优化问题对应于在欧几里得空间中求解一个函数的最小值点.比如在
ℓ
1
\ell_1
ℓ1 正则化问题 (1.2.5) 中,决策变量的可行域是
R
n
\mathbb{R}^n
Rn,其为一个无约束优化问题.在问题 (1.2.2) — (1.2.4) 中,可行集为
{
x
∣
A
x
=
b
}
\{x|Ax=b\}
{x∣Ax=b},其为约束优化问题.
因为问题 (1.1.1) 可以通过将约束 X ≠ R n \mathcal{X}\ne\mathbb{R}^n X=Rn 罚到目标函数上转化为无约束问题,所以在某种程度上,约束优化问题就是无约束优化问题.很多约束优化问题的求解也是转化为一系列的无约束优化问题来做,常见方式有增广拉格朗日函数法、罚函数法等.尽管如此,约束优化问题的理论以及算法研究仍然是非常重要的.主要原因是,借助于约束函数,我们能够更好地描述可行域的几何性质,进而更有效地找到最优解.对于典型的约束和无约束优化模型,我们将会在本书的第四章中介绍,相应的理论以及算法会在第五—八章中给出.
待补充 30
5.5 凸和非凸优化问题
凸优化问题是指最小化问题 (1.1.1) 中的目标函数和可行域分别是凸函
数和凸集.如果其中有一个或者两者都不是凸的,那么相应的最小化问题是非凸优化问题.因为凸优化问题的任何局部最优解都是全局最优解,其相应的算法设计以及理论分析相对非凸优化问题简单很多.
注意:若问题 (1.1.1) 中的 min 改为 max,且目标函数和可行域分别为
凹函数和凸集,我们也称这样的问题为凸优化问题.这是因为对凹函数求极大等价于对其相反数(凸函数)求极小.
在实际问题的建模中,我们经常更倾向于得到一个凸优化模型.另外,
判断一个问题是否是凸问题也很重要.比如,给定一个非凸优化问题,一种方法是将其转化为一系列凸优化子问题来求解.此时需要清楚原非凸问题中的哪个或哪些函数导致了非凸性,之后考虑的是如何用凸优化模型来逼近原问题.在压缩感知问题中,
ℓ
0
\ell_0
ℓ0 范数是非凸的,原问题对应的解的性质难以直接分析,相应的全局收敛的算法也不容易构造.利用 ℓ0 范数和 ℓ1 范数在某种意义上的等价性,我们将原非凸问题转化为凸优化问题.在一定的假设下,我们通过求解 ℓ1 范数对应的凸优化问题得到了原非凸优化问题的全局最优解.


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









