







找寻点 : 基于Transformer的结构应该怎么将中间特征去蒸馏到CNN结构中,两者结构差异很大很大。
论文链接:2209.02432.pdf (arxiv.org)
ABSTRACT:
传统的基于Logits的蒸馏方式,用于Transformer结构例如Vit是可以的,但是效率不够。基于中建特征的蒸馏方式应该怎么做呢?本文就是三种不同的方法,最后提出了一种基于中间特征的蒸馏方式:ViTKD,可以显著提高学生模型的效果。
INTRODUCTION
使用ViT去做基于中间特征的这种蒸馏方式,最近2022-MiniViT使用自注意力蒸馏和隐藏状态蒸馏。相对于logits蒸馏的方式,这种方式很受限。
作者进行了实验,使用DeiT-Small去蒸DeiT-Tiny,发现现在普遍使用的只是用最后一层去做损失,效果会下降。
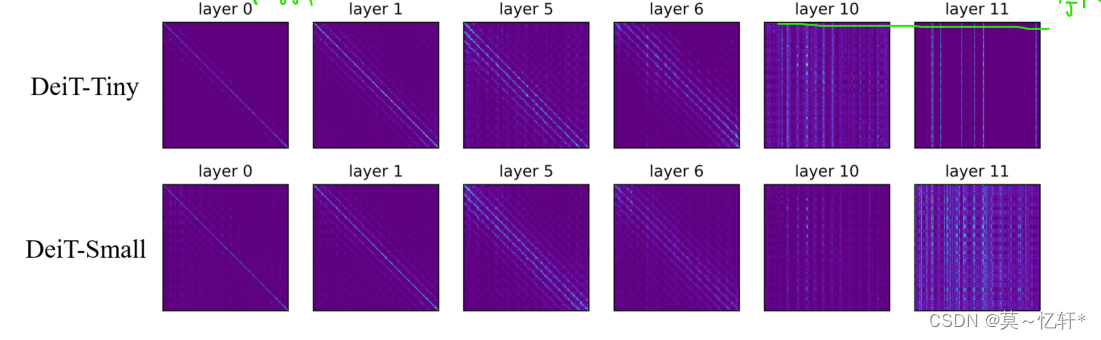
作者可视化了老师学生模型的每一层输出的特征图,如下图所示。从图中可以发现,对于浅层特征来说,老师和学生是比较相像的。对于深层特征来说,两者差异很大,说明在深层他们注意是在不同的tokens。说明要针对不同的层进行不同的处理。
基于此,本文就是针对浅层深层分别处理,来提出了三种不同的特征蒸馏方式,最后提出了蒸馏模型ViTKD。
2 PRACTICAL GUIDELINES FOR VIT'S FEATURE DISTILLATION
基于中间特征有两种策略:mimicking 和 generation
mimicking:对齐老师和学生的维度(线性层、相关矩阵)
generation:随机给学生token加掩码,再利用生成块去恢复(交叉注意力模块、自注意力模块、卷积投影)
- 深层适合使用generation方式
- 浅层适合使用mimicking,而且correlation matrix方法更好
- 使用FFN输出的特征会比直接使用MHA输出的特征进行蒸馏效果好
3 METHODOLOGY
简单介绍了2中策略下的5种变换方式
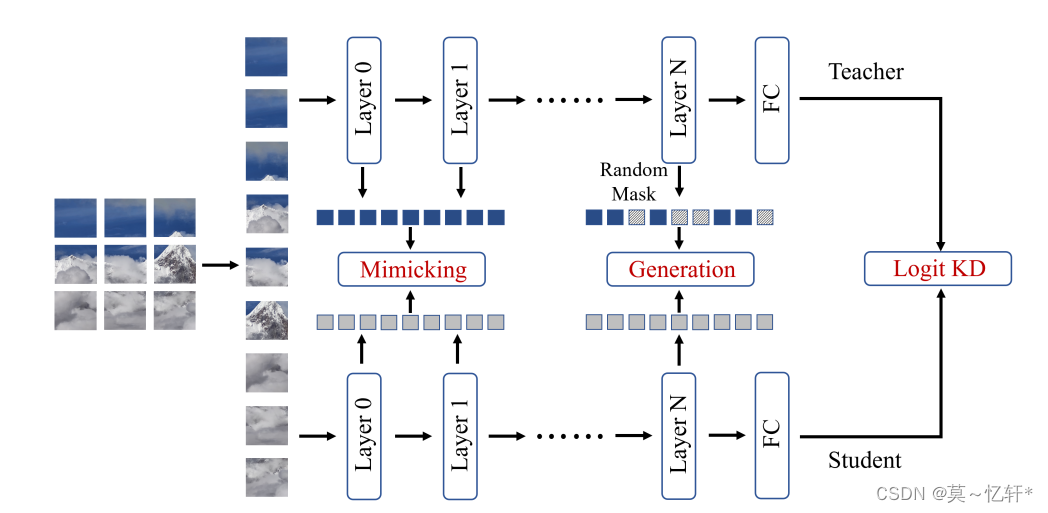
ViTKD整个网络图如下图:
使用的mimicking策略所使用的方式为:相关矩阵
使用的generation策略所使用的方式为:卷积投影
网络的整个损失如下:
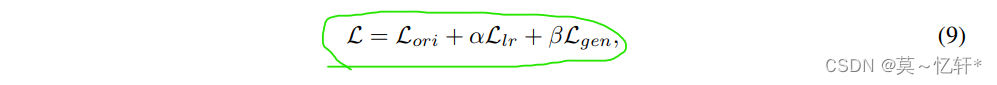
分别又KD损失、生成损失与模仿损失三部分组成。其中, KD损失中α=1 ,T= 1
4 EXPERIMENT
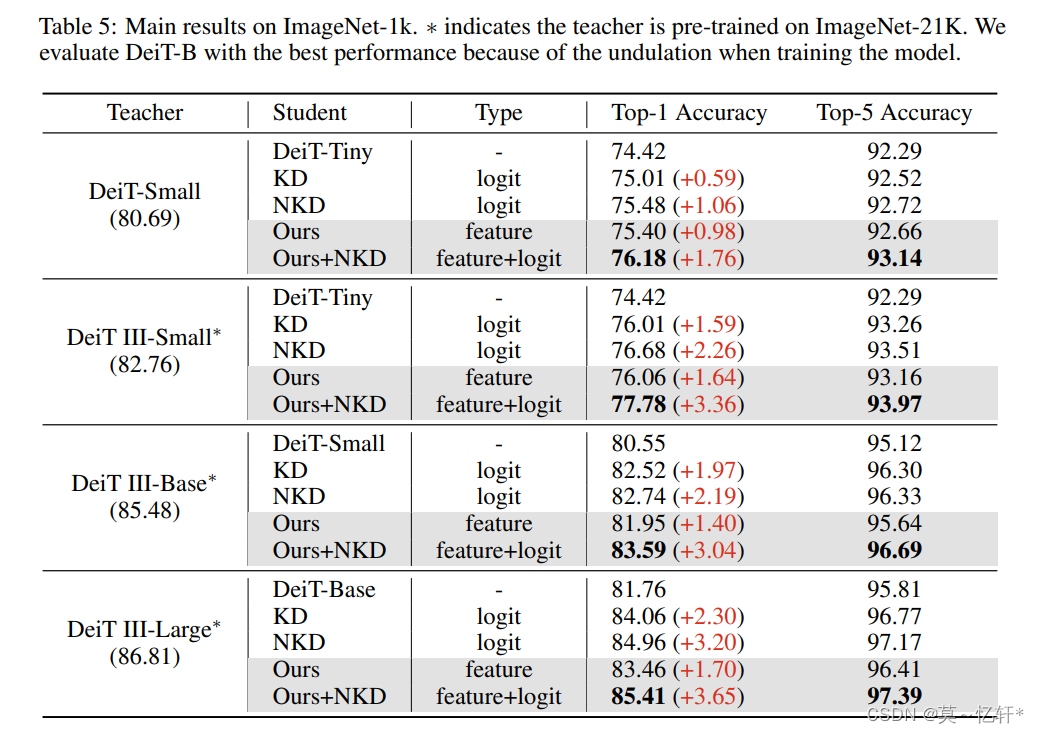
从实验结果来看,应用本文的蒸馏对于不同的模型都可以得到大大小小的效果提升。
5 MORE ANALYSES
浅层特征蒸馏是对效果提升最好的,这与基于CNN结构的蒸馏不同,两者之间可以互补。深层与浅层结合时,效果提高仅仅0.02%















 685
685











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









