







1.交叉熵
- 是用来衡量在给定的真实分布下,使用非真实分布指定的策略消除系统的不确定性所需要付出努力的大小
- 假定W的概率分布是正确的分类结果(把二分类扩展到多分类,那么这个结果就是第三类),其他结果是各种模型预测出来的结果。
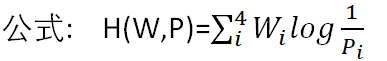
- 已知每一种情况的信息熵
| 天气【阴、晴、雨、雪】 | 信息熵 |
|---|---|
| P=[1/4,1/4,1/4,1/4] | H(P)=2 |
| Q=[1/4,1/8,1/2,1/8] | H(Q)=1.75 |
| Z=[1/8,1/16,3/4,1/16] | H(Z)=1.29 |
| W=[0,0,1,0] | H(W)=0 |
- 给定W的概率分布是正确的分类结果
| 天气【阴、晴、雨、雪】 | 交叉熵 |
|---|---|
| P=[1/4,1/4,1/4,1/4] | H(W,P)=2 |
| Q=[1/4,1/8,1/2,1/8] | H(W,Q)=1 |
| Z=[1/8,1/16,3/4,1/16] | H(W,Z)=0.415 |
| W=[0,0,1,0] | H(W,W)=0 |
H(W,P) = 0log4 + 0log4 + 1log4 + 0log4 = 2
H(W,Q) = 0log4 + 0log8 + 1log2 + 0log8 = 1
H(W,Z) = 0log8 + 0log4 + 1log4 + 0log4 = 0.415
- 对于二分类问题或者LR来说,相应的交叉熵损失函可以写成如下形式
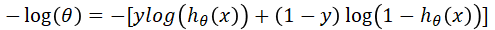
- 真实概率分布为 Z=[ y,1-y ]
- 预测概率分布为P=[ h(x),(1-h(x) ]
2.相对熵
- 相对熵是用来衡量两个概率分布之间的差异
- 根据上面的案例可以看到非真实分布Q得到的平均编码长度H(W,Q)大于根据真实分布W得到的平均编码长度H(W),我们将由Q得到的熵比由W得到的信息熵多出的bit数称为相对熵,又称为KL散度
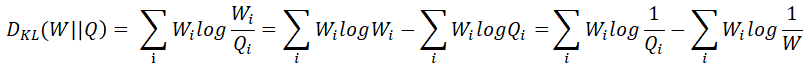
- H(W,Q) >= H(W) 当预测结果Q和实际结果W一致时,等号成立
相对熵 = 交叉熵 - 熵
3.决策时树常用的三种算法
- ID3
- C4.5
- CART
ID3算法
1.ID3算法:使用信息增益为准则来选择划分属性。根据样本子集属性取值的信息增益值的大小来选择决策属性,并根据该属性的不同取值生成决策树的分支,再对子集进行递归调用该方法,当所有子集的数据都只包含于同一个类别时结束。最后,根据生成的决策树模型,对新的、未知类别的数据对象进行分类。
2.信息增益:通俗的讲其实就是用整体的信息熵减去进行分组操作和得到的整体的信息熵
3.ID3算法的优点就是方法简单、计算量小、理论清晰、学习能力较强、比较适用于处理规模较大的学习问题。
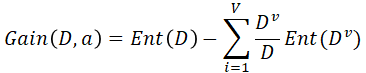
信息熵的计算公式:
1.信息熵:
2.进行分组后得到的整体信息熵
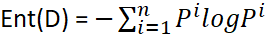
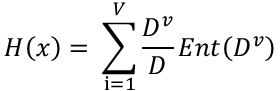
缺点:
1.没有考虑连续特征
2.采用了信息增益大的特征优先建立决策树的节点,但在相同条件下,一个对于预测无用的特征取了5个分支,而另一好的特征只有2个分支,分支多的信息增益大,算法会优先处理,但其实对于我们的预测斌没有好的帮助
3.对于缺失值没有考虑
4.没有考虑过拟合的问题
C4.5算法
- 为了减小使用信息增益为准则来选择划分属性的缺点,我们采用增益率来选择最优划分方案,这就是C4.5算法的思想
- 1.用信息增益率来选择属性,克服了用信息增益选择属性时偏向选择取值多的属性的不足;
2.在树构造过程中进行剪枝;
3.能够完成对连续属性的离散化处理;
4.能够对不完整数据进行处理。 - 优点: 产生的分类规则易于理解,准确率较高。
- 缺点: 矫枉过正,C4.5对更偏爱与分支少的特征,与ID3相反,实践中,先选取信息增益高于平均水平得到的属性,再从中选择增益率高的属性
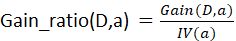
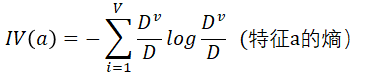
- 特征a的分支越多,混乱程度越大,熵越大
















 1137
1137











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











