







机器学习算法—朴素贝叶斯(分类方法)超详细!!!
相关概率论知识:
注:以下公式希望大家可以自己推导一下,有助于更好的理解我们的朴素贝叶斯算法,这一次的讲解,只是为了入门的宝贝可以更好的理解和 开始学会运用算法,后面的更新,将会是对于朴素贝叶斯算法的优化,基于这个例子的优化
1、相互独立事件:假设A、B相互独立,那么有:
**乘法公式:**P(AB)=P(A)*P(B)
2、表示事件B已经发生的前提下,事件A发生的概率,叫做事件B发生下事件A的条件概率。贝叶斯准则告诉我们,如果已知P(A|B),要求P(B|A),那么我们可以使用如下计算公式:
贝叶斯公式:
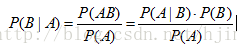
例子:
假设现分别有 A,B 两个容器,在容器 A 里分别有 7 个红球和 3 个白球,在容器 B 里有 1 个红球和 9 个白球,现已知从这两个容器里任意抽出了一个球,且是红球。
问这个红球是来自容器 A 的概率是多少?假设已经抽出红球为事件 B,从容器 A 里抽出球为事件 A,则有:P(B) = 8 / 20,P(A) = 1 / 2,P(B | A) = 7 / 10,按照公式,则有:P(A|B)=(7 / 10)*(1 / 2)/(8/20)=0.875。
原文链接:https://blog.csdn.net/hjimce/article/details/46054739
全概率公式
基本思想:
朴素贝叶斯为分类的一种算法,将各个样本在各个标签中的概率进行对比,并将样本归于概率最大的标签。(个人理解,可能不够完善,有误可评论或私发纠正,谢谢~~)
思路进阶:
一维:
我们现在有一个数据点X(点内有且只有一个特征),标签为C(C1,C2两个标签),现在需要对X进行分类。需要通过比较X为C1的概率P(C1|X)和X为C2的概率P(C2|X)
通过贝叶斯公式得出
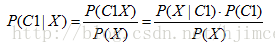
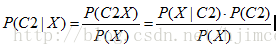
两者比较可以发现最后是分子之间大小的比较
多维:
我们现在有一个数据点X(点内有N个特征),标签为C(C1,C2两个标签),现在需要对X进行分类。需要通过比较X为C1的概率P(C1|X)和X为C2的概率P(C2|X)
通过贝叶斯公式得出
由于朴素贝叶斯算法的思想是假设各个特征值相互独立,于是X中N个特征值X1 X2…Xn相互独立
思路进阶重点!!!
数据点X中的各个特征值在标签C中必须同时成立,于是使用乘法公式化简可得:
P(X|C1)*P(C1)=P(X1|C1)P(X2|C1)……P(Xn|C1)*P(C1)
P(X|C2)*P(C2)=P(X1|C2)P(X2|C2)……P(Xn|C2)*P(C2)
最后比较两者概率大小即可进行分类
多个数据点分类即循环该算法
多个标签即循环计算各个数据点在各个标签中的概率
多个特征值即循环计算每个数据点的每个特征值在每个标签中的概率
代码实战!!
我们借用《机器学习实战》的例题来运用一下我们的朴素贝叶斯算法。这次我们的目的是将文档进行自动分类。
准备数据(将单词转换成数字)
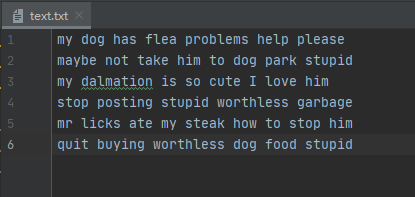
my dog has flea problems help please#复制放入新建的txt文件即可
maybe not take him to dog park stupid
my dalmation is so cute I love him
stop posting stupid worthless garbage
mr licks ate my steak how to stop him
quit buying worthless dog food stupid
定义一个load_data函数进行数据清洗:
def  最低0.47元/天 解锁文章
最低0.47元/天 解锁文章















 1135
1135











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









