 NLP发展历程:从机器翻译到深度学习的挑战与技术演变
NLP发展历程:从机器翻译到深度学习的挑战与技术演变








 本文回顾了自然语言处理(NLP)的历史,包括W.Weaver和A.D.Booth的早期工作,以及中文信息处理的发展。重点讨论了词法、句法、语义和语用歧义问题。NLP技术经历了理性主义符号逻辑、经验主义统计学习和神经网络连结主义的转变,强调了各阶段的优势和挑战。
本文回顾了自然语言处理(NLP)的历史,包括W.Weaver和A.D.Booth的早期工作,以及中文信息处理的发展。重点讨论了词法、句法、语义和语用歧义问题。NLP技术经历了理性主义符号逻辑、经验主义统计学习和神经网络连结主义的转变,强调了各阶段的优势和挑战。
学习目标:了解NLP
相关重要历史事件:
1.W. Weaver(上)和A.D. Booth(下)于1947-1949年间交流信件,其中提出机器翻译(machine translation, MT).


2.上个世纪70/80年代,出现了主要以中文汉语为处理对象的中文信息处理(Chinese information processing, CIP)
问题挑战:
1.词法歧义(morphological ambiguity):
门把手弄坏了->(1)门把手\弄坏了 (2)门\把\手\弄坏了
2.句法歧义(syntactic ambiguity):
今天吃馒头(没有问题);今天吃食堂(应该是今天去食堂吃饭);今天吃大碗(应该是几天吃大碗的饭菜)
3.语义歧义(semantic ambiguity):
他说:“她这个人真有意思(funny)”。她说:“他这个人怪有意思的(funny)”。于是人们以为他们有了意思(wish),并让他向她意思意思(express)。他火了:“我根本没有那个意思(thought)”!她也生气了:“你们这么说是什么意思(intention)”?事后有人说:“真有意思(funny)”。也有人说:“真没意思(nonsense)”。
4.语用歧义(pragmatic ambiguity):
要把权力装进制度的笼子;老虎苍蝇一起打;破四旧。
5.大量新型单词和句法的出现
技术方法:
1.1947-1990:理性主义、符号逻辑。基于单词的翻译和不同语言之间规则的转换而成。
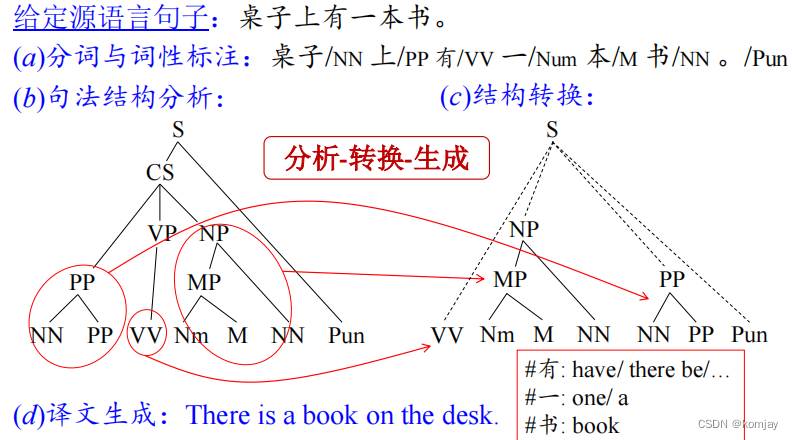
优势:保持原文结构、分析和转换等步骤可以追踪溯源。
劣势:转换规则需要人工编写、不利于扩展、可移植性差。
2.1990-2014:经验主义、统计学习。基于大量双语标注数据和统计概率模型设计。
优点:无需深层次分析、开发周期短。
弱点:需要大量优质双语句对、对生词不识别率低。
3.2014- :连结主义、神经网络。使用神经网络去取代统计学习中的概率模型。
优点:翻译能力目前最优。
弱点:需要大量优质语料、出现“幻觉”的译文


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









