







 文章介绍了一种利用文本、图像结构和语义表示新闻的模型,通过iMMoE进行信息融合,强调自举和多视图技术。模型包含预处理、编码、融合和重新加权步骤,实验结果显示在信息挖掘和参数效率方面表现出色,尽管整体性能有待提升。
文章介绍了一种利用文本、图像结构和语义表示新闻的模型,通过iMMoE进行信息融合,强调自举和多视图技术。模型包含预处理、编码、融合和重新加权步骤,实验结果显示在信息挖掘和参数效率方面表现出色,尽管整体性能有待提升。
一、概述
文章提出了三种视图信息来表示一篇新闻:文本、图像结构、图像语义。然后设计了改进的多门混合专家系统(iMMoE)来进行信息融合。保留单模态信息来保证特征对新闻的保真性,增加的多模态信息能保证不同模态的一致性,从而提高整体模型的识别能力。
二、原理
如文章标题所写,文章有两个关键点“Boostrapping”(中文直译为:自举)和“多视图”,其中,多视图指的是新闻的照片和文字两种模态所组成的4种特征,分别为单视图的图片结构特征(IP)、单视图的图片语义特征(IS)、单视图的文本特征(T)、将图片语义特征与文本特征结合的融合特征(CC)。
然后自举实际上是一种集成学习的方法,一个专家系统(MoE),而文章对原来的专家系统技术进行了改进,加入了门结构后能够更好地控制专家们的输出,而且可以设计多套门结构来获取多个输出。文章将其命名为Improved MMoE(即iMMoE)。
三、模型架构
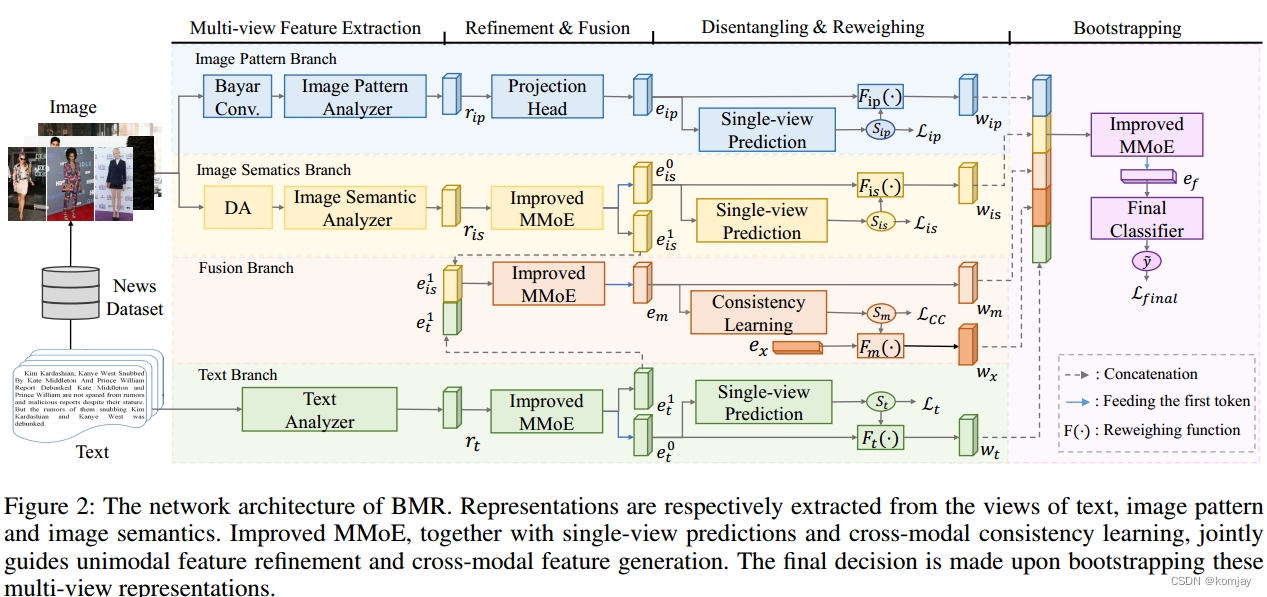
文章总体的模型架构如上图所展示,接下来我们从左到右、从上到下,来看其框架。
1.Multi-view Feature Extraction
Bayar Conv块是一种图形预处理方法,其能帮助后面的编码块(Image Pattern Analyzer)更关注图像的结构特征,忽视语义特征;DA块指的是数据增强模块,其对图片进行翻转、颜色变换来获得新的图片,从而让后面的编码块(Image Semantic Analyzer)更关注图片的语义信息。
然后三个分析块(编码块)都是使用别人训练好的模型来对前面的数据进行编码,训练过程不调参。IP编码块使用预训练好的InceptionNet-V3来提取图像结构信息;IS编码块使用Masked Autoencoder
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 341
341

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









