







 文章介绍了在多模态领域中解决一致性对齐和交互融合问题的方法,提出MRHFR模型,结合新闻文本和图像信息,通过融合策略和用户评论判断,提升虚假新闻检测性能。实验结果显示该方法的有效性和潜在的模态融合扩展性。
文章介绍了在多模态领域中解决一致性对齐和交互融合问题的方法,提出MRHFR模型,结合新闻文本和图像信息,通过融合策略和用户评论判断,提升虚假新闻检测性能。实验结果显示该方法的有效性和潜在的模态融合扩展性。
一、概述
在多模态领域中,主要存在两个核心问题:一致性对齐问题和交互融合问题。一致性对齐问题主要指不同模态的信息匹配,例如实体对齐、语义对齐,例子有:文本中的“男人”与图片中男子指代一个人。交互融合问题指不同模态的信息如何进行合理的融合。
本文提出一种新型的将新闻文本和图像两种模态进行融合的方法,以提升对虚假新闻的检测。
二、原理
首先可以知道,MRHFR所使用的多模态数据是:新闻图像、新闻文章和用户对新闻的评论。主要处理的就是图像信息和文本信息。其中,图像使用vgg-19来提取特征,文本(包括新闻文章和评论)使用Bert来提取,两个模型都是使用预训练好的模型。
在将新闻图像和新闻文章相互融合过程,文章提出三种融合方法,分别是Glimpse-Text&Read-Image、Read-Text&Glimpse-Image和Read-Text&Read-Image。其分别表示3种人类阅读习惯:粗看(瞥一眼)文章&细看(阅读)图片、细看文章&粗看图片、细看文章&细看图片。(编者注:感觉这3个习惯挺无厘头的,但是最后确实起到了效果)三种融合的特征会一并使用到最后的新闻检测中
其中,还需要使用用户评论去判修正三种融合特征向量,即给三个向量赋予权重,确定哪个更为重要。
三、模型架构
MRHFR的模型架构如下所示:
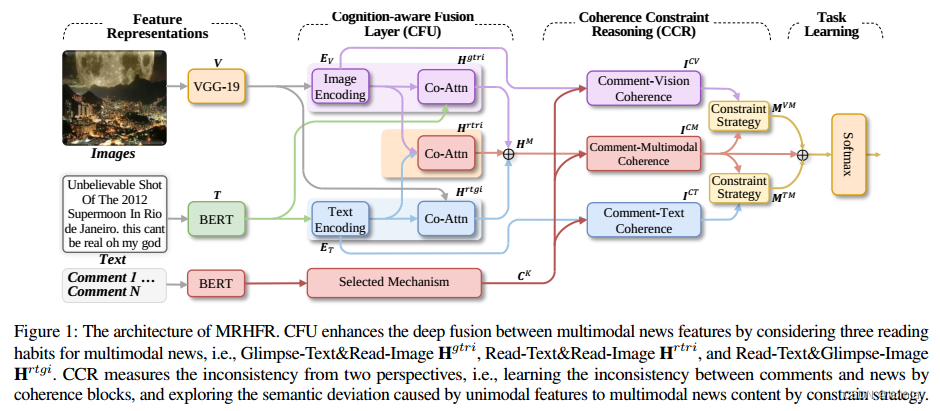
按照上面原理所讲, 其训练过程分4步,第一步是提取图像和文本的基础特征(Feature Representations,特征表征),第二步是将新闻文本特征和新闻图像特征分三种方法进行融合(Cognition-aware Fusion Layer,认知感知融合层),同时基于相似度选取最具综合性的几条评论以作下一步的备用。第三步是使用评论信息去约束融合特征,然后计算粗看特征与细看特征之间的差异,使用该差异再去设置3个特征之间的权重(CCR,一致性约束推理)。最后到第四步进行拼接检测(Task Learning,任务学习)。
1.特征表征
这一块并没啥需要细讲的,其中获取图像的VGG-19的结果后,作者直接使用一层全连接层和sigmoid激活函数将多通道信息汇总到一块。
![]()
公式如上,W是全连接层参数,是VGG-19得到的图像信息,
是sigmoid函数。
2.(评论)选择机制
由于一个新闻的评论区有许多评论,搜集到的评论也有很多,需要从中筛选最具代表性的几条评论。其使用的方法也是简单的,先使用全连接层对所有评论进行处理,得到每条评论的特征向量,再根据评分向量点乘计算任意两条评论的差异性,选择差异性
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









