







一、Softmax回归
Softmax是逻辑回归在多分类问题上的扩展,适合有k类情况下的分类任务。
1.1 Softmax回归的期望函数和代价函数
首先看下逻辑回归的假设函数:
更多逻辑回归请戳:
http://blog.csdn.net/qq_33414271/article/details/78191489
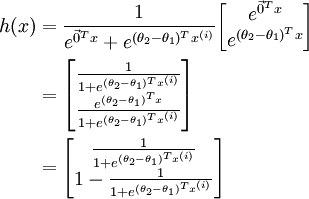
有上面可以看出
hθ
和
e−θTx
是正相关的,而Softmax回归和logistic 回归的在形式上也很类似,其中Softmax将x分类为类别j的概率为:
所以Softmax回归的期望函数为:
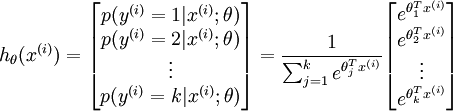
同样的,也可以知道Softmax回归的代价函数:
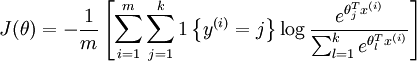
1 { 值为真的表达式}=1,也就是 1{2+2=4} 的值为1, 1{2+2=5} 的值为0
上式代价函数的意思是说如果预测预测为类别j的概率越小,分类的错误就越大。
1.2 Softmax回归参数的特点
Softmax 回归有一个不寻常的特点,就是给参数加/减一个数,分类的概率不变:
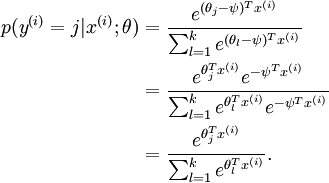
这就说我们设其中某个参数为0,也不影响最终的概率值,而且Softmax 回归的代价函数是一个凸函数,所以也不存局部最优解,但是 Hessian 矩阵是奇异的/不可逆的,这会直接导致采用牛顿法优化就遇到数值计算的问题。
实际应用中为了使算法实现更简单清楚,不任意地将某一参数设置为 0。但此时我们需要对代价函数做一个改动:加入权重衰减。权重衰减可以解决 softmax 回归的参数冗余所带来的数值问题。
通过下图的权重衰减项惩罚过大的参数值,此时代价函数就变成了严格的凸函数,这样就可以保证得到唯一的解了。 此时的 Hessian矩阵变为可逆矩阵。
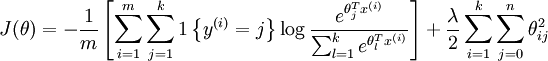
1.3 Softmax回归与Logistic 回归的关系
当类别数 \textstyle k = 2 时,softmax 回归退化为 logistic 回归。这表明 softmax 回归是 logistic 回归的一般形式。
Q:什么时候用softmax回归,什么时候用k个二元分类器呢?
A:这一选择取决于你的类别之间是否互斥:
- 四个类别的音乐,分别为:古典音乐、乡村音乐、摇滚乐和爵士乐,那么你可以假设每个训练样本只会被打上一个标签,此时选择softmax回归
- 四个类别如下:人声音乐、舞曲、影视原声、流行歌曲,那么这些类别之间并不是互斥的,使用4个二分类的 logistic 回归分类器更为合适。
二、自我学习
用机器学习算法训练模型,模型的好坏往往取决于是否有足够的数据,但不是每种应用场景中都有标记好的数据,实际上,大规模的标记数据给算法训练是很耗费人力物力的一件事情,那有没有什么方法让算法自己学习呢?
这就涉及到无监督学习和自我学习了,常见的无监督学习方式有两种:
1.自我学习:
目标是区分汽车和摩托车图像;哪里可以获取大量的未标注数据呢?最简单的方式可能是从互联网上下载一些随机的图像数据集,在这些数据上训练出一个稀疏自编码器,从中得到有用的特征。
这个例子里,未标注数据完全来自于一个和已标注数据不同的分布(未标注数据集中,或许其中一些图像包含汽车或者摩托车,但是不是所有的图像都如此)。这种情形被称为自学习。
2.半监督学习:
如果有大量的未标注图像数据,要么是汽车图像,要么是摩托车图像,仅仅是缺失了类标号(没有标注每张图片到底是汽车还是摩托车)。也可以用这些未标注数据来学习特征。
这种方式,即要求未标注样本和带标注样本服从相同的分布,有时候被称为半监督学习。在实践中,常常无法找到满足这种要求的未标注数据(到哪里找到一个每张图像不是汽车就是摩托车,只是丢失了类标号的图像数据库?)因此,自学习在无标注数据集的特征学习中应用更广。
三、建立分类用的深度网络

在自我学习中,我们首先利用未标注数据训练一个稀疏自编码器。随后,给定一个新样本 x,我们通过隐含层提取出特征a。
考虑利用这个方法所学到的分类器(输入-输出映射)。它描述了一个把测试样本 x 映射到预测值 p(y=1|x) 的函数。将此前的两张图片结合起来,就得到该函数的图形表示。
这个最终分类器整体上显然是一个大的神经网络。因此,在训练获得模型最初参数(利用自动编码器训练第一层,利用 logistic/softmax 回归训练第二层)之后,我们可以进一步修正模型参数,进而降低训练误差。具体来说,我们可以对参数进行微调,在现有参数的基础上采用梯度下降或者 L-BFGS 来降低已标注样本集 上的训练误差。
但这还是一个非常浅层的神经网络,因为隐层只有一个,深度神经网络,即含有多个隐藏层的神经网络。通过引入深度网络,我们可以计算更多复杂的输入特征。因为每一个隐藏层可以对上一层的输出进行非线性变换,因此深度神经网络拥有比“浅层”网络更加优异的表达能力(例如可以学习到更加复杂的函数关系)。
值得注意的是当训练深度网络的时候,每一层隐层应该使用非线性的激活函数 ,这是因为多层的线性函数组合在一起本质上也只有线性函数的表达能力(例如,将多个线性方程组合在一起仅仅产生另一个线性方程)。因此,在激活函数是线性的情况下,相比于单隐藏层神经网络,包含多隐藏层的深度网络并没有增加表达能力。
2.1 深层神经网络的优势
-
当处理对象是图像时,我们能够使用深度网络学习到“部分-整体”的分解关系。例如,第一层可以学习如何将图像中的像素组合在一起来检测边缘(正如我们在前面的练习中做的那样)。第二层可以将边缘组合起来检测更长的轮廓或者简单的“目标的部件”。在更深的层次上,可以将这些轮廓进一步组合起来以检测更为复杂的特征。
-
大脑皮层同样是分多层进行计算的。例如视觉图像在人脑中是分多个阶段进行处理的,首先是进入大脑皮层的“V1”区,然后紧跟着进入大脑皮层“V2”区,以此类推。
2.2 深层神经网络的困难
-
数据获取问题
有标签的数据通常是稀缺的,因此对于许多问题,我们很难获得足够多的样本来拟合一个复杂模型的参数。例如,考虑到深度网络具有强大的表达能力,在不充足的数据上进行训练将会导致过拟合。 -
局部极值问题
使用监督学习方法来对浅层网络(只有一个隐藏层)进行训练通常能够使参数收敛到合理的范围内。但是当用这种方法来训练深度网络的时候,并不能取得很好的效果。特别的,使用监督学习方法训练神经网络时,通常会涉及到求解一个高度非凸的优化问题,种非凸优化问题的搜索区域中充斥着大量“坏”的局部极值,因而使用梯度下降法(或者像共轭梯度下降法,L-BFGS等方法)效果并不好。 -
梯度弥散问题
梯度下降法(以及相关的L-BFGS算法等)在使用随机初始化权重的深度网络上效果不好的技术原因是:梯度会变得非常小。具体而言,当使用反向传播方法计算导数的时候,随着网络的深度的增加,反向传播的梯度(从输出层到网络的最初几层)的幅度值会急剧地减小。结果就造成了整体的损失函数相对于最初几层的权重的导数非常小。这样,当使用梯度下降法的时候,最初几层的权重变化非常缓慢,以至于它们不能够从样本中进行有效的学习。这种问题通常被称为“梯度的弥散”.
2.2 逐层贪婪训练
有什么好的办法可以训练深层神经网络的吗?
逐层贪婪训练会是一个不错的办法。
简单来说,逐层贪婪算法的主要思路是每次只训练网络中的一层,即我们首先训练一个只含一个隐藏层的网络,仅当这层网络训练结束之后才开始训练一个有两个隐藏层的网络,以此类推。
在每一步中,我们把已经训练好的前 k-1 层固定,然后增加第 k 层(也就是将我们已经训练好的前 k-1 的输出作为输入)。每一层的训练可以是有监督的(例如,将每一步的分类误差作为目标函数),但更通常使用无监督方法(例如自动编码器)。
举个栗子
假设训练一个识别MNIST手写数字分类的任务

首先,需要用原始输入训练一个自编码器,它能够学习得到原始输入的一阶特征表示 h(1)
接着,你需要把原始数据输入到上述训练好的稀疏自编码器中,对于每一个输入都可以得到它对应的一阶特征表示 h(1) ,然后你再用这些一阶特征作为另一个稀疏自编码器的输入,使用它们来学习二阶特征 h(2)
再把一阶特征输入到刚训练好的第二层稀疏自编码器中,你可以把这些二阶特征作为softmax分类器的输入,训练得到一个能将二阶特征映射到数字标签的模型。
如果网络的输入数据是图像,网络的第一层会学习如何去识别边,第二层一般会学习如何去组合边,从而构成轮廓、角等。更高层会学习如何去组合更形象且有意义的特征。例如,如果输入数据集包含人脸图像,更高层会学习如何识别或组合眼睛、鼻子、嘴等人脸器官。















 6273
6273

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









