






最近能明显感觉到大模型发展日新月异,一周不追踪业内最新动态,自己的知识储备就已经落后了,以后会不定期将最近最新的一些热点论文进行汇总,内容涵盖论文大纲+创新点总结+实验效果,旨在快速了解最新的技术,会对其中重要的论文另外展开详细解读。
1. Qwen2.5-Omni Technical Report
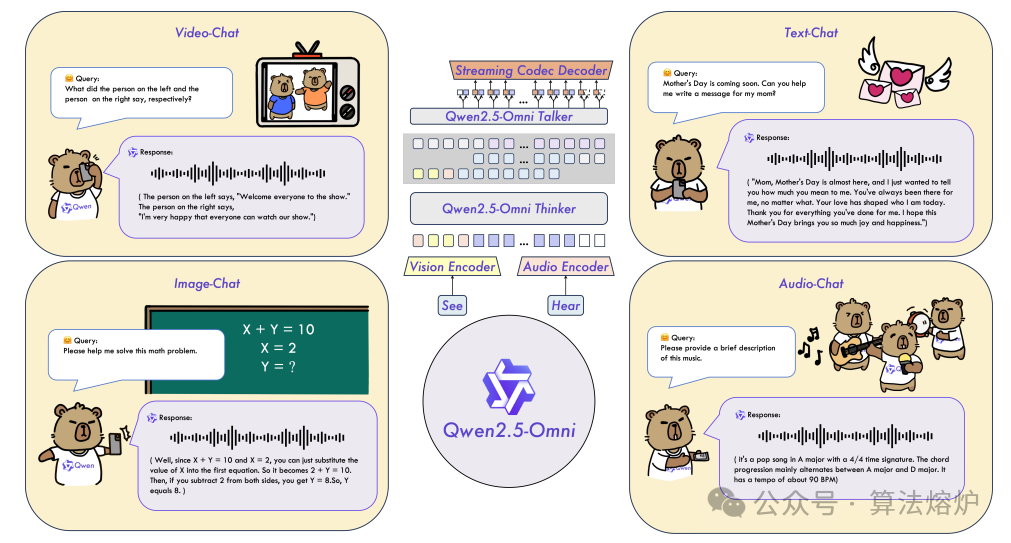
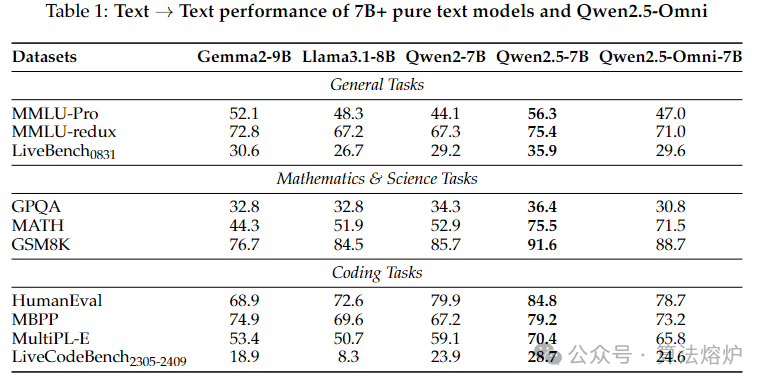
Qwen2.5-Omni是一款端到端的多模态模型,旨在感知多种模态信息,包括文本、图像、音频和视频,同时以流式方式生成文本和自然语音回复。为实现多模态信息的流式输入,音频和视觉编码器均采用分块处理方法。该策略有效地将长序列多模态数据的处理解耦,将感知任务交给多模态编码器,而将长序列建模任务交给大语言模型。这种分工通过共享注意力机制增强了不同模态的融合。为使视频输入与音频的时间戳同步,我们以交错方式按顺序组织音频和视频,并提出一种名为TMRoPE(时间对齐多模态旋转位置嵌入,Time-aligned Multimodal RoPE)的新型位置嵌入方法。为了在同时生成文本和语音的情况下避免两种模态之间的干扰,我们提出了Thinker-Talker架构。在该框架中,Thinker作为负责文本生成的大语言模型,而Talker是一个双轨自回归模型,它直接利用Thinker的隐藏表示来生成音频令牌作为输出。Thinker和Talker模型均设计为可进行端到端的训练和推理。为了以流式方式解码音频令牌,我们引入了一种限制感受野的滑动窗口扩散隐式模型(Diffusion Implicit Model,DiT),旨在减少初始数据包延迟。Qwen2.5-Omni与类似规模的Qwen2.5-VL性能相当,并且在图像和音频能力方面优于Qwen2-Audio。此外,Qwen2.5-Omni在诸如Omni-Bench等多模态基准测试中取得了最先进的成绩。值得注意的是,通过MMLU(大规模多任务语言理解基准,Massive Multitask Language Understanding)和GSM8K(小学数学应用题基准,Grade School Math 8K)等基准测试表明,Qwen2.5-Omni在端到端语音指令跟随方面的表现与文本输入能力相当。在语音生成方面,Qwen2.5-Omni的流式Talker在稳健性和自然度上优于大多数现有的流式和非流式模型。
模型/框架结构

论文大纲
创新点总结
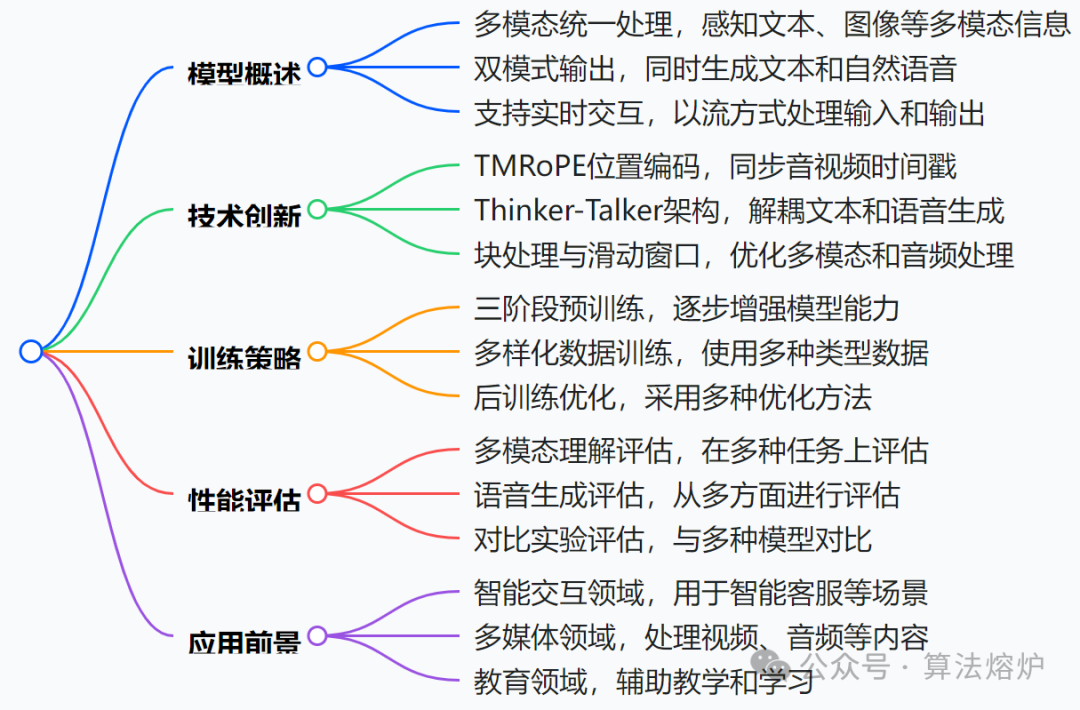
本文介绍的Qwen2.5-Omni模型在多模态处理、架构设计、位置编码、训练与生成等方面进行创新,以实现高效多模态交互,在性能上优于同类模型。
1. 多模态处理与架构创新:提出Thinker-Talker架构,Thinker负责处理多模态输入、生成文本,Talker基于Thinker的输出生成语音,二者协同实现端到端训练和推理,有效避免文本和语音生成的干扰。音频和视觉编码器采用块处理方法,将长序列多模态数据处理解耦,结合共享注意力机制,增强不同模态融合,实现多模态信息的高效流式输入。
2. 位置编码创新:提出TMRoPE位置嵌入方法,通过将音频和视频按交错方式组织,编码多模态输入的三维位置信息,同步音频和视频时间戳,提升模型对多模态信息的理解和分析能力。
3. 语音生成与训练创新:采用滑动窗口DiT解码音频令牌,限制感受野,减少初始包延迟,实现高效的流式语音生成。Talker采用三阶段训练,包括上下文延续学习、DPO增强稳定性、多说话人指令微调提升自然度和可控性,提高了语音生成的质量。
实验效果
论文链接:https://arxiv.org/pdf/2503.20215
2. DAPO: An Open-Source LLM Reinforcement Learning System at Scale
推理扩展赋予大语言模型(LLMs)前所未有的推理能力,其中强化学习是引发复杂推理的核心技术。然而,最先进的推理大语言模型的关键技术细节被隐瞒了(例如在OpenAI的o1博客和DeepSeek的R1技术报告中),因此研究社区仍然难以重现它们的强化学习训练结果。我们提出了解耦裁剪和动态采样策略优化(DAPO)算法,并完全开源了一个最先进的大规模强化学习系统,该系统使用Qwen2.5 - 32B基础模型在2024年美国数学邀请赛(AIME)中获得了50分。与之前隐瞒训练细节的工作不同,我们介绍了算法的四项关键技术,这些技术使大规模大语言模型的强化学习取得成功。此外,我们开源了基于verl框架构建的训练代码,以及经过精心整理和处理的数据集。我们开源系统的这些组件提高了可重复性,并为未来大规模大语言模型强化学习的研究提供了支持。
模型/框架结构

论文大纲
创新点总结
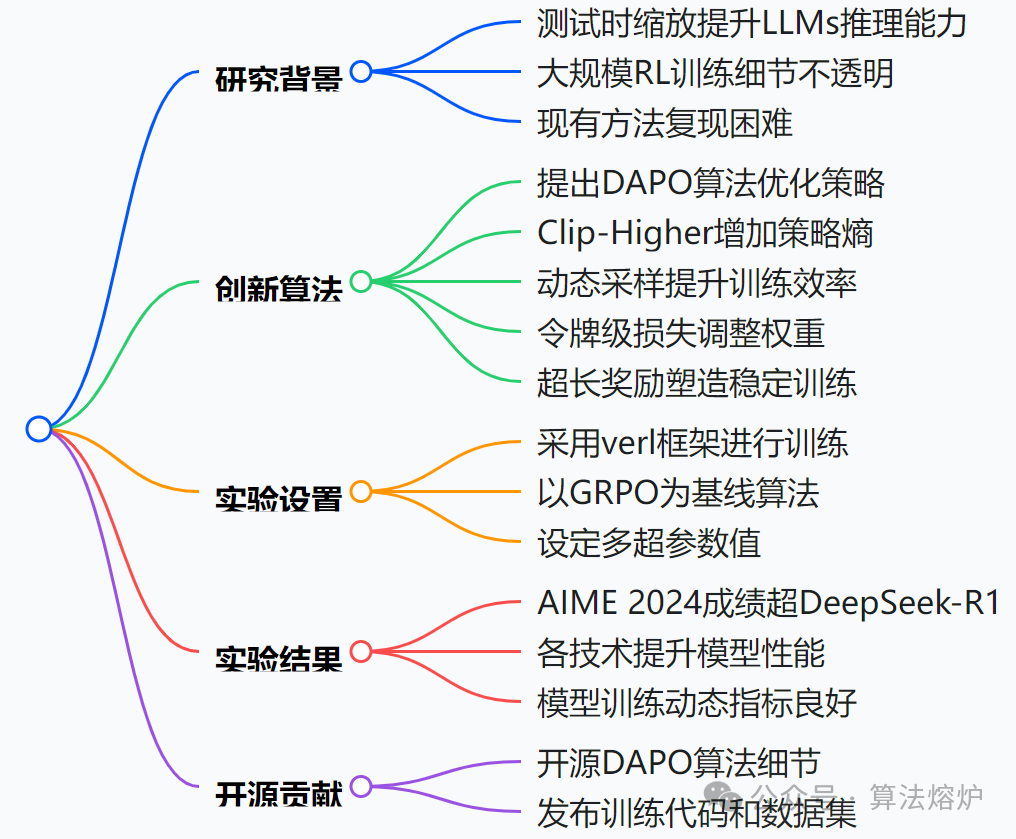
主要创新点在于提出DAPO算法、公开大规模RL系统以及通过实验验证算法有效性,为大语言模型强化学习研究提供新方向和资源。
1. 提出DAPO算法:创新地提出解耦裁剪和动态采样策略优化(DAPO)算法,针对大规模LLM的强化学习场景设计,提升模型训练效果。在传统近端策略优化(PPO)和组相对策略优化(GRPO)基础上,引入Clip-Higher、动态采样、令牌级策略梯度损失和超长奖励塑造等关键技术,解决训练中熵坍缩、梯度递减、样本权重不合理和奖励噪声等问题,增强策略多样性、训练效率、模型稳定性和对长推理链的学习能力。
2. 开源大规模RL系统:完全开源基于Qwen2.5-32B的大规模RL系统,涵盖算法、训练代码和数据集。使用verl框架搭建训练代码,整理出DAPO-Math-17K数据集,提高研究的可重复性,为相关领域研究提供资源和基础,推动大规模LLM RL的发展。
3. 实验验证算法有效性:以数学任务为评估场景,通过AIME 2024实验证明DAPO算法的有效性。用DAPO训练的Qwen-32B基础模型在AIME 2024上达到50分,超过DeepSeek-R1-Zero-Qwen-32B的47分,且训练步数仅为其50%。
实验效果
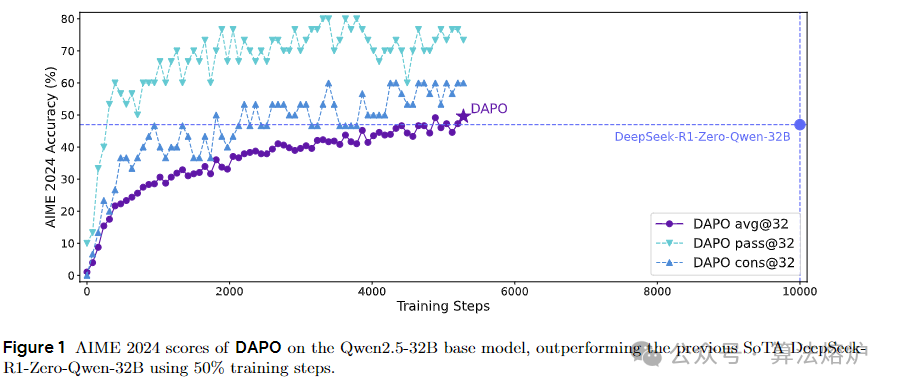
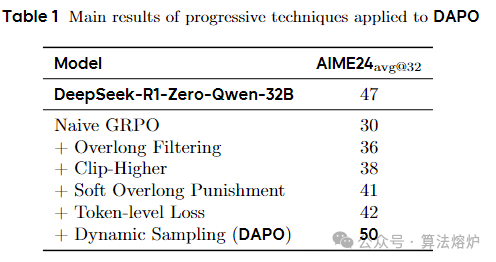
论文链接:https://arxiv.org/pdf/2503.14476
3. Transformers without Normalization
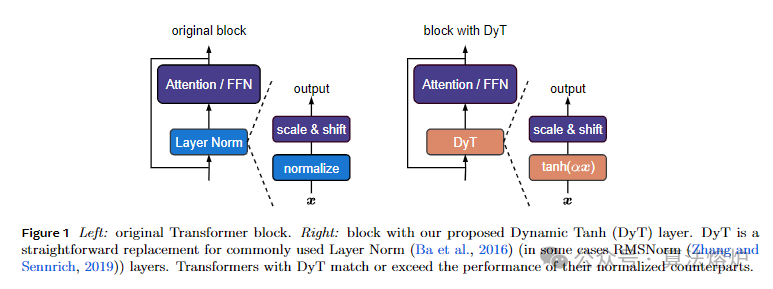
归一化层在现代神经网络中无处不在,长期以来一直被认为是至关重要的。这项工作表明,通过一种非常简单的技术,不含归一化层的Transformer模型也能达到相同甚至更好的性能。我们引入了动态双曲正切(Dynamic Tanh,DyT),这是一种逐元素操作,定义为DyT(x)=tanh(alpha x),可直接替代Transformer中的归一化层。DyT的灵感来自于观察到Transformer中的层归一化常常产生类似双曲正切函数的S形输入-输出映射。通过融入DyT,不含归一化层的Transformer模型在大多无需调整超参数的情况下,能够达到甚至超越含有归一化层的同类模型的性能。我们在从识别到生成、监督学习到自监督学习、计算机视觉到语言模型等多种场景下,验证了使用DyT的Transformer模型的有效性。这些发现挑战了传统观念中归一化层在现代神经网络中不可或缺的认知,并为深入理解归一化层在深度网络中的作用提供了新的视角。
模型/框架结构
论文大纲
创新点总结
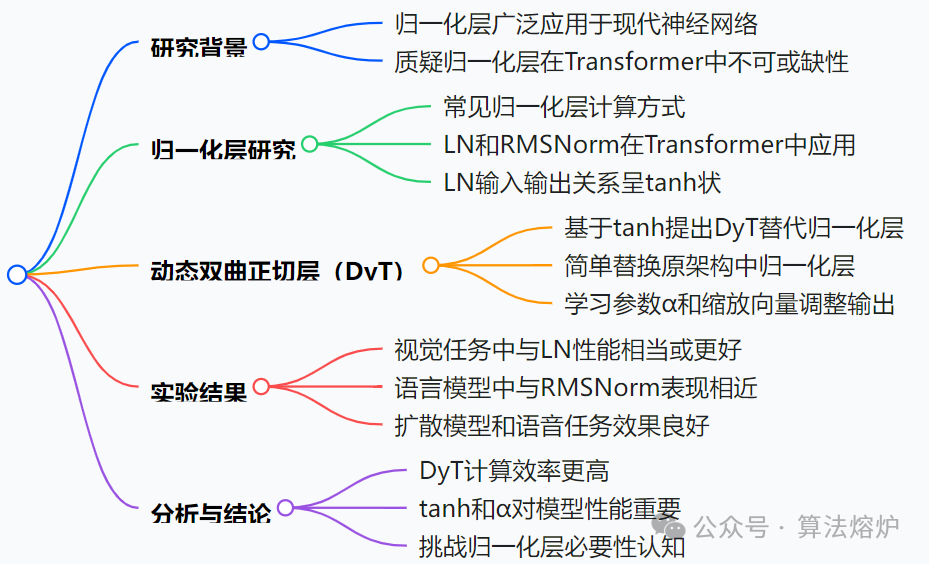
文章的主要创新点围绕动态双曲正切(DyT)展开,涵盖提出新型组件、验证广泛有效性、分析关键特性、对比其他方法及优化超参数初始化等方面。
1. 提出DyT替代归一化层:创新性地提出DyT作为Transformer中归一化层的替代方案。基于观察到层归一化(LN)常产生类似双曲正切(tanh)的输入输出映射,设计了的逐元素操作。它通过可学习参数α调整输入缩放,利用tanh函数压缩极端值,在不计算激活统计量的情况下模拟归一化层效果,且能保持输入中心部分的近似线性变换。
2. 验证DyT有效性:在多种任务和领域广泛验证了DyT的有效性。在视觉任务中,无论是监督学习的图像分类(如ViT和ConvNeXt在ImageNet-1K上的分类),还是自监督学习的掩码自动编码器(MAE)和DINO,使用DyT的模型与含LN的模型性能相当或更优;在语言模型(如LLaMA)训练中,DyT与默认的RMSNorm表现相近;在扩散模型(如DiT)、语音自监督学习(如wav2vec 2.0)以及DNA序列建模(如HyenaDNA和Caduceus模型)任务中,DyT也都取得了不错的效果 。
3. 分析DyT特性:对DyT的计算效率、tanh函数和α的作用等进行深入分析。计算效率方面,在LLaMA 7B模型上,DyT层相比RMSNorm层显著减少了推理和训练时间。消融实验表明,tanh函数对稳定训练至关重要,使用其他替代函数(如hardtanh、sigmoid)或去掉tanh(用恒等函数替代)会导致训练不稳定甚至发散,且tanh性能最佳;可学习参数α对模型性能也至关重要,去除α会导致性能下降,训练过程中α与激活的标准差倒数紧密相关,其最终值与输入激活的标准差倒数也有很强的相关性 。
4. 对比其他去归一化方法:将DyT与其他去除归一化层的方法(如基于初始化的Fixup、SkipInit)进行对比。在不同配置下,DyT始终优于这些方法,证明了其在实现无归一化层训练方面的优越性。
5. 优化α初始化:研究了α初始化对模型性能的影响。发现非语言模型对α初始化相对不敏感,α_0在0.5 - 1.2范围内通常能取得较好结果,默认设置α_0 = 0.5可保证训练稳定性和性能;而语言模型(LLMs)对α初始化较为敏感,调整α_0能显著提升性能,且较大模型需要较小的α_0值,注意力块中的DyT层使用较大α_0值、其他位置使用较小α_0值可提升性能,模型宽度对α_0的选择影响较大,深度影响较小。
实验效果
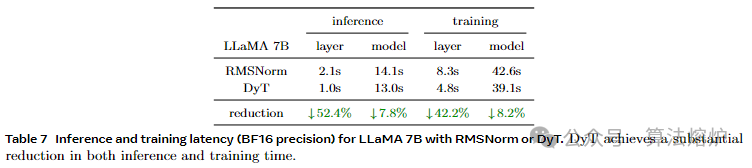
论文链接:https://arxiv.org/pdf/2503.10622
4. Feature-Level Insights into Artificial Text Detection with Sparse Autoencoders
随着先进大语言模型(LLMs)的兴起,人工文本检测(ATD)变得越来越重要。尽管人们付出了诸多努力,但没有一种算法能够在不同类型的未知文本上始终表现良好,也无法保证对新的大语言模型具有有效的泛化能力。可解释性在实现这一目标的过程中起着至关重要的作用。在本研究中,我们通过使用稀疏自动编码器(SAE)从Gemma-2-2b的残差流中提取特征,增强了人工文本检测的可解释性。我们识别出了具有可解释性和有效性的特征,并通过特定领域和模型的统计数据、引导方法以及手动或基于大语言模型的解释,分析了这些特征的语义和相关性。我们的方法为了解不同模型生成的文本与人类撰写的内容之间的差异提供了宝贵的见解。我们发现,现代大语言模型具有独特的写作风格,尤其是在信息密集型领域,即便它们可以通过个性化提示生成类似人类写作的内容。
模型/框架结构
论文大纲
创新点总结
文章提出用稀疏自动编码器(SAEs)分析人工文本检测(ATD)数据集中的特征,增强检测的可解释性,帮助理解文本生成和检测机制。
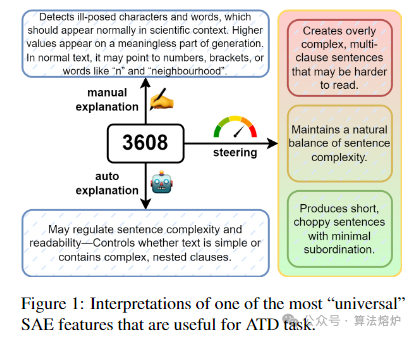
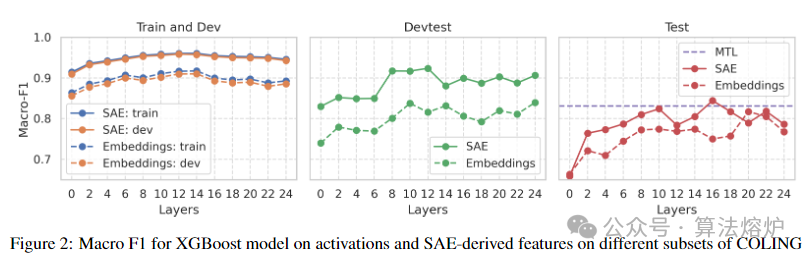
1. 多维度特征分析:运用SAEs从Gemma-2-2b模型的残差流中提取特征,突破传统检测方法的局限,从领域和模型特定统计、引导方法、手动及基于LLM的解释等多维度分析特征的语义和相关性。不仅能识别通用特征,还能发现领域或模型特定的特征,如通用特征3608和4645在多领域和模型表现良好,而像arXiv领域的12390号特征则体现特定领域文本的异常语法。
2. 提升可解释性:在ATD任务中引入SAEs,将提取的特征分为话语特征、噪声特征和风格特征,增强了检测的可解释性。通过手动解释和特征引导技术,深入理解每个特征的作用,如特征3608与文本的句子复杂度相关,强激活时会生成复杂多从句的句子,为判断文本是否由人工智能生成提供了清晰的依据。
3. 揭示模型写作风格差异:研究发现现代LLMs在信息密集领域有独特写作风格。即使通过个性化提示生成看似人类的文本,仍存在可检测的模式,如LLM生成文本存在过度复杂、断言性强、冗长介绍、重复和形式化等特点,而这些特点可通过SAEs提取的特征来识别。
4. 评估特征鲁棒性:基于RAID数据集评估分类器对有害表面特征和不同类型攻击的敏感性,分析特征在面对攻击时的表现,发现对攻击敏感的特征与重要检测特征重叠少,为进一步提升ATD系统的鲁棒性提供了参考 。
实验效果
论文链接:https://arxiv.org/pdf/2503.03601
5. I Have Covered All the Bases Here: Interpreting Reasoning Features in Large Language Models via Sparse Autoencoders
大语言模型(LLMs)在自然语言处理领域取得了显著成功。最近的进展催生了一类新的具备推理能力的大语言模型,例如,开源的DeepSeek-R1通过整合深度思考和复杂推理,取得了最先进的性能。尽管这些模型具备令人瞩目的能力,但其内部推理机制仍有待探索。
在这项工作中,我们使用稀疏自动编码器(SAEs)—— 一种将神经网络的潜在表示学习为可解释特征的稀疏分解方法,来识别在DeepSeek-R1系列模型中驱动推理的特征。首先,我们提出一种从SAEs表示中提取候选 “推理特征” 的方法。我们通过实证分析和可解释性方法对这些特征进行验证,证明它们与模型的推理能力直接相关。至关重要的是,我们证明了对这些特征进行调控能系统性地提高推理性能,首次为大语言模型的推理提供了一种机制性解释。
论文大纲
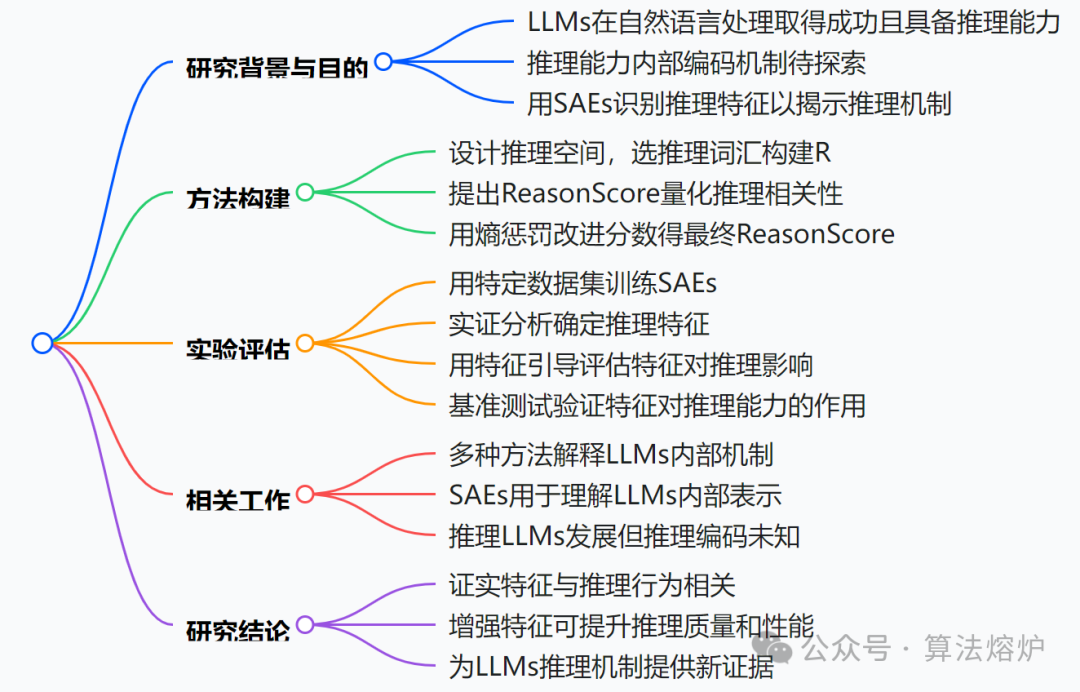
创新点总结
文章主要通过稀疏自动编码器(SAEs)探究大语言模型(LLMs)的推理机制,其创新点围绕新方法、新指标及实验验证展开。
1. 提出新方法识别推理特征:提出使用SAEs从DeepSeek-R1系列模型的激活空间中识别推理特定特征的方法。通过设计推理空间,从模型生成的数学任务解决方案中筛选出推理词汇,构建推理词汇表R。这种从语言空间角度出发的特征提取方式,为挖掘模型推理特征提供了新的思路,有别于传统方法 。
2. 引入量化指标ReasonScore:引入ReasonScore自动识别与推理相关的SAEs特征。该指标基于SAEs对推理模型激活的重构,通过计算特征在推理词汇和非推理词汇上的平均激活程度差异,并结合熵惩罚来衡量特征对推理的贡献。与以往方法相比,它能更量化、精准地评估特征与推理的相关性,提高了特征筛选的准确性和科学性 。
3. 实验验证特征与推理的因果关系:通过实证分析、自动可解释性分析和控制特征引导实验,验证了所识别的推理特征与模型推理行为之间的直接关联。在多个推理基准测试中,对特征进行引导能系统地提升模型的推理性能,如增加推理步骤、提高数值准确性和逻辑组织性等。这不仅证明了这些特征的有效性,还为理解模型推理机制提供了因果证据,是首次从机制层面证实特定可解释特征与复杂认知行为的联系 。
实验效果
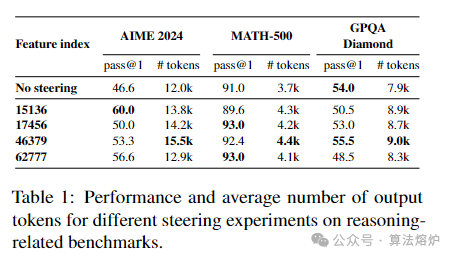
论文链接:https://arxiv.org/pdf/2503.18878

















 244
244

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









