






大语言模型(LLMs)令人瞩目的能力背后,存在着巨大的计算挑战,尤其是在GPU内存使用方面。这些挑战的一个来源是所谓的键值(KV)缓存,这是大语言模型中采用的一种关键优化技术,用于确保高效的逐个token生成。这种缓存会消耗大量的GPU内存,甚至会限制大语言模型的性能和上下文窗口大小。
本文将介绍KV缓存的优化技术。首先会解释基本的KV缓存是如何工作的,然后深入探讨开源模型和框架为提高其可扩展性、减少内存占用所采用的各种方法。
目录
- KV缓存的作用
- 基本的KV缓存
- 缓存的大小
- 分组查询注意力
- 滑动窗口注意力
- PagedAttention
- 跨多个GPU的分布式KV缓存
- 总结
KV缓存的作用
在推理过程中,大语言模型逐个生成输出token,这个过程被称为自回归解码。每个生成的token都依赖于之前所有的token,包括提示中的token和之前生成的所有输出token。当由于提示过长或输出较长导致token列表变得很大时,自注意力阶段的计算就可能成为瓶颈。
KV缓存解决了这个瓶颈问题,无论token数量多少,都能为每个解码步骤保持较低且稳定的计算开销。
为了理解为什么需要KV缓存,回想一下在最初提出并应用于如Llama-7B等模型的标准自注意力机制中,每个token会计算三个向量,即键向量、查询向量和值向量。这些向量是通过token的嵌入向量与WK、WQ和WV矩阵进行简单的矩阵乘法计算得到的,而这些矩阵是模型的学习参数的一部分。下面展示了由六个token组成的提示的键向量计算过程:
[此处插入原文中提示“Write a short poem about AI”的键向量计算图]
在标准自注意力机制中,存在多个并行的“头”,它们独立执行自注意力操作。因此,上述过程会针对每个注意力头和每一层重复进行,且每层的参数矩阵都不同。例如,在Llama-7B中,这意味着仅生成一个token就需要n_heads = 32和n_layers = 32。
随着token数量的增加,这种矩阵乘法操作涉及的矩阵会越来越大,可能会使GPU的计算能力饱和。对于在A100 GPU上运行的520亿参数模型,由于在这个阶段执行的浮点运算过多,当token数量达到208个时,性能就会开始下降。
KV缓存解决了这个问题。其核心思想很简单:在连续生成token的过程中,之前token计算出的键向量和值向量保持不变。我们不需要在每次迭代和每个token生成时重新计算它们,而是可以计算一次并缓存起来,供后续迭代使用。
基本的KV缓存
缓存的工作方式如下:
在初始解码迭代中,会为所有输入token计算键向量和值向量,如上图所示。然后,这些向量会存储在GPU内存中的一个张量中,作为缓存。迭代结束时,会生成一个新的token。
在后续的解码迭代中,只计算新生成token的键向量和值向量。将之前迭代缓存的键向量和值向量与新生成token的键向量和值向量连接起来,形成自注意力所需的K和V矩阵。这样就无需重新计算之前所有token的键向量和值向量。新的键向量和值向量也会被追加到缓存中。
例如,假设第一次迭代生成的token是“In”(这是ChatGPT写诗歌时喜欢用的开头)。那么第二次迭代的过程如下(与前图对比):
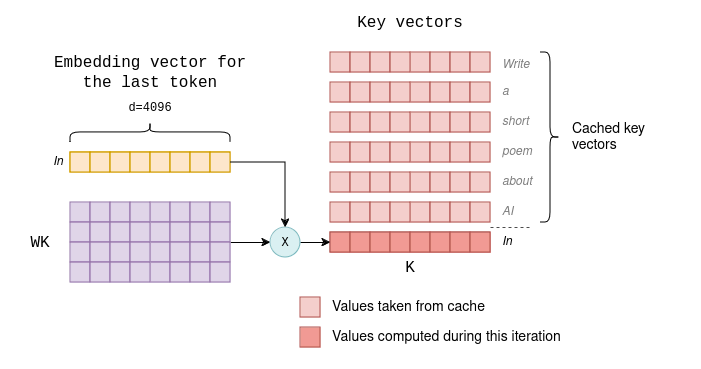
在第二次迭代中,只需要计算最后一个token的键向量,其余的从缓存中获取。
因此,后续每次生成的计算开销都保持较小且稳定。这就是为什么大语言模型对于第一个token和后续token有不同的性能指标,分别称为首token生成时间和每个输出token生成时间。生成第一个token时,必须计算所有的键向量和值向量,而对于后续token,只需要计算一个键向量和一个值向量。
你可能会想,为什么我们不缓存查询向量呢?答案是,在缓存了键向量和值向量之后,后续迭代中之前token的查询向量就不再需要了。计算自注意力只需要最新token的查询向量。我在之前的一篇博客文章中对此进行了更深入的解释。
缓存的大小
KV缓存到底需要多大呢?对于每个token,它需要为每个注意力头和每一层存储两个向量。向量中的每个元素都是一个16位的浮点数。因此,每个token在缓存中占用的内存(以字节为单位)为:
2 * 2 * head_dim * n_heads * n_layers
其中,head_dim是键向量和值向量的大小,n_heads是注意力头的数量,n_layers是模型中的层数。
代入Llama 2的参数:
| 模型 | 每个token的缓存大小 |
|---|---|
| Llama-2-7B | 512KB |
| Llama-2-13B | 800KB |
前面这篇文章已经详细解释了如何计算推理时kv cache所占显存,每个输出token大约需要1MB的GPU内存。
需要注意的是,这个计算是针对每个token的。为了适应单个推理任务的完整上下文窗口大小,我们必须相应地分配足够的缓存空间。此外,如果我们进行批量推理(即一次同时处理多个提示),缓存大小还需要再乘以批量大小。因此,缓存的总大小为:
2 * 2 * head_dim * n_heads * n_layers * max_context_length * batch_size
如果我们想利用Llama-2-13B的完整4096 token上下文窗口,批量大小为8,那么缓存大小将达到25GB,几乎与存储模型参数所需的26GB一样多。这需要大量的GPU内存!
因此,KV缓存的大小限制了两件事:
- 能够支持的最大上下文窗口大小。
- 每次推理的最大批量大小。
本文接下来将深入探讨常用的减少缓存大小的技术。
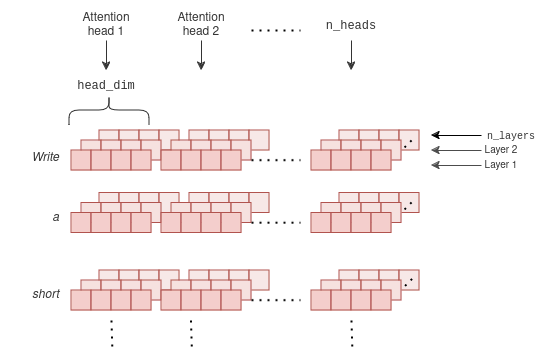
KV缓存可能会变得非常大,因为它涉及五个维度:每个向量的大小(head_dim)、注意力头的数量、层数、token的数量以及批量大小(此处未显示)。
分组查询注意力
分组查询注意力(GQA)是原始多头注意力的一种变体,它在保持大部分原始性能的同时减少了KV缓存的大小。Llama-2-70B中使用了这种技术。引用Llama-2论文中的内容:
自回归解码的标准做法是缓存序列中先前token的键(K)和值(V)对,以加速注意力计算。然而,随着上下文窗口或批量大小的增加,多头注意力(MHA)模型中与KV缓存大小相关的内存成本会显著增加。对于较大的模型,当KV缓存大小成为瓶颈时,可以在多个头之间共享键和值投影,而不会导致性能大幅下降(Chowdhery等人,2022)。可以使用具有单个KV投影的原始多查询格式(MQA,Shazeer,2019)或具有8个KV投影的分组查询注意力变体(GQA,Ainslie等人,2023)。
使用GQA的模型在计算键向量和值向量时使用较少数量的注意力头,记为n_kv_heads。对于查询向量,则保持原始的注意力头数量n_heads。然后,键值向量对会在多个查询头之间共享。这种方法有效地将KV缓存大小减少了n_heads / n_kv_heads倍。
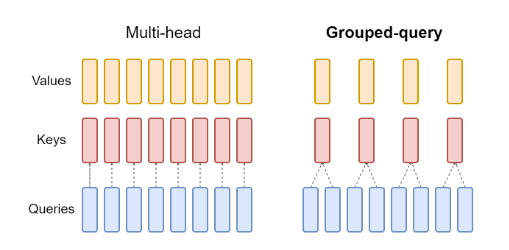
例如,在Llama-2-70B中,n_heads = 64,n_kv_heads = 8,将缓存大小减少了8倍。使用GQA的开源模型总结如下表:
| 模型 | 未使用GQA时每个token的缓存大小(假设) | GQA缩减因子 | 使用GQA时每个token的缓存大小 |
|---|---|---|---|
| Gemma-2B | 144KB | 8 | 18KB |
| Mistral-7B | 512KB | 4 | 128KB |
| Mixtral 8x7B | 1MB | 4 | 256KB |
| Llama-2-70B | 2.5MB | 8 | 320KB |
滑动窗口注意力
滑动窗口注意力(SWA)是Mistral-7B采用的一种技术,用于在不增加KV缓存大小的情况下支持更长的上下文窗口。
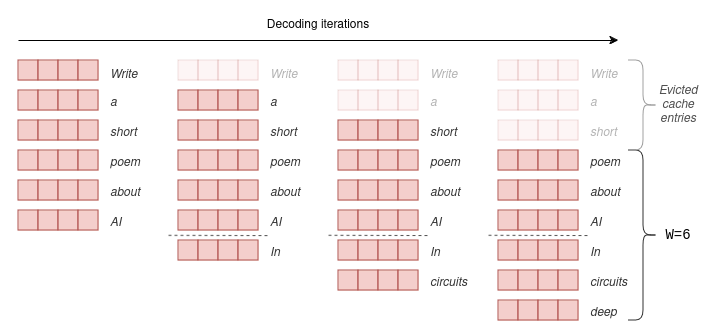
SWA是对原始自注意力机制的一种改进。在原始自注意力中,会使用每个token的键向量和查询向量,计算它与前面所有token的得分。而在SWA中,会选择一个固定的窗口大小W,每个token只与它前面的W个token计算得分。
本质上,这意味着在缓存中只需要保留最新的W个键向量和值向量。随着解码的进行,当token数量超过W时,会使用滑动窗口将旧的键向量和值向量从缓存中移除,因为它们不再需要。
这里的技巧在于,由于Transformer的分层架构,模型仍然可以关注到超过W个token之前的信息。关于旧token的信息存储在Transformer上层的键向量和值向量中。从理论上讲,模型可以关注到W * n_layers个token,同时在缓存中只保留W个向量,尽管关注能力会逐渐减弱。在Mistral论文中可以找到更详细的解释。
在实际应用中,Mistral-7B使用W = 4096,官方支持的上下文窗口大小为context_len = 8192。因此,除了GQA带来的4倍缩减,SWA还将KV缓存大小最多再减少2倍。
PagedAttention
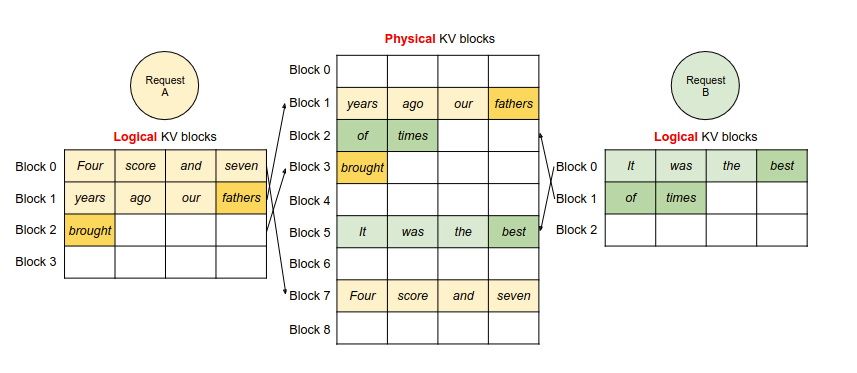
PagedAttention是vLLM推理框架推广并使用的一种复杂的缓存管理层。
PagedAttention的设计动机与GQA和SWA相同:旨在减少KV缓存大小,以支持更长的上下文窗口和更大的批量大小。在大规模推理场景中,处理大量提示可以提高输出token的吞吐量。
然而,PagedAttention并不改变模型的架构,而是作为一个缓存管理层,与前面提到的任何一种注意力机制(多头注意力、GQA和SWA)无缝集成。因此,它可以与所有现代开源大语言模型一起使用。
PagedAttention有两个关键发现:
- KV缓存中存在由于过度预留导致的大量内存浪费:为了支持完整的上下文窗口大小,总是会分配最大所需内存,但很少能被充分利用。
- 在多个推理请求共享相同提示,或者至少共享提示开头的情况下,初始token的键向量和值向量是相同的,可以在请求之间共享。这种情况在共享大型初始系统提示的应用请求中尤为常见。
PagedAttention管理缓存条目的方式类似于操作系统管理虚拟内存和物理内存:
- 不会预先分配物理GPU内存。
- 当保存新的缓存条目时,PagedAttention会以不连续的块分配新的物理GPU内存。
- 一个动态映射表在作为连续张量的缓存虚拟视图和不连续的物理块之间进行映射。
这解决了过度预留的问题,根据他们的研究,内存浪费从60 - 80%降低到了4%。此外,映射表允许多个推理请求在共享相同初始提示时重用相同的缓存条目。
跨多个GPU的分布式KV缓存
最近,闭源模型都显著提高了它们支持的上下文窗口大小。例如,GPT-4现在可以处理128k个token的上下文,而Gemini 1.5声称支持多达100万个token。然而,在使用这些超大上下文时,KV缓存可能会超过单个GPU的可用内存。
例如,假设GPT-4每个token的内存占用为1MB(这只是一个猜测),使用完整的上下文窗口将需要大约128GB的GPU内存,超过了单个A100显卡的容量。
分布式推理是指在多个GPU上运行大语言模型请求。这不仅带来了其他优势,还使得KV缓存可以突破单个GPU的内存限制。
其工作原理至少在理论上相当简单:由于自注意力机制由多个独立工作的头组成,它可以分布在多个GPU上。每个GPU被分配一部分注意力头来执行计算。每个注意力头的键向量和值向量会缓存在分配的GPU内存中。计算完成后,所有注意力头的结果会收集到一个GPU上,在那里进行合并,以供Transformer层的其余部分使用。这种方法允许将缓存分布到与注意力头数量相同的多个GPU上,例如,对于Llama-70b最多可以分布到8个GPU上。
像vLLM这样的框架提供了开箱即用的分布式推理能力。
总结
- KV缓存是大语言模型中采用的一种关键优化技术,用于保持逐个token生成时间的一致性和高效性。
- 然而,它会占用大量的GPU内存,每个token可能需要几MB的内存。
- 为了减少内存占用,开源模型利用了改进的注意力机制,如分组查询注意力(GQA)和滑动窗口注意力(SWA)。
- vLLM框架中实现的PagedAttention是一个透明的缓存管理层,减少了KV缓存导致的GPU内存浪费。
- 为了支持包含数十万个token的超大上下文,模型可能会将其KV缓存分布在多个GPU上。

















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









