






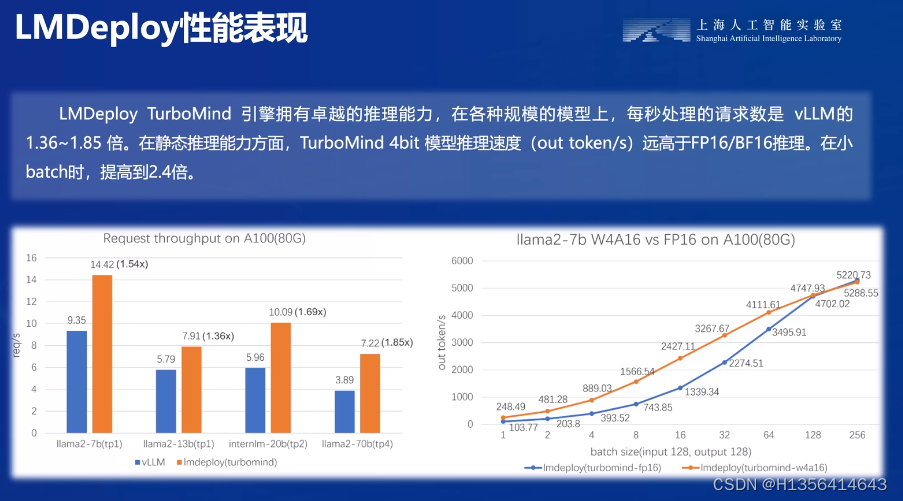
 本文探讨了在人工智能领域,特别是大模型部署的挑战,包括服务器端和移动端的部署选项,以及内存效率的优化方法如KV8量化和W4A16量化。文章还介绍了LMDeploy工具在模型量化和内存管理中的应用,以及如何通过调整参数来优化模型的性能。
本文探讨了在人工智能领域,特别是大模型部署的挑战,包括服务器端和移动端的部署选项,以及内存效率的优化方法如KV8量化和W4A16量化。文章还介绍了LMDeploy工具在模型量化和内存管理中的应用,以及如何通过调整参数来优化模型的性能。


大模型部署的背景:软件工程中,部署通常指的是将开发完毕的软件投入使用的过程
在人工智能领域,模型部署是实现深度学习算法落地的关键步骤。简单来说,模型部署是将训练好的深度学习模型在特定的环境中运行的过程。
场景:
服务器端:CPU部署,单GPU/TPU/NPU部署,多卡、集群部署......
移动端:移动机器人,手机等

GFLOPS (Giga Floating Point Operations Per Second) 是指每秒进行的十亿次浮点运算次数,而 TFLOPS (Tera Floating Point Operations Per Second) 则是每秒进行的万亿次浮点运算次数。
换句话说:
1 TFLOPS = 1000 GFLOPS
1 GFLOPS = 0.001 TFLOPS
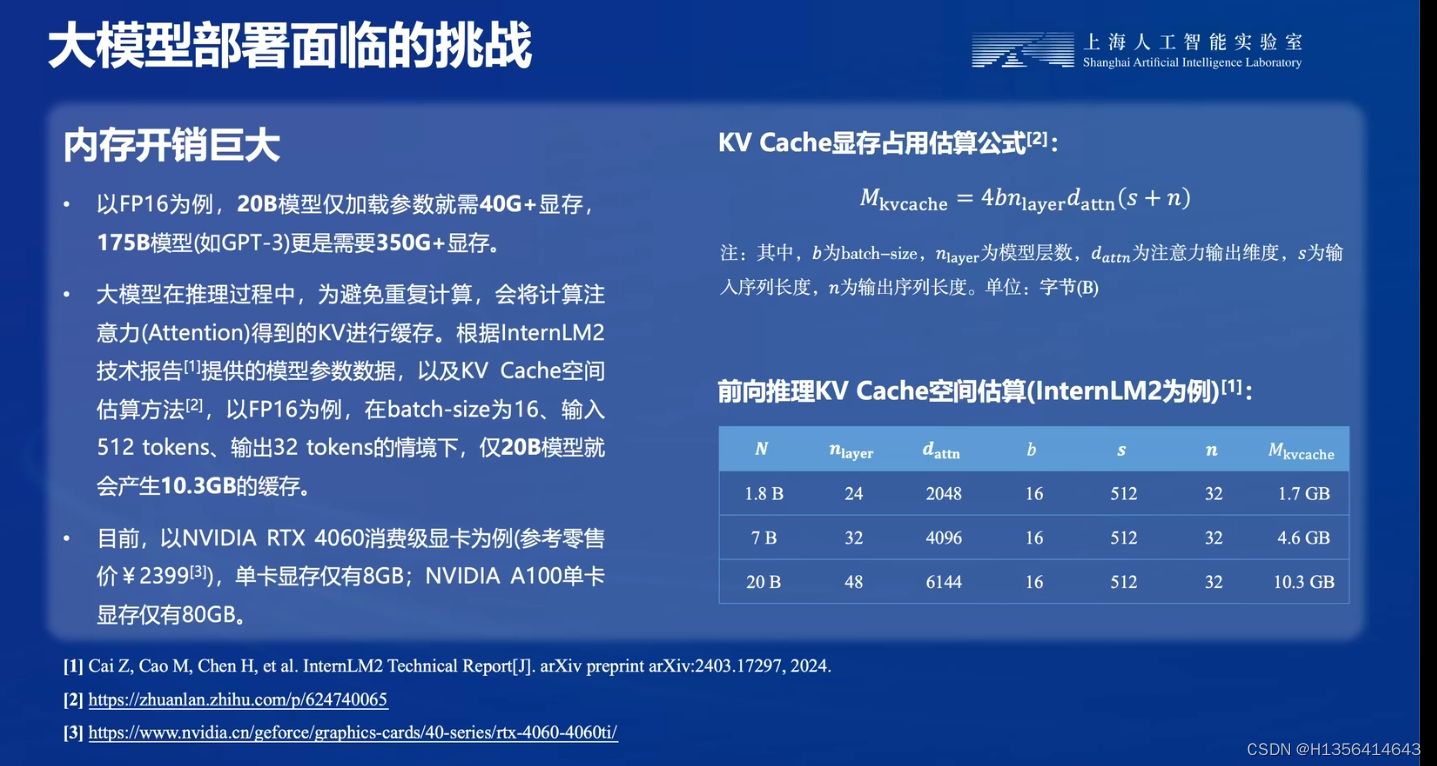
内存开销巨大:以FP16为例,20B模型参数加载需要40G+显存,175B模型(PGT3)需要350G+显存,大模型推理过程中会将注意力Attention 得到的KV进行缓存,以FP16为例估算方法,在batch-size 为16的,输入512token ,输出32token ,仅仅模型就会产生10.3GB缓存
以目前,NVDIA RTX4060消费级显卡为例,参考零售价格2399,单卡显存仅仅有8GB,NVDIA A100单卡现存仅仅有80GB
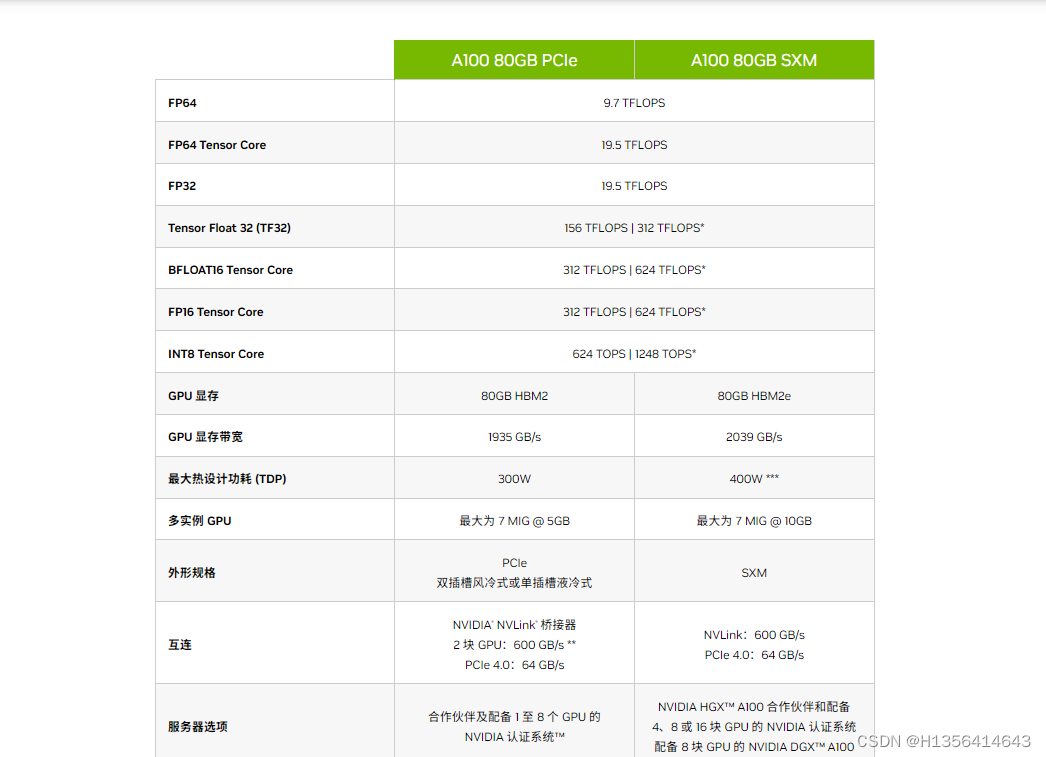
附官方资料NVIDIA A100 | NVIDIA
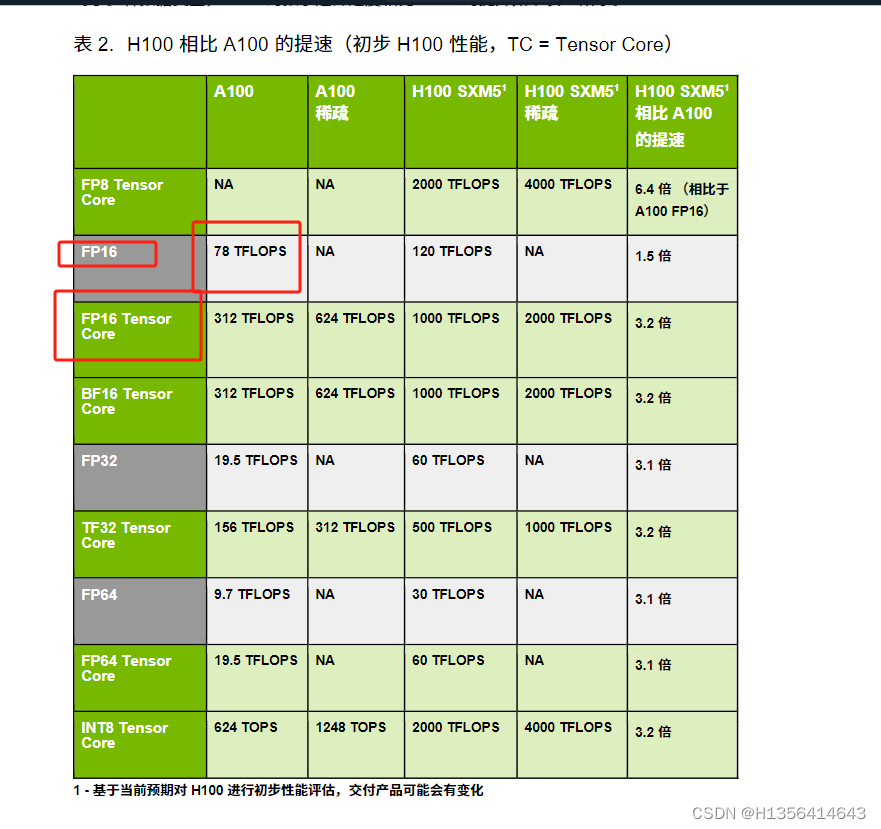
H100参数
NVIDIA H100 Tensor Core GPU 架构白皮书






环境安装
studio-conda -t lmdeploy -o pytorch-2.1.2
conda activate lmdeploy
pip install lmdeploy[all]==0.3.0
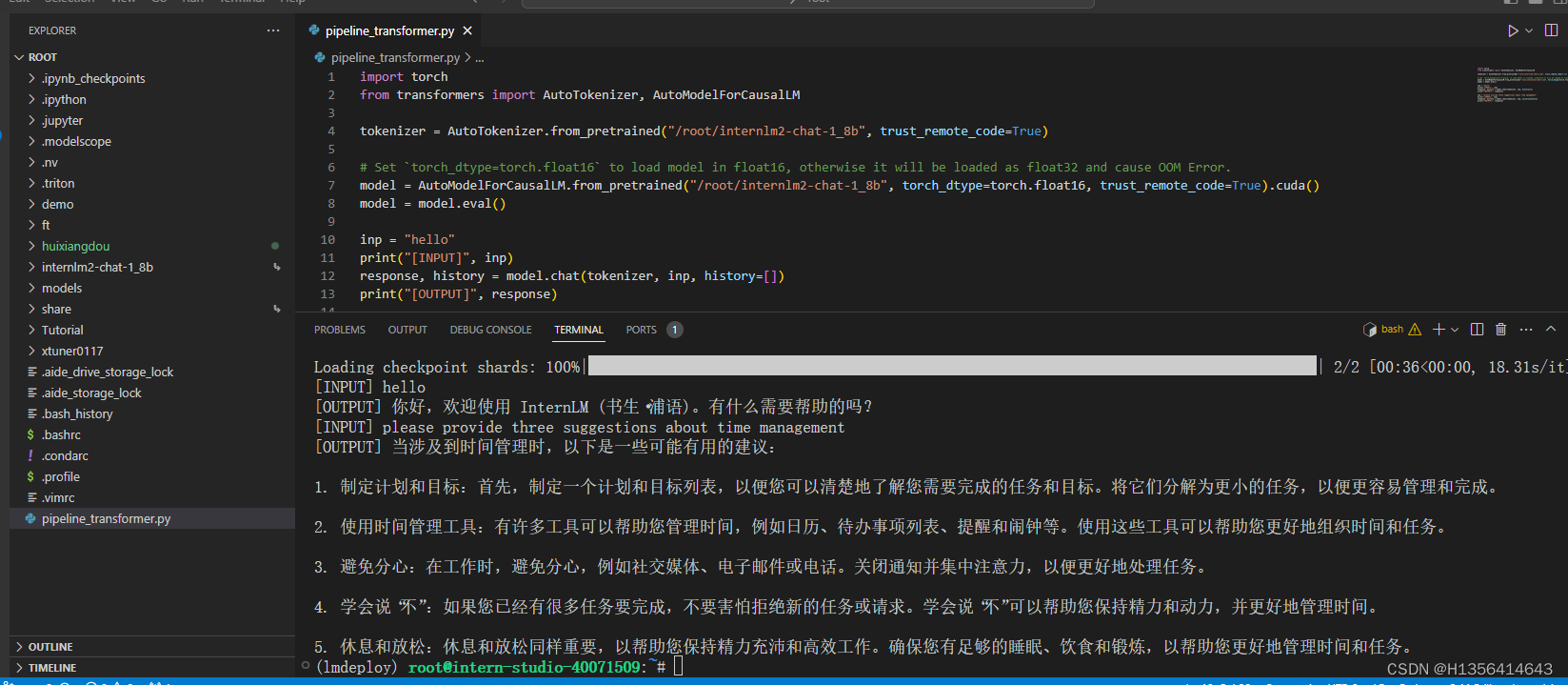
首先进入一个你想要存放模型的目录,本教程统一放置在Home目录。执行如下指令:
然后执行如下指令由开发机的共享目录软链接或拷贝模型:
执行完如上指令后,可以运行“ls”命令。可以看到,当前目录下已经多了一个internlm2-chat-1_8b文件夹,即下载好的预训练模型。
cd ~
ln -s /root/share/new_models/Shanghai_AI_Laboratory/internlm2-chat-1_8b /root/
# cp -r /root/share/new_models/Shanghai_AI_Laboratory/internlm2-chat-1_8b /root/
量化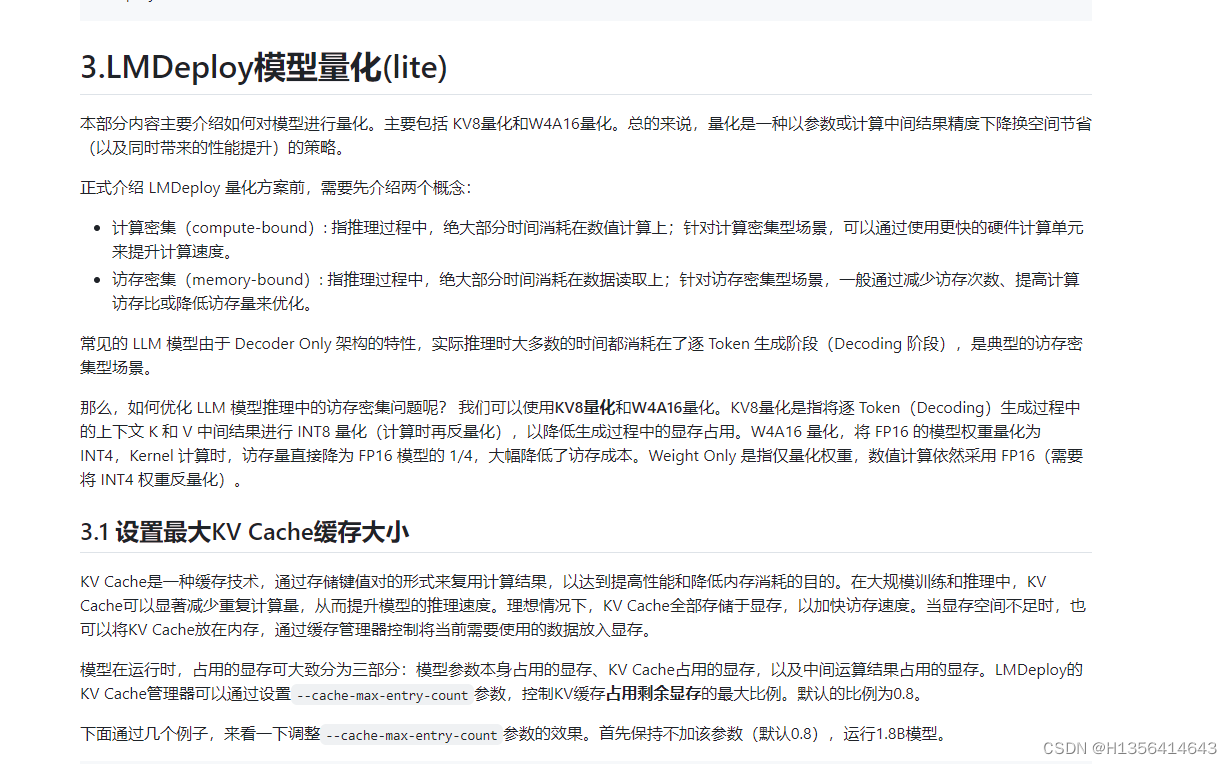
两种量化方案:KV8量化和W4A16量化,量化本质是以一参数或者计算中间结果精度下降换空间的方式。
计算密集型:推理过程中,绝大部分时间消耗在数值计算上,针对计算场景可以使用更快的硬件计算单元提升计算速度。
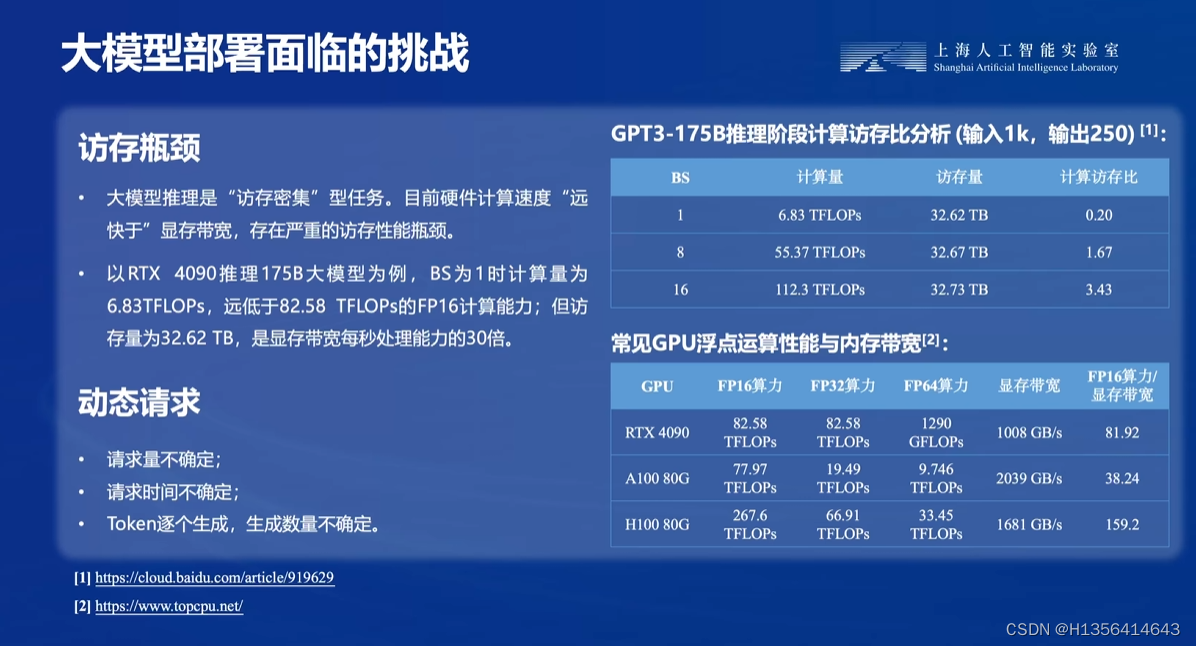
访问密集型:在推理过程,绝大部分时间消耗在数据读取上,针对此场景,一般可以通过减少访存次数,或者提高计算访存比,或者降低访存量来优化
常见的 LLM 模型由于 Decoder Only 架构的特性,实际推理时大多数的时间都消耗在了逐 Token 生成阶段(Decoding 阶段),是典型的访存密集型场景。
那么,如何优化 LLM 模型推理中的访存密集问题呢? 我们可以使用KV8量化和W4A16量化。KV8量化是指将逐 Token(Decoding)生成过程中的上下文 K 和 V 中间结果进行 INT8 量化(计算时再反量化),以降低生成过程中的显存占用。W4A16 量化,将 FP16 的模型权重量化为 INT4,Kernel 计算时,访存量直接降为 FP16 模型的 1/4,大幅降低了访存成本。Weight Only 是指仅量化权重,数值计算依然采用 FP16(需要将 INT4 权重反量化)。
模型在运行时,占用的显存可大致分为三部分:模型参数本身占用的显存、KV Cache占用的显存,以及中间运算结果占用的显存。LMDeploy的KV Cache管理器可以通过设置--cache-max-entry-count参数,控制KV缓存占用剩余显存的最大比例。默认的比例为0.8。
下面通过几个例子,来看一下调整--cache-max-entry-count参数的效果。首先保持不加该参数(默认0.8),运行1.8B模型。
lmdeploy chat /root/internlm2-chat-1_8b
仅需执行一条命令,就可以完成模型量化工作。
设置KV Cache最大占用比例为0.4,开启W4A16量化,以命令行方式与模型对话。
lmdeploy lite auto_awq \
/root/internlm2-chat-1_8b \
--calib-dataset 'ptb' \
--calib-samples 128 \
--calib-seqlen 1024 \
--w-bits 4 \
--w-group-size 128 \
--work-dir /root/internlm2-chat-1_8b-4bit
mdeploy chat /root/internlm2-chat-1_8b-4bit --model-format awq --cache-max-entry-count 0.4
LMDeploy服务(serve)
lmdeploy serve api_server \
/root/internlm2-chat-1_8b-4bit \
--model-format awq \
--quant-policy 1 \
--server-name 0.0.0.0 \
--server-port 23333 \
--tp 1\
--cache-max-entry-count 0.4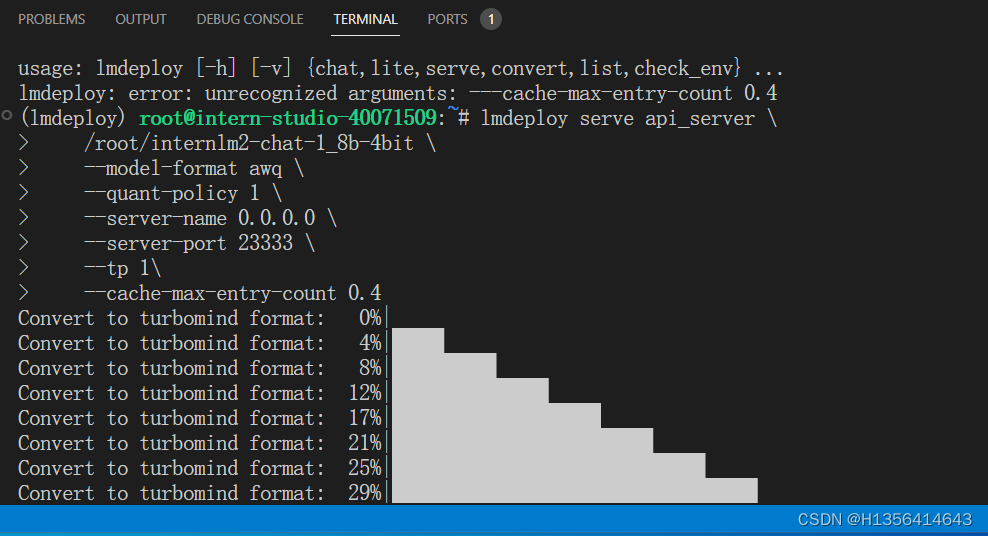

运行命令行客户端:
lmdeploy serve api_client http://localhost:23333
网页客户端连接API服务器
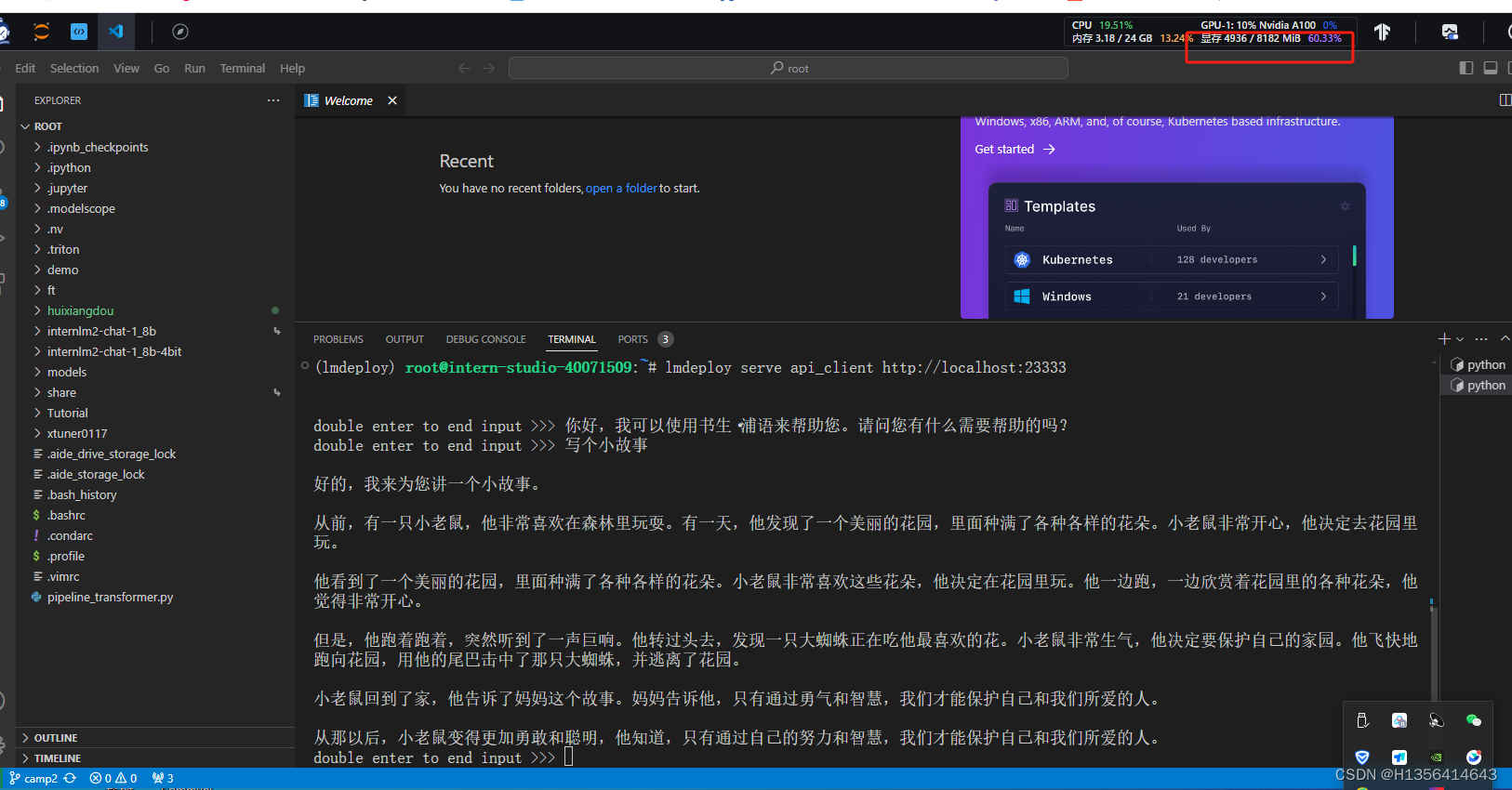
- 使用W4A16量化,调整KV Cache的占用比例为0.4,使用Python代码集成的方式运行internlm2-chat-1.8b模型。(优秀学员必做)
from lmdeploy import pipeline, TurbomindEngineConfig
# 调低 k/v cache内存占比调整为总显存的 20%
backend_config = TurbomindEngineConfig(cache_max_entry_count=0.4)
pipe = pipeline('/root/internlm2-chat-1_8b-4bit',
backend_config=backend_config)
response = pipe(['Hi, pls intro yourself', '上海是'])
print(response)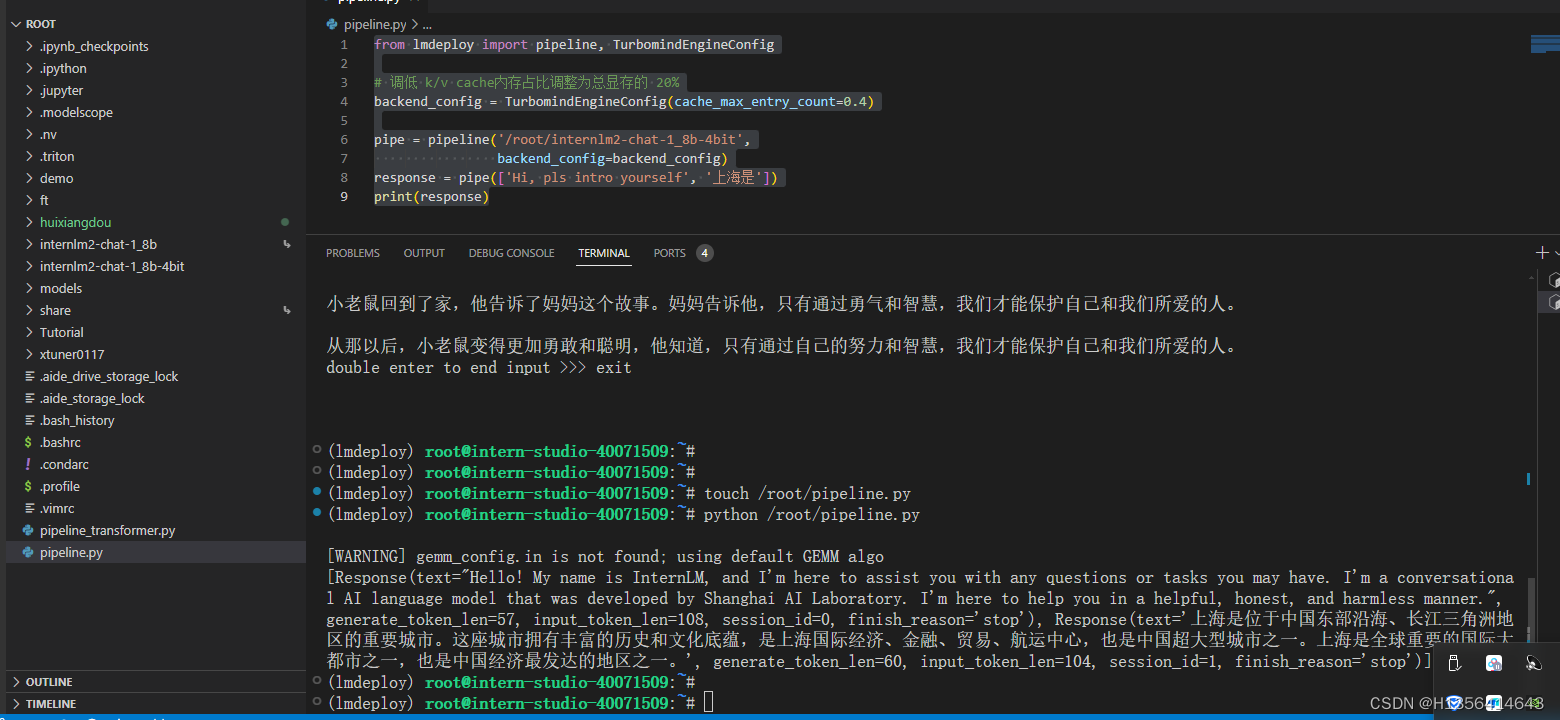
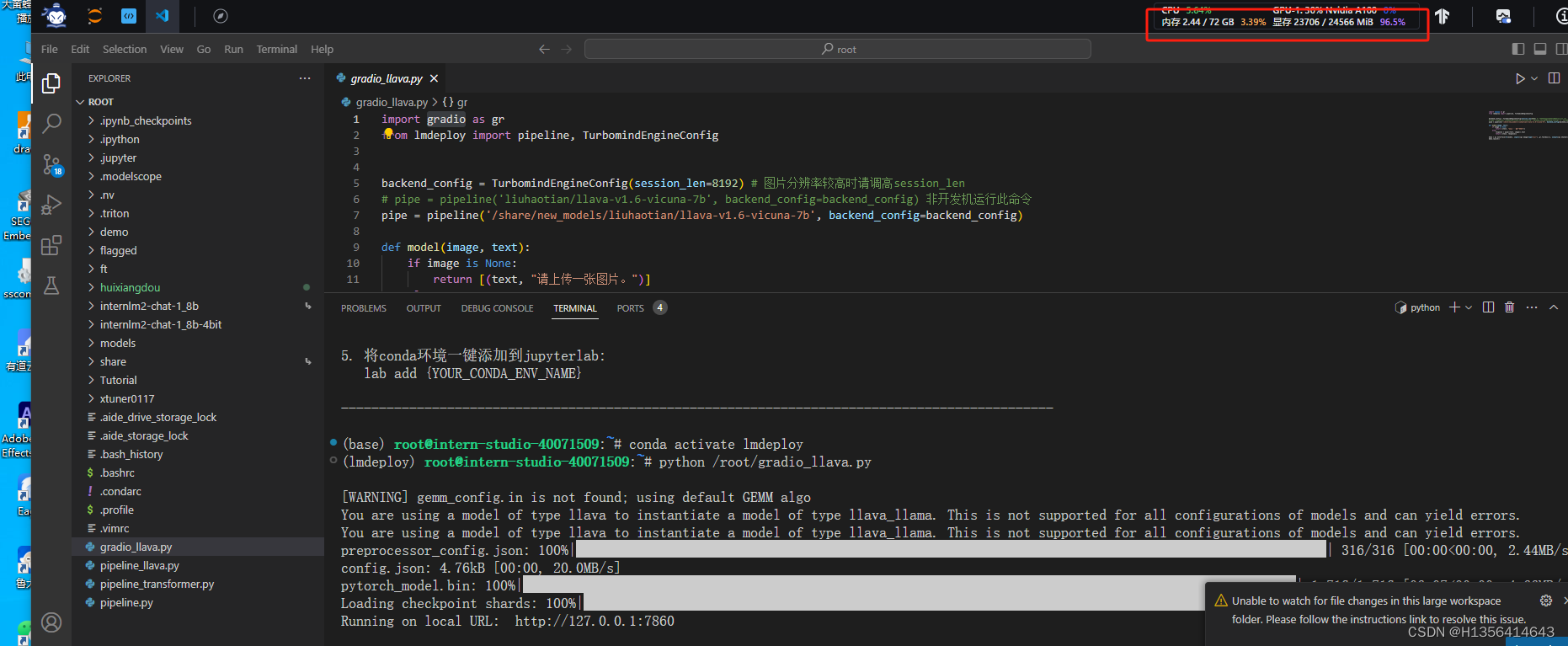
- 使用 LMDeploy 运行视觉多模态大模型 llava gradio demo。(优秀学员必做)
开发机需要升级配置到30% ,10%会提示带不起来,
















 1678
1678











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









