







Detection Algorithms
- You are building a 3-class object classification and localization algorithm. The classes are: pedestrian (c=1), car (c=2), motorcycle (c=3). What should yy be for the image below? Remember that “?” means “don’t care”, which means that the neural network loss function won’t care what the neural network gives for that component of the output. Recall y = [
p
c
,
b
x
,
b
y
,
b
h
,
b
w
,
c
1
,
c
2
,
c
3
p_c, b_x, b_y, b_h, b_w, c_1, c_2, c_3
pc,bx,by,bh,bw,c1,c2,c3].

- y=[1,?,?,?,?,1,?,?]
- y=[1,0.66,0.5,0.75,0.16,1,0,0]
- y=[1,0.66,0.5,0.16,0.75,1,0,0]
- y=[1,0.66,0.5,0.75,0.16,0,0,0]
- You are working on a factory automation task. Your system will see a can of soft-drink coming down a conveyor belt, and you want it to take a picture and decide whether (i) there is a soft-drink can in the image, and if so (ii) its bounding box. Since the soft-drink can is round, the bounding box is always square, and the soft drink can always appear the same size in the image. There is at most one soft drink can in each image. Here’re some typical images in your training set:

To solve this task it is necessary to divide the task into two: 1. Construct a system to detect if a can is present or not. 2. Construct a system that calculates the bounding box of the can when present. Which one of the following do you agree with the most?
- We can approach the task as an image classification with a localization problem.
- An end-to-end solution is always superior to a two-step system.
- The two-step system is always a better option compared to an end-to-end solution.
- We can’t solve the task as an image classification with a localization problem since all the bounding boxes have the same dimensions.
- If you build a neural network that inputs a picture of a person’s face and outputs N landmarks on the face (assume the input image always contains exactly one face), how many output units will the network have?
- 2N
- N
- N 2 N^2 N2
- 3N
- When training one of the object detection systems described in the lectures, you need a training set that contains many pictures of the object(s) you wish to detect. However, bounding boxes do not need to be provided in the training set, since the algorithm can learn to detect the objects by itself.
- False
- True
解析:you need bounding boxes in the training set. Your loss function should try to match the predictions for the bounding boxes to the true bounding boxes from the training set.
- What is the IoU between the red box and the blue box in the following figure? Assume that all the squares have the same measurements.
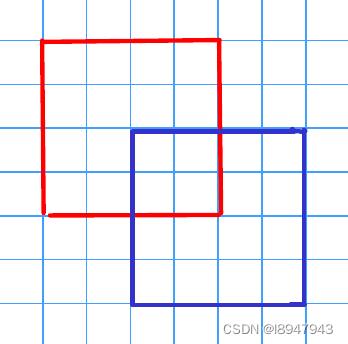
- 1 8 \frac{1}{8} 81
- 1 2 \frac{1}{2} 21
- 1 7 \frac{1}{7} 71
- 1 4 \frac{1}{4} 41
解析:(2 * 2)/ (4 * 4 + 4 * 4 - 2 * 2)= 4 / 28 = 1 / 7
- Suppose you run non-max suppression on the predicted boxes below. The parameters you use for non-max suppression are that boxes with probability q≤ 0.4 are discarded, and the IoU threshold for deciding if two boxes overlap is 0.5. How many boxes will remain after non-max suppression?
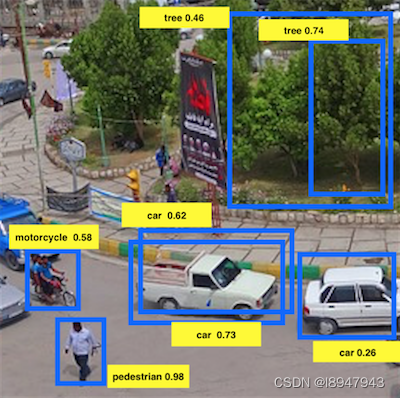
- 4
- 5
- 6
- 7
- If we use anchor boxes in YOLO we no longer need the coordinates of the bounding box b x , b y , b h , b w b_x, b_y, b_h, b_w bx,by,bh,bw since they are given by the cell position of the grid and the anchor box selection. True/False?
- False
- True
解析:We use the grid and anchor boxes to improve the capabilities of the algorithm to localize and detect objects, for example, two different objects that intersect, but we still use the bounding box coordinates.
- Semantic segmentation can only be applied to classify pixels of images in a binary way as 1 or 0, according to whether they belong to a certain class or not. True/False?
- False
- True
解析:The same ideas used for multi-class classification can be applied to semantic segmentation.
- Using the concept of Transpose Convolution, fill in the values of X, Y and Z below. (padding = 1, stride = 2)
Input: 2x2 **

Filter: 3x3

Result: 6x6
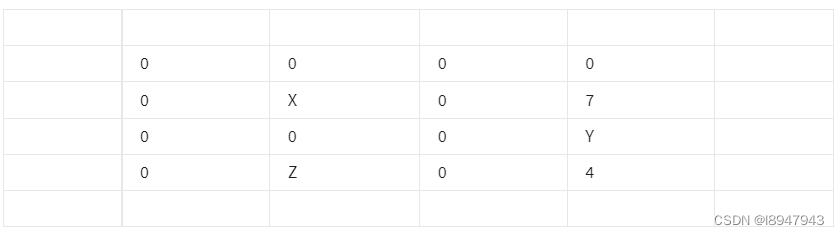
- X = 3, Y = 0, Z = 4
- X = 10, Y = 0, Z = 6
- X = 4, Y = 3, Z = 2
- X = 10, Y = 0, Z = 0
- When using the U-Net architecture with an input h × w × c h\times w \times c h×w×c, where cc denotes the number of channels, the output will always have the shape h × w × c h \times w \times c h×w×c. True/False?
- False
- True
解析:The output of the U-Net architecture can be h×w×k where k is the number of classes. The number of channels doesn’t have to match between input and output.















 7773
7773











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











