







基于张量网络的自适应学习
- A d a p t i v e T e n s o r L e a r n i n g w i t h T e n s o r N e t w o r k s ( 基 于 张 量 网 络 的 自 适 应 学 习 ) Adaptive Tensor Learning with Tensor Networks(基于张量网络的自适应学习) AdaptiveTensorLearningwithTensorNetworks(基于张量网络的自适应学习)
A d a p t i v e T e n s o r L e a r n i n g w i t h T e n s o r N e t w o r k s ( 基 于 张 量 网 络 的 自 适 应 学 习 ) Adaptive Tensor Learning with Tensor Networks(基于张量网络的自适应学习) AdaptiveTensorLearningwithTensorNetworks(基于张量网络的自适应学习)
1. 介绍 1.\textit{介绍} 1.介绍
论文中提出了一种自适应张量学习算法,它与分解模型无关。这个方法依赖于张量网络形式主义,这种形式主义在物理学界取得了巨大的成功,并且最近证明了它在机器学习中压缩模型的潜力,发展了对深层神经网络表达能力的新见解,并设计了监督和非监督学习的新方法。
这个新的分解模型将在最小化参数数量和最小化给定损失函数之间实现更好的折衷。
中间展示了一个张量学习框架,介绍这个框架如何自然地从普通的分解模型推广到任意的张量网络。这里定义了一个新的张量优化问题,即在参数数目的约束下,使任意张量网络结构上的损失最小化。由此产生的问题是双层优化问题,其中上层是张量网络结构上的离散优化,下层是给定损失函数的连续优化。论文中提出一个贪婪的方法来优化上层问题,结合自动微分和连续优化技术来优化下层问题。从秩1初始化开始,贪婪算法连续地识别秩增量的张量网络的最有希望的边缘,使得能够从数据中自适应地识别最适合手头任务的张量网络结构。
在介绍了张量学习框架之后就介绍论文的主题——张量学习的贪婪算法,这个方法是基于一个简单的贪婪方法优化一个可微的损失函数,从一个秩为1的张量开始,连续地为小的秩增量识别最有希望的张量网络边。它能够自适应地识别具有少量参数的张量网络结构,这些参数有效地从数据中优化目标函数。
最后部分是实验,将不同分解模型与文中的分解模型做了一些对比。
2. 知识回顾 2.\textit{知识回顾} 2.知识回顾
这一部分比较简单。
C
P
CP
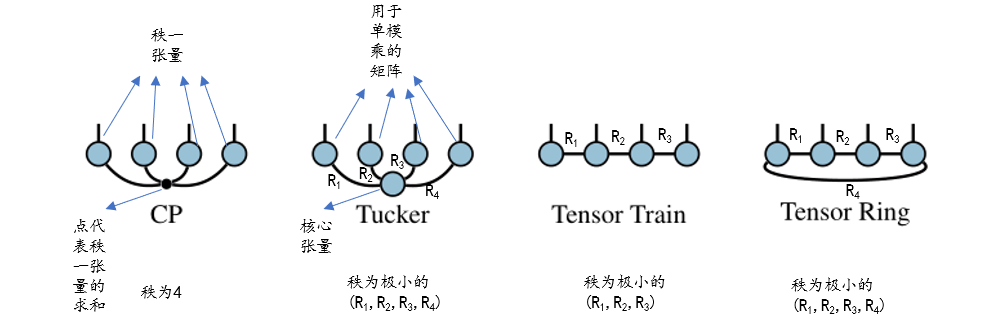
CP分解:把一个张量分解成多个秩一张量的和,张量的秩即为秩一张量的最小个数,这只是严格意义上的,实际不会得到这个严格意义上的张量的秩,而是用低秩去近似。
T u c k e r Tucker Tucker分解:把一个张量分解成一个核心张量和多个矩阵的单模乘,每个矩阵的其中一个维度的维数作为秩,这些秩构成的最小元组即为 T u c k e r Tucker Tucker秩,或者多线性秩,这里很好体现了多线性秩。
T R TR TR分解:张量环分解,也可以叫 M P S MPS MPS,因为它实际上是周期性边界条件的 M P S MPS MPS, T R TR TR秩即极小的辅助指标元组。
T
T
TT
TT分解:开放边界条件的
M
P
S
MPS
MPS,
T
T
TT
TT秩也是极小的辅助指标元组。
3. 张量学习框架 3.\textit{张量学习框架} 3.张量学习框架
考虑如下优化:
min
W
∈
R
d
1
×
⋯
×
d
p
L
(
W
)
s
.
t
.
rank
(
W
)
≤
R
\min _{\mathcal{W} \in \mathbb{R}^{d_{1}} \times \cdots \times d_{p}} \mathcal{L}(\mathcal{W}) \quad s.t. \operatorname{rank}(\mathcal{W}) \leq R
W∈Rd1×⋯×dpminL(W)s.t.rank(W)≤R
这就是经常见到的所谓低秩近似的最通用的表达形式了,另外s.t. 表示满足……条件。根据前面的知识回顾,这样的表示将发生变化,这就是论文中提到的第一个问题,即损失函数的不同选择导致了不同的常见张量学习问题。
张量学习框架其实就是给定一个用于张量学习的函数,然后规定损失函数(还会在损失函数后面加个惩罚项),低秩要求作为规范,这是张量学习框架所含的三个部分。
对于张量秩约束,有两种常见的处理方法,一种是使用凸松弛,然后使用经典的凸优化工具箱来解决由此产生的问题,另一种就是直接使得所给张量的因子最小化从而构造新的损失函数,不过此时这个损失函数是没有前面提到的秩约束的。 后面这种的一个实际例子是
T
u
c
k
e
r
Tucker
Tucker分解,其优化只包含了损失函数,而且该函数不再是凸的了,即:
min
G
∈
R
R
1
×
⋯
×
R
p
,
U
i
∈
R
d
i
×
R
i
,
1
≤
i
≤
p
∥
G
×
1
U
1
×
2
⋯
×
p
U
p
−
X
∥
F
2
\min _{\mathcal{G} \in \mathbb{R}^{R_{1} \times \cdots \times R_{p}} ,\mathbf{U}_{i} \in \mathbb{R}^{d_{i}} \times R_{i}, 1 \leq i \leq p}\left\|\mathcal{G} \times_{1} \mathbf{U}_{1} \times_{2} \cdots \times_{p} \mathbf{U}_{p}-\mathcal{X}\right\|_{F}^{2}
G∈RR1×⋯×Rp,Ui∈Rdi×Ri,1≤i≤pmin∥G×1U1×2⋯×pUp−X∥F2
那么这个与上面的那个有着秩约束的优化有什么区别呢?这个无秩约束的优化实际上是将秩
R
R
R作为一个变量丢进了损失函数,从知识回顾中还可以知道,
T
u
c
k
e
r
Tucker
Tucker秩是一个元组,这个元组中秩的选取将影响损失函数的值,这个特点也是本文的关键所在。
4. 张量学习的贪婪算法 4.\textit{张量学习的贪婪算法} 4.张量学习的贪婪算法
对于大多数张量学习问题,没有明确的方法选择使用哪种分解模型。此外,模型不规范的代价可能很高:例如,对于具有低秩的张量,
T
T
TT
TT格式中的最佳低秩近似几乎总是比具有相同参数数的秩分解差。还可能发生的情况是,没有一个常用的模型适合于该任务,并且使用新的张量网络结构将实现最小化参数数量和最小化损失函数之间的最佳折衷。根据任务的不同,实现这种折衷可能有不同的含义:对于张量分解,这将导致更好的压缩比,而对于张量回归,这将导致学习算法的更好的样本复杂性。这些考虑导致我们考虑寻找最佳张量网络结构以最小化给定损失的问题,其中人们希望最小化参数的数量和张量网络实现的目标。当然,具有大量参数的张量网络将倾向于获得较低的损失函数值。陈述问题的一个自然方法是:给定最大参数数的界限,求张量网络结构和最小化给定损失函数的核心张量。
给出规定,
(
R
i
,
j
)
1
≤
i
<
j
≤
p
\left(R_{i, j}\right)_{1 \leq i<j \leq p}
(Ri,j)1≤i<j≤p是对张量中单个秩的表示,
i
i
i表示第
i
i
i个节点(感觉用格点描述似乎更好),
j
j
j表示第
j
j
j个节点
R
i
,
j
=
1
R_{i, j}=1
Ri,j=1代表没边,大于
1
1
1则代表第
i
i
i个节点和第
j
j
j个节点之间连接了一条维数为
R
i
,
j
R_{i, j}
Ri,j的边,在
M
P
S
MPS
MPS中也可以说多了一个辅助指标。
把张量
W
∈
R
d
1
×
⋯
×
d
p
\mathcal{W} \in \mathbb{R}^{d_{1} \times \cdots \times d_{p}}
W∈Rd1×⋯×dp 表示成这样的核心张量的集合
G
(
1
)
,
⋯
,
G
(
p
)
\mathcal{G}^{(1)}, \cdots, \mathcal{G}^{(p)}
G(1),⋯,G(p), 每一个核心张量
G
(
i
)
\mathcal{G}^{(i)}
G(i) 的尺寸都是
R
1
,
i
×
⋯
×
R
i
−
1
,
i
×
d
i
×
R
i
,
i
+
1
×
⋯
×
R
i
,
p
.
R_{1, i} \times \cdots \times R_{i-1, i} \times d_{i} \times R_{i, i+1} \times \cdots \times R_{i, p} .
R1,i×⋯×Ri−1,i×di×Ri,i+1×⋯×Ri,p. 每一个核心张量都是
p
p
p阶的,但其中有些维度会等于1。 我们用
T
N
(
G
(
1
)
,
⋯
,
G
(
p
)
)
\mathrm{TN}\left(\mathcal{G}^{(1)}, \cdots, \mathcal{G}^{(p)}\right)
TN(G(1),⋯,G(p)) 表示出结果张量。
例如一个四阶张量可以表示成:
TN
(
G
(
1
)
,
⋯
,
G
(
4
)
)
i
1
i
2
i
3
i
4
=
∑
j
1
2
=
1
R
1
,
2
∑
j
1
3
=
1
R
1
,
3
⋯
∑
j
3
4
=
1
R
3
,
4
G
i
1
,
j
1
2
,
j
1
3
,
j
1
j
G
j
1
2
,
i
2
,
j
2
3
,
j
2
j
G
G
j
1
3
,
j
2
3
,
i
3
,
j
3
3
(
3
)
G
j
1
4
,
j
2
4
,
j
3
4
,
i
4
(
4
)
\operatorname{TN}\left(\mathcal{G}^{(1)}, \cdots, \mathcal{G}^{(4)}\right)_{i_{1} i_{2} i_{3} i_{4}}=\sum_{j_{1}^{2}=1}^{R_{1,2}} \sum_{j_{1}^{3}=1}^{R_{1,3}} \cdots \sum_{j_{3}^{4}=1}^{R_{3,4}} \mathcal{G}_{i_{1}, j_{1}^{2}, j_{1}^{3}, j_{1}^{j}} \mathcal{G}_{j_{1}^{2}, i_{2}, j_{2}^{3}, j_{2}^{j}}^{\mathcal{G}} \mathcal{G}_{j_{1}^{3}, j_{2}^{3}, i_{3}, j_{3}^{3}}^{(3)} \mathcal{G}_{j_{1}^{4}, j_{2}^{4}, j_{3}^{4}, i_{4}}^{(4)}
TN(G(1),⋯,G(4))i1i2i3i4=j12=1∑R1,2j13=1∑R1,3⋯j34=1∑R3,4Gi1,j12,j13,j1jGj12,i2,j23,j2jGGj13,j23,i3,j33(3)Gj14,j24,j34,i4(4)
这个公式什么意思呢?其实就是对这些辅助指标求和,只保留物理指标,以下图为例:
一般情况,上面这个
T
T
TT
TT分解只对三个辅助指标求和,但是论文中提出的方法显然不一样,论文中的方法让任意两个格点之间都连接有一个辅助指标,这个操作才是该论文的关键,是最精彩的操作。因为图中的
T
T
TT
TT分解只考虑了相邻格点之间的关系,考虑的是局域,论文中的方法考虑的更全,也考虑了不相邻格点之间的关系,也就是所谓的贪婪的穷举,行就留下,不行的丢弃,很简单的一个道理,对应的优化则是:
min
R
i
,
j
,
1
≤
i
<
j
≤
p
min
G
(
1
)
,
⋯
,
G
(
p
)
L
(
TN
(
G
(
1
)
,
⋯
,
G
(
p
)
)
)
s.t.
size
(
G
(
1
)
,
⋯
,
G
(
p
)
)
≤
C
\min _{R_{i, j}, \atop 1 \leq i<j \leq p} \min _{\mathcal{G}^{(1)}, \cdots, \mathcal{G}^{(p)}} \mathcal{L}\left(\operatorname{TN}\left(\mathcal{G}^{(1)}, \cdots, \mathcal{G}^{(p)}\right)\right) \quad \text { s.t. } \operatorname{size}\left(\mathcal{G}^{(1)}, \cdots, \mathcal{G}^{(p)}\right) \leq C
1≤i<j≤pRi,j,minG(1),⋯,G(p)minL(TN(G(1),⋯,G(p))) s.t. size(G(1),⋯,G(p))≤C
其中
L
\mathcal{L}
L 是损失函数, 每一个核张量都是
p
p
p阶的,
C
C
C是参数总量。
另一个问题 2 2 2是双层优化问题,其中上层是张量网络结构上的离散优化,下层是连续优化(假设损失函数是连续的)。 如果有可能求解下层连续优化,则通过枚举上层的搜索空间,即枚举所有满足参数个数约束的张量网络结构,并选择达到目标下限值的一个,可以找到精确解。 这种方法当然是不现实的,因为搜索空间本质上是组合的(其大小将以 W W W的数量级呈指数增长)。此外,对于大多数张量学习问题,下层连续优化问题是 N P NP NP难的。论文中提出一种简单的贪婪方法来优化上层问题,结合自动微分和连续优化技术来优化下层问题。
5. 局限性 5.\textit{局限性} 5.局限性
首先,贪婪算法可能很耗时,因为它必须在每次迭代中测试所有可能的边(张量的二次量级)。然而,这一步是高度可并行化的,并且可以定制高效的特定于任务的试探法来识别要增加的最佳边。
第二,贪婪算法是解决组合上层离散优化问题的最简单方法之一,并且易于识别次优解。
最后,贪婪算法学习的张量网络结构不包含超边和内部节点,但贪婪算法可以很容易地解决这个限制,这是留给未来的工作。
6. 算法 6.\textit{算法} 6.算法
Algorithm
1
Greedy-TL: Greedy algorithm for tensor learning.
Input: Loss function
L
:
R
d
1
×
⋯
×
d
p
→
R
, rank increment
R
.
1: // Initialize tensor network to a random rank one tensor and optimize loss function.
2:
R
i
,
j
←
1
for
1
≤
i
<
j
≤
p
3: Initialize core tensors
G
(
i
)
∈
R
R
1
,
i
×
⋯
×
R
i
−
1
,
i
×
d
i
×
R
i
,
i
+
1
×
⋯
×
R
i
,
p
randomly
4:
(
G
(
1
)
,
⋯
,
G
(
p
)
)
←
optimize
L
(
TN
(
G
(
1
)
,
⋯
,
G
(
p
)
)
)
w.r.t.
G
(
1
)
,
⋯
,
G
(
p
)
5: repeat
6:
(
i
,
j
)
←
find-best-edge
(
L
,
(
G
(
1
)
,
⋯
,
G
(
p
)
)
)
7:
G
(
i
)
←
add-slice
(
G
(
i
)
,
j
,
R
)
/
/
add
R
new slices to the jth mode of
G
(
i
)
8:
G
(
j
)
←
add-slice
(
G
(
j
)
,
i
,
R
)
/
/
add
R
new slices to the ith mode of
G
(
j
)
9
:
R
i
,
j
←
R
i
,
j
+
R
10
:
/
/
Optimize tensor network with rank of edge
(
i
,
j
)
increased by
R
11
:
(
G
(
1
)
,
⋯
,
G
(
p
)
)
←
optimize
L
(
TN
(
G
(
1
)
,
⋯
,
G
(
p
)
)
)
w.r.t.
G
(
1
)
,
⋯
,
G
(
p
)
12
:
until Stopping criterion
\begin{array}{l} \text { Algorithm } 1 \text { Greedy-TL: Greedy algorithm for tensor learning. } \\ \hline \text { Input: Loss function } \mathcal{L}: \mathbb{R}^{d_{1} \times \cdots \times d_{p}} \rightarrow \mathbb{R} \text { , rank increment } R \text { . } \\ \text { 1: // Initialize tensor network to a random rank one tensor and optimize loss function. } \\ \text { 2: } R_{i, j} \leftarrow 1 \text { for } 1 \leq i<j \leq p \\ \text { 3: Initialize core tensors } \mathcal{G}^{(i)} \in \mathbb{R}^{R_{1, i} \times \cdots \times R_{i-1, i} \times d_{i} \times R_{i, i+1} \times \cdots \times R_{i, p}} \text { randomly } \\ \text { 4: }\left(\mathcal{G}^{(1)}, \cdots, \mathcal{G}^{(p)}\right) \leftarrow \text { optimize } \mathcal{L}\left(\operatorname{TN}\left(\mathcal{G}^{(1)}, \cdots, \mathcal{G}^{(p)}\right)\right) \text { w.r.t. } \mathcal{G}^{(1)}, \cdots, \mathcal{G}^{(p)} \\ \text { 5: repeat } \\ \text { 6: } \quad(i, j) \leftarrow \text { find-best-edge }\left(\mathcal{L},\left(\mathcal{G}^{(1)}, \cdots, \mathcal{G}^{(p)}\right)\right) \\ \text { 7: } \quad \mathcal{G}^{(i)} \leftarrow \text { add-slice }\left(\mathcal{G}^{(i)}, j, R\right) \quad / / \text { add } R \text { new slices to the jth mode of } \mathcal{G}^{(i)} \\ \text { 8: } \mathcal{G}^{(j)} \leftarrow \text { add-slice }\left(\mathcal{G}^{(j)}, i, R\right) \quad / / \text { add } R \text { new slices to the ith mode of } \mathcal{G}^{(j)} \\ 9: \quad R_{i, j} \leftarrow R_{i, j}+R \\ 10: \quad / / \text { Optimize tensor network with rank of edge }(i, j) \text { increased by } R \\ 11: \quad\left(\mathcal{G}^{(1)}, \cdots, \mathcal{G}^{(p)}\right) \leftarrow \text { optimize } \mathcal{L}\left(\operatorname{TN}\left(\mathcal{G}^{(1)}, \cdots, \mathcal{G}^{(p)}\right)\right) \text { w.r.t. } \mathcal{G}^{(1)}, \cdots, \mathcal{G}^{(p)} \\ 12: \text { until Stopping criterion } \end{array}
Algorithm 1 Greedy-TL: Greedy algorithm for tensor learning. Input: Loss function L:Rd1×⋯×dp→R , rank increment R . 1: // Initialize tensor network to a random rank one tensor and optimize loss function. 2: Ri,j←1 for 1≤i<j≤p 3: Initialize core tensors G(i)∈RR1,i×⋯×Ri−1,i×di×Ri,i+1×⋯×Ri,p randomly 4: (G(1),⋯,G(p))← optimize L(TN(G(1),⋯,G(p))) w.r.t. G(1),⋯,G(p) 5: repeat 6: (i,j)← find-best-edge (L,(G(1),⋯,G(p))) 7: G(i)← add-slice (G(i),j,R)// add R new slices to the jth mode of G(i) 8: G(j)← add-slice (G(j),i,R)// add R new slices to the ith mode of G(j)9:Ri,j←Ri,j+R10:// Optimize tensor network with rank of edge (i,j) increased by R11:(G(1),⋯,G(p))← optimize L(TN(G(1),⋯,G(p))) w.r.t. G(1),⋯,G(p)12: until Stopping criterion
其中
w
.
r
.
t
w.r.t
w.r.t意思是关于。
这个算法要表达的其实很简单:
第
2
2
2行和
3
3
3行初始化核心张量(实际上是一个向量),把除了物理指标以外的辅助指标全部置为
1
1
1;
第
4
4
4行初始化原张量的近似,最开始肯定损失很大,随着后面循环的进行,损失会变小;
第
5
5
5行就是开始循环,这没写具体情况,但我猜大概是每次循环都设置一个
R
R
R值,这个
R
R
R每次迭代都会加一个固定的值;
第
6
6
6行寻找最好的辅助指标,通过最优化来评估;
第
7
7
7行和第
8
8
8行对最好的辅助指标对应的两个核心张量进行填加片的操作,如果
R
R
R为
1
1
1,这个片是什么依据核心张量的尺寸而定,如果核心张量尺寸为
4
∗
1
4 * 1
4∗1,
R
=
1
R=1
R=1,则核心张量尺寸变成
4
∗
2
4 * 2
4∗2,这里加的就是一个向量,随着阶数更高,或者
R
R
R(
R
R
R应该是一开始就可以设置的)发生变化;
第
9
9
9行自然是改变对应的辅助指标了;
第
11
11
11行新张量更新;
第
12
12
12行如果未达到收敛条件就继续循环。
算法的思想已经比较明朗了,在
r
e
p
e
a
t
repeat
repeat附近中找每一个
R
R
R下最好的那个辅助指标(边),注意,只找一个,找完后就更新对应核心张量和秩
R
R
R,然后更新新张量,接着判断是否达到收敛条件,没达到就继续下一次迭代找更大秩
R
R
R对应的辅助指标,依次循环直到收敛。
有关片的例子:
对于一个
4
4
4阶张量, 对 (1,2)边的秩加1需要添加片
d
1
×
R
1
,
3
×
R
1
,
4
d_{1} \times R_{1,3} \times R_{1,4}
d1×R1,3×R1,4 (resp.
d
2
×
R
2
,
3
×
R
2
,
4
d_{2} \times R_{2,3} \times R_{2,4}
d2×R2,3×R2,4 )到
G
(
1
)
(
r
e
s
p
.
G
(
2
)
)
\mathcal{G}^{(1)}(resp. \left.\mathcal{G}^{(2)}\right )
G(1)(resp.G(2))上. 经过这个操作后,
G
(
1
)
\mathcal{G}^{(1)}
G(1) 的尺寸为
d
1
×
(
R
1
,
2
+
1
)
×
R
1
,
3
×
R
1
,
4
d_{1} \times\left(R_{1,2}+1\right) \times R_{1,3} \times R_{1,4}
d1×(R1,2+1)×R1,3×R1,4 并且另一个核心张量
G
(
2
)
\mathcal{G}^{(2)}
G(2) 的尺寸变为
(
R
1
,
2
+
1
)
×
d
2
×
R
2
,
3
×
R
2
,
4
\left(R_{1,2}+1\right) \times d_{2} \times R_{2,3} \times R_{2,4}
(R1,2+1)×d2×R2,3×R2,4,
r
e
s
p
.
resp.
resp.意思是替换。
7. 实验 7.\textit{实验} 7.实验
实 验 一 实验一 实验一
随机生成一个
7
×
7
×
7
×
7
×
7
7 × 7 × 7 × 7 × 7
7×7×7×7×7的张量,然后使用分解模型来分解这个张量,并把不同的分解模型在效果上进行对比。
这是三个初始化的新张量:

经过自适应学习后其中两个变成:

效果对比:
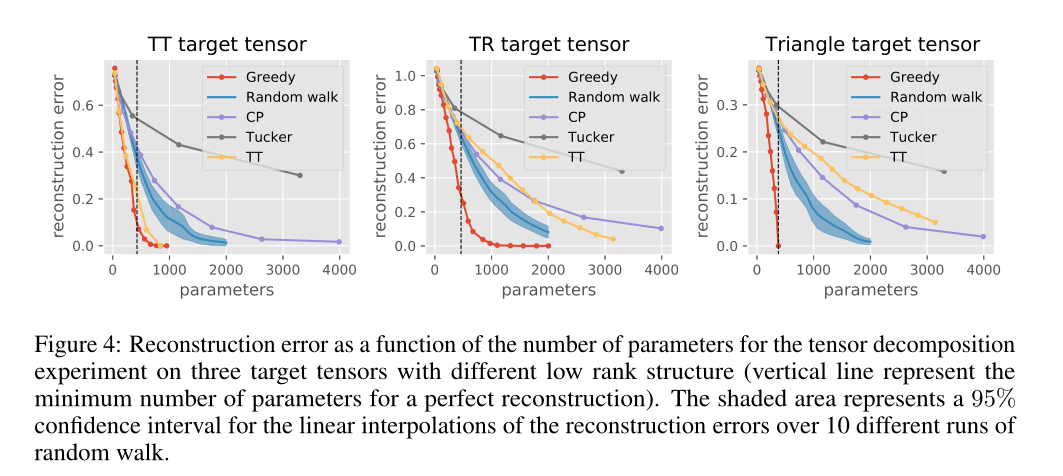
可以看出,文中提出的
G
r
e
a
d
y
Gready
Gready算法效果好于其他算法。
实 验 二 实验二 实验二
将爱因斯坦的人脸图像 r e s a h p e resahpe resahpe成 6 × 10 × 10 × 6 × 10 × 10 × 3 6 × 10 × 10 × 6 × 10 × 10 × 3 6×10×10×6×10×10×3的张量后再用不同分解模型对图像进行恢复并对比图像损失,具体如下:
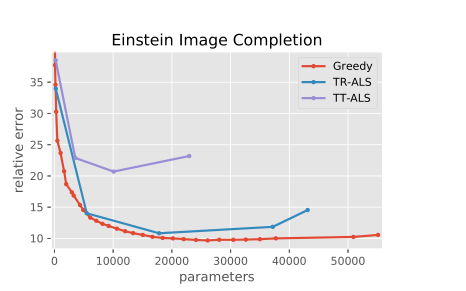
图像恢复效果:

将Yale 人脸数据库中的图片reshape成 6 × 8 × 6 × 7 × 8 × 19 × 2 6×8×6×7×8×19×2 6×8×6×7×8×19×2的张量后用不同分解模型进行图像恢复并对比图像损失,具体如下:
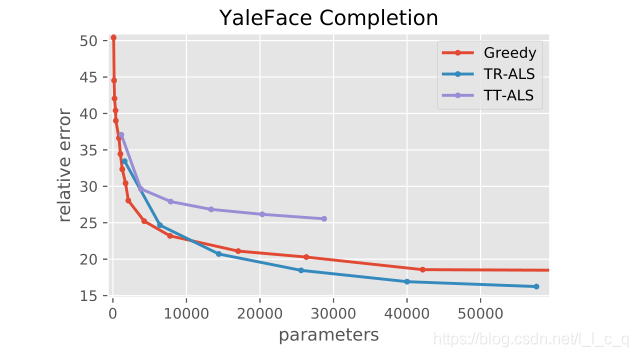
从这两张图都可以看出:无论是从参数还是相对误差来看,论文中的算法都优于传统算法的最佳结果。
8. 论文中提到的两个问题 8.\textit{论文中提到的两个问题} 8.论文中提到的两个问题
回顾一下论文中所提到的两个问题:
问题
1
1
1:损失函数的不同选择导致了不同的常见张量学习问题,针对秩约束有两种解决方式,一种是使用凸松弛,然后使用经典的凸优化工具箱来解决,另一种就是直接使得所给张量的因子最小化从而构造新的损失函数,论文中给出的方法就用了这种解决方式,每次迭代处理的都是作为张量因子的核心张量(格点)。
问题
2
2
2:双层优化问题,其中上层是张量网络结构上的离散优化(优化的边可能并不连接同一个格点),下层是连续优化(假设损失函数是连续的),这里应该体现在优化器如何应对损失上面(自动微分或梯度下降),至于论文名为何有个自适应是因为用了一个
R
M
S
p
r
o
p
RMSprop
RMSprop优化器,它可以用加权的方式调整学习率,可不就是自适应学习,而且相比动量法(一种优化算法),它进一步优化梯度摆动幅度过大的问题,并进一步加速损失函数的收敛速度。
9. 推荐 9.\textit{推荐} 9.推荐
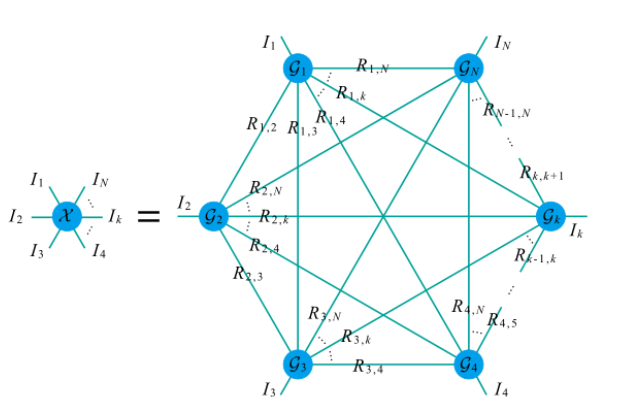
文中这篇论文通过优化秩(辅助指标)来优化下图这样一个张量网络,而今年(2021)4月份有一篇论文叫《 F u l l y Fully Fully- C o n n e c t e d Connected Connected T e n s o r Tensor Tensor N e t w o r k Network Network D e c o m p o s i t i o n Decomposition Decomposition a n d and and I t s Its Its A p p l i c a t i o n Application Application t o to to H i g h e r Higher Higher- O r d e r Order Order T e n s o r Tensor Tensor C o m p l e t i o n Completion Completion》,这篇论文同样讲的是如何优化下面这个张量网络,其方式是想办法去优化张量网络中的节点来优化整个张量网络,但说到底,两种方式都是优化下面这个张量网络,很适合对比学习。

















 83
83

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









