






**
论文:On Pixel-Wise Explanations for Non-Linear Classifier Decisions by Layer-Wise Relevance Propagation
**
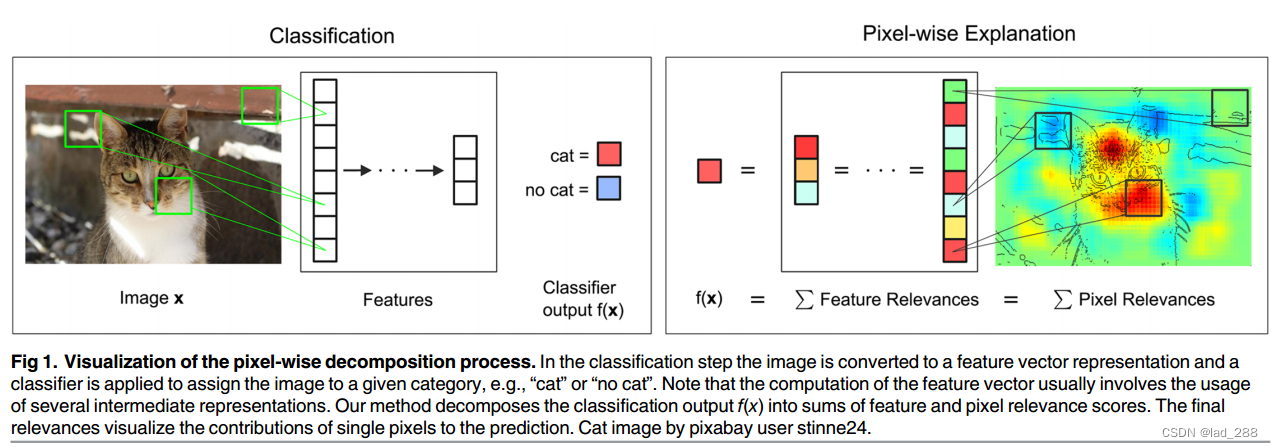
图1.逐像素分解过程的可视化。在分类步骤中,图像被转换为特征向量表示,并应用分类器将图像分配给给定类别,例如“猫”或“没有猫”。注意,特征向量的计算通常涉及使用多个中间表示。本文的方法将分类输出f(x)分解为特征和像素相关性得分的总和,最终的相关性可视化单个像素对预测的贡献。
主要思想
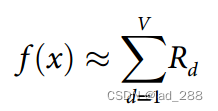
Layer-wise relevance propagation
将逐层相关性传播作为由一组约束定义的概念,任何满足约束的解决方案都将被认为遵循逐层相关性传播的概念。
一般形式的逐层相关性传播假设分类器可以分解为多个计算层,这些层可以是从图像中提取特征的部分,也可以是在计算的特征上运行的分类算法的部分。第一层是输入,即图像的像素,最后一层是分类器f的实值预测输出,第l层被建模为维度为V(l)的向量z。逐层相关性传播假设我们在第l+1层的向量z的每个维度Zd都有一个相关性分数Rd。其想法是找到下一层l处向量z的每个维度Zd的相关性分数Rd,该层更接近输出层,使得下列等式成立。
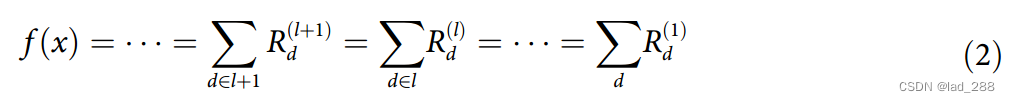
接下来推导需满足的约束

这里做出两个假设
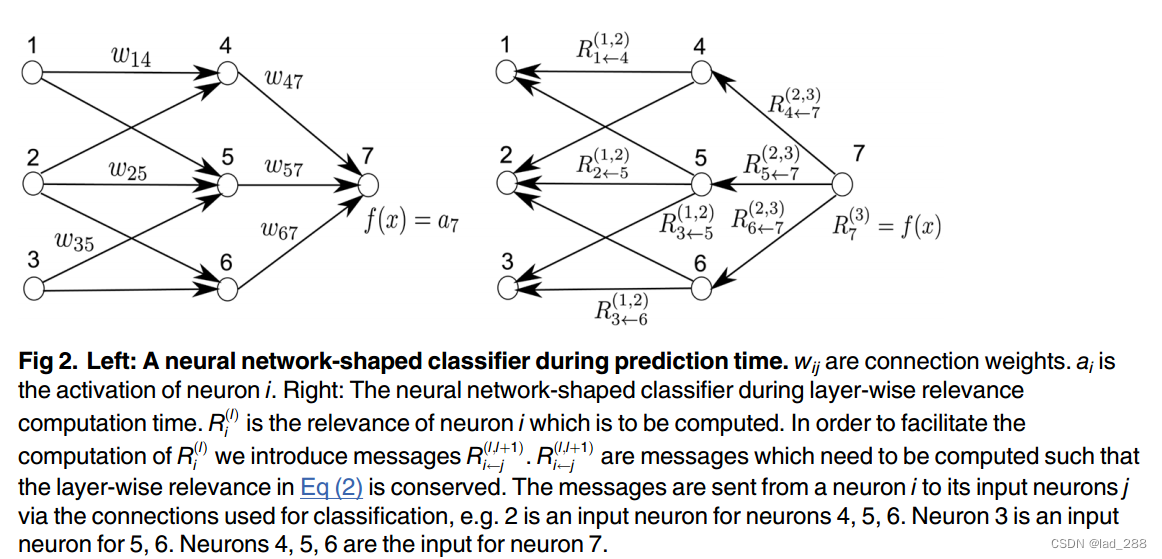
–将分层相关性看作神经元i和j之间的消息,这些消息可以沿着每个连接发送,但是与预测的方向相反,这些消息是从神经元定向到其输入神经元。
–将除神经元7之外的任何神经元的相关性定义为以下形式:
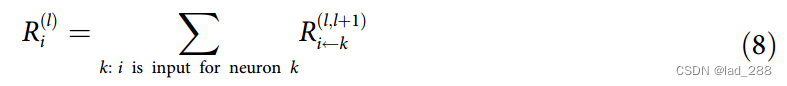
那么图2右图中的计算就会变成下面这样:
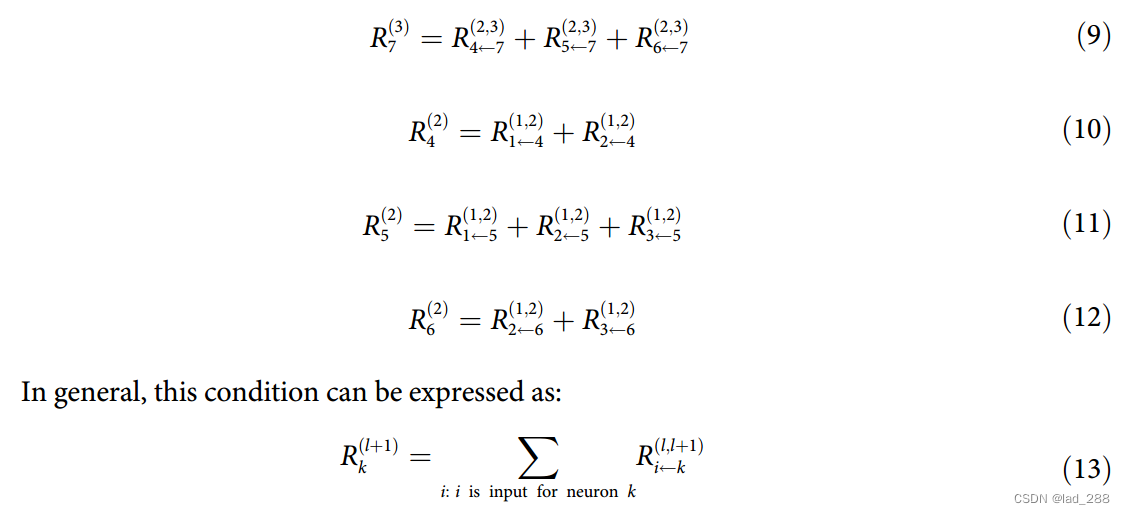
方程(13)左边求和
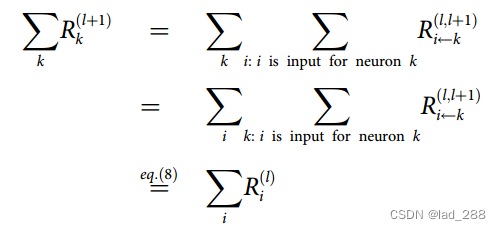
消息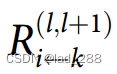 可以解释为将神经元k的相关性
可以解释为将神经元k的相关性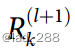 分布到第l层的输入神经元上
分布到第l层的输入神经元上
以上,将方程(8)和(13)设置为定义逐层相关性传播的主要约束
显性表示,逐层相关性传播应该反映在分类期间传递的消息,在分类过程中,当神经元i与k有正向连接时,神经元i向神经元k输入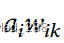
重写公式(9)和(10)的右边
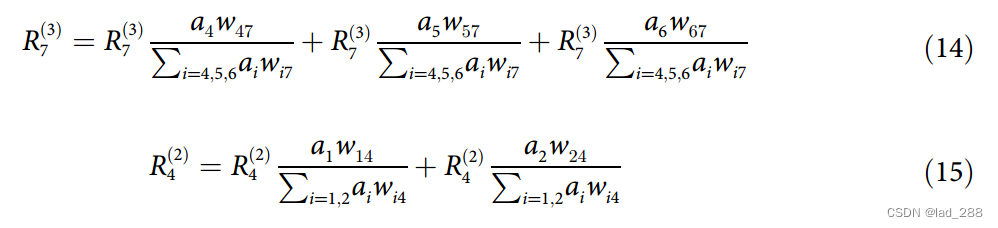
可得一般表示为

公式(16)回答了消息可能是什么的问题,即已计算出接收神经元的相关性,并按来自前一层l的神经元i的输入按比例加权。当我们使用不同的分类架构并用给定层的特征向量的一个维度替换神经元的概念时,这个概念也以类似的方式成立。
应用
算法从已经计算过的l+1层的相关性R(l+1)开始,然后类似公式(13)计算来自l+1层的所有元素k和来自前一层l的所有元素i的消息R(l,l+1),再用公式(8)来定义l层的所有元素的相关性R(l)。
总结
在逐层相关性传播的定义中,总相关性被约束为从一层到另一层保持不变,总节点相关性必须等于传入该节点的所有相关性消息的总和,也等于传出到同一节点的所有相关消息的总和。需要注意的是,该定义并不是作为具有不同最小值的目标的算法或解决方案给出的。相反,它是作为一组约束给出的,解决方案应该满足约束。因此,在这些约束条件下,具有不同结果解的不同算法是可接受的。

















 1897
1897

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









