




 本文介绍使用Scrapy框架和CSS选择器抓取网页数据的实战案例,演示了如何定位特定元素并提取链接,同时提供了当仅有文本而无响应类时使用CSS选择器的方法。
本文介绍使用Scrapy框架和CSS选择器抓取网页数据的实战案例,演示了如何定位特定元素并提取链接,同时提供了当仅有文本而无响应类时使用CSS选择器的方法。
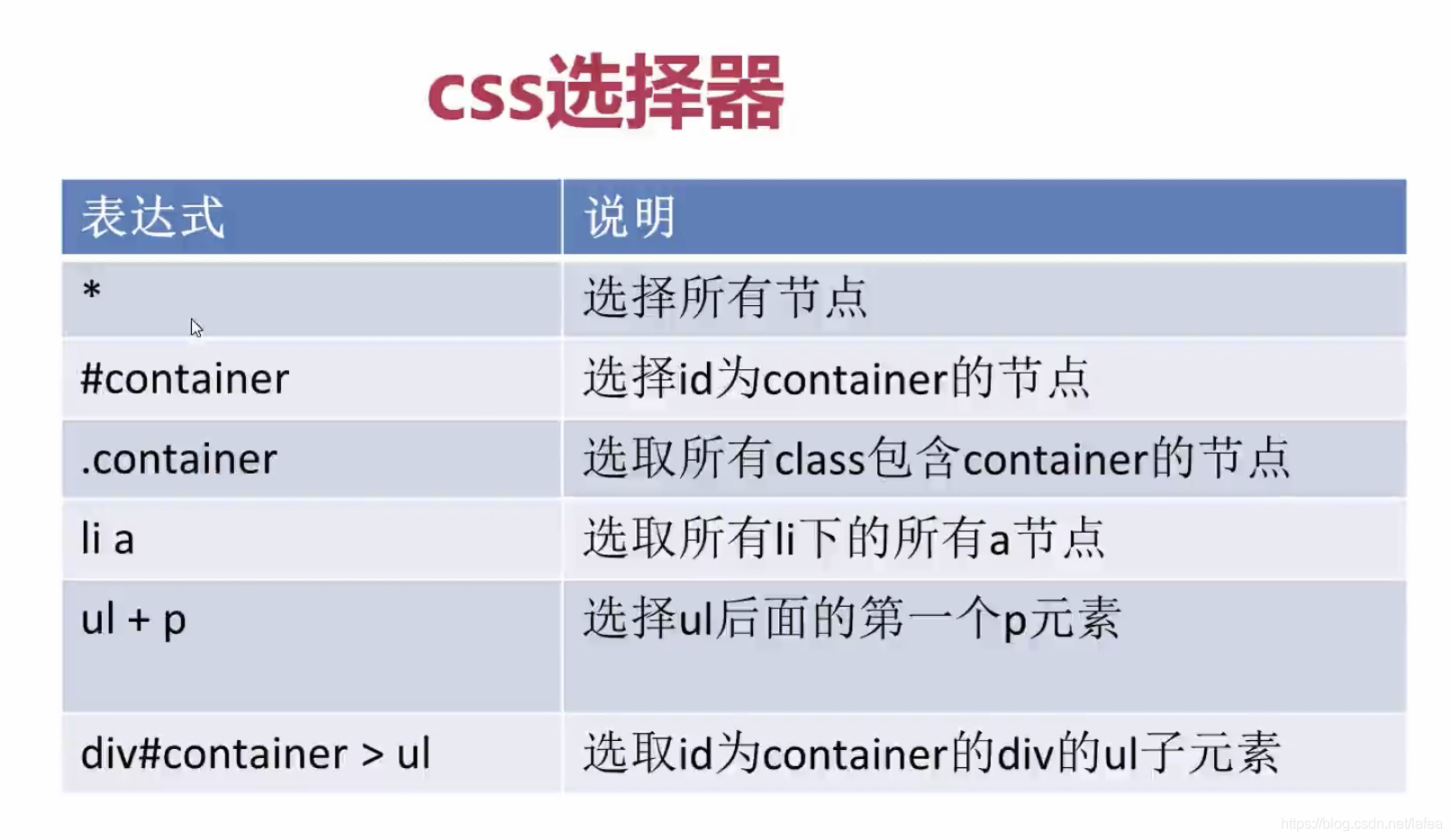
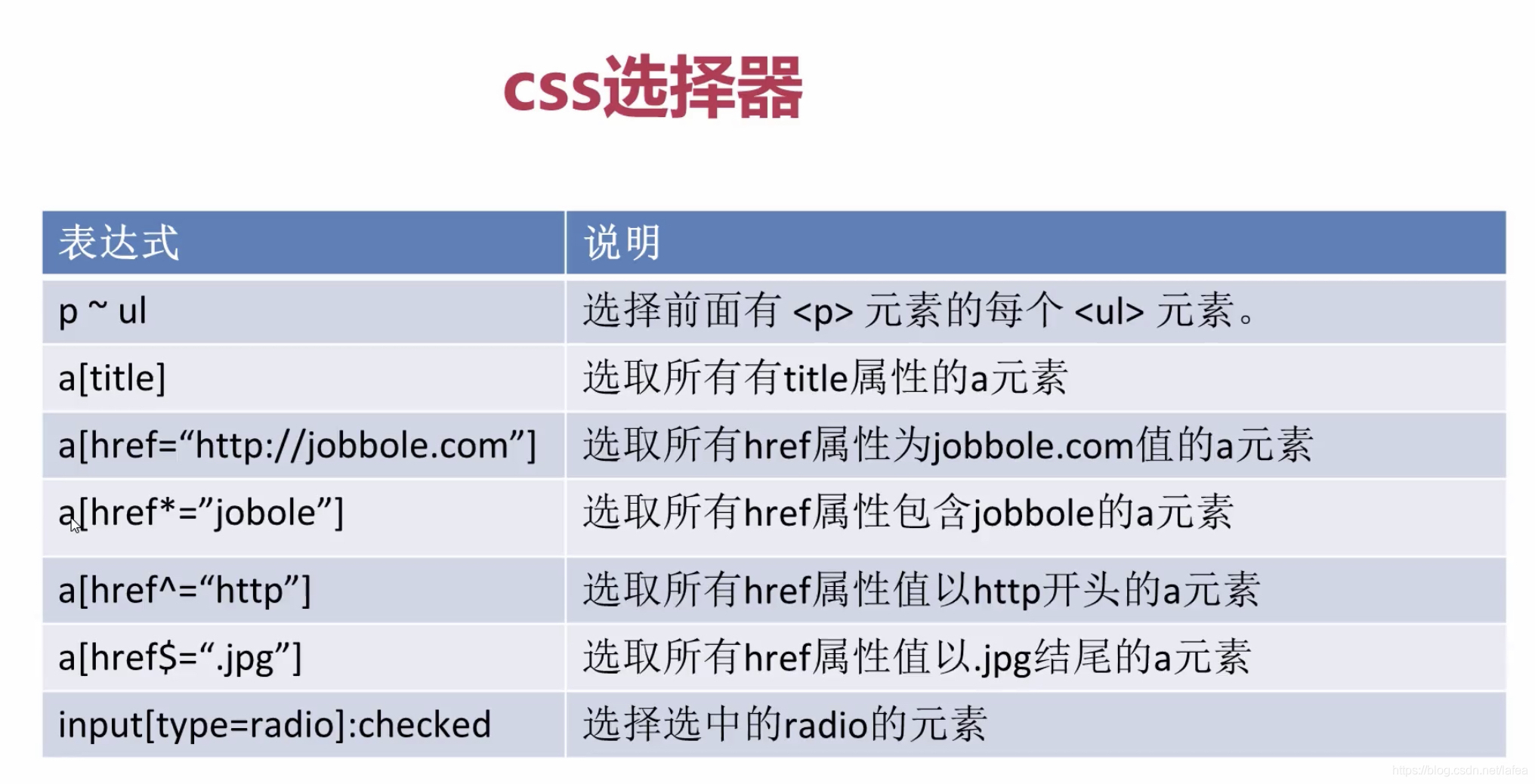
爬虫与css选择器
scrapy 依赖 lxml, lxml 是c语言写的,也支持css
css 没有 xpath 强大

# -*- coding: utf-8 -*-
import scrapy
class JobboleSpider(scrapy.Spider):
name = 'jobbole'
allowed_domains = ['news.cnblogs.com']
start_urls = ['http://news.cnblogs.com/']
def parse(self, response):
# 一般别直接定位到a,因为a太常见了,往上找点class或id定位
# response一般返回一个selectorlist,内容比较杂所以加extract方法,返回一个结果list
# extract后的list最好别用getitem的方式调用,容易抛异常
# 当然还有 .extract_first("") 这种类似的方法获取列表第一个值, 括号内是找不到时的默认值
# url = response.xpath('//div[@id="news_list"]//h2[@class="news_entry"]/a/@href').extract()
# css选择器的写法
url = response.css('div#news_list h2 a::attr(href)').extract()
print(url)
print(len(url))
# 如果没有response类,只有一段文本,又想用css选择器呢?
from scrapy import Selector
text = response.text
sel = Selector(text=text)
url = sel.css('div#news_list h2 a::attr(href)').extract()
print(url)
pass

















 538
538

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









