






根据之前例程的各部分实现结合使用场景进行修改 使得性能测试结果更加真实可靠
一个常见的场景 输入拉流rtsp 推理 输出rtsp流服务
要实现的具体功能 拉流rtsp 解码 预处理 推理 后处理 编码 rtsp流服务
拉流rtsp 用ffmpeg实现 解封装得到h264 为了传输稳定配置rtsp over tcp
解码 例程有mpp解码实现 解h264得到nv12图像
预处理
为了减少cpu占用和提高帧率 处理图像尽量不使用opencv 而是使用rga 例程有rga处理图像实现 主要实现放缩和nv12转rgb
但是预处理一般用letterbox方式 就是要宽高等比放缩 多余空间填充黑边 图像居中等 这样一来就不是放缩和nv12转rgb这么简单了 还要位移填充 坐标处理等
另外rga的使用会有很多注意事项 需要查阅官方文档 网上很多使用rga出现4G内存报错、图像抖动和处理慢都是对rga理解不够 解决办法有限定rga3核和使用专门的内存分配器等
此测试使用letterbox方式
推理
例程有推理的实现 但那是只使用了一个npu核 实际使用需要把所有核都调动起来 提高处理帧率 一般有两种办法 一个是多核推理 一个是多线程推理
多核推理是在一个线程内让多个npu核共同推理每一帧
多线程推理是为每个npu核各用一个线程 各线程轮流输入不同的图像给npu逐个推理
他们的特点是 多核推理时延迟低 多线程推理帧率高
举个具体的例子 在3576上两个npu核 一个核推理耗时50ms 两个核进行多核推理 是两个核共同推理一帧 耗时40ms 仅减少10ms 总帧率是25 但是两个核进行多线程推理 是两个核分别推理一帧 一个核推理耗时50ms 单核帧率20 两个核总帧率20*2=40 一般为了高帧率而选择使用多线程推理
官方文档对多核推理的使用和调优有详细的说明 多核推理适用于模型网络更复杂的场景 多核推理的调度需要cpu参与 可以通过把程序绑定cpu大核和调中断来提高多核推理的效率
实现方面 多核推理实现简单 只需要一个api就能实现 多线程推理实现复杂 需要自己做npu调度 分配各核输入输出 需要保证负载均衡 保证输入输出顺序
此测试使用多线程推理方式
后处理
例程有输出过滤的nms和画框实现 主要是少了打标签
画框是用cpu实现的 即根据坐标点直接改写图像数据
而且是直接在解码出来的nv12图像上画框 而不是rgb图像 这样减少了nv12转rgb的处理时间 而且如果不这样做 后面编码还要转多一次rgb转nv12
理论上讲要换成rga画框 但是实际上因为画框需要处理的像素点太少了 一般cpu画框比rga画框快 目标太多可能会不一样 需要根据实测来决定方式 我这边实测cpu画框平均每帧耗时3.39ms 而rga画框平均每帧耗时7.8ms 所以一般选择opencv画框
打标签在例程上有部分实现 得到标签文字后需要用opencv将文字转成图像 此时是rgb格式 也用opencv转成nv12 最后将文字的图像填充到原来的图像也是和画框那样用cpu实现 以上图像处理不用rga实现 原因和画框一样
编码 例程有mpp编码实现 nv12图像编码得到h264
rtsp流服务 用的网上开源的叫rtsp_demo的项目 将h264封装成rtsp流服务 外部可以直接拉流
以上各处理流程都必须各用一条线程 保证相互独立互不影响 每个线程都要通过线程安全队列传输输入输出数据 像流水线一样逐级处理
模型用的例程里的模型
测试视频是1080p@30 码率2554kbps
播放视频
在pc上用vlc拉流的rtsp
资源占用率
cpu 50% (满载800%)
mem 1.3% 105MB
npu core0:15% core1:16% core2:15%
rga rga3_core0:10% rga3_core1:0% rga2:0%
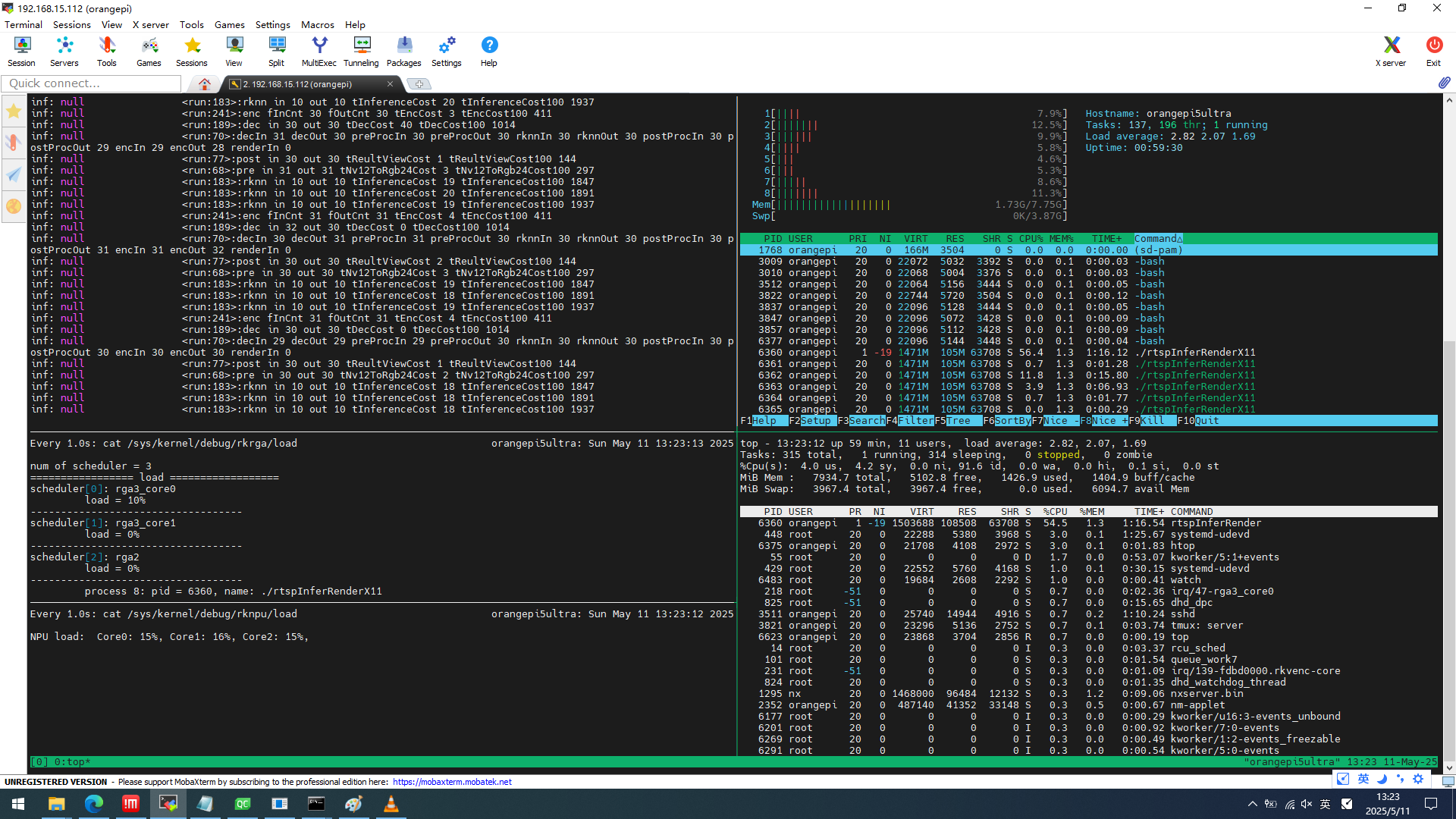
输出信息
inf: null <run:70>:decIn 30 decOut 30 preProcIn 30 preProcOut 29 rknnIn 29 rknnOut 30 postProcIn 30 postProcOut 31 encIn 31 encOut 31 renderIn 0
inf: null <run:77>:post in 29 out 29 tReultViewCost 1 tReultViewCost100 97
inf: null <run:68>:pre in 29 out 29 tNv12ToRgb24Cost 2 tNv12ToRgb24Cost100 285
inf: null <run:183>:rknn in 10 out 10 tInferenceCost 17 tInferenceCost100 1913
inf: null <run:183>:rknn in 9 out 9 tInferenceCost 19 tInferenceCost100 1887
inf: null <run:183>:rknn in 10 out 10 tInferenceCost 19 tInferenceCost100 1839
inf: null <run:241>:enc fInCnt 27 fOutCnt 27 tEncCost 4 tEncCost100 420
inf: null <run:189>:dec in 30 out 30 tDecCost 0 tDecCost100 1012
信息总结
每帧平均耗时ms
解码 10.12 预处理 2.85 推理 18.79 后处理 0.97 编码 4.2

















 9265
9265

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









