









By the time you finish this class
* You’ll know how to apply the most advanced machine learning algorithms to such problems as anti-spam, image recognition, clustering, building recommender systems, and many other problems.
* You’ll also know how to select the right algorithm for the right job, as well as become expert at ‘debugging’ and figuring out how to improve a learning algorithm’s performance.
Week 1
Introduction
- What is Machine Learning(机器学习是什么
- 机器学习分类:
- Supervised Learning监督学习:已经知晓样本应该归属的类别
- Unsupervised Learning 非监督学习:不知道样本所属的类别
Model and Cost Function
(数学模型和代价函数)
1. 模型表现
2. 代价函数
Parameter Learning
- Gradient Descent(梯度下降法)
- Linear Regression with One Variable
- Gradient Descent for Linear Regression
Linear Algebra Review
Week 2
Linear Regression with Multiple Variables
- Multiple Features
- Gradient Descent for Multiple Variables
- Gradient Descent in Practice
- Feature Scaling
- Learning Rate
- Features and Polynomial Regression
Computing Prameters Analytically
- Normal Equation
- Noninvertibility
Submitting Programming Assignments
Octave/Matlab Tutorial
->Summary&Note
机器学习的目的是通过已有的样本数据,对样本外的个体进行自动预测或者分类。机器学习的种类可以分为监督学习和非监督学习,机器学习的具体工作内容有定量性质的回归,以及针对类别的分类。
说到回归,就是要构造出函数尽量去拟合所有样本数据,从而能对样本外的结果进行预测,这里用最小二乘法来计算函数同实际样本数据的误差,实际方式有两种,分别是:Gradient Descent 和 Normal Equation,前者从高数中的微积分角度来理解,后者可以从线性代数中的向量投影来理解。
Gradient Descent 和 Normal Equation 的比较
Gradient Descent
\theta_{j}:=\theta_{j}-\alpha\frac{1}{m}\sum_{i=1}^m(h_{\theta}(x^{(i)}-y^{(i)}))*x_j^{(i)}
vectorization:
\theta := \theta-\frac{\alpha}{m}X^{T}(h_{\theta}(X)-Y)Gradient Descent 在实际操作中,计算代价函数并修改theta参数使得模型在迭代中不断接近理想。为了提高拟合速度,可以增大学习率alpha,也可以将样本中的数据进行缩放,常见的有归一化。学习率的选择有讲究,太小会拖延,太大则不容易得到理想Feature数据,甚至于使得函数无法收敛,算法的时间复杂度为 O(Kn^2)。
Mean Normalization:
x_{i}:=\frac{X_{i}-\mu_{i}}{s_{i}}
Normal Equation
\theta=(X^{T}X)^{-1}X^{T}y则是通过矩阵计算来直接获得理想的 features ,简单直接,算法的时间复杂度为O(n^3)。
样本量较小的时候选Normal Equation没跑,一般在样本量 >10000 的时候会毫不犹豫选择Cost Function。
附注:关于 Normal Equation 的推导,David C. Lay 所著的 Linear Algebra and its Applications 中有很优秀的讲解。
Week 3
Logistic Regression
0<=h_\theta<=1- Hypothesis Representation:
h_{\theta}(x)=\frac{1}{1+e^{-\theta^{T}X}}:Logistic function
g(z)=\frac{1}{1+e^{-z}} :Sigmoid function
h_{\theta}(x)=g(\theta^Tx)
P(y=0|x;\theta) = 1- P(y=1|x;\theta)
Decision boundary
确定 h() 函数分类阈值Cost Function
注意区分 Linear regression 和 logistic regression 代价函数的不同
J(\theta)=\frac{1}{m}\sum_{i=1}^mCost(h_\theta,y^{(i)})
=\frac{1}{m}[\sum_{i=1}^my^{(i)}log(h_\theta(x^{(i)})+(1-y^{(i)})log(1-h_\theta(x^{(i)}))]- Simplified cost function and gradient descent
- Gradient descent
\theta_j:=\theta_j - \alpha\frac{\partial}{\partial\theta_j}J(\theta)Regularization
Muticlass Classification
Solving the Problem of Overfitting
This terminology is applied to both linear and logistic regression. There are two main options to address the issue of overfitting:
1) Reduce the number of features:
Manually select which features to keep.
Use a model selection algorithm (studied later in the course).
2) Regularization
Keep all the features, but reduce the magnitude of parameters θj.
Regularization works well when we have a lot of slightly useful features.
修改cost function,加入参数大小对函数的评估,从而限制高次项系数大小,让boundary更平滑,减小overfitting(过拟合)
Recall that if m < n, then XTX is non-invertible. However, when we add the term λ⋅L, then XTX + λ⋅L becomes invertible.
Week 4
Neural Networks Representation
一种 解决特征很多组合又十分复杂的非线性模型的Regression问题 的方法
Model representation
a_i^j : activation of unit i in layer j
\Theta^{(j)} = matrix.of.weights. controlling.function.mapping.from layer.j.to.layer.j+1
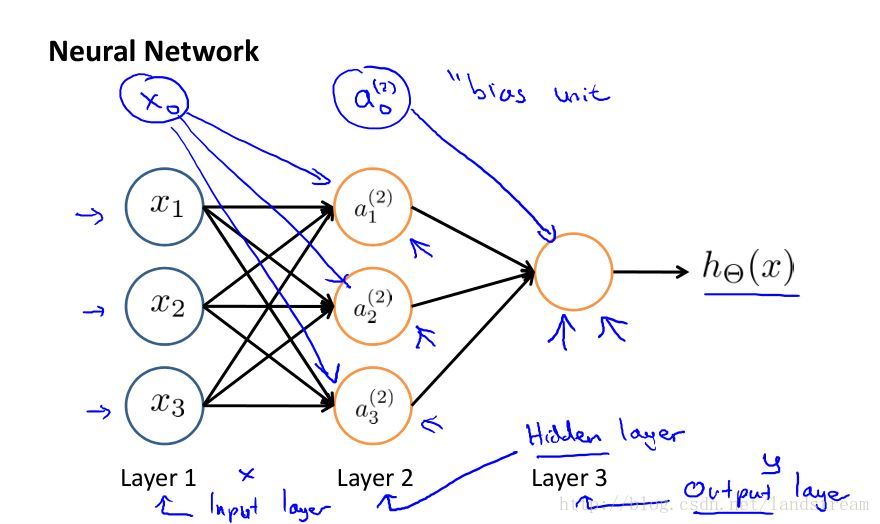
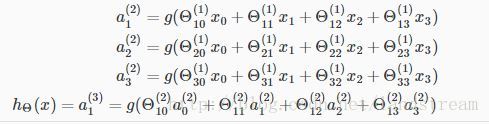
Notes
神经网络模型能够方便灵活的表达包括:布尔逻辑运算、复杂的多项式运算等数学模型,可以提高训练的时间效率。















 305
305

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









