







具体的软硬件实现点击 MCU-AI技术网页_MCU-AI人工智能
前言
虽然血压(BP)的测量现在广泛地由自动无创血压(NIBP)监测设备进行,因为它们不需要熟练的临床医生,也不存在并发症的风险,但其准确性仍存疑。本研究开发了一种新的基于端到端深度学习的算法,该算法直接从Korotkoff声音(KSs)序列而不是示波波形(OWs)来估计NIBP。首先,使用不同的信号分割技术形成KSs的片段序列,即,使用具有或不具有重叠的滑动窗口进行分割,以及使用心搏周期估计进行分割。然后将每个序列中的每个片段标记为1)收缩后和舒张前(AB)或2)收缩前或舒张后(BA),从而实现二元序列到序列的分类问题。为了解决由此产生的序列到序列分类问题,将一维卷积神经网络(CNNs)和递归神经网络(RNNs)相结合,开发了一种算法。然后,与收缩压和舒张压相关的节段(SBP和DBP)被识别为输出目标序列从BA类切换到AB类,然后从AB类切换到BA类的节段。最后,通过将切换节段的中心点映射到放气曲线来获得SBP和DBP的值。为了评估所提出的NIBP估计方法的性能,我们使用了从155名参与者(87名男性,年龄:23-97岁,臂围:10-35 cm,收缩压:81-104 mmHg,舒张压:37-104 mmHg)收集的350个NIBP样本的数据库,使用五倍交叉验证方法,相对于参考值,收缩压和舒张压的估计误差分别为1.6±3.9 mmHg(平均绝对误差±误差标准差)和2.5±4.0 mmHg。我们最后得出结论,所提出的基于端到端深度学习的KSs序列NIBP估计算法是一种新技术,需要适度的预处理步骤,可以准确地测量BP。
持续有创血压是危重患者管理过程中监测的一个非常重要的生命体征。为了有创地测量血压,将导管插入桡动脉,因此,必须由熟练的临床医生进行。尽管如此,这仍然会使患者面临不同的风险,如缺血、感染和出血[6]。因此,无创血压(NIBP)监测设备现在被广泛用于测量血压。公认的NIBP测量的黄金标准是听诊血压计[7],[8],将袖带放在上臂上,并充气至收缩压以上(SBP),以确保肱动脉完全闭塞。放置在闭塞袖带下方和肱动脉上方的听诊器用于检测袖带放气期间的Korotkoff音(KSs),其中收缩压和舒张压(DBP)分别对应于KSs的出现和消失。然而,这种长期存在的听诊方法正在让位给使用示波法[9]、[10]进行NIBP测量的自动化方法,其中SBP和DBP是通过分析袖带放气过程中袖带压力振荡的包络(即示波波形包络(OWE))的专有算法来确定的。
传统示波法的主要关注点是OWE,并且已经提出了几种传统算法,包括最大幅度算法(MAA)[11]和最大/最小斜率算法(MMSA)[12],来从OWE估计SBP和DBP。最近注意到,示波脉冲的信息量也很大,因此,已经努力开发算法来从示波脉冲估计SBP和DBP。这种方法通过对示波脉冲建模或通过测量和处理示波脉冲形态的变化来估计NIBP值[13]。
文献中提出的大多数基于人工智能(AI)的NIBP估计算法都使用示波波形(OW),更具体地说,它们模仿了经典的MAA。换言之,这些基于人工智能的算法使用从OWE中提取的特征,并通过不同的基于人工智能算法,如高斯混合模型(GMM)和高斯混合回归(GMR),以及深度学习回归方法,估计SBP和DBP对应的比率[9]。最近,已经开发了不同的基于AI的NIBP估计方法,其中使用分类问题来估计SBP和DBP,该分类问题是为了对从示波图的脉冲中提取的特征向量进行分类而形成的。几种基于人工智能的分类方法被用于使用示波脉冲来估计NIBP。这些基于分类的方法根据其考虑相邻脉冲之间相关性的能力可分为两大类,例如,长短期记忆递归神经网络(LSTM RNN)[14]和隐马尔可夫模型(HMM)[15]与基于深度信念网络(DBN-DNN)和前馈神经网络(FFNNs)的分类模型[16]。
无袖带NIBP监测方法开始成为NIBP估计的一种流行模式。这些设备对高血压的意识、管理和控制非常有用。然而,目前无袖带NIBP监测设备的准确性存在严重问题,2021年欧洲高血压学会血压测量指南不建议临床使用[17]。
示波NIBP测量通常也被认为不如听诊测量准确[18],[19],并且示波图可能会受到心律失常的干扰,心律失常经常出现在65岁以上患有慢性病的老年患者中[20],[21]。为了直接从KSs中估计NIBP,并进一步评估市场上的示波NIBP监测设备的准确性,已经引入了许多基于智能手机的试剂盒[22],[23]。另一方面,大量研究表明,使用血压计进行血压测量的不同操作员的读数之间存在显著差异[24],[25]。这表明开发自动化听诊技术的必要性,该技术较少依赖于操作者。
在这项研究中,开发了一种新的基于端到端深度学习的技术来从KSs中准确估计NIBP,该技术需要适度的预处理,属于上文讨论的后一类。该方法使用两种分割技术将NIBP估计从数字化的KSs转换为seq到seq的分类问题,这两种分割方法可以在不具有并行OW的情况下分割KSs。这与现有提出的用于形成序列到序列分类问题[27]、[30]、[31]的方法不同,这些方法需要并行OW。此外,我们开发并使用了卷积神经网络(CNNs)和双向LSTM RNN(BiLSTM RNNs)的组合,即CNN-BiLSTM RNNs,来对通过分割技术获得的片段进行分类。这可以根据其他(以前和将来)片段对从KSs导出的片段进行分类,从而可以有效地处理KSs中发生在收缩点之前或舒张点之后的噪声。这种方法也不同于当前使用手动特征提取技术的方法(参见[30],[31]),并且需要较少的预处理步骤来处理原始KSs并为seq-to-seq分类算法提取合适的输入(特征)。
数据集
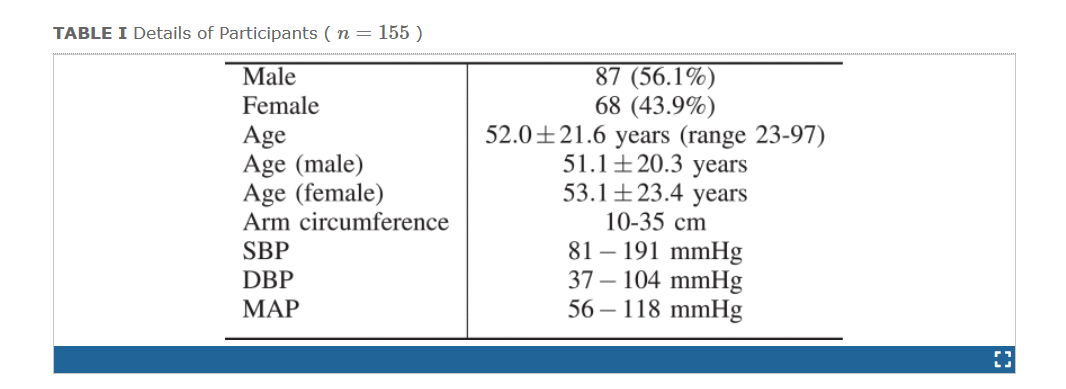
本研究中使用的数据库(UNSW研究伦理委员会,申请号:12/11)包括通过单一NIBP监测设备收集的350份NIBP记录,该设备是Telemedcare Pty有限公司的多参数临床监测单元(CMU),并获得FDA批准。CMU只是一个数据收集设备,其功能可以被许多其他设备取代。它已不再生产。我们在正常的自动化配置中使用了NIBP模块。该模块自动将袖带充气至预设压力,并进一步使用伺服控制以每秒2-3毫米的速度对袖带放气。该设备以10位分辨率和500采样s−1的采样率在0到5 V之间内部记录袖带压力、KSs和示波信号,并将其保存为XML文件。[24]中对我们文章中使用的数据收集方法进行了广泛描述。每个NIBP记录都包含袖带压力信号、OW和相应的数字化KSs。这些样本是从155名参与者(87名男性)身上采集的。该数据集中每个患者的最大和最小记录数分别为5和1。参与者的详细信息见表I,可在[24]中找到。
数据预处理
1) 高通滤波:
与之前解释的确定黄金参考值的过程一致,我们使用20 Hz的截止频率对KSs进行高通滤波。
2) 均方根能量计算:
对应于每个KS信号的均方根(rms)能量(RMSEn)也通过将零相位移动平均数字滤波器(使用100ms的汉明窗口)应用于滤波的KS来计算。RMSEn在[24]中被用作背景噪声的测量,并进一步提高KSs的信噪比。在本研究中,检测RMSEn信号的峰值位置,并将其用作固定长度片段所在的中心点。
3) KS和RMSEn信号的归一化:
然后对每个高通滤波的KS信号进行标准化,即zi=(xi−x’/SDxi),其中xi是第i个KS序列,x’是其平均值,SDxi表示其标准偏差,相应的RMSEn被标准化为[0,1]。
为了形成基于深度学习的seq-to-seq分类算法(在本节的下文中详细阐述)的输入,使用以下两种方法对处理后的KSs进行分割。
众所周知的分段之间有或没有重叠的滑动分割技术[34],以下称为第一分割方法。
片段以算法1检测到的点为中心,该算法根据RMSEn信号估计心搏周期,并随后确定固定长度片段所处的中心点,下文称为第二分割方法。注意,算法1中的findPeak(‧,‧,‧)是一个子程序,它接收一个信号,即RMSEn和两个阈值,即α=0.5和β=200,并返回最小高度为α和最小距离为β样本的峰值的指数。此外,findMax(‧)是一个接收信号并返回其最大值的位置(索引)的子程序。


来自每个KS序列的每个片段被标记为:1)收缩后和舒张前(AB)和2)收缩前或舒张后(BA)。定义BA=1和AB=2,第i段的输出目标可以写成yi∈{1,2}。让我们假设第j个分段的KS序列由nj个分段组成。该样本的目标序列可以表示为Yj=[y1,y2,…,ynj]。使用从KSs获得的片段,我们形成深度学习模型的输入(来自KSs的片段序列);图2显示了这一点。有了从KSs导出的片段序列和相应的目标标记序列,作为从KSs估计SBP和DBP的第一步,我们形成了一个seq-to-seq分类问题,该问题由设计的CNN-BiLSTM-RNN模型处理,在本节中解释如下。应当注意,SBP和DBP是从如下标签序列中发现的。
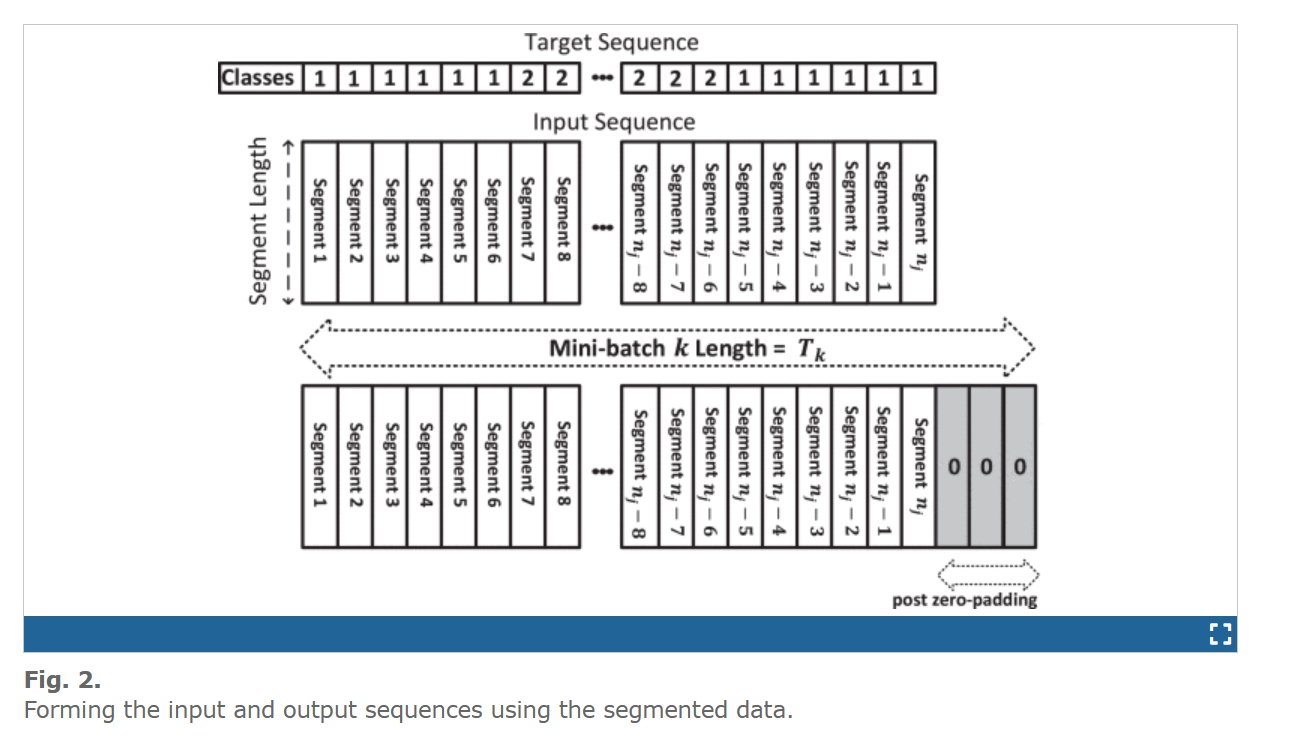
在这项研究中,我们使用了一种五重交叉验证方法,即将数据集随机分为五个子集,每个子集包括70个样本,在每次运行中,使用四个子集来训练深度学习模型,并使用一个子集作为测试数据集。尽管对于每个样本,使用CNN从每个片段提取的特征的数量是相同的,但是从不同KS样本导出的片段的数量以及由此产生的输入序列的长度将不是固定的。因此,由于所设计的网络的输入必须是具有固定维度的张量,我们将训练数据划分为多个子集(小批量),并进一步对每个小批量内的序列进行后零填充(见图2)。
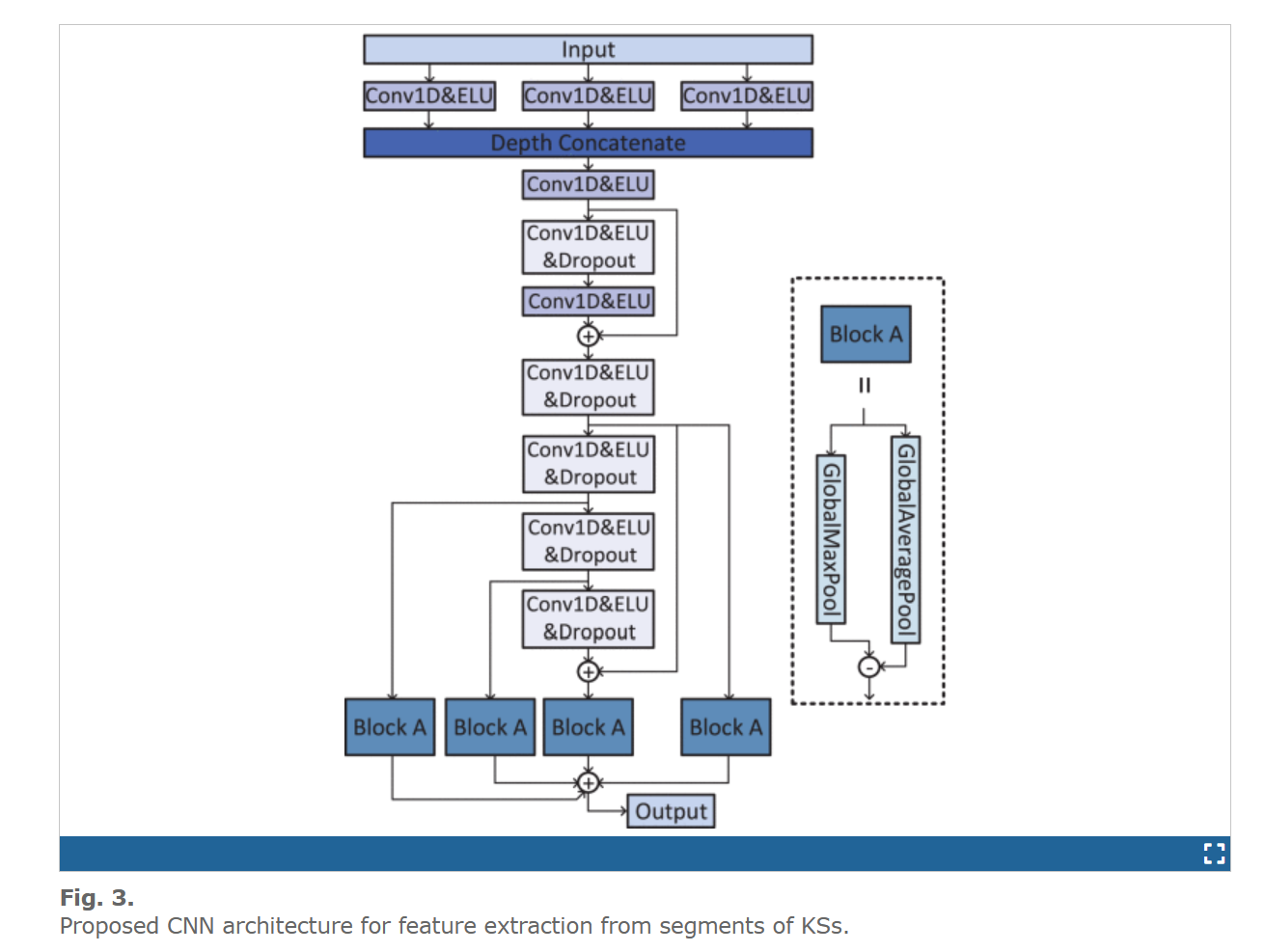
所开发的CNN BiLSTM模型的结构如图1和图3所示
这里报告的结果是从五个不同的测试样本集得出的五个值的平均值。如表II所示,我们对80%的NIBP样本进行了广泛的实验,并对其余20%的样本进行了验证,从而调整了所设计的CNN-BiLSTM的超参数。因此,所获得的结果对调谐超参数的敏感性是适度的。

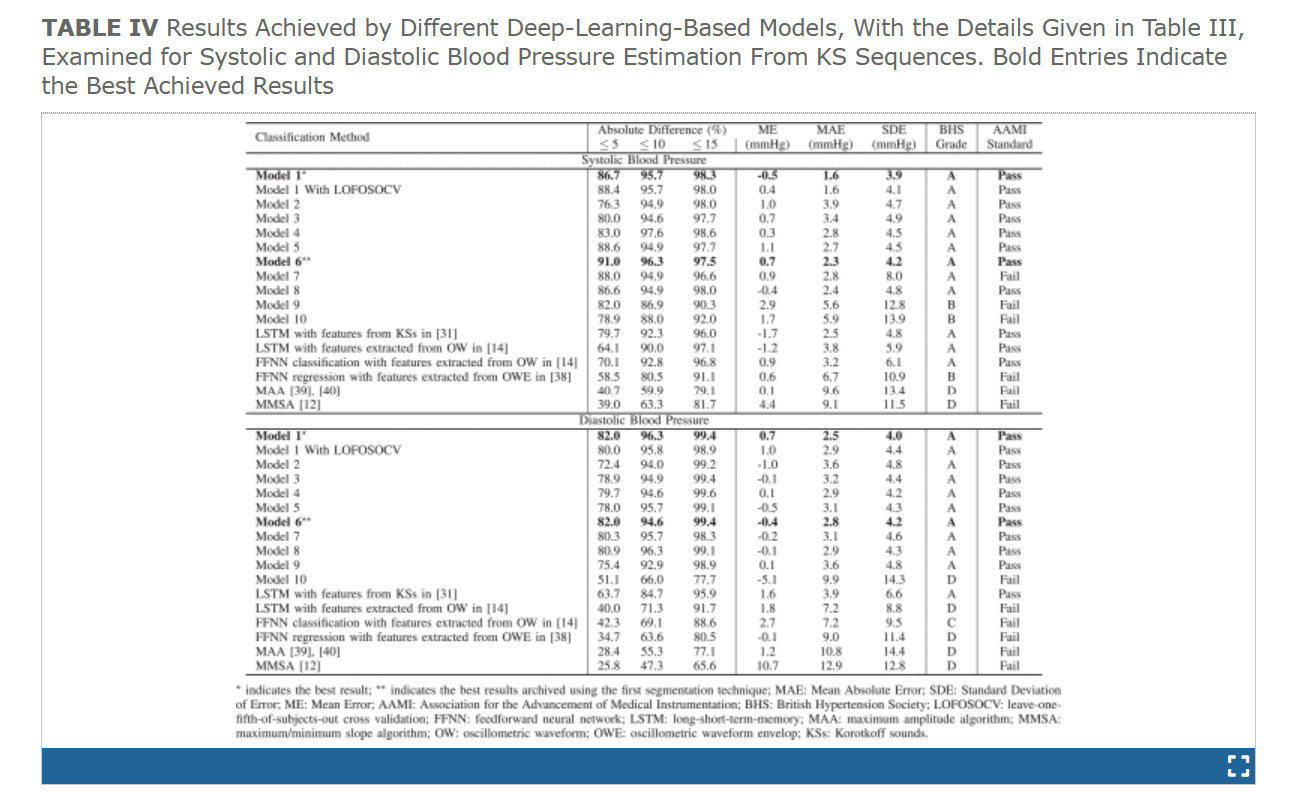
在这项研究中,我们测试了图中使用CNN架构的十个不同模型。3用于特征提取,结构/参数如表III所示。表IV显示了使用不同分割方法从不同模型获得的结果。
















 764
764

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









