







一、项目背景
手写字符识别是计算机视觉中的一个重要问题,具有广泛的应用,包括自动化处理邮政信件、文档数字化、自动标注等任务。传统的手写字符识别方法依赖于人工提取特征,但随着深度学习的发展,特别是卷积神经网络(CNN)的崛起,现如今的手写字符识别已经逐步实现了自动化特征学习和高效识别。
本项目旨在开发一个基于卷积神经网络(CNN)的手写英文字母识别系统。该系统将能够识别图像中的手写字母并输出对应的字母类别。
二、项目目标
本项目的主要目标是:
- 设计并训练一个卷积神经网络模型:基于 EMNIST(扩展版 MNIST)数据集,设计一个卷积神经网络模型,能够对手写英文字母进行分类。
- 开发数据预处理模块:将图像数据转为适合模型输入的格式,包括灰度化、尺寸调整和标准化。
- 训练并评估模型:使用训练数据进行模型训练,并使用测试数据评估模型的性能。
- 实现图像预测功能:使用训练好的模型对新的手写字母图像进行预测,并输出结果。
三、项目技术方案
1. 技术框架
- 深度学习框架:本项目使用 PyTorch 作为深度学习框架。PyTorch 提供了灵活性、强大的计算图和易于调试的特性,成为当前深度学习领域的主流框架。
- 数据处理:使用
torchvision提供的图像处理工具,将图像转换为符合模型要求的格式。 - 卷积神经网络(CNN):模型通过卷积层提取图像特征,再通过池化层进行下采样,最后通过全连接层进行分类。
2. 数据集
本项目使用 EMNIST 数据集(扩展版 MNIST),包含 26 个英文字母的手写图像(A-Z)。该数据集是由原始 MNIST 数据集扩展而来,包含了更丰富的字母类别数据。PyTorch 的 torchvision.datasets 模块已经提供了加载和预处理该数据集的接口。
- EMNIST 数据集的标签:EMNIST 数据集中的字母标签从 1 开始,因此在训练过程中需要调整标签,以适应模型的输入格式。
3. 模型设计
本项目的核心是设计一个卷积神经网络(CNN)来处理图像数据,进行手写字母识别。网络结构如下:
- 输入层:图像尺寸为 28x28,单通道(灰度图像)。
- 卷积层 1:输入 1 通道,输出 32 通道,卷积核大小为 3x3,步长为 1,padding 为 1。
- 卷积层 2:输入 32 通道,输出 64 通道,卷积核大小为 3x3,步长为 1,padding 为 1。
- 池化层:使用最大池化(MaxPooling)操作来进行下采样。
- 全连接层 1:将卷积层输出展平,并通过全连接层(FC)进行处理,输出 128 维特征。
- 全连接层 2:输出 26 个类别对应的分类结果。
4. 模型训练
训练过程使用 交叉熵损失函数(CrossEntropyLoss),优化器使用 Adam 优化器。训练过程中,每个 epoch 会计算训练损失和验证准确率,并保存表现最好的模型权重。
5. 预测功能
模型训练完成后,用户可以通过 predict.py 模块对新的手写英文字母图像进行预测。该模块加载训练好的模型,输入图像数据,输出预测结果。
四、研究计划
1. 阶段划分
第一阶段:数据准备与预处理(预计时间:1周)
- 下载并准备 EMNIST 数据集。
- 对图像数据进行尺寸调整、灰度化处理,确保数据格式一致。
- 编写并测试数据加载模块,确保数据可以顺利输入到模型中。
第二阶段:模型设计与训练(预计时间:2周)
- 设计并实现 CNN 模型结构。
- 编写训练代码,使用 EMNIST 数据集进行训练。
- 调整超参数,进行模型优化。
第三阶段:评估与测试(预计时间:1周)
- 评估训练好的模型在验证集和测试集上的准确率。
- 调整模型架构或参数以提高模型性能。
第四阶段:预测功能开发与集成(预计时间:1周)
- 实现预测功能,输入新的手写字母图像并进行分类。
- 集成训练和预测模块,完成最终系统。
2. 开发工具与环境
- 编程语言:Python
- 深度学习框架:PyTorch
- 图像处理库:PIL、torchvision
- 开发环境:Anaconda(虚拟环境管理)、Jupyter Notebook(实验验证)
- 操作系统:Windows / Linux(适配 GPU 加速)
五、预期成果
- 手写字母识别模型:基于卷积神经网络的手写英文字母识别模型,能够准确识别图像中的字母。
- 分类系统:一个完整的图像分类系统,能够处理手写字母图像并返回分类结果。
具体代码实现分析:
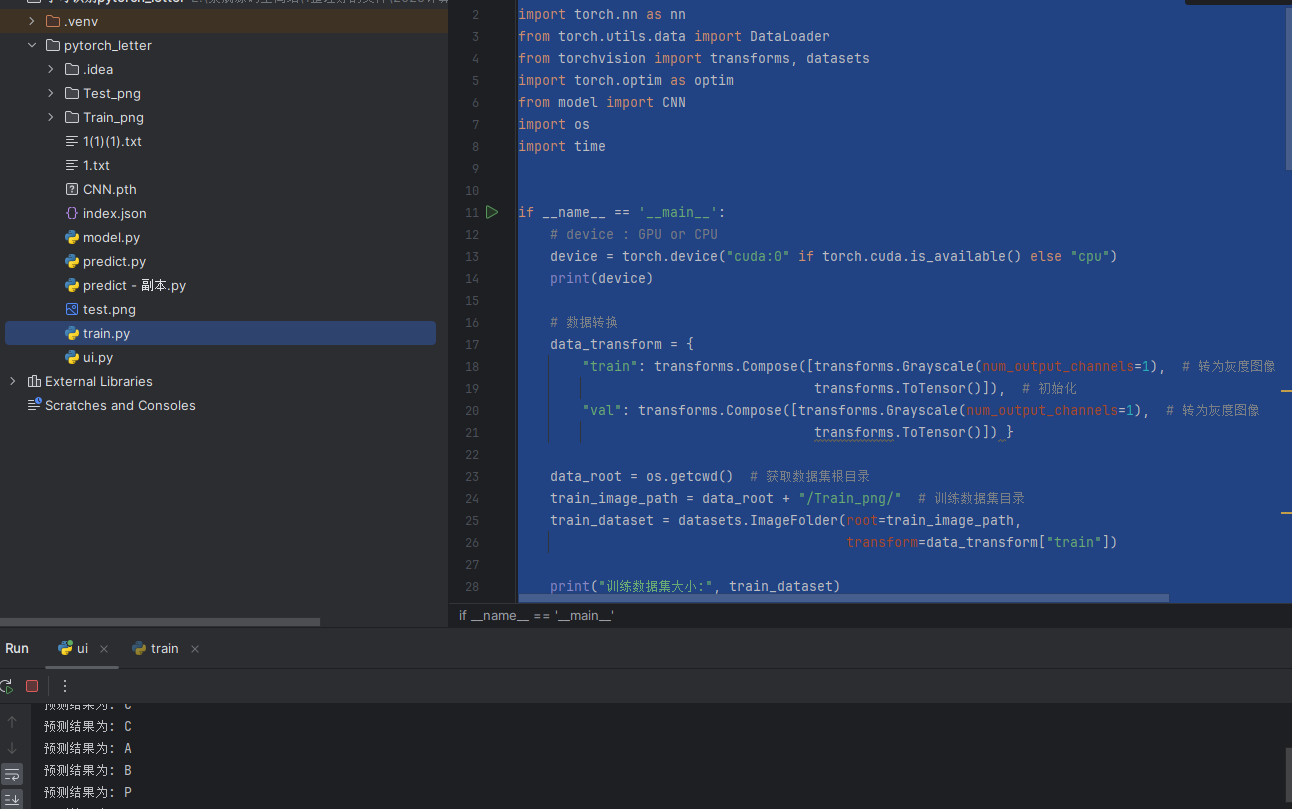
1. 设备配置:
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
print(device)
- 这段代码根据是否有可用的 GPU 来选择设备。如果有 GPU,则使用 GPU (
cuda:0),否则使用 CPU。 torch.cuda.is_available()检查当前环境是否支持 CUDA。
2. 数据预处理:
data_transform = {
"train": transforms.Compose([transforms.Grayscale(num_output_channels=1),
transforms.ToTensor()]), # 训练集数据预处理
"val": transforms.Compose([transforms.Grayscale(num_output_channels=1),
transforms.ToTensor()]) # 验证集数据预处理
}
- 这部分代码定义了训练集和验证集的转换操作:
transforms.Grayscale(num_output_channels=1):将图像转换为单通道的灰度图像。transforms.ToTensor():将图像转换为张量,并将像素值标准化到[0, 1]范围。
3. 加载训练集和验证集数据:
train_image_path = data_root + "/Train_png/"
train_dataset = datasets.ImageFolder(root=train_image_path,
transform=data_transform["train"])
train_loader = DataLoader(train_dataset, batch_size=batch_size, shuffle=True,
num_workers=4, pin_memory=True)
datasets.ImageFolder()用来从文件夹加载图片数据,并根据目录结构自动为每个类别分配一个标签。- 训练集图像存放在
Train_png文件夹中,采用之前定义的data_transform["train"]进行预处理。 DataLoader用于加载数据集,设置了批量大小batch_size、数据是否打乱shuffle=True,并利用多个进程num_workers=4来加速数据加载。
类似地,验证集数据被加载到 validate_loader。
4. 模型定义:
net = CNN() # 使用CNN模型 net.to(device) # 将模型转移到指定设备
CNN()是假设存在的一个卷积神经网络模型,您需要在model.py文件中定义这个网络结构。net.to(device)将模型移动到 GPU 或 CPU,取决于设备设置。
5. 定义损失函数和优化器:
loss_function = nn.CrossEntropyLoss() # 使用交叉熵损失函数 optimizer = optim.Adam(net.parameters(), lr=0.0001) # 使用Adam优化器,学习率0.0001
- 使用了 交叉熵损失函数(
CrossEntropyLoss),适用于多分类任务。 - 使用 Adam 优化器 来优化模型的参数,学习率设置为
0.0001。
6. 训练过程:
for epoch in range(50):
# train
net.train() # 切换到训练模式(启用 dropout 等)
running_loss = 0.0
for step, data in enumerate(train_loader):
images, labels = data
optimizer.zero_grad() # 清除之前计算的梯度
outputs = net(images.to(device)) # 前向传播
loss = loss_function(outputs, labels.to(device)) # 计算损失
loss.backward() # 反向传播计算梯度
optimizer.step() # 更新模型参数
running_loss += loss.item() # 累计损失
# 打印训练进度
rate = (step + 1) / len(train_loader)
a = "*" * int(rate * 50)
b = "." * int((1 - rate) * 50)
print("\rtrain loss: {:^3.0f}%[{}->{}]{:.3f}".format(int(rate * 100), a, b, loss), end="")
print()
- 每一轮(epoch)中,模型都会执行训练过程:
- 将数据(图像和标签)输入到网络中,进行前向传播计算预测结果。
- 使用交叉熵损失函数计算损失。
- 进行反向传播计算梯度,并通过优化器更新模型的参数。
- 每处理一批数据,都会更新累计损失并打印训练进度。
7. 验证过程:
net.eval() # 切换到评估模式(禁用 dropout)
acc = 0.0
with torch.no_grad(): # 在验证过程中不需要计算梯度
for val_data in validate_loader:
val_images, val_labels = val_data
outputs = net(val_images.to(device)) # 获取预测结果
predict_y = torch.max(outputs, dim=1)[1] # 选择预测类别
acc += (predict_y == val_labels.to(device)).sum().item() # 统计准确预测的数量
val_accurate = acc / val_num # 计算验证集准确率
- 在每个 epoch 后,会对验证集进行评估:
- 将模型切换到
eval()模式,这样就不会启用训练时特有的技术(如 dropout)。 - 通过
torch.no_grad()禁用梯度计算,减少内存使用。 - 遍历验证集,计算预测类别并统计预测正确的数量,最后计算准确率。
8. 保存最佳模型:
if val_accurate > best_acc:
best_acc = val_accurate
torch.save(net.state_dict(), save_path) # 保存模型
- 如果当前 epoch 的验证准确率优于之前记录的最高准确率,则更新
best_acc并保存当前模型的权重。 torch.save(net.state_dict(), save_path)保存模型的权重(参数)到指定路径。
9. 输出训练结果:
print('[epoch %d] train_loss: %.3f test_accuracy: %.3f' %
(epoch + 1, running_loss / len(train_loader), val_accurate))
- 每个 epoch 结束后,会打印当前训练集的平均损失值和验证集的准确率。
10. 结束训练:
print('Finished Training')
- 训练完成后,打印信息。
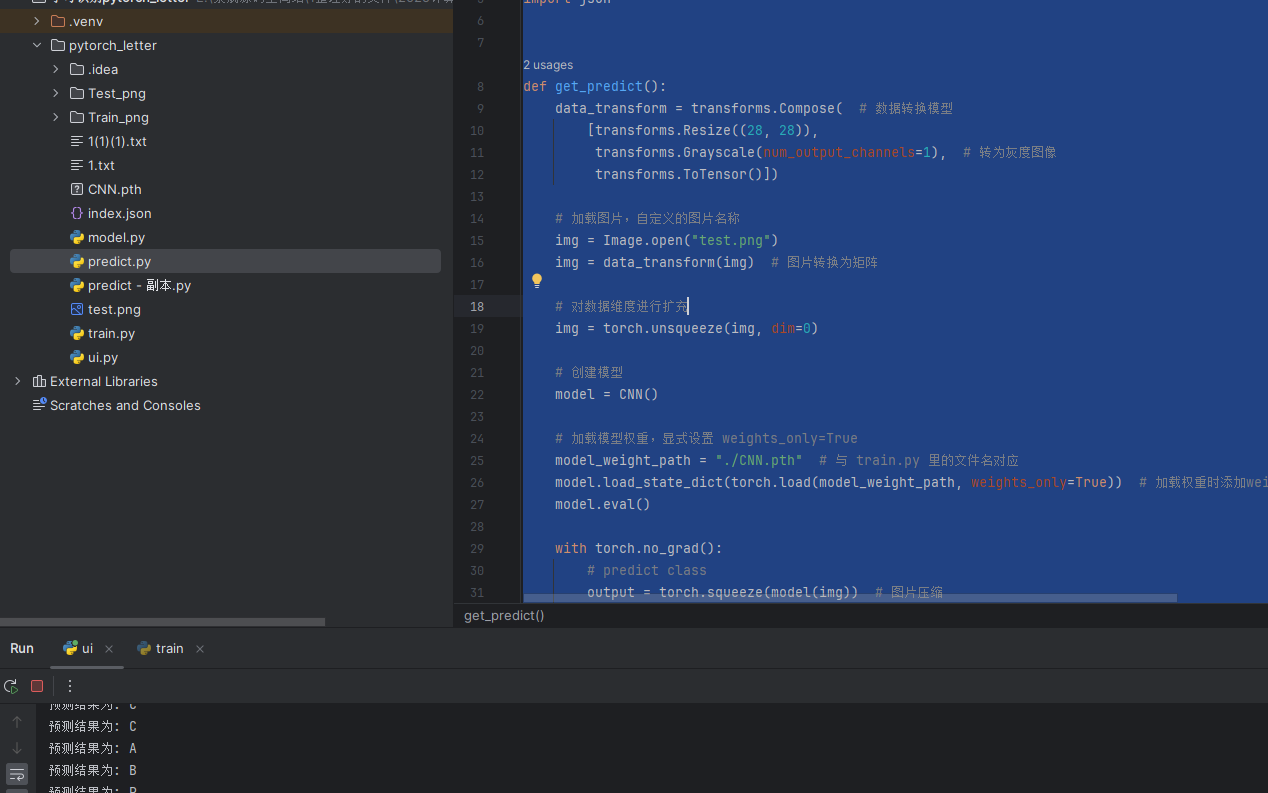
主要包括加载图像、转换为张量、加载训练好的模型权重、进行推理预测,并返回分类结果。下面逐步解析每一部分:
1. 数据预处理:
data_transform = transforms.Compose( # 数据转换模型
[transforms.Resize((28, 28)),
transforms.Grayscale(num_output_channels=1), # 转为灰度图像
transforms.ToTensor()])
transforms.Resize((28, 28)):将输入图像的大小调整为 28x28 像素。通常这个步骤是为了匹配网络输入的尺寸要求。transforms.Grayscale(num_output_channels=1):将输入图像转换为灰度图像。num_output_channels=1表示输出图像是单通道的灰度图像(而不是 RGB 三个通道)。transforms.ToTensor():将图像转换为 PyTorch 的张量,并将像素值缩放到 [0, 1] 范围。图像会被自动转换为C x H x W的张量(即通道数、高度和宽度)。
2. 加载图片:
img = Image.open("test.png")
img = data_transform(img) # 图片转换为矩阵
Image.open("test.png"):使用PIL库打开名为test.png的图片文件。data_transform(img):使用之前定义的数据转换步骤 (data_transform),将图像转换为灰度图像、调整大小,并将其转换为 PyTorch 张量。
3. 维度扩充:
img = torch.unsqueeze(img, dim=0)
torch.unsqueeze(img, dim=0):该步骤将张量img的维度扩展,使其变为(1, C, H, W)的四维张量,代表批量大小为 1 的图像数据。原始的img张量是(C, H, W),即单张图像的形状。使用unsqueeze方法在最前面添加一个维度,表示批量大小。
4. 加载模型:
model = CNN() model_weight_path = "./CNN.pth" # 与 train.py 里的文件名对应 model.load_state_dict(torch.load(model_weight_path, weights_only=True)) # 加载权重时添加weights_only=True model.eval()
CNN():创建CNN类的实例,假设在model.py文件中定义了一个卷积神经网络模型CNN。此时模型的参数是随机初始化的。model.load_state_dict(torch.load(model_weight_path, weights_only=True)):加载模型的预训练权重。model_weight_path是保存模型权重的文件路径,通常是训练后保存的.pth文件。weights_only=True:表示只加载模型的权重,而不加载模型的结构定义。model.eval():将模型切换为评估模式。在评估模式下,像 dropout 或 batch normalization 这类训练时特有的操作会被禁用,确保在推理过程中模型的行为是确定性的。
5. 进行推理:
with torch.no_grad():
# predict class
output = torch.squeeze(model(img)) # 图片压缩
predict = torch.softmax(output, dim=0) # 求 softmax 值
predict_cla = torch.argmax(predict).item() # 预测分类结果,使用 .item() 获取标量值
torch.no_grad():这段代码使用torch.no_grad()来禁用梯度计算,因为在推理阶段,我们不需要计算和存储梯度,从而节省内存和计算资源。model(img):将图像输入到网络中,进行前向传播,得到网络的输出。这里model(img)会返回一个包含分类分数的张量,通常是一个C维度的向量,其中C是类别数。torch.squeeze(output):移除张量中尺寸为 1 的维度。这里squeeze用于去除可能存在的多余维度,使得output变成一个一维的分类分数向量。torch.softmax(output, dim=0):对输出进行 Softmax 操作,将模型的输出转换为概率分布。Softmax 函数会将输出的每个元素压缩到 [0, 1] 范围,并且所有元素的和为 1。torch.argmax(predict):获取概率最大的索引,即预测的类别。torch.argmax返回沿指定维度最大值的索引,在这里它用于找到最大概率对应的类别索引。.item():用于从单元素张量中提取标量值。torch.argmax(predict)返回一个张量,所以使用.item()来获取标量类别值。
6. 加载标签并返回结果:
open("index.json", "r") as f:
data = json.load(f)
print("预测结果为:", data[str(predict_cla)])
return data[str(predict_cla)]
with open("index.json", "r") as f::打开index.json文件,这个文件包含了类别标签的映射关系,通常是一个字典,键是类别索引,值是类别名称。json.load(f):将 JSON 文件内容加载到 Python 字典中。data[str(predict_cla)]:使用预测的类别索引predict_cla获取相应的类别名称。因为 JSON 文件的键通常是字符串类型,所以将predict_cla转换为字符串。print("预测结果为:", data[str(predict_cla)]):打印出预测的类别名称。return data[str(predict_cla)]:返回预测的类别名称。
最终程序实现效果:
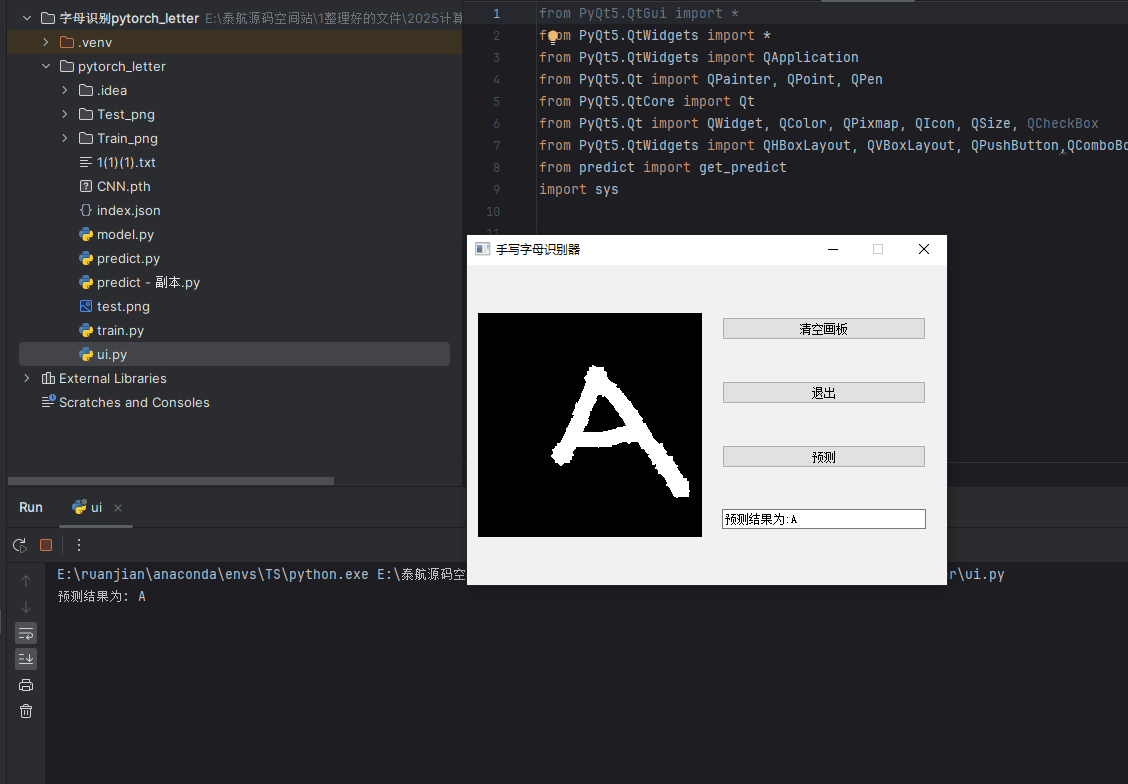
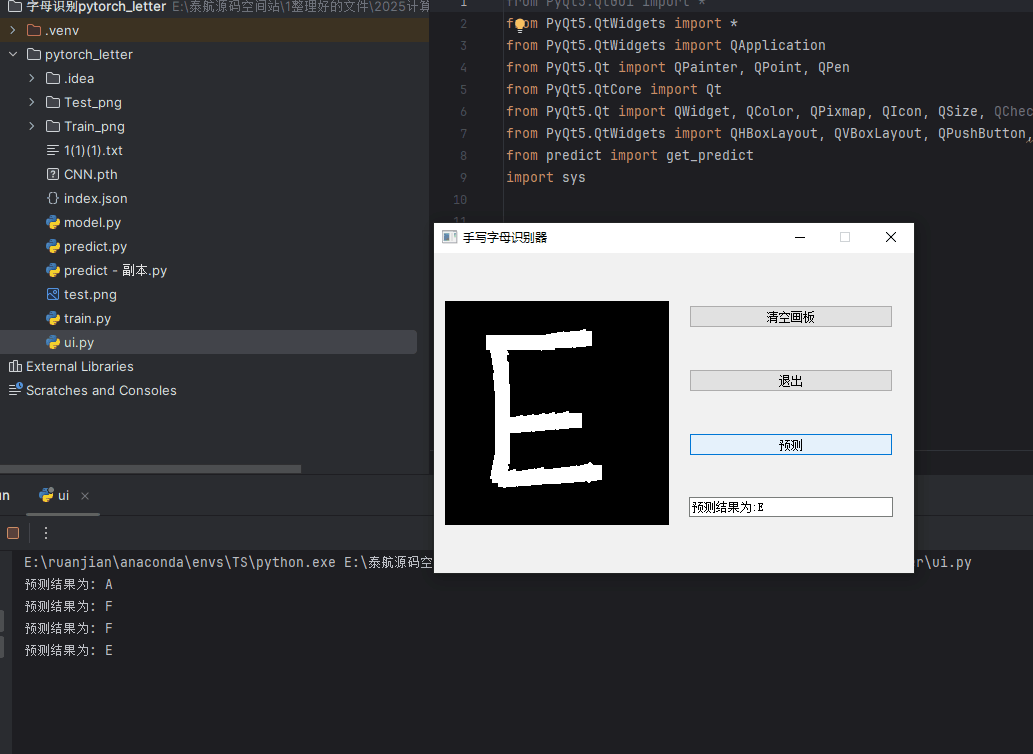


















 1003
1003

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











