







Open Sourcing a Deep Learning Solution for Detecting NSFW Images
By Jay Mahadeokar and Gerry Pesavento
Automatically identifying that an image is not suitable/safe for work (NSFW), including offensive and adult images, is an important problem which researchers have been trying to tackle for decades. Since images and user-generated content dominate the Internet today, filtering NSFW images becomes an essential component of Web and mobile applications. With the evolution of computer vision, improved training data, and deep learning algorithms, computers are now able to automatically classify NSFW image content with greater precision.
Defining NSFW material is subjective and the task of identifying these images is non-trivial. Moreover, what may be objectionable in one context can be suitable in another. For this reason, the model we describe below focuses only on one type of NSFW content: pornographic images. The identification of NSFW sketches, cartoons, text, images of graphic violence, or other types of unsuitable content is not addressed with this model.
To the best of our knowledge, there is no open source model or algorithm for identifying NSFW images. In the spirit of collaboration and with the hope of advancing this endeavor, we are releasing our deep learning model that will allow developers to experiment with a classifier for NSFW detection, and provide feedback to us on ways to improve the classifier.
Our general purpose Caffe deep neural network model (Github code) takes an image as input and outputs a probability (i.e a score between 0-1) which can be used to detect and filter NSFW images. Developers can use this score to filter images below a certain suitable threshold based on a ROC curve for specific use-cases, or use this signal to rank images in search results.

Convolutional Neural Network (CNN) architectures and tradeoffs
In recent years, CNNs have become very successful in image classification problems [1] [5] [6]. Since 2012, new CNN architectures have continuously improved the accuracy of the standard ImageNet classification challenge. Some of the major breakthroughs include AlexNet (2012) [6], GoogLeNet [5], VGG (2013) [2] and Residual Networks (2015) [1]. These networks have different tradeoffs in terms of runtime, memory requirements, and accuracy. The main indicators for runtime and memory requirements are:
- Flops or connections – The number of connections in a neural network determine the number of compute operations during a forward pass, which is proportional to the runtime of the network while classifying an image.
- Parameters -–The number of parameters in a neural network determine the amount of memory needed to load the network.
Ideally we want a network with minimum flops and minimum parameters, which would achieve maximum accuracy.
Training a deep neural network for NSFW classification
We train the models using a dataset of positive (i.e. NSFW) images and negative (i.e. SFW – suitable/safe for work) images. We are not releasing the training images or other details due to the nature of the data, but instead we open source the output model which can be used for classification by a developer.
We use the Caffe deep learning library and CaffeOnSpark; the latter is a powerful open source framework for distributed learning that brings Caffe deep learning to Hadoop and Spark clusters for training models (Big shout out to Yahoo’s CaffeOnSpark team!).
While training, the images were resized to 256x256 pixels, horizontally flipped for data augmentation, and randomly cropped to 224x224 pixels, and were then fed to the network. For training residual networks, we used scale augmentation as described in the ResNet paper [1], to avoid overfitting. We evaluated various architectures to experiment with tradeoffs of runtime vs accuracy.
- MS_CTC [4] – This architecture was proposed in Microsoft’s constrained time cost paper. It improves on top of AlexNet in terms of speed and accuracy maintaining a combination of convolutional and fully-connected layers.
- Squeezenet [3] – This architecture introduces the fire module which contain layers to squeeze and then expand the input data blob. This helps to save the number of parameters keeping the Imagenet accuracy as good as AlexNet, while the memory requirement is only 6MB.
- VGG [2] – This architecture has 13 conv layers and 3 FC layers.
- GoogLeNet [5] – GoogLeNet introduces inception modules and has 20 convolutional layer stages. It also uses hanging loss functions in intermediate layers to tackle the problem of diminishing gradients for deep networks.
- ResNet-50 [1] – ResNets use shortcut connections to solve the problem of diminishing gradients. We used the 50-layer residual network released by the authors.
- ResNet-50-thin – The model was generated using our pynetbuilder tool and replicates the Residual Network paper’s 50-layer network (with half number of filters in each layer). You can find more details on how the model was generated and trained here.
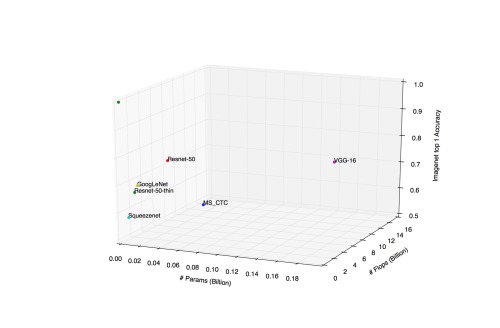
Tradeoffs of different architectures: accuracy vs number of flops vs number of params in network.
The deep models were first pre-trained on the ImageNet 1000 class dataset. For each network, we replace the last layer (FC1000) with a 2-node fully-connected layer. Then we fine-tune the weights on the NSFW dataset. Note that we keep the learning rate multiplier for the last FC layer 5 times the multiplier of other layers, which are being fine-tuned. We also tune the hyper parameters (step size, base learning rate) to optimize the performance.
We observe that the performance of the models on NSFW classification tasks is related to the performance of the pre-trained model on ImageNet classification tasks, so if we have a better pretrained model, it helps in fine-tuned classification tasks. The graph below shows the relative performance on our held-out NSFW evaluation set. Please note that the false positive rate (FPR) at a fixed false negative rate (FNR) shown in the graph is specific to our evaluation dataset, and is shown here for illustrative purposes. To use the models for NSFW filtering, we suggest that you plot the ROC curve using your dataset and pick a suitable threshold.
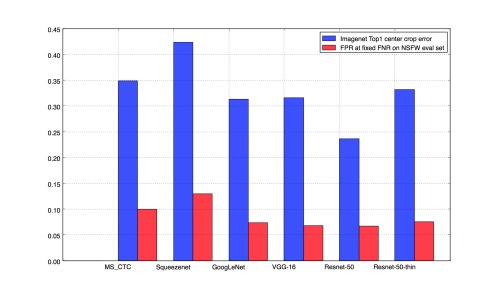
Comparison of performance of models on Imagenet and their counterparts fine-tuned on NSFW dataset.
We are releasing the thin ResNet 50 model, since it provides good tradeoff in terms of accuracy, and the model is lightweight in terms of runtime (takes < 0.5 sec on CPU) and memory (~23 MB). Please refer our git repository for instructions and usage of our model. We encourage developers to try the model for their NSFW filtering use cases. For any questions or feedback about performance of model, we encourage creating a issue and we will respond ASAP.
Results can be improved by fine-tuning the model for your dataset or use case. If you achieve improved performance or you have trained a NSFW model with different architecture, we encourage contributing to the model or sharing the link on our descriptionpage.
Disclaimer: The definition of NSFW is subjective and contextual. This model is a general purpose reference model, which can be used for the preliminary filtering of pornographic images. We do not provide guarantees of accuracy of output, rather we make this available for developers to explore and enhance as an open source project.
We would like to thank Sachin Farfade, Amar Ramesh Kamat, Armin Kappeler, and Shraddha Advani for their contributions in this work.
References:
[1] He, Kaiming, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. “Deep residual learning for image recognition” arXiv preprint arXiv:1512.03385 (2015).
[2] Simonyan, Karen, and Andrew Zisserman. “Very deep convolutional networks for large-scale image recognition.”; arXiv preprint arXiv:1409.1556(2014).
[3] Iandola, Forrest N., Matthew W. Moskewicz, Khalid Ashraf, Song Han, William J. Dally, and Kurt Keutzer. “SqueezeNet: AlexNet-level accuracy with 50x fewer parameters and 1MB model size.”; arXiv preprint arXiv:1602.07360 (2016).
[4] He, Kaiming, and Jian Sun. “Convolutional neural networks at constrained time cost.” In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp. 5353-5360. 2015.
[5] Szegedy, Christian, Wei Liu, Yangqing Jia, Pierre Sermanet,Scott Reed, Dragomir Anguelov, Dumitru Erhan, Vincent Vanhoucke, and Andrew Rabinovich. “Going deeper with convolutions” In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp. 1-9. 2015.
[6] Krizhevsky, Alex, Ilya Sutskever, and Geoffrey E. Hinton. “Imagenet classification with deep convolutional neural networks” In Advances in neural information processing systems, pp. 1097-1105. 2012.















 284
284

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









