





摘要
大型Transformer模型最近已经成为自然语言处理最新进展的核心。然而,这些模型的训练和推理成本已经迅速增长,并变得非常昂贵。在这里,我们的目标是通过寻找一种更有效的变体来降低Transformer的成本。与以前的方法相比,我们的搜索是在一个较低的级别上执行的,在定义Transformer TensorFlow程序的原语上。我们确定了一个名为Primer的架构,它比原始的Transformer和其他自回归语言建模的变量具有更小的训练成本。Primer的改进主要归因于两个简单的修改:将ReLU激活平方和在自注意中的每个 Q Q Q、 K K K和 V V V投影后添加一个深度卷积层。
实验表明,随着计算规模的增长,Primer的增益增加,并在最优模型尺寸下的质量遵循幂律。我们还通过经验验证,Primer可以放入不同的代码库,以显著加快训练,而不需要额外的调整。例如,在500M的参数大小下,Primer在C4自回归语言建模上改进了原始的T5架构,将训练成本降低了4倍。此外,降低的训练成本意味着Primer需要更少的计算来达到一个目标的单发性能。例如,在一个类似于GPT-3 XL的1.9B参数配置中,Primer使用1/3的训练计算来实现与Transformer相同的一次性性能。我们开源了我们的模型和T5中的几个比较,以帮助实现再现性。
零、一些基础
1.Perplexity
是一种用于评估语言模型性能的指标,它表示在给定一个语言模型的情况下,用该模型对一个测试集进行预测的难度。
具体来说,Perplexity是语言模型在测试集上的困惑度(Perplexity),也就是测试集上的交叉熵(Cross-Entropy)指数的反比。一个低的困惑度表明该语言模型能够更好地对测试集进行预测,即该模型更好地拟合了测试集中的数据。
数学上,给定一个测试集 S S S,语言模型的困惑度被定义为: P P ( S ) = 2 − ∑ i = 1 N log p ( x i ) N P P(S)=2^{-\frac{\sum_{i=1}^N \log p\left(x_i\right)}{N}} PP(S)=2−N∑i=1Nlogp(xi) 其中, x i x_i xi 是测试集中的第 i i i个单词, p ( x i ) p(x_i) p(xi) 是模型预测该单词的概率, N N N 是测试集中单词的总数。
Perplexity通常被用来评估语言模型在自然语言处理任务中的性能,例如语音识别、机器翻译、文本生成等。在训练过程中,可以使用Perplexity作为损失函数或优化目标来优化语言模型的性能。
2. Downstream one-shot tasks
(1)Downstream tasks
真正想要解决的任务。如果你想训练一个网络无论是生成任务还是检测任务,你可能会使用一些公开的数据集进行训练,例如coco,imagenet之类的公共数据集进行训练,而这些数据集可能不会很好完成你真正想完成的内容,这就意味着在解决的实际问题的数据集上,要微调这个预训练模型,而这个任务称为下游任务。
(2)One-shot tasks
是指从只有一个或者很少几个训练样本的情况下学习如何正确地分类或识别新样本的任务。
3.Regularized Evolution with hurdles
它的基本思想是在每一代中,从一个种群中随机选择一些候选者,然后用一个评价函数(例如验证损失)来比较它们的表现,并保留最好的一个。同时,每个候选者都有一个年龄属性,年龄越大的候选者越容易被淘汰。这样可以增加搜索空间的多样性和探索性。
hurdles是一种用于提高进化算法效率的技术。它的原理是在每一代中,只有部分候选者需要完成训练,而其他候选者可以根据已经训练过的候选者的表现来判断是否有必要继续训练。这样可以节省计算资源和时间。
4.Pareto最优推理
它的目标是在多目标优化问题中找到一组解,使得每个目标都不能被改进而不损害其他目标。Pareto最优推理可以用于处理不同目标之间的权衡和冲突,以及考虑不确定性和偏好的影响。
一、介绍
在过去的几年中,Transformer被广泛应用于许多NLP进展。随着规模的扩大,Transformer生产了性能越来越好的,但训练大型型号的成本变得令人望而却步。
在本文中,我们旨在降低Transformer语言模型的训练成本。为此,我们提出通过修改Transformer的TensorFlow计算图来寻找更有效的替代方案。给定一个TensorFlow程序的搜索空间,我们使用进化来搜索,在给定固定数量的训练计算下实现尽可能低的验证损失的模型。使用TensorFlow程序作为搜索空间的一个优点是,它更容易找到简单的低级改进来优化Transformer。我们专注于仅限解码器的自回归语言建模(LM),因为它的通用性和成功的。
所发现的模型名为Primer(PRIMitives searched transformER),在自回归语言建模上比常见的Transformer变体有很强的性能改进。我们的实验表明,Primer的好处是(1)使用更小的训练成本实现目标质量,(2)在固定的训练成本下获得更高的质量,(3)使用更小的推理成本实现目标质量。这些优点包括模型尺寸(20M至1.9B参数)、计算规模(10至105加速器小时)、数据集(LM1B、C4、PG19)、硬件平台(TPUv2、TPUv3、TPUv4和V100)、使用默认配置(Tensor2Tensor、Lingvo和T5)的多个Transformer代码库、以及多个型号系列(密集Transformer、稀疏专家混合开关Transformer和Synthesizers)。我们开源这些比较,以帮助我们的结果的重现性。
我们的主要发现是,在控制模型的大小和质量时,Primer比Transformer的计算节省随着训练成本的增加而增加。当使用最佳大小的模型时,这些节省遵循关于质量的幂律。为了证明Primer在一个已建立的训练设置中的节省,我们比较了500M参数Primer和原始的T5架构,使用了Raffel等人使用的应用于自回归语言建模的精确配置。在这种情况下,Primer在相同的训练成本下提高了0.9的 perplexity,并使用少4.2倍的计算达到与T5基线模型的质量匹配。我们在类似于GPT-3 XL 的设置中,通过比较Primer和1.9B参数的Transformer,进一步证明了Primer的节省转移到一次性评估。在那里,使用3倍的训练计算,Primer在预训练perplexity和下游one-shot任务上取得了与Transformer相似的性能。
我们的分析表明,Primer比Transformer的改进主要归因于两个主要的修改:ReLU激活的平方和在自注意中的每个 Q Q Q、 K K K和 V V V投影后增加一个深度卷积层。这两种修改都很简单,可以放到现有的转换器代码库中,以获得自回归语言建模的显著收益。
二、搜索空间和搜索方法
(1)搜索TensorFlow程序
为了构造一个Transformer备选方案的搜索空间,我们使用了来自TensorFlow(TF)的操作。在这个搜索空间中,每个程序都定义了一个自回归语言模型的可堆叠解码器块。给定输入张量
X
∈
R
n
×
d
X \in \mathbb{R}^{n \times d}
X∈Rn×d表示长度为
n
n
n的序列,嵌入长度为
d
d
d的序列,我们的程序返回相同形状的张量。当堆叠时,它们的输出代表了在每个序列位置上的下一个标记预测嵌入。我们的程序只指定模型架构,而没有指定其他内容。换句话说,输入和输出嵌入矩阵本身,以及输入预处理和权值优化都不在我们的程序的范围内。
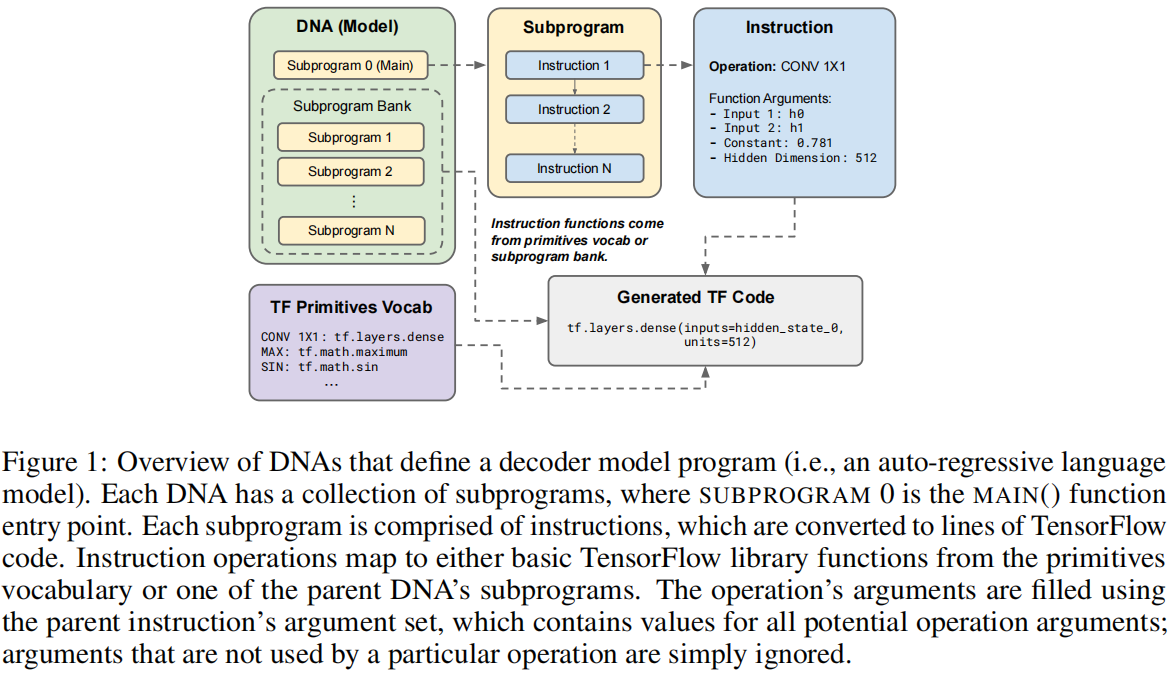
定义解码器模型程序(即自回归语言模型)的DNA的概述。每个DNA都有一个子程序,其中SUBPROGRAM0是MAIN()函数入口点。每个子程序都由指令组成,这些指令被转换为TensorFlow代码的几行。指令操作从原语词汇表或父DNA的一个子程序映射到基本的TensorFlow库函数。操作的参数使用父指令的参数集填充,该参数集包含所有潜在的操作参数的值;没有被特定操作使用的参数将被忽略。
图1显示了程序是如何在我们的搜索空间中构建出来的。每个程序都是由一个进化搜索DNA构建的,这是一个subprograms的索引集合。子程序0是作为执行入口点的MAIN()函数,而其他的子程序是DNA的subprogram
bank的一部分。每个子程序都是一个没有长度约束的索引instructions数组。指令是一种具有一组输入arguments的operation。该操作表示该指令所执行的函数。每个操作都映射到primitives vocabulary中的一个TF函数或DNA子程序库中的另一个子程序。原语词汇表由简单的原语TF函数组成,如ADD、LOG和MATMUL(详见附录A.1)。值得强调的是,像自我注意这样的高级构建块并不是搜索空间中的操作,而是可以从我们的低级操作中构建出来。DNA的子程序库由额外的程序组成,可以作为指令执行。每个子程序只能调用子程序库中具有较高索引的子程序,从而消除了循环的可能性。
每个指令的参数集都包含每个指令操作的潜在参数值列表。参数字段集表示所有操作原语所使用的字段的并集:
-
Input 1:将被用作第一个张量输入的隐藏状态的索引。每个隐藏状态的索引是产生它的指令的索引,子程序的输入状态在索引0和1处。使用此操作的一个操作示例是SIN。
-
Input 2:第二个张量输入的索引。这只用于关于张量输入的二进制操作。使用此操作的操作的示例是ADD。
-
Constant:实值常数。使用这个方法的操作的一个示例是MAX;tf.math.maximum ( x , C ) (x, C) (x,C) for C = 0 C=0 C=0是我们表达Transformer的ReLU激励的方式。
-
Dimension Size:一个表示利用权重矩阵的变换的输出维度大小的整数。使用此操作的一个例子是CONV 1X1,由Transformer的注意力投影和前馈部分使用的密集投影。关于我们如何使用相对维度来调整模型的大小,请参见附录A.2。
-
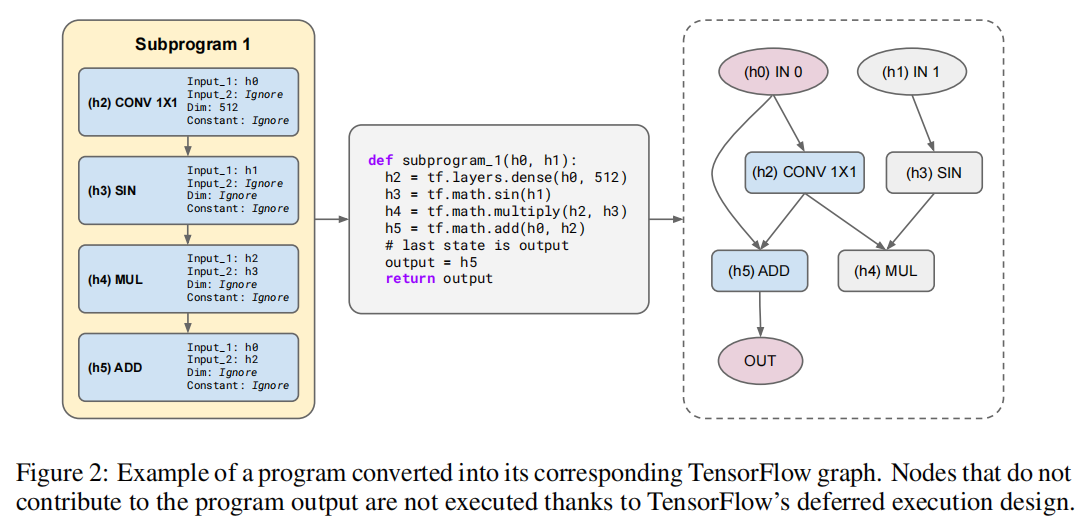
一个程序转换为其相应的TensorFlow图的例子。由于TensorFlow的延迟执行设计,对程序输出没有贡献的节点不会被执行。
(2)进化搜索
我们的进化搜索的目标是在搜索空间中找到训练最有效的架构。为此,我们给每个模型一个固定的训练预算(24 TPUv2小时),并将其适应度定义为其在Tensor2Tensor中的One Billion Words Benchmark (LM1B)上的困惑度(perplexity)。这种方法,我们称为固定训练预算的隐式效率目标(implicit efficiency objective),对比了以前的架构搜索工作,明确地旨在在优化效率时减少训练或推理步长时间。我们的目标是不同的,因为步长时间和样本效率之间的权衡是隐含的。例如,在我们的搜索中,一个将步长时间加倍,但将样本效率加倍的修改是一个很好的修改,因为它最终使体系结构提高了计算效率。事实上,我们发现这些修改是最有益的,调整ReLU和增加深度卷积,增加了训练步长时间。然而,它们大大提高了模型的样本效率,从而大大减少了达到目标质量所需的训练步骤数,从而减少了达到目标质量所需的总计算量。
我们使用的搜索算法是带有障碍的正则化进化(Regularized Evolution)。我们使用第50百分位的通过栏来配置障碍,以便在每个障碍频段投入相等的计算;与使用完整模型评估的相同实验相比,这将搜索成本降低了6.25倍(更多细节见附录A.3)。此外,我们使用7个小时的训练作为一整天的训练的代替,因为一个普通的Transformer只需要7小时的训练就能达到24小时训练困惑度的90%。这进一步降低了搜索成本的3.43倍,总计算减少系数为21.43倍。因此,尽管我们的目标是提高24小时的表现,但平均只需要1.1个小时(更多的搜索细节,包括突变细节和超参数)。我们对∼25K个体进行搜索,并在搜索任务中重新训练前100个个体,以选择最好的一个。
我们的搜索空间不同于以前的搜索空间,后者通常有很大的偏差,因此随机搜索性能良好。 由于我们的搜索空间没有这种偏差,因此由于数值不稳定,我们空间中 78% 的长度等于 Transformer 程序的随机程序不能训练超过五分钟。 由于退化程序的这种开放性和丰富性,有必要使用 Transformer 的副本来初始化搜索群体(输入嵌入大小 d m o d e l = 512 d_{model}= 512 dmodel=512,前馈向上投影大小 d f f = 2048 d_{ff} = 2048 dff=2048,和层数 L = 6 L = 6 L=6)来初始化搜索种群(图3)。要将此初始化应用于我们的搜索空间,我们必须确定如何将 Transformer 程序划分为子程序。 为此,我们按照构成它的机器学习概念进行划分。 例如,我们使用常用的实现分别为自注意力、ReLU 和层范数创建一个子程序(完整列表请参见附录 A.5)。 我们称此方法为概念初始化,因为它通过初始化为搜索引入了偏差,同时保留了进化的搜索空间和突变的开放式操作空间。 这与之前大量通过搜索空间引入偏差的工作形成对比。 尽管一些作品也在微型任务上探索了像我们这样的开放式搜索空间,但我们证明了我们的技术可以扩展到全尺寸深度学习机制(参见第 4 节)。
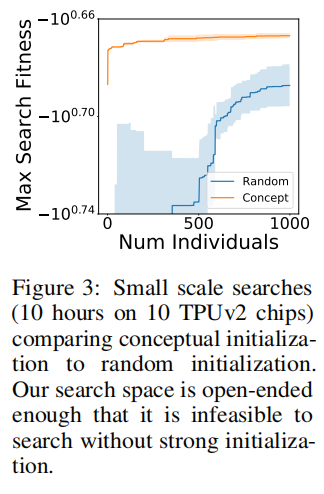
小规模搜索(在10个TPUv2芯片上进行10个小时),比较概念初始化和随机初始化。我们的搜索空间是足够开放的,对于没有强初始化的搜索是不可行的。
三、Primer
(1)Primer
我们将已发现的模型命名为Primer,它代表PRIMitives searched transformER(完整的程序见附录图23)。当在搜索任务上重新训练时,Primer显示出显著的改进,需要不到一半的Transformer 计算便能达到相同的质量(图6)。在第4节中,我们还展示了当Primer转移到其他代码库、训练机制、数据集和下游一次性任务时,也获得了同样大的收益。
(2)Primer-EZ
这项工作的核心动机是开发语言建模从业者可以轻松采用的简单技术。 为实现这一点,我们在两个 Max Search Fitness 代码库(T5 和 Tensor2Tensor)上执行消融测试,并确定哪些 Primer 修改通常有用(附录图 26)。 产生最强大改进的两个是前馈 ReLU 的平方和将深度卷积添加到注意力多头投影(图 4)。 我们将仅具有这两个简单修改的 Transformer 称为 Primer-EZ; 对于有兴趣使用 Primer 的语言建模从业者,这是我们推荐的起点。 我们现在解释这些修改,然后衡量它们的实证有效性。
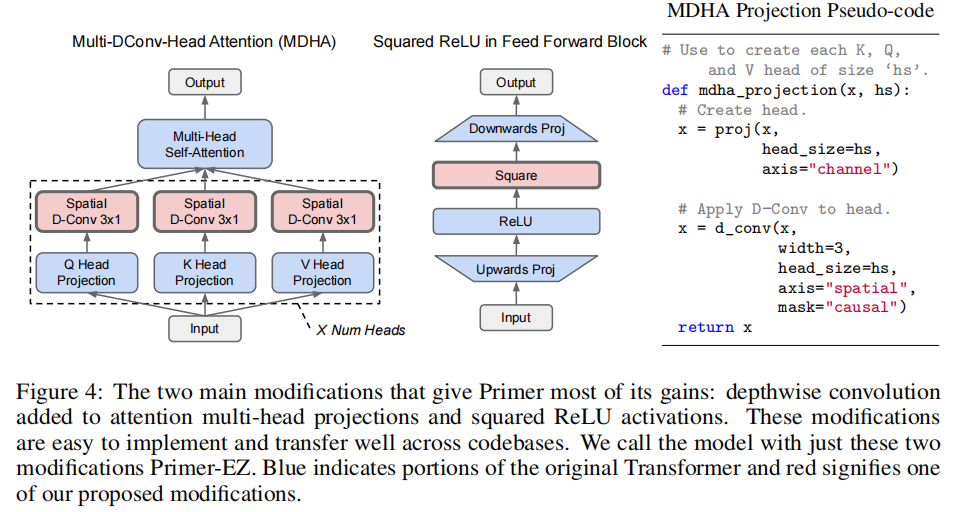
两个主要的修改给了Primer大部分的收益:深度卷积增加了注意多头投影和平方ReLU激活。这些修改很容易实现,并可以在代码库之间很好地传输。我们把只有这两个修改的模型称为Primer-EZ。蓝色表示原始Transformer 的部分,红色表示我们建议的修改之一。
(3)Squared ReLU
最有效的修改是从Transformer的前馈块中的一个ReLU激活到一个平方的ReLU激活的改进。在神经网络激活函数中研究了不同程度的校正多项式,但并不常用;据我们所知,这是第一次这种校正多项式激活被证明在Transformer中是有用的。有趣的是,高阶多项式的有效性也可以在其他有效的 Transformer 非线性中观察到,例如像 ReGLU (
y
=
U
x
⊙
max
(
V
x
,
0
)
y=U x \odot \max (V x, 0)
y=Ux⊙max(Vx,0)其中
⊙
\odot
⊙ 是按元素点乘)这样的 GLU 变体,和像近似 GELU(
y
=
0.5
x
(
1
+
tanh
(
2
/
π
(
x
+
0.044715
x
3
)
)
)
y=0.5 x\left(1+\tanh \left(\sqrt{2 / \pi}\left(x+0.044715 x^3\right)\right)\right)
y=0.5x(1+tanh(2/π(x+0.044715x3)))) 这样的逐点激活。然而,与最常用的激活函数: ReLU、GELU和Swish相比,平方的ReLU作为
x
→
∞
x→∞
x→∞具有截然不同的渐近性(图5左侧)。Squared ReLU 确实与 ReGLU 有很大的重叠,实际上当 ReGLU 的
U
U
U 和
V
V
V 权重矩阵相同并且 ReLU 平方之前紧接一个权重矩阵
U
U
U 的线性变换时是等价的。这使我们相信平方 ReLU 获得了以下好处 这些 GLU 变体更简单,没有额外的参数,并且提供更好的质量(图 5 右侧)。

左:平方ReLU与其他常见的激活函数相比有明显不同的渐近性。中:平方ReLU与GLU变体有显著的重叠,这些变体使用类似ReLU的渐近性激活,如ReGLU和SwiGLU。我们的实验表明,在转换语言模型中,平方的ReLU优于这些GLU变体。右图:在C4自回归LM上训练525K步的Transformer的不同非线性的比较。
(4)Multi-DConv-Head Attention (MDHA)
另一个有效的修改是在自注意力中查询 Q Q Q、键 $K $和值 V V V 的每个多头投影之后添加 3 × 1 3×1 3×1 深度卷积。 这些深度卷积是在每个密集投影输出的空间维度上执行的。 有趣的是,这种逐点卷积和深度卷积的顺序与典型的可分离卷积相反,我们在附录 A.6 中发现这种方法不太有效。 我们还发现,更宽的深度卷积和标准卷积不仅不会提高性能,而且在某些情况下还会损害性能。 尽管之前已将深度卷积用于Transformer,但据我们所知,尚未在每次密集头部投影后使用它们。 MDHA 类似于 Convolutional Attention,后者使用可分离卷积而不是深度卷积,并且不像我们那样对每个注意力头应用卷积操作。
(5)Other Modifications
其他Primer的修改效果较差。每个修改的图表可以在附录中找到A.5和消融术的研究结果见附录A.7.我们在此简要描述这些修改及其用途:
-
Shared Q and K Depthwise Representation Primer为 Q Q Q和 K K K共享一些权重矩阵。 K K K是使用前面描述的MDHA投影和 Q = K W Q=KW Q=KW可学习权重矩阵 W ∈ R d × d W∈\mathbb{R}^{d×d} W∈Rd×d创建的。我们发现,这通常会影响到工作表现。
-
Pre and Post Normalization Transformers 的标准做法是在自注意力和前馈转换之前进行规范化。 Primer 在自注意力之前使用归一化,但在前馈变换之后应用第二次归一化。 我们发现这在某些但不是所有情况下都有帮助。
-
Custom Normalization Primer使用了一个修改版本的层标准化,它使用了 x ( x − µ ) x(x−µ) x(x−µ)而不是 ( x − µ ) 2 (x−µ)^2 (x−µ)2,但我们发现这并不总是有效的。
-
12X Bottleneck Projection 所发现的模型使用了更小的 d m o d e l d_{model} dmodel大小384(与基线的512相比)和更大的 d f f d_{ff} dff大小4608(与基线的2048相比)。我们发现,在较小的尺寸(∼35M参数)下,这种更大的投影显著改善了结果,但对于较大的模型效果较差,正如之前提到的。因此,我们在引用Primer或Primer-EZ时,不包括此修改。
-
Post-Softmax Spatial Gating 发现的模型在注意力 softmax 之后有一组每通道可学习标量,这提高了固定长度序列的困惑度。 然而,这些标量不能应用于可变序列长度,因此我们不在我们的实验中将此修改包含在 Primer 中。
-
Extraneous Modifications 有一些额外的修改在已发现的架构中没有产生任何有意义的差异。例如,隐藏状态被乘以-1.12。为了验证这些修改既没有帮助也没有影响质量,我们在正文中的讨论中排除了它们,并且在使用Primer进行实验时不包括它们。这些无关的修改仍然可以在附录A.5中找到。
四、结果
在我们的实验中,我们比较了Primer与三种Transformer变体:
- Vanilla Transformer: 原始Transformer与ReLU激活和层归一化外的剩余路径。
- Transformer+GELU: 一种常用的Vanilla Transformer的变体,使用GELU7近似激活函数。
- Transformer++: 一个具有以下增强功能的Transformer: RMS标准化、Swish激活和前馈反向瓶颈(SwiGLU)中的一个GLU乘法分支。这些修改是基准的,并显示在T5 中是有效的。
我们对三个不同的代码基准进行了比较:Tensor2Tensor(T2T)、T5 和Lingvo 。Tensor2Tensor是我们用于搜索的代码基准,所以我们的大部分并排操作都是在T5和Lingvo中完成的,以证明可转移性。在所有情况下,我们对每个代码库使用默认的Transformer超参数,并禁用正则化。有关更多超参数的详细信息,请参见附录A.8。
在下面的章节中,我们将在关于自回归语言建模的四个主要实验中展示我们的结果。首先,我们将展示Primer在搜索任务上优于基线模型。接下来,我们将展示 Primer 相对于 Transformers 的计算节省与模型质量之间的关系在最佳模型大小下遵循幂律。 这些节省也会跨数据集和代码库转移。 然后,我们将研究 Primer 在已建立的训练机制中的收益,并证明它可以使用完整的计算 T5 训练在 500M 参数大小下实现 4.2 倍的计算节省。 最后,我们将证明这些收益转移到 GPT-3 建立的预训练和一次性下游任务设置。
1.搜索任务比较
我们首先分析了Primer在搜索任务上的表现:序列长度为64的LM1B语言建模,∼35M模型参数,4096个标记批次和24小时的训练。我们与Tensor2Tensor(T2T)和T5 以及TPUv2s和V100gpu上的基线模型进行了比较。我们根据它达到Vanilla Transformer的最终质量的速度来对每个模型的性能进行评级,我们将称之为它的加速因素。图6显示,在所有情况下,Primer提供了比Transformer高出1.7倍或更多的加速系数。图6还显示了Primer和Primer-EZ都可以推广到其他硬件平台和代码库。

使用35M参数模型比较LM1B搜索任务。“加速因子”是指每个模型要达到与训练24小时的 vanilla Transformer质量相同所需的计算分数。Primer和Primer-EZ在所有情况下都能加速超过1.7倍。请注意,结果将在代码库和不同的硬件之间进行传输。
左:在扫描最优模型大小时,Transformer语言模型质量与训练计算之间的关系大致服从幂律。右:比较这些幂律线的变化的Transformer修改,拟合平滑的MSE损失。模型线是平行的,这意味着使用优越的建模计算节省也可以作为质量的幂律。垂直虚线之间的间距表示2倍的计算差异。请注意,这两个图中的x轴和y轴都是用对数表示的。
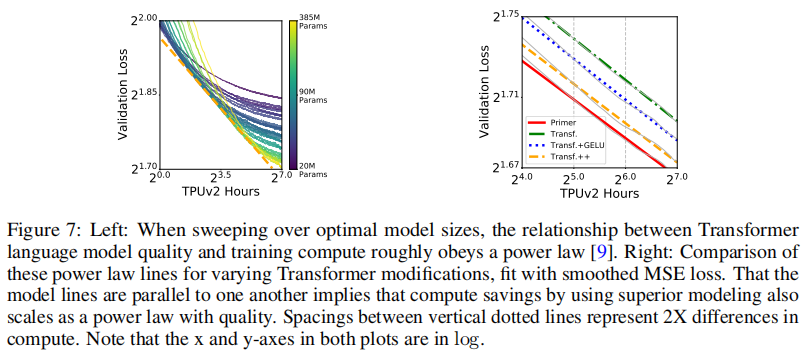
接下来,我们研究了Primer的尺度规则。在这里,我们通过使用每种排列 L ∈ { 6 , 9 , 12 } L \in \{ 6,9,12 \} L∈{6,9,12}层, d m o d e l ∈ { 384 , 512 , 1024 } d_{model} \in \{ 384,512,1024 \} dmodel∈{384,512,1024}初始嵌入尺寸,和 p ∈ { 4 , 8 , 12 } p \in \{ 4,8,12 \} p∈{4,8,12}前向前馈投影比,训练每个模型,将Primer与许多大小的基线进行比较,创造一个参数,范围从23M到385M。结果如图7所示,证实了先前的主张,即在最优参数大小下,计算和语言模型质量之间的关系大致遵循幂。也就是说,在验证损失 l l l和训练计算 c c c之间的关系,遵循关系 l = a c − k l=ac^{-k} l=ac−k,其中 a a a和 k k k为经验常数。这是用双log空间中的一条直线表示的(图7): log l = − k log c + log a \log l=-k \log c +\log a logl=−klogc+loga。然而,这些行对于每个体系结构都不相同。这些线大致平行,但上下移动。在附录A.9我们展示了那个,给定一个 log b k \log b^k logbk的垂直空间,像这样的平行线表示计算节省, s s s,用于高级建模也遵循形式 l = a 1 ( 1 − 1 / b ) k s − k l=a_1(1-1/b)^ks^{-k} l=a1(1−1/b)ks−k的幂律。这背后的直觉是, b b b是所有 l l l的一个常数的计算约简因子,因此一个相对于 l l l的训练计算的幂律投资也会导致一个相对于 l l l的幂律节省(见附录A.9)。
Primer也有改进推理的能力,尽管我们的搜索集中在训练计算上。图8显示了当使用前馈传递时间作为推理的代理时,质量和推理的Pareto前沿比较。我们使用前向传递时间作为推理的代理,因为有多种方法来解码一个语言模型,每种方法都有不同的计算成本。我们可以更深入地分析Primer在不同解码方法、服务平台、数据集等方面的推理性能,但这超出了本工作的范围。
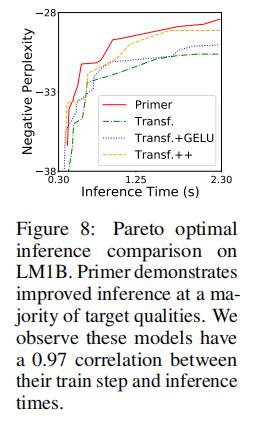
在LM1B上的Pareto最优推理比较。Primer演示了对大多数目标质量的改进推理。我们观察到这些模型在它们的训练步长和推理时间之间有0.97的相关性。
2.Primer可转移到其他代码库、数据集和模型类型
我们现在研究Primer在另一个代码库T5中转移到更大的数据集PG19和C4的能力。我们另外扩展到一个更高的计算机制,以前的研究作为大规模训练的代理;批次增加到65K标记,序列长度增长为512,每个解码器是110M参数(
d
m
o
d
e
l
=
768
d_{model}=768
dmodel=768,
d
f
f
=
3072
d_{ff}=3072
dff=3072,
L
=
12
L=12
L=12),每个模型在4个TPUv3芯片上训练到∼525K步骤。我们还继续训练每个模型到1M步,以研究更大的计算预算对Primer节省的影响。结果如图9所示,Primer模型在较大的数据、较高的计算状态中与在较小的LM1B状态中一样强。与普通基线相比,Primer和Primer-EZ在PG19和C4训练结束时的效率至少高出1.8倍。
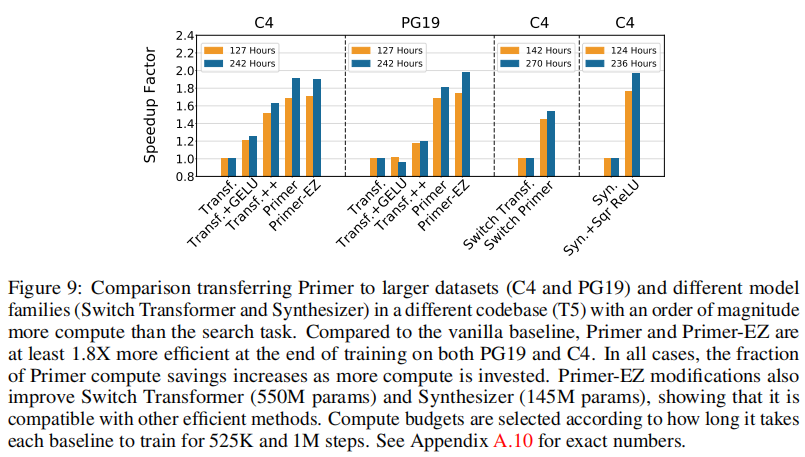
比较将Primer转移到更大的数据集,C4和PG19)和不同的模型族(不同码库(T5)中的开关Transformer和合成器),计算量比搜索任务多一个数量级。与普通基线相比,Primer和Primer-EZ在PG19和C4训练结束时的效率至少高出1.8倍。在所有情况下,随着更多计算量的投入,Primer计算节省的比例都会增加。Primer-EZ修改还改进了开关Transformer(550M参数)和合成器(145M参数),表明它与其他有效的方法兼容。计算预算是根据每个基线训练525K和100万步所需的时间来选择的。具体数字详见附录A.10。
图9还显示了Primer的修改与其他高效的模型族兼容,如大型稀疏混合专家,如开关Transformer和高效的Transformer近似,如合成器。对于这些实验,我们使用了Narang等人提供的T5实现。增加深度卷积和平方的ReLU技术将开关Transformer的计算成本降低了1.5倍;这意味着在控制计算时,困惑度提高了0.6(见附录A.10)。在合成器中添加平方ReLUs可以降低训练成本2.0倍,并在完全训练时提高困惑度0.7倍。
3.大规模T5自回归语言模型训练
在大规模计算配置中,Primer计算节省率甚至更高。为了证明Primer在已建立的高计算训练设置中的节省,我们扩展到完整的T5计算机制,复制Raffel等人的。这与前一节中的C4配置相同,但使用了批∼1M令牌、64 TPUv3芯片和537M参数(
d
m
o
d
e
l
=
1024
d_{model}=1024
dmodel=1024,
d
f
f
=
8192
d_{ff}=8192
dff=8192,
L
=
24
L=24
L=24)。Primer的计算效率比原来的T5模型高4.2倍,比我们加强的增强Transformer++基线高2倍(表1)。
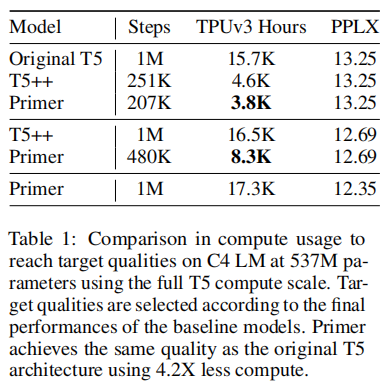
这里节省更好的原因是,在固定的规模下,更多的计算投资产生更高的Primer计算节省。图10显示了随着模型训练时间的更长,计算Primer的比例如何缩小;这是由于控制和变量困惑训练曲线的渐近性质。这与第A.6节中描述的幂次法节约不同。在那里,我们为每个计算预算使用最优的参数数,因此计算节省系数b保持不变。对于固定的模型大小,计算节省因子随着计算量的增加而增加,这意味着计算节省可以超过幂律估计。注意,这意味着可以通过投入的比基线模型更多的计算来“模拟”这里给出的比较。正是由于这个原因,我们使用了Raffel等人的精确副本。的训练规则:来演示Primer在已经发布的培训配置中的节省。
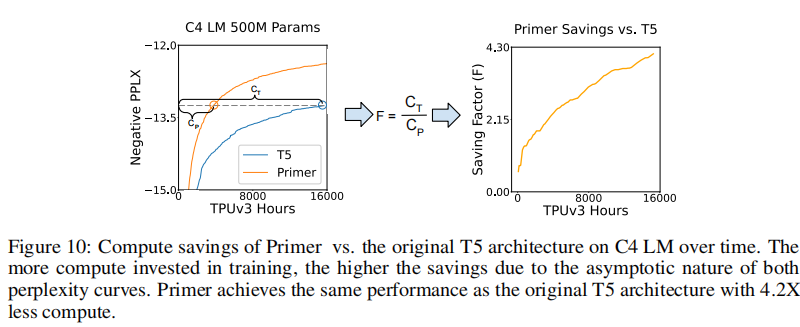
随着时间的推移,计算C4 LM上Primer与原始T5架构的节省。在训练上投入的计算量越多,由于这两个困惑曲线的渐近性质,节省的钱就越高。Primer实现了与原来的T5架构相同的性能,计算少4.2倍的时间。
4.Primer对下游One-Shot任务的可转移性
在我们最后的比较中,我们证明了Primer的改进也适用于训练前和一次性的下游任务转移机制。最近语言建模的趋势是在大数据集上训练大型模型,这被称为“预训练”。然后,这些模型被转移到看不见的数据集和任务中,并且,在不进行大量或任何额外训练的情况下,展示了在那些“下游”任务上表现良好的能力。在我们这里研究的仅解码器自回归语言建模配置中,最令人印象深刻的是GPT-3 取得了令人印象深刻的结果,它表明,大型语言模型可以在看不见的任务上表现出强大的性能,只给出一个例子——称为“一次性”学习。在本节中,我们演示了Primer的训练计算节省超出了达到目标训练前的困惑,并确实转移到下游的一次性任务性能。
为此,我们复制了GPT-3预训练和一次性评估设置。这种复制与GPT-3中使用的复制并不完全相同,因为GPT-3不是开源的。因此,这些实验并不意味着要直接与GPT-3进行比较,因为存在配置差异。相反,这些实验被用作Transformer和Primer结构的控制比较。我们使用一个专有的预训练数据集在Lingvo代码库中进行这些实验。下游任务以Brown等人描述的一次性方式配置,通过每个任务的输入向每个模型输入单个前缀示例。我们比较了(1)基线1.9B参数Transformer(
d
m
o
d
e
l
=
2048
d_{model}=2048
dmodel=2048,
d
f
f
=
12288
d_{ff}=12288
dff=12288,
L
=
24
L=24
L=24)与GELU激活,这意味着接近GPT-3 XL架构,以及(2)没有共享
Q
Q
Q、
K
K
K表示的完整Primer,根据附录A.7,这只会影响性能。每个模型都使用一批∼2M标签进行训练,使用512个TPUv4芯片进行∼140小时(∼71.8K总加速器小时或∼1M列车步长)。我们再次使用T5训练超面积表,没有任何额外的调优。

图11显示,Primer在减少3倍的计算量的情况下,实现了与Transformer+GELU相同的训练前困惑和一次性下游性能。附录中的表6给出了27个被评估的下游任务的确切性能数字。尽管入门器使用的计算量少了3倍,但在5个任务上优于转换器+GELU,在1个任务上表现更差,在其余21个任务上表现相同。同样的表显示,当给定等效计算时,Primer在15个任务上优于Transformer+GELU,在2个任务上表现更差,在其余10个任务上表现相等。这一结果表明,Primer不仅可以提高语言建模的困惑度,而且还可以转移到下游的NLP任务中。
五、结论
(1)限制
这项研究也有其局限性。首先,尽管我们的比较规模相当大,但它们仍然比最先进的模型,如全面的GPT-3要小几个数量级。其次,我们主要关注仅限解码器的模型,而基于编码器的序列模型仍然是广泛使用的。在附录A.12中,我们在T5中进行了编码-解码器掩码语言建模比较,但没有对结果进行显著的深入的研究。主要的发现是,尽管Primer修饰改进了Vanilla Transformer,但它们的性能只有与Transformer++一样好。这一结果表明,对于仅针对解码器的自回归语言模型很有效的架构修改,对于基于编码器的掩码语言模型可能不一定那么有效。开发更好的编码器是我们未来研究的一个课题。
(2)一些建议和未来的发展方向
我们推荐采用Primer和Primer-EZ来进行自回归语言建模,因为它们具有强大的性能、简单性和对超参数和代码库变化的鲁棒性。为了证明它们的潜力,我们只是将它们放到已建立的代码库中,并且没有任何更改,表明它们可以显著提高性能。此外,在实践中,额外的调优可以进一步提高其性能。我们也希望我们的工作能鼓励人们对高效Transformer的开发进行更多的研究。例如,这项研究的一个重要发现是,激活函数的微小变化可以产生更有效的训练。为了降低Transformer的成本,更多的开发投资可能是未来探索的一个有前途的领域。
六、附录
A 附录
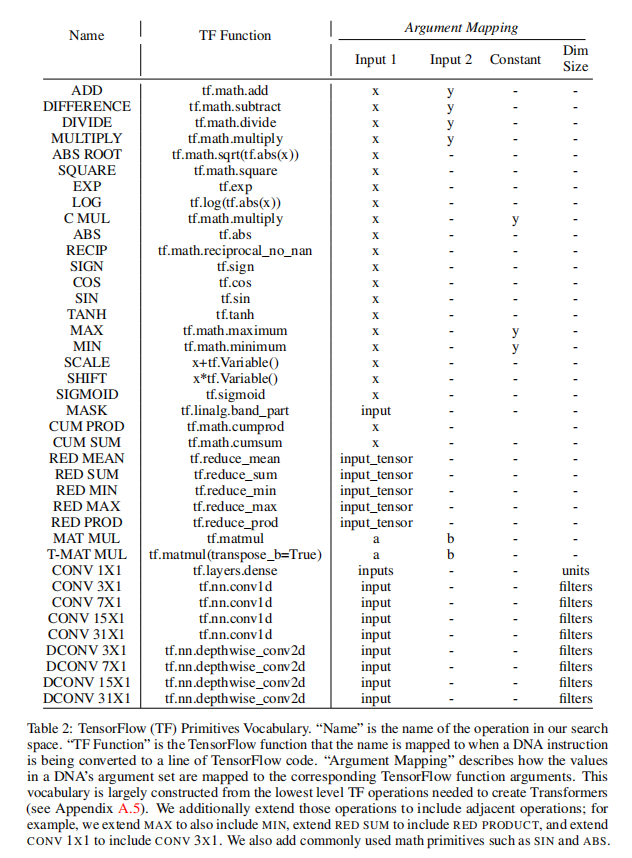
A.1 TensorFlow原语词汇
A.2 构造TensorFlow流图
相对尺寸
价值银行
因果掩蔽
分支
解决维度不匹配
A.3 Halving Hurdles
A.4 进化搜索细节
突变
A.5 Transformer和Primer程序比较
A.6 精确LM1B数字
A.7 消融和插入研究
A.8 完整的训练细节
A.9 幂律计算储蓄推导
A.10 中型实验的精确T5数字
A.11 单独One-Shot任务的表现
A.12 遮盖的语言模型
A.13 碳排放估计
A.14 与进化型Transformer的比较
A.15 实际讨论
七、主要参考文献
八、代码解析
【待补充】
相关领域
【待补充】














 525
525











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









