







 本文介绍了神经稀疏体素场(NSVF),一种结合神经网络与稀疏体素结构的新方法,用于快速、高质量的自由视角渲染。NSVF解决了现有方法中的模糊渲染和低效问题,通过体素有界隐式场和可微分的光线行进操作,实现了从2D图像学习3D场景表示。与最先进的方法相比,NSVF在推理时速度快10倍以上,同时提供更清晰的渲染结果。该方法适用于多场景学习、动态场景渲染和场景编辑。
本文介绍了神经稀疏体素场(NSVF),一种结合神经网络与稀疏体素结构的新方法,用于快速、高质量的自由视角渲染。NSVF解决了现有方法中的模糊渲染和低效问题,通过体素有界隐式场和可微分的光线行进操作,实现了从2D图像学习3D场景表示。与最先进的方法相比,NSVF在推理时速度快10倍以上,同时提供更清晰的渲染结果。该方法适用于多场景学习、动态场景渲染和场景编辑。
论文地址:https://proceedings.neurips.cc/paper/2020/file/b4b758962f17808746e9bb832a6fa4b8-Paper.pdf
Github:https://github.com/facebookresearch/NSVF
摘要
使用经典计算机图形技术对真实世界场景进行逼真的自由视角渲染具有挑战性,因为它需要捕获详细外观和几何模型的困难步骤。最近的研究通过学习在没有 3D 监督的情况下隐式编码几何和外观的场景表示,证明了有希望的结果。然而,现有方法在实践中经常表现出由于网络容量有限或难以找到相机光线与场景几何体的准确交点而导致的模糊渲染。从这些表示中合成高分辨率图像通常需要耗时的光线行进。在这项工作中,我们引入了神经稀疏体素场 (NSVF),这是一种用于快速和高质量自由视角渲染的新神经场景表示。NSVF 定义了一组以稀疏体素八叉树组织的体素有界隐式场,以对每个单元格中的局部属性进行建模。我们仅从一组构成的 RGB 图像中,通过可微分的光线行进操作逐步学习潜在的体素结构。使用稀疏体素八叉树结构,可以通过跳过不包含相关场景内容的体素来加速渲染新视图。我们的方法在推理时通常比最先进的方法(即 NeRF(Mildenhall 等人,2020 年))快 10 倍以上,同时获得更高质量的结果。此外,通过利用显式稀疏体素表示,我们的方法可以轻松应用于场景编辑和场景合成。我们还展示了几个具有挑战性的任务,包括多场景学习、移动人的自由视角渲染和大规模场景渲染。
介绍
计算机图形学中的逼真渲染具有广泛的应用,包括混合现实、视觉效果、可视化,甚至计算机视觉和机器人导航中的训练数据生成。从任意角度逼真地渲染真实世界场景是一项巨大的挑战,因为通常无法像在高预算的视觉效果制作中那样获得高质量的场景几何图形和材料模型。因此,研究人员开发了基于图像的渲染 (IBR) 方法,将基于视觉的场景几何建模与基于图像的视图插值相结合(Shum 和 Kang,2000;Zhang 和 Chen,2004;Szeliski,2010)。尽管取得了重大进展,但 IBR 方法仍然具有次优渲染质量和对结果的有限控制,并且通常是特定于场景类型的。为了克服这些限制,最近的工作采用了深度神经网络来隐式地学习场景表示,从带有或不带有粗几何的 2D 观察中封装几何和外观。这种神经表示通常与 3D 几何模型相结合,例如体素网格(Yan 等人,2016 年;Sitzmann 等人,2019a;Lombardi 等人,2019 年)、纹理网格(Thies 等人,2019 年;Kim 等人al., 2018; Liu et al., 2019a, 2020)、多平面图像(Zhou et al., 2018; Flynn et al., 2019; Mildenhall et al., 2019)、点云(Meshry et al., 2019;Aliev 等人,2019 年)和隐函数(Sitzmann 等人,2019b;Mildenhall 等人,2020 年)。
与大多数显式几何表示不同,神经隐式函数是平滑、连续的,并且理论上可以实现高空间分辨率。然而,现有方法在实践中经常表现出由于网络容量有限或难以找到相机光线与场景几何体的准确交点而导致的模糊渲染。从这些表示中合成高分辨率图像通常需要耗时的光线行进。此外,使用这些神经表示编辑或重新合成 3D 场景模型并不简单。
在本文中,我们提出了神经稀疏体素场 (NSVF),这是一种用于快速和高质量自由视点渲染的新隐式表示。NSVF 不是使用单个隐函数对整个空间进行建模,而是由一组以稀疏体素八叉树组织的体素有界隐式字段组成。具体来说,我们在体素的每个顶点分配一个体素嵌入,并通过在相应体素的八个顶点处聚合体素嵌入来获得体素内部查询点的表示。这进一步通过多层感知器网络 (MLP) 来预测该查询点的几何形状和外观。我们的方法可以通过可微分的光线行进操作从场景的一组 2D 图像中逐步学习 NSVF,从粗到细。在训练期间,不包含场景信息的稀疏体素将被修剪,以允许网络专注于具有场景内容的体积区域的隐函数学习。使用稀疏体素,可以通过跳过没有场景内容的空体素来大大加快推理时的渲染速度。
我们的方法在推理时通常比最先进的方法(即 NeRF(Mildenhall 等人,2020 年))快 10 倍以上,同时获得更高质量的结果。我们在各种具有挑战性的任务上广泛评估了我们的方法,包括多对象学习、动态和室内场景的自由视点渲染。我们的方法可用于编辑和合成场景。总而言之,我们的技术贡献是:
l我们提出了由一组体素有界隐式场组成的 NSVF,其中对于每个体素,体素嵌入被学习以编码局部属性以实现高质量渲染;
lNSVF 利用稀疏体素结构实现高效渲染;
l我们引入了一种渐进式训练策略,该策略以端到端的方式从一组有姿势的 2D 图像中通过可微分的光线行进操作有效地学习底层稀疏体素结构。
背景
现有的神经场景表示和神经渲染方法通常旨在学习将空间位置映射到隐式描述场景的局部几何形状和外观的特征表示的函数,其中可以使用计算机图形学中的渲染技术合成该场景的新视角。为此,渲染过程以可微分的方式制定,以便可以通过最小化渲染和场景的 2D 图像之间的差异来训练对场景表示进行编码的神经网络。在本节中,我们将描述使用隐式场的现有表示和渲染方法及其局限性。
Neural Rendering with Implicit Fields 隐式场的神经渲染
让我们将场景表示为隐函数 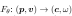 ,其中 θ 是底层神经网络的参数。该函数描述了场景颜色 c 及其在空间位置 p 和光线方向 v 处的概率密度 ω。给定位置
,其中 θ 是底层神经网络的参数。该函数描述了场景颜色 c 及其在空间位置 p 和光线方向 v 处的概率密度 ω。给定位置  处的针孔相机,我们通过从相机拍摄光线来把大小为 H × W 的二维图像渲染成 3D 场景。因此,我们评估体积渲染积分以计算相机光线的颜色
处的针孔相机,我们通过从相机拍摄光线来把大小为 H × W 的二维图像渲染成 3D 场景。因此,我们评估体积渲染积分以计算相机光线的颜色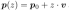 为:
为:

请注意,为了鼓励场景表示是多视角一致的,ω 被限制为仅 p(z) 的函数,而 c 将 p(z) 和 v 作为输入来建模与视角相关的颜色。评估该积分的不同渲染策略是可行的。
Surface Rendering。基于表面的方法 (Sitzmann et al., 2019b; Liu et al., 2019b; Niemeyer et al., 2019) 假设 ω(p(z)) 是狄拉克函数 δ(p(z)) p(z∗ )) 其中 p(z∗) 是相机光线与场景几何的交点。
Volume Rendering.(Lombardi 等人,2019 年;Mildenhall 等人,2020 年)通过在每条相机光线上密集采样点并将采样点的颜色和密度累积到 2D 图像中来估计方程(1)中的积分 C(p0, v)。例如,最先进的方法 NeRF(Mildenhall 等人,2020 年)估计 C(p0, v) 为:
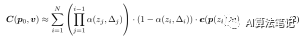
其中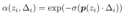 ,然后
,然后
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 343
343

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











