






 本文介绍了Python中使用pandas处理数据重复和缺失值的方法。针对重复数据,利用duplicated和drop_duplicates进行检查与去重;对于缺失值,根据其产生原因和比例选择均值、中位数或众数填补,或创建指示变量参与建模。还展示了使用lambda函数检查缺失值占比及fillna方法的填充策略。
本文介绍了Python中使用pandas处理数据重复和缺失值的方法。针对重复数据,利用duplicated和drop_duplicates进行检查与去重;对于缺失值,根据其产生原因和比例选择均值、中位数或众数填补,或创建指示变量参与建模。还展示了使用lambda函数检查缺失值占比及fillna方法的填充策略。
学习原处链接:https://blog.csdn.net/zw0Pi8G5C1x/article/details/84610050/
https://www.jianshu.com/p/a93fe1423bc5
1.数据重复
panadas提供查看、处理重复数据的方法duplicated和drop_duplicates。

duplicated可以查看重复的数据。

drop_duplicates方法可以去重。

2.缺失数据处理
缺失值一般有NA表示,在处理缺失值时要遵循一定的原则。
首先应弄清缺失值产生的原因,再通过经验进行填补。
- 当缺失值少于20%时,连续变量可以使用均值或中位数进行填补;分类变量不需要填补、单一类即可,或者也可用众数填补分类变量。
- 当缺失值多于80%时,每个有缺失值的变量生成一个指示哑变量,参与后续的建模,不适用原始变量。
pandas提供fillna方法用于替换缺失值数据:
(1)查看缺失值情况
使用lambda函数。
在介绍之前,先来看一下lambda的定义。
lambda函数:lambda作为一个表达式,定义了一个匿名函数。例如:
def g(x):
return x+1
可以使用lambda简化成:
lambda x:x+1lambda函数冒号之前为变量,如果为多变量,可以用逗号隔开,例如:lambda x,y,z:x+y+z
回到正题,想要了解数据缺失值的情况,可以使用lambda创造一个函数,来查看缺失值。
来看个例子:
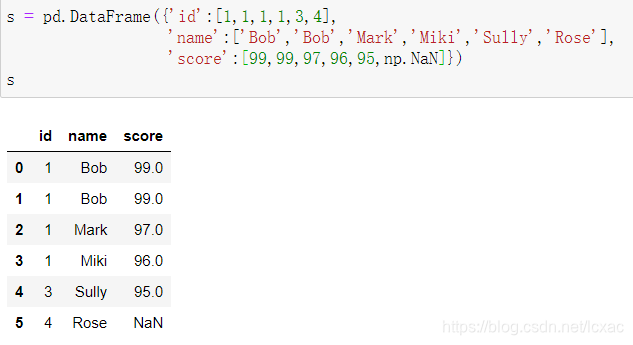

col.isnull():将每列中是NaN的值的数量;
col.size:当前列总共有多行元素。
所以,lambda定义了一个 一列中值为NaN在每一列中的占比。
(2)以指定的值填补
使用fillna对缺失值进行填补。
a.均值填补(使用mean()函数进行均值的计算)
s.score.fillna(s.score.mean())b.分位数填补(使用median()函数进行分位数的计算)
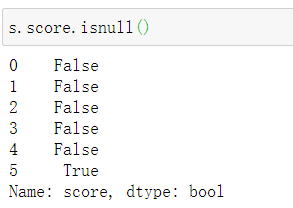
s.score.fillna(s.score.median())(3)缺失值指示变量
a.调用isnull()函数产生缺失值指示变量(True,False)
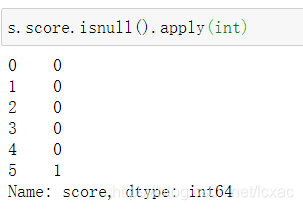
b. 如果想转换成0,1型指示变量,可以用apply方法。

















 1053
1053

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









