









1. 题目
Learning from Context or Names?
An Empirical Study on Neural Relation Extraction
从上下文学习还是从实体名称中学习?一个关于神经关系抽取的实证研究
2. 作者
Hao Peng1∗ , Tianyu Gao2∗ , Xu Han1 , Yankai Lin3 , Peng Li3 , Zhiyuan Liu1*†* ,
Maosong Sun1 , Jie Zhou3
单位:Tsinghua University,Princeton University,WeChat AI, Tencent Inc
EMNLP 2020
3. 摘要
关于什么信息特征(主要是上下文与实体提及)是对关系抽取是有用的进行研究,看看影响程度是怎么样的?提出采用实体遮蔽的对比学习框架。
从“文本上下文(textual context)”与“实体提及(entity mentions)”这两个信息源出发去研究关系抽取,结论为:
1)上下文信息是神经关系抽取模型的主要信息来源,同时模型也存在对实体信息的过度依赖问题,而实体信息中大部分是实体类型信息;
2)现有的数据集可能会通过实体泄露浅层的启发式信息,这可能也导致了一些关系抽取任务的效果虚高。
提出的解决方案为:实体遮蔽的对比预训练学习框架[entity-masked contrastive pre-training framework]。
4. 结果
4.1 信息抽取中影响因素报告:
4.2 实体遮蔽的对比预训练学习框架
5.实验设置
5.1 三个关系模型研究
| CNN | CNN模型是来自【4】,而参数,输入,嵌入向量来处【5】; |
|---|---|
| Bert | Bert参考论文【6】,通过特殊标记突出强调句子中提到的实体,并使用实体表示的级联进行分类。 |
| Matching the blanks (MTB) | MTB【6】是一种基于BERT的面向RE的预训练模型。 |
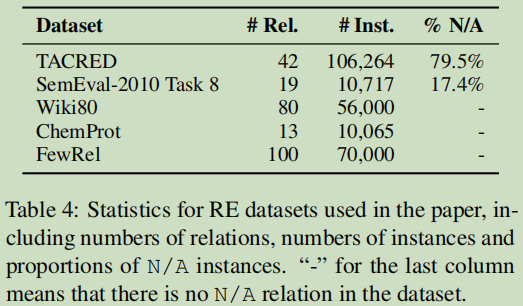
5.2 public benchmarks–公共基准
TACRED【5】最大的监督RE数据集作为实验数据。106,264条实例和42个关系,每个实体也提供了类型注释。
5.3 数据集分组
| Context+Mention (C+M) | 整个句子被提供,在预训练时模型知道实体提及在哪里,也把实体标出来。 |
|---|---|
| Context+Type (C+T) | 使用实体类型去替换实体类型。 |
| Only Context (OnlyC) | 目标解释 textual context的贡献。使用[SUBJ] 与[OBJ]特殊符号去代码实体提及。 |
| Only Mention (OnlyM) | 只采用实体提及的信息去做实验; |
| Only Type (OnlyT) | 只采用实体类型的信息去做实验; |
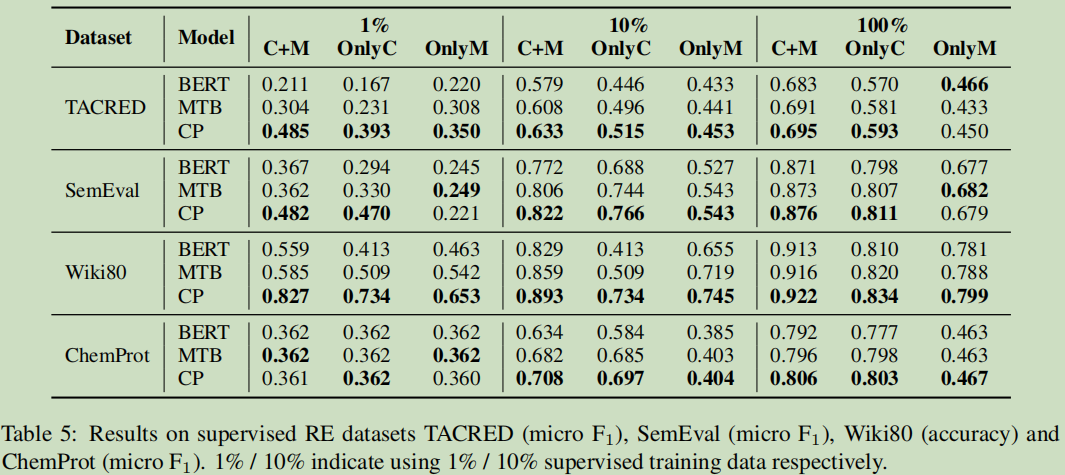
5.4 结果
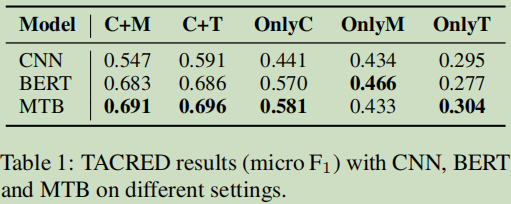
5.5 结论
结论1:上下文与实体提及都是重要信息,而实体类型比较实体提及更重要一些;
结论2:存在的RE数据中的实体提及引起浅层泄露,由于数据的倾斜使得实验数据有些虚高;
6 实体遮蔽的对比预训练学习框架及实验
对比学习:idea来源于【8】,目的是把相邻的拉放在一起,把不相邻推开。
相邻实例有相似的表达,定义相邻的实例子比较重要,论文引入了知识图谱去完成相邻性问题。
远程监督:【7】,我们假设在知识图谱中具有相同关系的实体对的句子是“邻居”。
mask:以概率P_BLANK使用[BLANK]标记对实体描述进行Mask,为了避免提及的干扰,根据【9】概念设置为0.7;
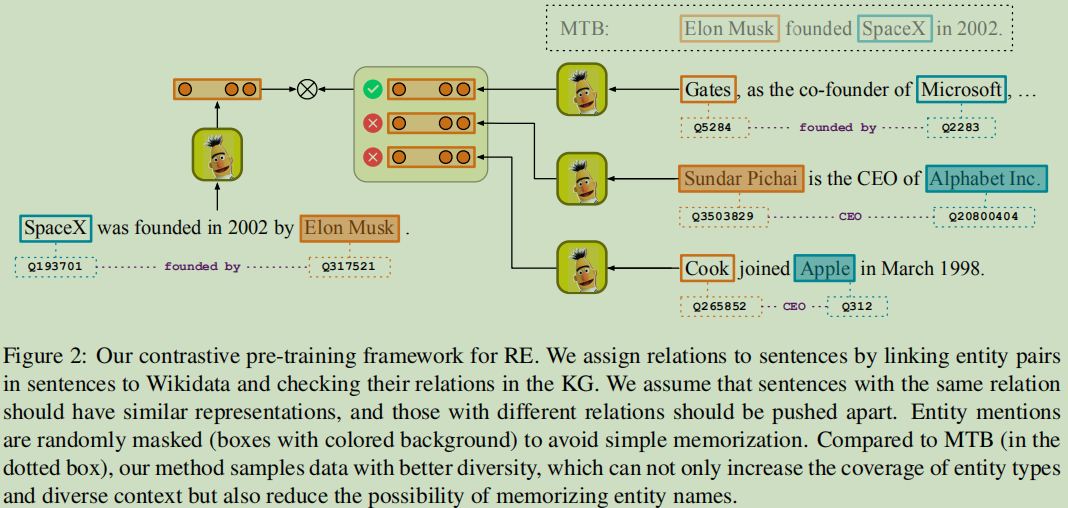
数据生成过程:
一个句子对<“SpaceX was founded in 2002 by Elon Musk”,“As the co-founder of Microsoft, Bill Gates …”>, 数据库中有(SpaceX, founded by, Elon Musk)
与 (Microsoft, founded by, Bill Gates) 两个实体关系;希望这两个句子有相似的表达(因为这两个句子都关联着founded by这个关系);对于右边的举例的CEO关系的句子,希望它们的表达与founed by有不同的表示。
6.1 输入格式
“SpaceX was founded by Elon Musk.” =[加入开始,加入结尾,把实体标注出来]=> “[CLS][E1] SpaceX [/E1] was founded by [E2] Elon Musk [/E2] . [SEP]”.
6.2 预训练目标函数
pre-training阶段(两个目标函数):Contrastive Pre-training Objective与Masked Language Modeling Objective
Contrastive Pre-training Objective:
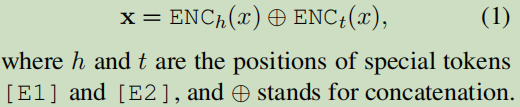
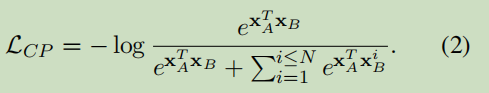
Masked Language Modeling Objective:
主要采用bert论文上的MLM的目标函数。
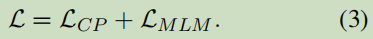
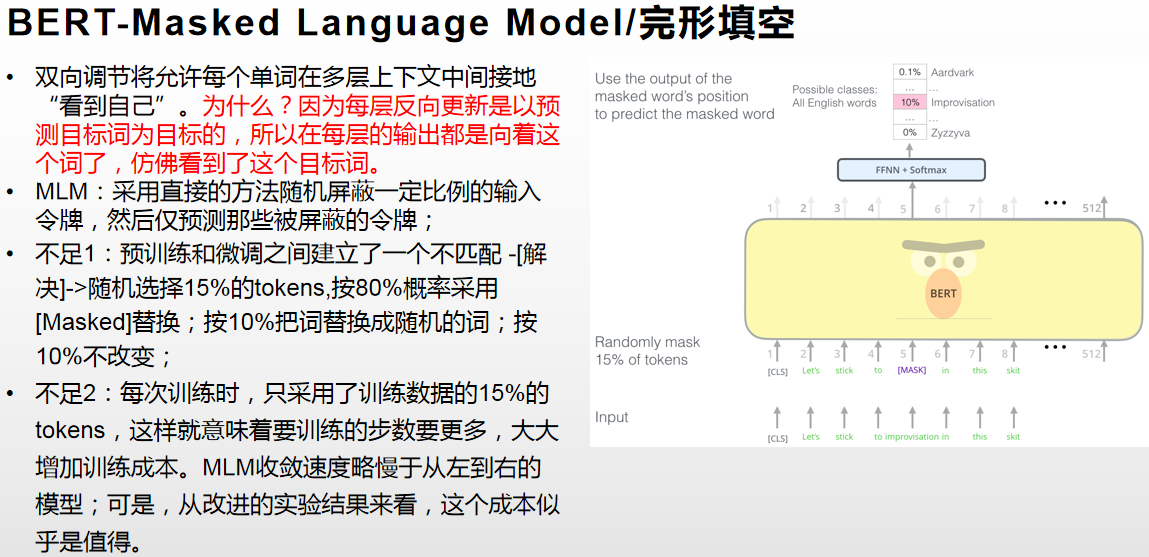
附bert的MLM:
6.3 RE任务[fine-tune阶段]
数据
Supervised RE
监督的RE任务中的关系是预先定义好的,对于关系分类在给定的关系集中可以找到,如果不存的加一个N/A或no_relation的分类。
在实验过程,论文设计了一个低资源版本的实验,分别对上面的数据集作1%与10%的数据选择。
Few-Shot RE
用很少的数据样本去训练一个新任务。比较典型的设置为N-way K-shot.N个关系类型,第个关系类型K个样本。
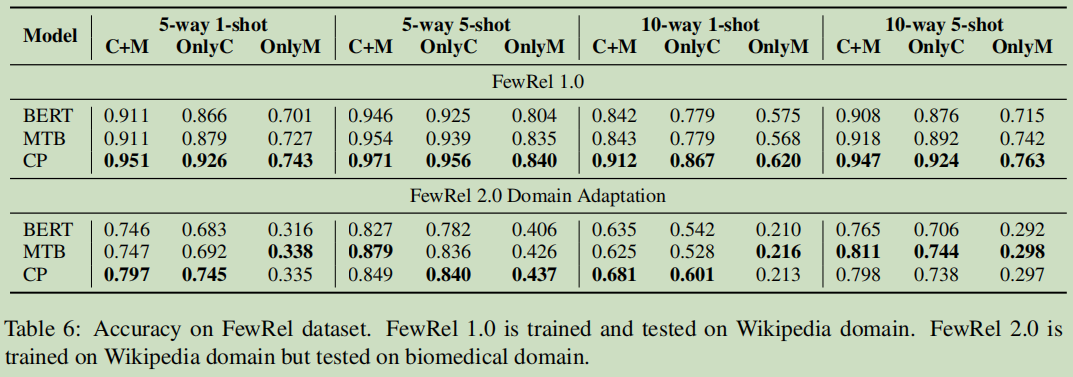
模型
基线模型:BERT,MTB。
本论文的模型:CP:contrastive pre-training framework
结果分析
a. CP的预模型提升了上下文的理解与实体类型识别上。
b. CP对于跨越不同的领域也是比较有效的。
c. CP模型提升了上下文与实体类型的抽取
d. 预模型对于低资源与few-show设置也有效;
7. 相关工作
7.1 RE的发展历程
早期: pattern-based methods ,feature-based methods,kernel-based methods, graphical models
深度学习: recursive neural networks for,neural RE,可是带来数据不足的问题,解决数据不足问题的两种方法:distant supervision与few-shot learning
distant supervision
distant supervision是将已有的知识库(比如 freebase)对应到丰富的非结构化数据中(比如新闻文本),从而生成大量的训练数据,从而训练出一个效果不错的关系抽取器。
Few-shot Learning顾名思义就是用很少的样本去做分类或者回归。Few-Shot Learning是meta learning中的一种。而meta learning可以理解为learn to learn。
- k-way:the support set has k classes.
- n-shot:every class has n exampples.
7.2 Pre-training for RE
学习RE模式的预训练模型。
7.3 Analysis of RE
RE分析,【10】RE模型是怎么样从上下文及名字提及到学习信息的。【11】在实体提及中可能存在浅层线索,可是没有系统去作分析。
8. 心得
整体来看,还是很详细的一篇文章,从实验中研究了上下文与实体提及对关系抽取的影响性,针对这个两个关系影响提出了专门针对RE的预训练模型及CP方法。里面含有的相关知识也是很多的,涉及到预训练,对比学习,少样本学习等等这些有效的深度学习思想,也是比较前沿的方法,最后是研究成果也很好,里面的每个细节值好好学习。
9.参考
【1】论文下载:https://arxiv.org/pdf/2010.01923.pdf
【2】github开源:https://github.com/thunlp/ RE-Context-or-Names
【3】刘知远老师的“灵魂发问”:关系抽取到底在乎什么?https://mp.weixin.qq.com/s/azD5OKyTxYVVZM8eho4JXA
【4】Thien Huu Nguyen and Ralph Grishman. 2015. Relation extraction: Perspective from convolutional neural networks. In Proceedings of the NAACL Work shop on Vector Space Modeling for NLP, pages 39–48.
【5】Yuhao Zhang, Victor Zhong, Danqi Chen, Gabor Angeli, and Christopher D Manning. 2017. Position aware attention and supervised data improve slot filling. In Proceedings of EMNLP, pages 35–45.
【6】Livio Baldini Soares, Nicholas FitzGerald, Jeffrey Ling, and Tom Kwiatkowski. 2019. Matching the blanks: Distributional similarity for relation learning. In Proceedings of ACL, pages 2895–2905.
【7】Mike Mintz, Steven Bills, Rion Snow, and Dan Jurafsky. 2009. Distant supervision for relation extraction without labeled data. In Proceedings of ACL
IJCNLP, pages 1003–1011.
【8】Raia Hadsell, Sumit Chopra, and Yann LeCun. 2006. Dimensionality reduction by learning an invariant mapping. In 2006 IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR’06), volume 2, pages 1735–1742. IEEE.
【9】Livio Baldini Soares, Nicholas FitzGerald, Jeffrey Ling, and Tom Kwiatkowski. 2019. Matching the blanks: Distributional similarity for relation learning. In Proceedings of ACL, pages 2895–2905.
【10】Xu Han, Tianyu Gao, Yankai Lin, Hao Peng, Yaoliang Yang, Chaojun Xiao, Zhiyuan Liu, Peng Li,Maosong Sun, and Jie Zhou. 2020. More data, more
relations, more context and more openness: A review and outlook for relation extraction.
【11】Christoph Alt, Aleksandra Gabryszak, and Leonhard Hennig. 2020. TACRED revisited: A thorough evaluation of the TACRED relation extraction task. In Proceedings of ACL.
作者:happyprince https://blog.csdn.net/ld326/article/details/112311041















 3805
3805











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









