









一,题目
A Frustratingly Easy Approach for Joint Entity and Relation Extraction
一种简单易行的联合实体和关系提取方法
二,作者
Zexuan Zhong
Danqi Chen:https://www.cs.princeton.edu/~danqic/
Email: danqic@cs.princeton.edu
Department of Computer Science Princeton University 普林斯顿大学 世界排名12
2020.10
三,摘要
提出了一个非常简单的关系抽取方法,获得SOA.通过对于实体识别与关系抽取学习两个独立的预训练编码器;
大量实验证明学习不同上下文对实体与关系抽取的重要性;
四,贡献
a. 提出一个简单的联合抽取方法,获得SOA【ACE04, ACE05, SciERC】;
b. 详细解释了为什么这个方法这么好,不同的因素是怎样影响结果?
c. 对于加速推理模型方面,提出一个有效的近似模型;在只下降很少正确率的情况下有8到16位的提升。
五,相关技术
传统上,提取文本中实体之间的关系被研究为两个独立的任务:命名实体识别和关系抽取。
近年,把命名实体识别与关系抽取联合起来学习,可以分成两类:结构化预测和多任务学习.
5.1 结构化预测
| 归类 | 相关研究 |
|---|---|
| 提出了一个基于行动的系统,该系统识别新实体以及与实体的链接 | Incremental joint extraction of entity mentions and relations.(2014); End-to-end neural relation extraction with global optimization (2017) |
| 采用填表方法 | Joint extraction of entities and relations based on a novel tagging scheme.(2017); Modeling joint entity and relation extraction with table representation(2014); Going out on a limb: Joint extraction of entity mentions and relations without dependency trees.(2017,ACL) |
| 基于序列标记的方法 | Joint extraction of entities and relations based on a novel tagging scheme.(2017,ACL) |
| 出基于图的方法来联合预测实体和关系类型 | Joint type inference on entities and relations via graph convolutional networks.(2019,ACL); GraphRel: Modeling text as relational graphs for joint entity and relation extraction.(2019,ACL) |
| 将任务转化为多轮问答 | Entity-relation extraction as multi-turn question answering.(2019,ACL) |
所有这些方法都需要解决全局优化问题,在推理是使用束搜索或强化学习来执行联合解码。
5.2 多任务学习
本质上是建立两个独立的任务(NER,RE)来共享参数,优化时只优化一份参数来学习。
| 归类 | 相关研究 |
|---|---|
| End-to-end relation extraction using LSTMs on sequences and tree structures(2016,ACL) | NER是列序标注模型,RE采用基于Tree的LSTM模型,两个模型共享一个LSTM层 |
| Adversarial training for multi-context joint entity and relation extraction(2018,EMNLP) | 跟上面差不多,只是RE模型是一个多标签头选择问题; |
这些方法仍然是pipeline流程,首先抽取实体,关系抽取模型使用了已抽取出来实体。
5.3 共享跨度(span)表示
【4】DYGIE–Multi-task identification of entities, relations, and coreference for scientific knowledge graph construction(2018,EMNLP)
A general framework for information extraction using dynamic span graphs(2019,NAACL)
Entity, relation, and event extraction with contextualized span representations(2019,EMNLP)
A joint neural model for information extraction with
global features(2020,ACL)
span的含义我认为是不同备选实体之间的组合. 论文的思想基于这里,对DYGID的简化。
关于关系抽取的Bert
Simple bert models for relation extraction and semantic role labeling(2019)
Matching the blanks: Distributional similarity for relation learning(2019,ACL)
论文对Bert作了研究
6. 模型
6.1 定义(形式化定义)
X表示一个句子,S表示spans集合,列表出尽可能多的spans.
NER任务的输出:

RE任务的输出:
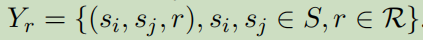
6.2 模型 (提出模型)
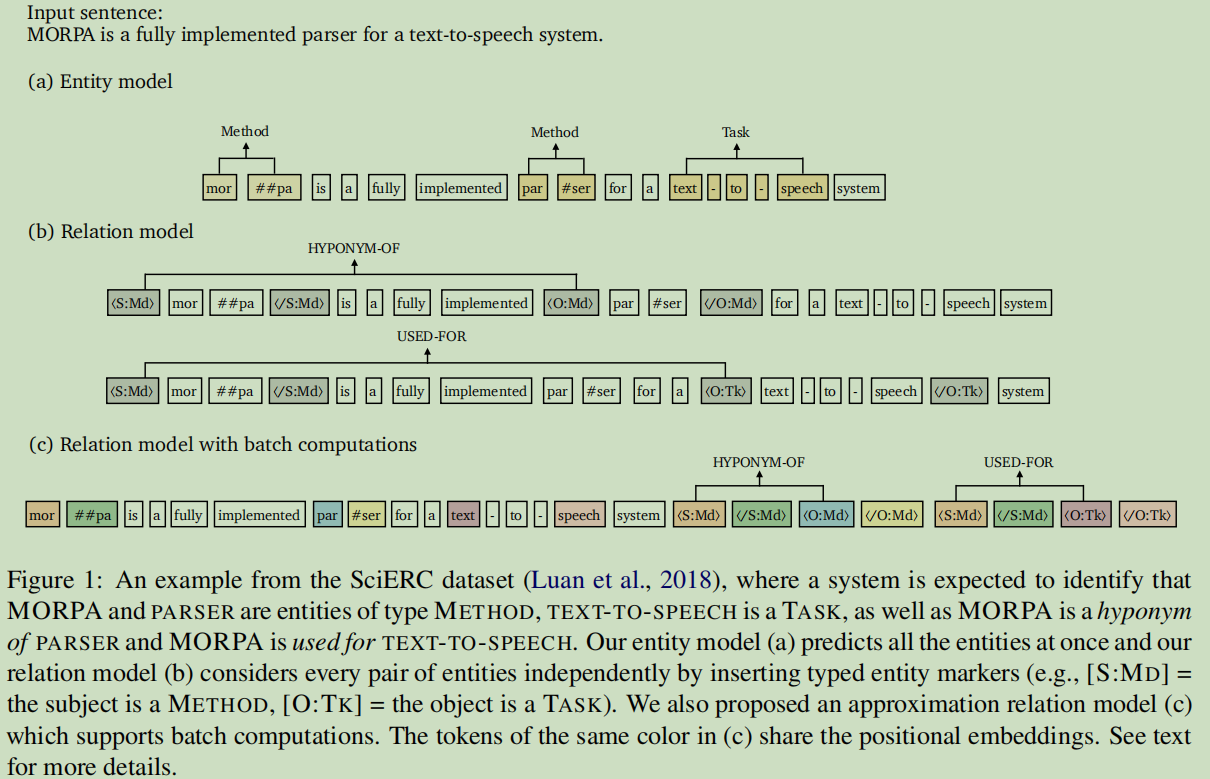
第一步,输入句子并对单个span进行类型预测;
第二步,在关系模型上,处理候选实体对,根据标注去高亮主语,谓语及相关的类型。
6.2.1 Entity model
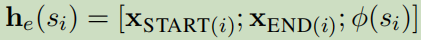
采用bert来对每个token来上下文表示。h是某个span嵌入bert之后的向量。这里包含了开始位置信息,结束位置信息,嵌入信息的拼接。这个表达直接用来预测单个span的类型:
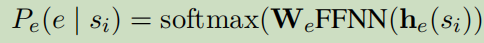
WeFFNN()模型来自DyGIE++(Entity, Relation, and EE with Contextualized Span Representations).使用带有ReLU激活函数的两层前向神经网络。
6.2.2 Relation model
目标:关系模型的目标是输入一对span,预测这对span的类型。
问题:前面的研究采用h作为输入去预测,论文认为这种方法只是捕捉了实体各自周围的上下文章信息,可能对具体的span对依赖信息捕捉不到。
处理方法:对主语,宾语及它们的类型作一个类型标记高亮[高亮的信息来自于手工标注的数据]:
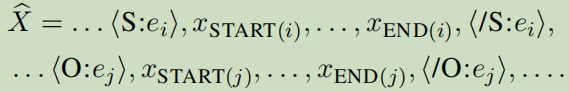
然后,应用某外一个预见编码器在加了高亮标注的句子上,把两个开始位置联接起来:

即为标注开始的那个标记符<S:e_i>或者<O:e_j>的位置。
最后,预测:
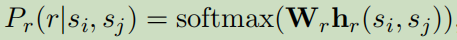
6.2.3 Cross-sentence context–跨句子的上下文
原因:跨句信息可以用来帮助预测实体类型和关系,特别是代词。
旧的方法:使用传播机制去连通代词和关系连接包括跨句的上下文。有些加入3句的窗口去处理,效果也不错。
现在方法:以固定W来扩展跨句。具体来讲当输入句子有n个词,这里分另从左边与右边扩展(W-n)/2 个词,默认W=100
6.2.3 Training & inference
训练
损失函数:
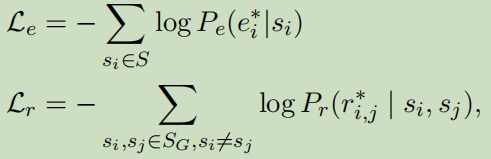
对于训练关系模型,只使用Gold实体数据与实体的Gold标注数据作为关系模型的输入。
推理
第一步先预测实体类型,第二步,以预测的结果输入到关系模型中。
6.2.4 区别于DYGIE++
(1)我们对实体和关系模型使用独立的编码器,不需要进行任何多任务学习;预测的实体标签直接用作关系模型的输入特征。
(2)关系模型中的上下文表示是针对每一对跨度的。
(3)我们将跨句信息与附加上下文一起扩展输入。
(4)我们不使用束搜索或图传播层。
因此,模型要简单得多。
6.3 高效的批量计算(近似推理模型)
模型可能缺点:对每一对实体都要在关系模型运行一次。
期望:希望在同一个句子中重复使用不同span对的计算;
解决:对原模型提出近似模型,可是有两个挑战:
a. 我们将标记的位置嵌入与相应跨度的开始和结束标记联系起来,而不是直接将实体标记插入到原始句子中;
b. 在注意力层加入约束,规定文本tokens只关注文本tokens,它不会关注标记tokens,而一个实体的标记token可以关注到所有的文本tokens和所有关联的4个标记tokens.
效果:这样文本tokens就独立于tokens的标记了,这样就可以重用计算过的结果了。这样就可以把这些标记性的token放在句子末尾一起打包了。
7. 实验
7.1 数据集
ACE04,ACE054 ,SciERC
ACE04是5-fold,ACE05与SciERC分别分割为train,dev,test:

7.2 评价指标
F1分数
NER正确:实体的边界&类型正确;
RE正确:两个实体的边界&关系类型正确;
Rel+(strict F1): 两实体类型&两实体边界&实体关系正确。
7.3 具体实现
相关资源:
HuggingFace’s Transformers library(Huggingface’s transformers: State-of-the-art natural language processing),
bert-base-uncased(BERT: Pre-training of deep bidirectional transformers for language understanding,NAACL),
albert-xxlarge-v1( ALBERT: A lite bert for self-supervised learning of language representations,ICLR),
scibert-scivocab-uncased (Scibert: A pretrained language model for scientifific text,EMNLP*)
7.4 结果
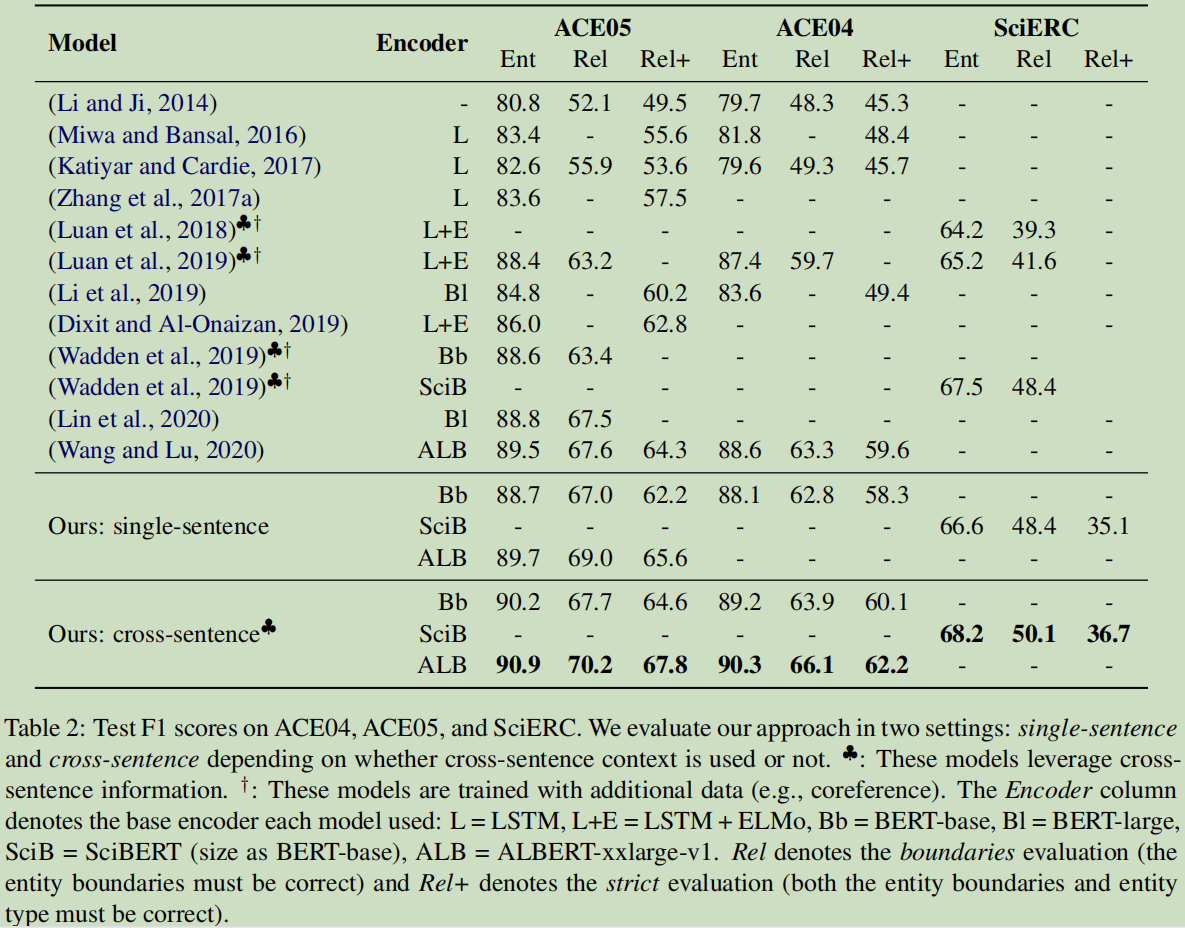
结论:单句了与跨句子都有比较,显然跨上下文句子是有很大的提升的。
对于实体识别,对于三个数据集有1.4%,1.7%,0.7%的提升,跨句子比句子也有一定的提升。对于关系,有不同程度的提升。
证明了学习不同实体的不同表示和不同实体对的关系的有效性,以及在关系模型的输入层融合实体信息的有效性。
7.5 批量计算和加速效果
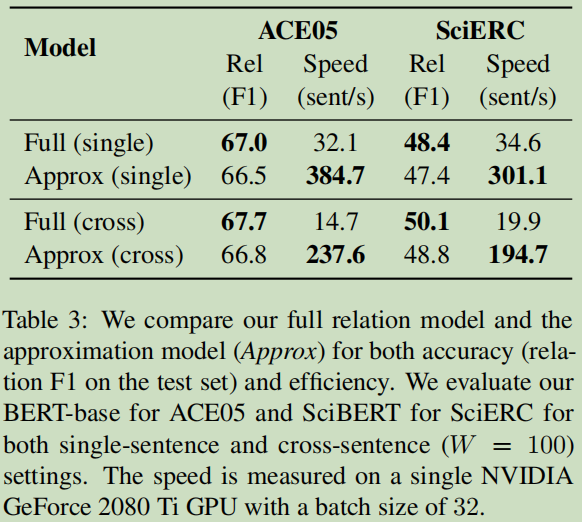
例如:在单句实验中,对于ACE05,获得了11.9倍;对于SciERC,获得了8.7倍。然而在F1的正确率方面,只下降了0.5%.
8. 分析
思考:为什么这么简单的模型可以获得这么好的成绩与性能?
8.1 类型化的文字标记的重要性
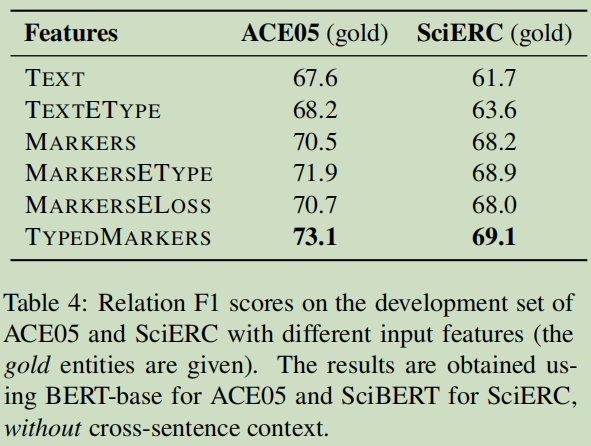
结论:实体的类型对于关系抽取提供了非常重要的信息。
这个结论与Learning from Context or Names? An Empirical Study on Neural Relation Extraction 文章有同样的结论,英雄所得结论都是相同。
8.2 实体与关系的交互模型
对于实体与关系的联合模型中,实体与关系的相互影响来增加信息是非常重要的,这里分析相互影响程度是怎样的?
这节目标:验证这个pipeline流程的方法是否是一个特殊的个例?
第一,验证共享这两个表达编码器是否可以提升模型? 一起训练实体与关系抽取,同时优化Le+Lr。
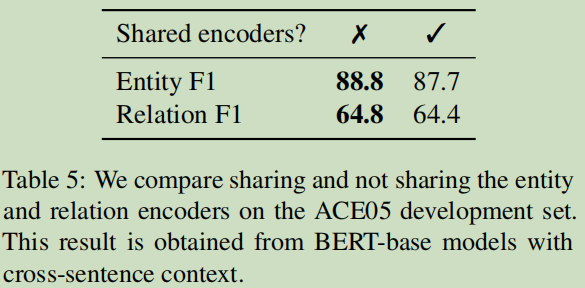
结论:共享编码器对F1并没有提高,反而下降了。这个结论与之前大量论文是在基于共享参数训练不同。,不过实验结果说明一切。
论文认为:两个任务希望有不同输入格式,需要不同的特征来预测实体与关系,所于独立的编码器确实可以学到到更好的特定于任务的特性。
第二,验证关系的信息是否可以提升NER?
结论:关系信息并不可以提升NER模型。
总结:
(1)实体信息有助于预测关系。 然而,在实验中没有发现足够的证据表明关系信息可以大大提高实体性能。
(2)简单地共享编码器并不能带了正确率的提升。
8.3 减少错误传播
Pipeline一个公认的缺点是错误传播。
第一,是否使用预测的实体而不是Gold实体去训练可以减少错误传播。采用10-way jackknifing方法,这个方法像是留一法,这里把数据分10份,用除第k份的数据进行训练的模型去预测第k份的数据。

第二,使用更多的spans对去训练与测试关系模型
结论:经过上面的尝试,并没有找到错误传播的因素在哪里,有待找原因。
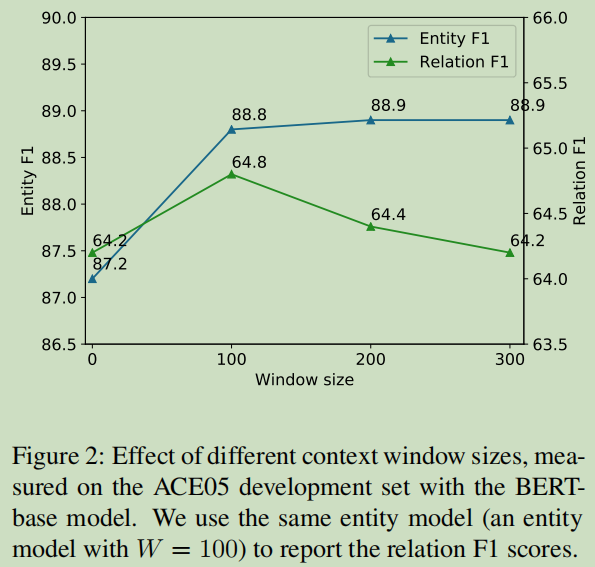
8.4 跨上下文句子的效果
实验结果显示,跨上下文句子是有效果的。
这里讨论一下上下文窗口W的情况,为什么上面的实验W取100:
9. 总结
有点打破joint一定比pipeline好的固定思维,其实简单的方法也可以很有效,站在巨人的肩膀上进行优化。另外,很多论文都证明的一点:实体的类型对于关系抽取提供非常重要的信息。
看论文过程像是一场旅游。比较实在与平素的语言告诉我们这一模型,在这过程进行了一系列的思考,对所遇的问题,通过一个一个实验证明这个模型的可行性。
结论的形成,并非是一朝一夕。
参考:
【1】A Frustratingly Easy Approach for Joint Entity and Relation Extraction,https://arxiv.org/pdf/2010.12812.pdf
【2】反直觉!陈丹琦用pipeline方式刷新关系抽取SOTA,https://zhuanlan.zhihu.com/p/274938894
【3】SciERC,https://bitbucket.org/luanyi/scierc/src/master/
【4】Multi-Task Identification of Entities, Relations, and Coreferencefor Scientific Knowledge Graph Construction,http://nlp.cs.washington.edu/sciIE/
happyprince,https://blog.csdn.net/ld326/article/details/112677034















 3002
3002











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









