









题目
Joint Extraction of Entities and Relations Based on a Novel Decomposition Strategy
Chinese Academy of Sciences — 中科院
Xiaomi AI Lab – 小米AI实验室
Peking University – 北京大学
摘要
解决问题: redundant entity pairs(冗余的实体对);ignore the important inner structure (忽略了重要的内部结构);
方法:首先把联合抽取任务分解成两个相关的任务---- HE extraction(辨别出所有的头部实体)与TER extraction(对于每个头实体识别出相关的尾实体及关系);然后把这两个任务分解成序列标记问题(span-based tagging scheme)。
结果:三个公开数据集超过5.2%, 5.9% , 21.5% (F1 score);
介绍
现在的方法1(pileline):
传统方法-先抽取实体,然后是关系,这样忽略了两个子任务的内在联系。一个解决方法为:参数共享来缓解;可是还是把两任务分开了。导致结果:N个实体,要对N^2个关系进行分类,且大部分是没有关系的类;
现在的方法2(统一的标签标注方案): 设计多功能的标签,可是解决不了overlapping的问题;一次性的标注过程,会忽略掉三元组的内存相关关系。
模型
把任务分析为几个序列的问题,第一个序列任务为头实体(Head-Entity (HE) extraction);其它的序列任务为对于每个头实体相对应的尾实体及关系的抽取任务(Tail-Entity and Relation (TER) extraction)。 – 提出了extract-then-label(ETL)范式
概率模型:
p(h, r, t*|S) = p(h|S)p(r, t|*h, S)
方法的优点,相对于之前的Pileline的方法,这个方法在第一步不需要把所有的实体都抽取出来,只识别出可能是三元组的头实体就可以。
受QA的指针表示启发的span-based的标注,模型引入 span-based tagging scheme。
==对于m个头实体的句子,整个任务被分解为“2 + 2m”个序列标记子任务,“2” 表示HE的标注任务,“2m”表示TER任务;==为什么是“2”呢? 因为这里是一个是"start",一个“end”.
Tagging Scheme – 标记策略
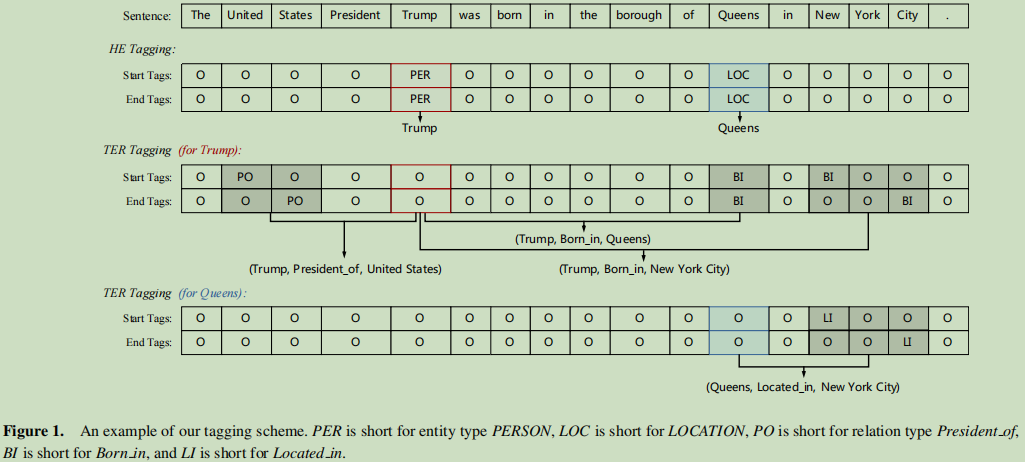
对于HE抽取任务,实体类型标注在实体的start与end位置上;
对于TER抽取任务上,把关系模型标注在相关的位置上,这个关系是对于给的头实体对应的。
相对于PA-LSTM的标记策略BIES, 这个有好的时间复杂性。
Hierarchical Boundary Tagger – 层次边界标记器
论文提出的HE与TER标注,可以采用了一套统一的标记架构去抽取,一般化之后就是:
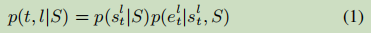
s为标记为l,目标为t的开始标记,e为结束标记。
对于start的任务:
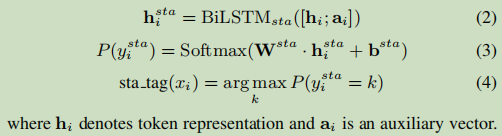
对于HE抽取,a_i是来自整个句子的全局的表达;对于TER抽取,a_i是全局表达及头实体表达的连接;这里用BiLSTM来把hi与ai融合在一起,最后输出一个单一的向量;
同理,对于end的任务:
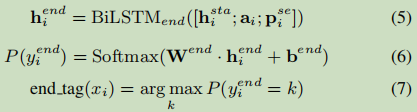
p_i_se表示位置信息;
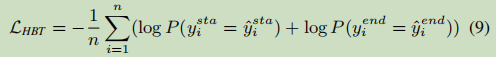
这里的n表示句子的长度。
对于预测阶段(multi-span decoding algorithm):

EXTRACTION SYSTEM – 抽取系统
首先编码句子,然后HE抽取;最后对每个头实体的语义与位置进行TER任务抽取。
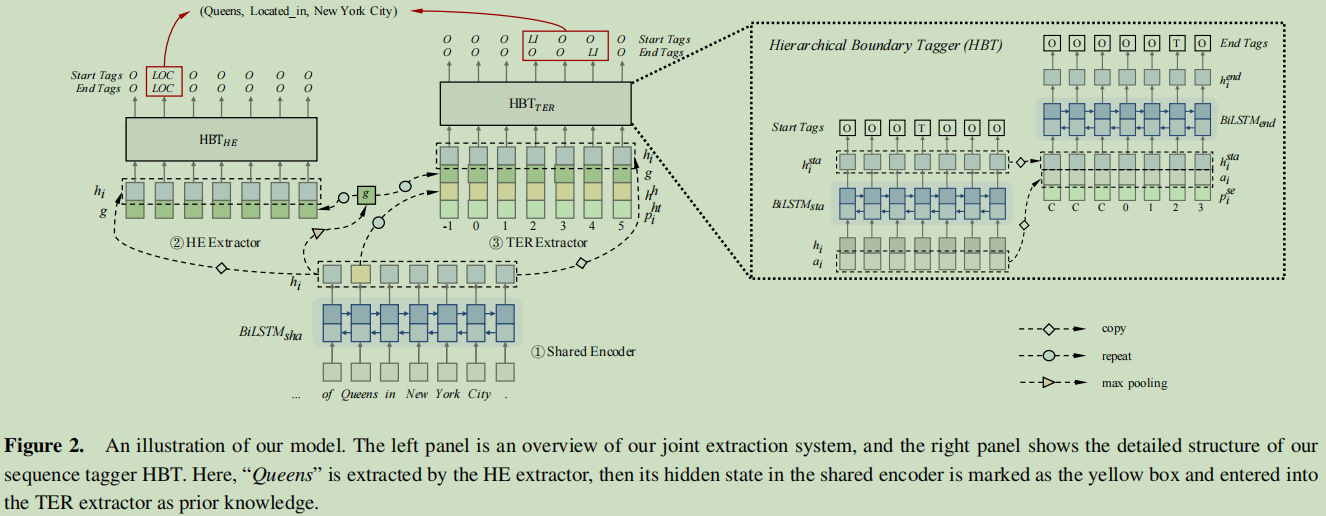
Shared Encoder – 共享编码器

X_i是x_i的词表达,xi包括了预测训练的内容,也包括了字符串的内容;也考虑了POS的信息。。。
HE Extractor
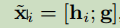
这里的g表示整个句子的全局表达,通过最大池化所以隐状态得到的结果。
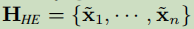
把这些x组成了H_HE,这个是否感觉有些信息是多余的?g究竟重复了多少?每个x都有它。

其中,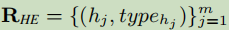 ,包括了句子中所有的头实体及相应的实体标记。
,包括了句子中所有的头实体及相应的实体标记。
TER Extractor

把这些x构成了:
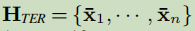
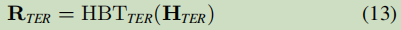
其中,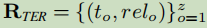
Training of Joint Extractor

实验
数据集:NYT-single,NYT-multi,WebNLG
评估指标:standard micro Precision, Recall and F1 score
选择对比的模型:Cotype,NovelTagging,MultiDecoder,MultiHead,PA-LSTM ,GraphRel ,OrderRL
baseline: ETL-BIES(采用BiLSTM-CRF)
结果:
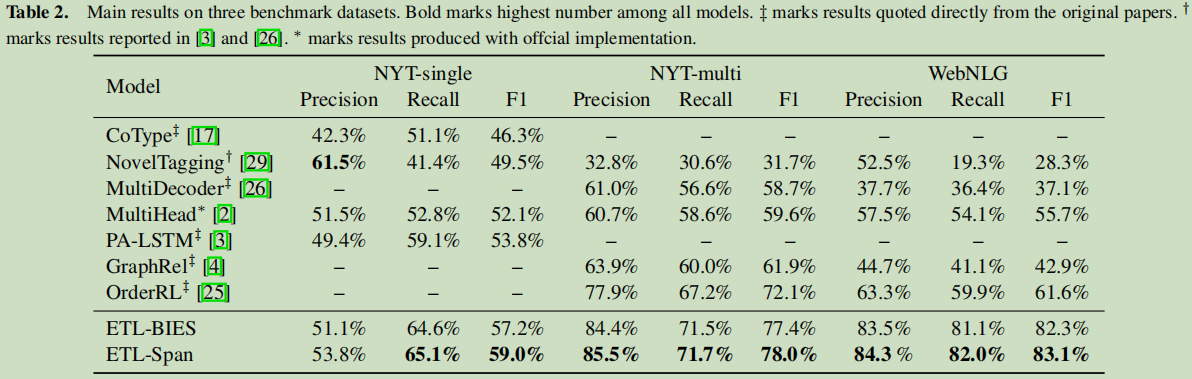
结果显示出来,比之前的方法都有提升,特别是在multi方面表现得是比较显著的。对于非overlapping的情况,模型表现与之前相当的抽取能力。

ETL-Span可将ETL-BIES的解码速度加速了3.7倍。
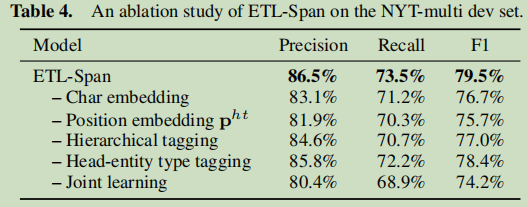
对于消融分析:
不同类型句子的效果情况:
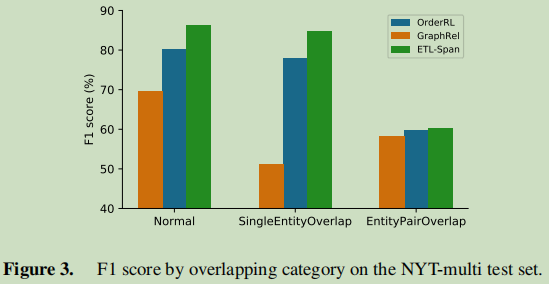
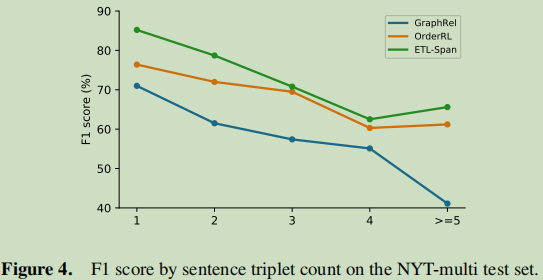
对于句中含三元组个数分析:
总结
整个模型看完,模型就一个字“复杂”!!不过另一个好处是详细,很多个细节点都交待得比较清楚。
从这个实验结果来看,基于span的方法的确是比序列标注的要优。
参考
github: https://github.com/yubowen-ph/JointER
论文: https://arxiv.org/pdf/1909.04273.pdf
https://blog.csdn.net/ld326/article/details/117047064

















 2847
2847

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









