










**0. 摘要
**
随着大型语言模型 (LLMs) 的流行,人们尝试将其扩展到视觉领域。从能够引导我们穿越陌生环境的视觉助手到仅使用高级文本描述生成图像的生成模型,视觉语言模型 (VLM) 的应用将极大地影响我们与技术的互动方式。然而,为了提高这些模型的可靠性,还需要解决许多挑战。语言是离散的,而视觉则在更高维度的空间中演变,其中的概念并不总是容易离散化。为了更好地理解将视觉映射到语言背后的机制,我们介绍了这篇关于 VLMs 的入门文章,希望它能帮助任何想要进入该领域的人。首先,我们介绍了什么是 VLMs,它们如何工作以及如何训练它们。然后,我们介绍并讨论了评估 VLMs 的方法。虽然这项工作主要集中在将图像映射到语言,但我们还讨论了将 VLMs 扩展到视频。
1 简介
近年来,我们在语言建模方面取得了令人印象深刻的进展。许多大型语言模型 (LLMs) 如 Llama 或 ChatGPT 现在能够解决各种各样的任务,因此它们的应用越来越受欢迎。这些模型以前主要限于文本输入,现在已经扩展到包含视觉输入。将视觉与语言连接起来将解锁许多应用,这些应用将成为当前基于人工智能的技术革命的关键。尽管已经有几项工作将大型语言模型扩展到视觉领域,但将语言与视觉连接起来还没有完全解决。例如,大多数模型难以理解空间关系或计数,而无需依赖额外数据标注的复杂工程开销。许多视觉语言模型 (VLMs) 也缺乏对属性和顺序的理解。它们经常忽略输入提示的一部分,导致需要进行大量的提示工程工作才能产生所需的结果。其中一些模型还会产生幻觉,并生成既不需要也不相关的內容。因此,开发可靠的模型仍然是一个非常活跃的研究领域。
在这项工作中,我们介绍了视觉语言模型 (VLMs)。我们解释了什么是 VLMs,它们是如何训练的,以及如何根据不同的研究目标有效地评估 VLMs。这项工作不应被视为关于 VLMs 的调查或完整指南。有关 VLMs 的完整和更技术性的调查,请参考 Zhang 等人(2024a);Ghosh 等人(2024);Zhou 和 Shimada(2023);Chen 等人(2023a);Du 等人(2022);Uppal 等人(2022),以及 Liang 等人(2024)。因此,我们不打算引用 VLM 研究领域中的所有工作。这项工作也不涵盖该领域的所有最佳实践。相反,我们的目标是提供一个清晰易懂的 VLM 研究介绍,并重点介绍该领域研究的有效实践。对于想要进入该领域的来自其他领域的学习者或研究人员来说,本介绍应该特别有用。
我们首先介绍不同的 VLM 训练范式。我们讨论了对比方法如何改变了该领域。然后,我们介绍了利用掩蔽策略或生成组件的方法。最后,我们介绍了使用预训练主干(例如 LLMs)的 VLMs。将 VLMs 分成不同的类别并非易事,因为它们中的大多数都有重叠的组件。但是,我们希望我们的分类能够帮助新研究人员了解该领域,并阐明 VLMs 背后的内部机制。
接下来,我们介绍了训练 VLMs 的典型方法。例如,我们涵盖了:哪些数据集适合不同的研究目标?哪种数据整理策略?我们需要训练文本编码器,还是可以利用预训练的 LLM?对比损失足以理解视觉,还是生成组件是关键?我们还介绍了用于提高模型性能以及接地和更好地对齐的常用技术。
虽然提供训练模型的方法对于更好地理解 VLMs 的需求至关重要,但提供这些模型的稳健可靠的评估同样重要。最近引入了许多用于评估 VLMs 的基准。但是,其中一些基准存在研究人员应该注意的重要局限性。通过讨论 VLM 基准的优缺点,我们希望阐明未来改进我们对 VLMs 理解的挑战。我们首先讨论评估 VLMs 的视觉语言能力的基准,然后介绍如何衡量偏差。
下一代 VLMs 将能够通过将视频映射到语言来理解视频。然而,视频存在图像中不存在的不同挑战。计算成本当然要高得多,但关于如何通过文本映射时间维度也存在其他考虑因素。通过阐明当前从视频中学习的方法,我们希望突出显示当前需要解决的研究挑战。
通过降低进入 VLM 研究的门槛,我们希望为 VLMs 的更负责任的开发提供基础,同时推动视觉理解的边界。
微信公众号“走向未来”专注于大模型、知识图谱、大语言模型、多模态大模型、视觉模型、认知智能、通用人工智能、AI大工程、人工智能基础设施、人工智能数据集等等人工智能技术、产品和应用。欢迎点击关注。
2 VLM 家族
鉴于深度学习在计算机视觉和自然语言处理领域的巨大进步,已经出现了将这两个领域连接起来的几项举措。在本文中,我们重点关注基于 Transformer 的最新技术(Vaswani 等人,2017)。我们将这些最新的举措分为四种不同的训练范式(图 1)。第一个围绕对比训练的策略是一种常用的策略,它利用正负样本对。然后训练 VLM 对正样本对预测相似的表示,而对负样本对预测不同的表示。第二项举措,掩蔽,利用给定一些未掩蔽文本的掩蔽图像块的重建。类似地,通过掩蔽标题中的单词,可以训练 VLM 在给定未掩蔽图像的情况下重建这些单词。基于预训练主干的 VLMs 通常利用 Llama 等开源 LLMs(Touvron 等人,2023)来学习图像编码器(也可以是预训练的)和 LLM 之间的映射。学习预训练模型之间的映射通常比从头开始训练文本和图像编码器成本更低。虽然大多数这些方法利用中间表示或部分重建,但生成式 VLMs 的训练方式使其能够生成图像或标题。鉴于这些模型的性质,它们的训练成本通常最高。我们强调这些范式并非相互排斥;许多方法依赖于对比、掩蔽和生成准则的混合。对于每种范式,我们只介绍一个或两个模型,以便读者对这些模型的设计方式有一些高级的见解。
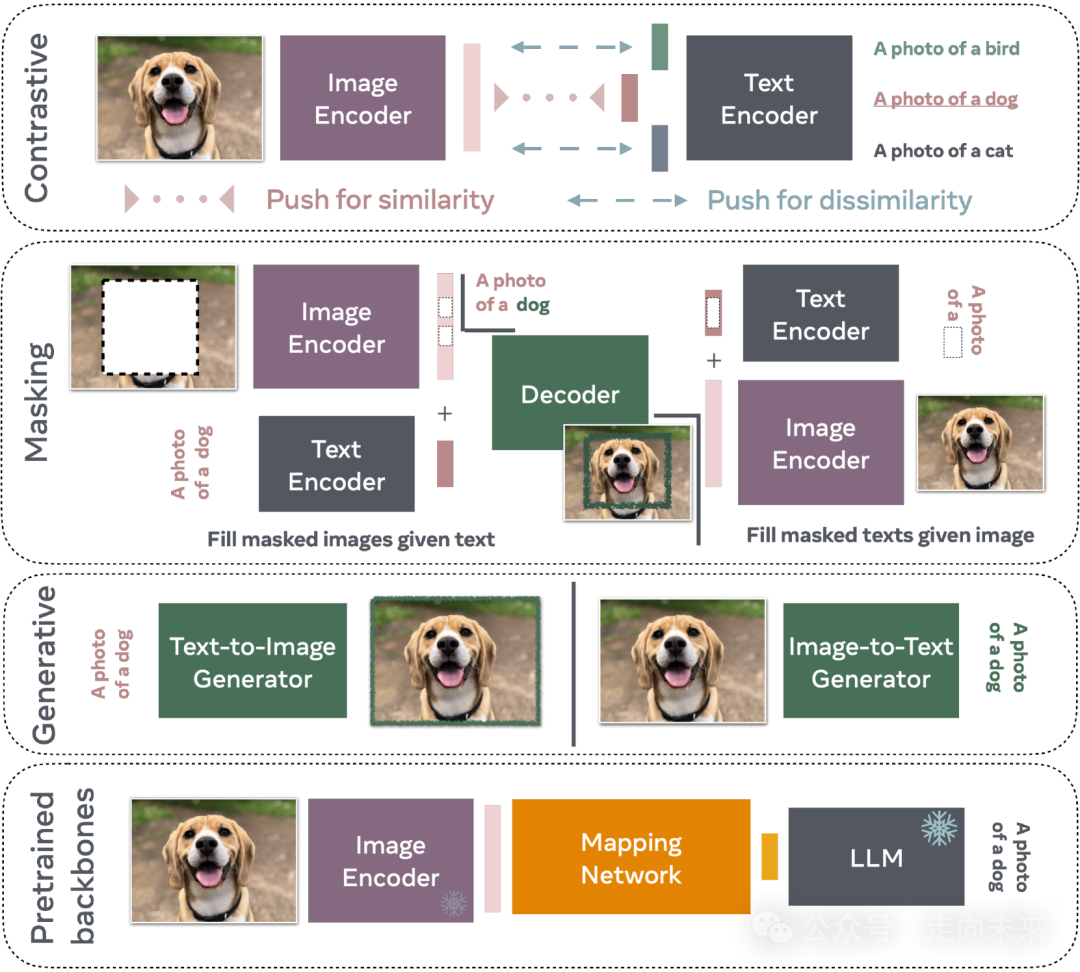
图 1:VLM 家族。对比训练是一种常用的策略,它使用正负样本对。训练 VLM 对正样本对预测相似的表示,而对负样本对预测不同的表示。掩蔽是另一种可以利用的策略,通过在给定未掩蔽文本标题的情况下重建缺失的块来训练 VLMs。类似地,通过掩蔽标题中的单词,可以训练 VLM 在给定未掩蔽图像的情况下重建这些单词。虽然大多数这些方法利用中间表示或部分重建,但生成式 VLMs 的训练方式使其能够生成完整的图像或非常长的标题。鉴于这些模型的性质,它们的训练成本通常最高。基于预训练主干的 VLMs 通常利用 Llama 等开源 LLMs 来学习图像编码器(也可以是预训练的)和 LLM 之间的映射。
重要的是要强调这些范式并非相互排斥;许多方法依赖于对比、掩蔽和生成准则的混合。
2.1 基于 Transformer 的 VLMs 的早期工作
通过使用 Transformer 架构(Vaswani 等人,2017),来自 Transformer 的双向编码器表示 (BERT)(Devlin 等人,2019)在当时显著优于所有语言建模方法。不出所料,研究人员已经将 BERT 扩展到处理视觉数据。其中两个是 visual-BERT(Li 等人,2019)和 ViLBERT(Lu 等人,2019),它们将文本与图像标记结合在一起。这些模型在两个目标上进行训练:1)一个经典的掩蔽建模任务,旨在预测给定输入中缺失的部分;2)一个句子-图像预测任务,旨在预测标题是否实际上描述了图像内容。通过利用这两个目标,这些模型在多个视觉语言任务中取得了优异的性能,这主要归因于 Transformer 模型能够通过注意力机制学习将单词与视觉线索关联起来。
2.2 基于对比的 VLMs

然而,上述要求 x−∼Pθ(x)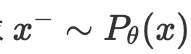 ,这对应于来自模型分布的样本,该样本可能是难以处理的。有几种技术可以近似这种分布。一种依赖于马尔可夫链蒙特卡罗 (MCMC)技术,通过迭代过程找到最小化预测能量的示例。第二种依赖于分数匹配(Hyvärinen,2005)和去噪分数匹配(Vincent,2011)准则,这些准则通过仅学习概率密度相对于输入数据的梯度来消除归一化因子。另一类方法,大多数关于自监督学习和 VLM 的最新工作都基于此,是噪声对比估计 (NCE)(Gutmann 和 Hyvärinen,2010)。
,这对应于来自模型分布的样本,该样本可能是难以处理的。有几种技术可以近似这种分布。一种依赖于马尔可夫链蒙特卡罗 (MCMC)技术,通过迭代过程找到最小化预测能量的示例。第二种依赖于分数匹配(Hyvärinen,2005)和去噪分数匹配(Vincent,2011)准则,这些准则通过仅学习概率密度相对于输入数据的梯度来消除归一化因子。另一类方法,大多数关于自监督学习和 VLM 的最新工作都基于此,是噪声对比估计 (NCE)(Gutmann 和 Hyvärinen,2010)。
与使用模型分布来采样负样本不同,NCE 背后的直觉是,从噪声分布u′∼pn(u′) 中采样在某些情况下可能足够好地近似来自模型分布的样本。即使在理论上很难证明为什么这种方法可能有效,但最近的自监督学习 (SSL)文献中也存在大量关于基于 NCE 的方法成功的经验证据(Chen 等人,2020)。原始的 NCE 框架可以描述为一个二元分类问题,其中模型应该对来自真实数据分布的样本预测标签 C=1,而对来自噪声分布的样本预测标签 C=0。通过这样做,模型学习区分真实数据点和噪声数据点。因此,损失函数可以定义为具有交叉熵的二元分类:

InfoNCE 损失不预测二元值,而是利用模型表示空间中计算的距离度量,例如余弦相似度。这需要计算示例的正样本对之间的距离以及所有负样本对之间的距离。模型学习通过 Softmax 预测最有可能的示例对,该示例对在表示空间中最接近,同时将较低的概率与所有其他负样本对相关联。对于 SimCLR 等 SSL 方法(Chen 等人,2020),正样本对定义为一个图像及其相应的经过手工制作的数据增强版本(例如,在原始图像上应用灰度化之后),而负样本对是使用一个图像和一个小批量中存在的所有其他图像构建的。基于 InfoNCE 的方法的主要缺点是引入了对小批量内容的依赖。这通常需要较大的小批量才能使正负样本之间的对比训练标准更有效。
2.2.1 CLIP
使用 InfoNCE 损失的一种常见的对比方法是对比语言-图像预训练 (CLIP)(Radford 等人,2021)。
正样本对定义为一个图像及其相应的真实标题,而负样本对定义为同一个图像,但包含在小批量中描述其他图像的所有其他标题。CLIP 的一个新颖之处在于训练一个模型,以将视觉和语言合并到一个共享的表示空间中。CLIP 训练随机初始化的视觉和文本编码器,以使用对比损失将图像及其标题的表示映射到相似的嵌入向量。在从网络收集的 4 亿个标题-图像对上训练的原始 CLIP 模型显示出非凡的零样本分类迁移能力。具体来说,ResNet-101 CLIP 匹配了监督 ResNet(He 等人,2015)模型的性能(达到 76.2% 的零样本分类准确率),并在几个鲁棒性基准上超过了它。
SigLIP(Zhai 等人,2023b)类似于 CLIP,不同之处在于它使用基于二元交叉熵的原始 NCE 损失,而不是使用基于 InfoNCE 的 CLIP 的多类目标。这种变化使模型能够在比 CLIP 更小的批量大小上获得更好的 0 样本性能。
潜在语言图像预训练 (Llip)(Lavoie 等人,2024)考虑了图像可以用多种不同的方式进行标注的事实。它建议通过交叉注意力模块将图像的编码条件化为目标标题。考虑标题的多样性会增加表示的表达能力,并且通常会提高下游零样本迁移分类和检索性能。
2.3 具有掩蔽目标的 VLMs
掩蔽是深度学习研究中常用的技术。它可以被视为一种特定形式的去噪自动编码器(Vincent 等人,2008),其中噪声具有空间结构。它也与图像修复策略相关,这些策略被 Pathak 等人(2016)用来学习强大的视觉表示。最近,BERT(Devlin 等人,2019)在训练期间使用掩蔽语言建模 (MLM)来预测句子中缺失的标记。掩蔽特别适合 Transformer 架构(Vaswani 等人,2017),因为输入信号的标记化使得更容易随机丢弃特定的输入标记。
在视觉方面也有一些工作通过使用掩蔽图像建模 (MIM)来学习表示,例如 MAE(He 等人,2022)或 I-JEPA(Assran 等人,2023)。自然地,也有一些工作将这两种技术结合起来训练 VLMs。第一个是FLAVA(Singh 等人,2022),它利用包括掩蔽在内的几种训练策略来学习文本和图像表示。第二个是 MaskVLM(Kwon 等人,2023),它是一个独立的模型。最后,我们将在信息论和掩蔽策略之间建立一些联系。
2.3.1 FLAVA
基于掩蔽方法的第一个例子是基础语言和视觉对齐 (FLAVA)(Singh 等人,2022)。它的架构包含三个核心组件,每个组件都基于 Transformer 框架,并针对特定模式进行定制。图像编码器采用视觉 Transformer (ViT)(Dosovitskiy 等人,2021)将图像处理成用于线性嵌入和基于 Transformer 的表示的块,包括一个分类标记 ([CLSI])([CLSI])。文本编码器使用 Transformer(Vaswani 等人,2017)对文本输入进行标记化,并将它们嵌入到向量中,以进行上下文处理并输出隐藏状态向量,以及一个分类标记 ([CLST])([CLST])。这两个编码器都使用掩蔽方法进行训练。在此基础上,多模态编码器融合了来自图像和文本编码器的隐藏状态,利用 Transformer 框架中学习到的线性投影和交叉注意力机制来整合视觉和文本信息,这由一个额外的多模态分类标记 ([CLSM])([CLSM]) 所突出显示。该模型采用了一个综合的训练方案,该方案结合了多模态和单模态掩蔽建模损失,以及对比目标。它在 7000 万个公开可用的图像和文本对数据集上进行预训练。通过这种方法,FLAVA 表现出非凡的多功能性和有效性,在 35 个跨越视觉、语言和多模态基准的各种任务中取得了最先进的性能,从而说明了该模型能够理解和整合来自不同领域的信息的能力。
2.3.2 MaskVLM
FLAVA 的一个局限性是使用预训练的视觉编码器,例如 dVAE(Zhang 等人,2019)。为了使 VLM 减少对第三方模型的依赖,Kwon 等人(2023)引入了 MaskVLM,它直接在像素空间和文本标记空间中应用掩蔽。使其在文本和图像中都能正常工作的一个关键是使用来自一种模式到另一种模式的信息流;文本重建任务接收来自图像编码器的信息,反之亦然。
2.3.3 关于 VLM 目标的信息论观点
Federici 等人(2020)首先表明,VLMs 可以被理解为解决速率失真问题,通过减少多余信息并最大化预测信息。

这种观点将掩蔽和其他形式的增强以及两种数据模式之间的选择函数统一起来;所有这些都可以表示为数据的某种变换。
我们可以制定相关的速率失真问题(Shwartz Ziv 和 LeCun,2024):


由于信息论观点的结果,我们理解对比损失和自动编码损失是失真的实现,而速率主要由使用的数据变换决定。
2.4 基于生成的 VLMs
与之前主要在潜在表示上操作以构建图像或文本抽象,然后将它们相互映射的训练范式相比,生成范式考虑了文本和/或图像的生成。一些方法,如 CoCa(Yu 等人,2022b)学习一个完整的文本编码器和解码器,使图像标注成为可能。另一些方法,如 Chameleon Team(2024)和 CM3leon(Yu 等人,2023),是显式训练以生成文本和图像的多模态生成模型。最后,一些模型仅训练以基于文本生成图像,例如 Stable Diffusion(Rombach 等人,2022)、Imagen(Saharia 等人,2022)和 Parti(Yu 等人,2022c)。然而,即使它们被训练为仅生成图像,它们也可以用来解决几个视觉语言理解任务。
**2.4.1 学习文本生成器的示例:**CoCa
除了在 CLIP 中表现良好的对比损失之外,对比式标题生成器 (CoCa)(Yu 等人,2022b)还采用了一个生成损失,该损失对应于由多模态文本解码器生成的标题,该解码器将 (1) 图像编码器输出和 (2) 由单模态文本解码器生成的表示作为输入。新的损失允许在不需要使用多模态融合模块进行进一步适应的情况下执行新的多模态理解任务(例如,VQA)。
CoCa 通过简单地将带注释的图像标签视为文本从头开始进行预训练。预训练依赖于两个数据集:ALIGN,它包含约 18 亿张带有替代文本的图像,以及 JFT-3B,这是一个内部数据集,它包含 >29.5k 个类别作为标签,但将标签视为替代文本。
2.4.2 多模态生成模型的示例:Chameleon 和 CM3leon
Yu 等人(2023)介绍了 CM3leon,这是一个用于文本到图像和图像到文本生成的基模型。CM3leon 从 Gafni 等人(2022)那里借鉴了图像标记器,该标记器将 256 × 256 的图像编码为来自 8192 个词汇表的 1024 个标记。它从 Zhang 等人(2022)那里借鉴了文本标记器,词汇量为 56320。它引入了一个特殊标记 来指示模式之间的转换。这种标记化方法允许模型处理交织的文本和图像。然后将标记化的图像和文本传递到一个仅解码器的 Transformer 模型(Brown 等人,2020;Zhang 等人,2022),该模型参数化了 CM3leon 模型。
CM3leon 模型经历了一个两阶段的训练过程。第一阶段是检索增强预训练。此阶段使用基于 CLIP 的编码器(Radford 等人,2021)作为密集检索器,以获取相关且多样化的多模态文档,并将这些文档添加到输入序列的开头。然后使用输入序列上的下一个标记预测来训练模型。检索增强有效地增加了预训练期间可用的标记,从而提高了数据效率。第二阶段涉及监督微调 (SFT),其中模型经历多任务指令微调。此阶段允许模型处理和生成跨不同模式的内容,从而显著提高其在各种任务上的性能,包括文本到图像生成和语言引导的图像编辑。这些阶段共同使 CM3leon 能够在多模态任务中取得最先进的性能,展示了自回归模型在处理文本和图像之间复杂交互方面的能力的重大进步。
这项工作的扩展是 Chameleon,这是一系列新的混合模式基模型(Team,2024),它可以生成和推理交织的文本和图像内容的混合序列。这种能力允许进行全面的多模态文档建模,扩展到典型的多模态任务之外,例如图像生成、图像理解和仅文本语言模型。Chameleon 从一开始就被独特地设计为混合模式,利用统一的架构,以端到端的方式从头开始在所有模式(图像、文本和代码)的混合上进行训练。这种集成方法对图像和文本都采用完全基于标记的表示。通过将图像转换为离散标记,类似于文本中的单词,相同的 Transformer 架构可以应用于图像和文本标记序列,而无需为每种模式使用单独的编码器。这种早期融合策略,即从一开始就将所有模式映射到共享的表示空间,能够在不同模式之间进行无缝推理和生成。然而,这也带来了重大的技术挑战,特别是在优化稳定性和扩展性方面。这些挑战通过架构创新和训练技术的结合来解决,包括对 Transformer 架构的新颖修改,例如查询-键归一化和修改后的层归一化放置,这些对于在混合模式环境中进行稳定训练至关重要。此外,他们还展示了如何将用于仅文本语言模型的监督微调方法适应混合模式上下文,从而在规模上实现强大的对齐。
2.4.3 将生成式文本到图像模型用于下游视觉语言任务
最近在语言条件图像生成模型方面取得了重大进展(Bie 等人,2023;Zhang 等人,2023a),从像 Stable Diffusion(Rombach 等人,2022)和 Imagen(Saharia 等人,2022)这样的扩散模型到像 Parti(Yu 等人,2022c)这样的自回归模型。虽然重点一直是它们的生成能力,但实际上它们可以直接用于判别任务,例如分类或标题预测,而无需任何重新训练。

使用条件生成模型执行判别任务并不是一个新想法——生成式分类或“通过合成进行分析”(Yuille 和 Kersten,2006)一直是朴素贝叶斯(Rubinstein 等人,1997;Ng 和 Jordan,2001)和线性判别分析(Fisher,1936)等基础方法背后的核心思想。这些生成式分类方法传统上受到弱生成模型能力的限制;然而,如今的生成模型非常出色,以至于生成式分类器再次变得具有竞争力。
使用自回归模型进行似然估计。
其他模式(如语言或语音)中大多数最先进的自回归模型作用于离散标记,而不是原始输入。对于语言和语音等固有离散的模式来说,这相对简单,但对于图像等连续模式来说却很困难。为了有效地利用自回归建模技术(如 LLMs),从业者通常训练一个图像标记器,该标记器将图像映射到离散标记序列(t1,⋯,tK)。在将图像转换为离散标记序列(例如,对图像进行标记化)之后,估计图像似然就很简单了:
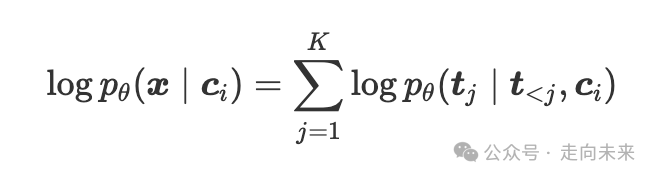
(6)
其中 pθ 由自回归 VLM 参数化。鉴于这种标记化是自回归 VLMs 的一个关键部分,人们可能会问:我们如何训练图像标记器?许多当前的图像标记器基于向量量化-变分自动编码器 (VQ-VAE)(Van Den Oord 等人,2017)框架,该框架将自动编码器(负责创建良好的压缩连续表示)与向量量化层(负责将连续表示映射到离散表示)结合在一起。该架构通常是一个卷积神经网络 (CNN)(LeCun 和 Bengio,1998)编码器,后面跟着一个向量量化层,再跟着一个 CNN 解码器。实际的离散化步骤发生在向量量化层,该层将编码器输出映射到学习到的嵌入表中最近的嵌入(“学习”在这里意味着嵌入表在整个训练过程中都会更新)。标记器的损失函数是像素空间中的重建损失(例如,输入和重建像素之间的 L2 距离)以及代码本承诺损失的组合,以鼓励编码器输出和代码本嵌入彼此接近。大多数现代图像标记器通过添加不同的损失或更改编码器/解码器的架构来改进这种 VQ-VAE 框架。值得注意的是,VQ-GAN(Esser 等人,2021)添加了感知损失和对抗损失(包括真实图像和重建图像之间的鉴别器),以捕获更细粒度的细节。VIT-VQGAN(Yu 等人,2022a)使用视觉 Transformer 而不是 CNN 作为编码器和解码器架构。
使用扩散模型进行似然估计。
使用扩散模型获得密度估计更具挑战性,因为它们不直接输出 pθ(x∣c)。相反,这些网络 ϵθ 通常经过训练以估计噪声图像 xt 中的噪声 ϵ。因此,基于扩散的分类技术(Li 等人,2023a;Clark 和 Jaini,2023)估计条件图像似然的(通常是重新加权的)变分下界:
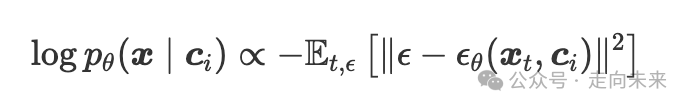
(7)
噪声预测误差越低,条件似然 pθ(x∣c) 就越高。
测量等式 (7) 中的下界依赖于重复采样以获得蒙特卡罗估计。
Li 等人(2023a)和 Clark 和 Jaini(2023)开发了减少所需样本数量的技术,动态地将样本分配给最有可能的类别,并确保添加的噪声 ϵ 在所有潜在类别中匹配。然而,即使使用这些技术,使用条件扩散模型进行分类仍然在计算上很昂贵,它随着类别的数量而扩展,并且每个测试图像需要数百或数千次网络评估。因此,虽然使用扩散模型进行分类的性能相当好,但推断在开发进一步优化之前是不切实际的。
生成式分类器的优势。
虽然使用这些生成式分类器进行推断更昂贵,但它们确实具有显著的优势。生成式分类器具有更高的“有效鲁棒性”,这意味着对于给定的分布内准确率,它们具有更好的分布外性能(Li 等人,2023a)。在像 Winoground(Thrush 等人,2022)这样的组合推理任务中,生成式分类器远远超过了像 CLIP(Li 等人,2023a;Clark 和 Jaini,2023)这样的判别方法。生成式分类器,无论是自回归的(Parti)还是基于扩散的(Imagen),已被证明具有更高的形状偏差,并且与人类判断更一致(Jaini 等人,2024)。最后,生成式分类器可以在测试时使用仅未标记的测试示例与判别模型联合适应(Prabhudesai 等人,2023)。这已被证明可以提高分类、分割和深度预测任务的性能,特别是在在线分布偏移场景中。
2.5 来自预训练主干的 VLMs
VLMs 的一个缺点是它们从头开始训练成本很高。它们通常需要数百到数千个 GPU,同时必须使用数亿个图像和文本对。因此,许多研究工作不是从头开始训练模型,而是尝试利用现有的大型语言模型和/或现有的视觉提取器。大多数这些工作都基于这样一个事实,即许多大型语言模型是开源的,因此可以轻松使用。通过利用这些模型,可以学习文本模式和图像模式之间的映射。学习这种映射使 LLMs 能够回答视觉问题,同时只需要很少的计算资源。在本节中,我们只介绍了其中两个模型,第一个是 Frozen(Tsimpoukelli 等人,2021),它是第一个利用预训练 LLMs 的模型。然后,我们介绍了 Mini-GPT 模型家族(Zhu 等人,2023a)。
2.5.1 Frozen
Frozen(Tsimpoukelli 等人,2021)是利用预训练 LLM 的模型的第一个例子。这项工作建议通过一个轻量级映射网络将视觉编码器连接到冻结的语言模型,该网络将视觉特征投影到文本标记嵌入中。视觉编码器(NF-ResNet-50(Brock 等人,2021))和线性映射是从头开始训练的,而语言模型(一个在 C4(Raffel 等人,2020)上训练的 70 亿参数 Transformer)保持冻结(这对保持预训练模型已经学习到的特征至关重要)。该模型在 Conceptual Captions(Sharma 等人,2018b)上使用简单的文本生成目标进行监督。在推理时,语言模型可以根据交织的文本和图像嵌入进行条件化。作者表明,该模型能够快速适应新任务、快速访问一般知识以及快速绑定视觉和语言元素。虽然只取得了适度的性能,但 Frozen 已经成为当前能够进行开放式多模态零样本/少样本学习的多模态 LLMs 的重要第一步。
2.5.2 MiniGPT 的示例
从 Flamingo(Alayrac 等人,2022)等模型开始,最近的趋势是训练多模态语言模型,其中输入包含文本和图像,输出包含文本(以及可选的图像)。MiniGPT-4(Zhu 等人,2023a)接受文本输入和图像输入,并生成文本输出。在 MiniGPT-4 中,使用了一个简单的线性投影层来将图像表示(使用 BLIP-2(Li 等人,2023e)中的相同视觉编码器,该编码器基于 Q-Former 和 ViT 主干)与 Vicuna 语言模型(Chiang 等人,2023)的输入空间对齐。鉴于视觉编码器和 Vicuna 语言模型已经过预训练,并作为现成的模型从先前的工作中使用,MiniGPT-4 只需要训练线性投影层,这在两轮中完成。第一轮涉及 20k 个训练步骤(批量大小为 256),对应于来自 Conceptual Caption(Sharma 等人,2018b)、SBU(Ordonez 等人,2011)和 LAION(Schuhmann 等人,2021)的约 500 万个图像-文本对。作者只使用了四个 A100 GPU 运行了大约十个小时,因为只需要训练线性投影层的参数。第二轮训练利用了高度精选的数据,以指令微调的形式进行,只需要 400 个训练步骤(批量大小为 12)。
MiniGPT-5(Zheng 等人,2023)扩展了 MiniGPT-4,以便输出可以包含与图像交织的文本。为了也生成图像,MiniGPT-5 使用了生成标记,这些标记是特殊的视觉标记,可以(通过 Transformer 层)映射到特征向量,而特征向量又可以馈送到冻结的 Stable Diffusion 2.1 模型(Rombach 等人,2021)中。作者在下游任务(例如,多模态对话生成和故事生成)上使用了监督训练。
LLMs 已经成为许多语言相关应用的通用接口,例如通用聊天机器人。受此启发,MiniGPT-v2(Chen 等人,2023b)提出通过统一的接口执行各种视觉语言任务,例如图像标注、视觉问答和对象定位。为了实现有效执行这些任务的目标,MiniGPT-v2 在训练时引入了不同任务的唯一标识符,使模型能够轻松区分每个任务指令,并有效地学习。在视觉问答和视觉定位基准上的实验结果表明,MiniGPT-v2 表现出强大的视觉语言理解能力。
2.5.3 使用预训练主干的其他流行模型
Qwen
与 MiniGPT-4 类似,Qwen-VL 和 Qwen-VL-Chat(Bai 等人,2023b)模型依赖于 LLM、视觉编码器和将视觉表示与 LLM 的输入空间对齐的机制。在 Qwen 中,LLM 从 Qwen-7B(Bai 等人,2023a)初始化,视觉编码器基于 ViT-bigG,并且使用一层交叉注意力模块将视觉表示压缩为固定长度(256)的序列,该序列被馈送到 LLM 中。
BLIP2
Li 等人(2023e)介绍了 BLIP-2,这是一个将图像作为输入并生成文本输出的视觉语言模型。它利用预训练的、冻结的模型来大大缩短训练时间:视觉编码器(例如 CLIP)生成图像嵌入,这些嵌入被映射到 LLM(例如 OPT)的输入空间中。一个相对较小的(约 1 亿到 2 亿个参数)组件称为 Q-Former 被训练用于这种映射——它是一个 Transformer,它接收固定数量的随机初始化的“查询”向量;在正向传递中,查询通过 Q-Former 中的交叉注意力与图像嵌入交互,然后是一个线性层,将查询投影到 LLM 的输入空间。
文献中还有许多其他基于预训练 LLMs 的模型。每个 LLM 最终都会扩展到 VLM 版本,这意味着关于此类主题的特定调查的范围将非常大。在本介绍中,我们的目标是介绍一些精选的模型,因为它们都依赖于学习表示之间映射的相同原理。
3 VLM 训练指南
几项工作(Henighan 等人,2020b,a)阐明了扩展对于进一步推动深度神经网络性能的重要性。受这些扩展定律的启发,最近的大多数工作都集中在增加计算量和规模以学习更好的模型。这导致了像 CLIP(Radford 等人,2021)这样的模型,该模型在 4 亿张图像上进行了训练,使用了非常高的计算预算。即使是它的相应开源实现 OpenCLIP(Ilharco 等人,2021)也是使用 256 到 600 个 GPU 训练了几天或几周,具体取决于模型的大小。然而,最近的工作(Sorscher 等人,2022)表明,可以使用数据整理管道来超越扩展定律。在本节中,我们首先讨论数据在训练模型中的重要性,并介绍一些用于创建用于训练 VLMs 的数据集的方法。然后,我们讨论从业者可能用来更有效地训练 VLMs 的常用软件、工具和技巧。由于训练 VLMs 的方法不同,我们还讨论了在特定情况下选择哪种模型。最后,我们介绍了一些关于如何改进接地(将文本与视觉线索正确映射的能力)的技巧。我们还介绍了使用人类偏好来改进对齐的技术。VLMs 通常用于阅读和翻译文本,因此我们还介绍了一些可以用来进一步推动 VLMs 的 OCR 能力的技术。最后,我们讨论了常见的微调方法。

图 2:训练 VLMs 时需要牢记的重要事项。数据是训练 VLMs 的最重要的方面之一。拥有一个多样化且平衡的数据集对于学习能够涵盖足够概念的良好世界模型至关重要。去除大型数据集内经常出现的大量重复项也很重要,这将节省大量的计算时间并降低记忆风险。此外,修剪数据也是一个重要的组成部分,因为我们要确保标题确实与图像内容相关。最后,提高标题质量对于增强 VLMs 的性能至关重要。
接地 VLMs 是另一个重要步骤,以确保 VLMs 正确地将单词与特定概念关联起来。两种常见的接地方法分别利用边界框或负标题。最后,对齐是必不可少的步骤,以确保模型生成的是从人类角度来看的预期答案。
3.1 训练数据
为了评估预训练数据集的质量,DataComp(Gadre 等人,2023)提出了一个基准,其中 CLIP 的模型架构和预训练超参数是固定的。重点是设计图像-文本数据集,在 38 个下游任务上实现强大的零样本和检索性能。DataComp 提供了多个噪声网络数据集池,从小型(128 万个)到超大型(128 亿个)图像-文本对不等。对于每个池,提出了并评估了多种过滤策略。DataComp 表明,数据修剪是训练高效且高性能 VLMs 的关键步骤。VLMs 的数据修剪方法可以分为三类:(1)消除低质量对的启发式方法;(2)利用预训练 VLMs 根据其多模态对齐对图像-文本对进行排序,丢弃对齐不良的对的引导方法;最后,(3)旨在创建多样化且平衡数据集的方法。
启发式方法:基于启发式方法的过滤器可以进一步分为单模态和多模态过滤器。单模态启发式方法包括去除文本复杂度低的标题,如通过对象、属性和动作的数量来衡量(Radenovic 等人,2023a),使用 fastText(Joulin 等人,2017)消除非英语替代文本,以及根据图像的分辨率和纵横比去除图像(Gadre 等人,2023)。多模态启发式方法包括使用图像分类器来过滤掉图像-文本对,其中图像中检测到的任何对象都不映射到任何文本标记(Sharma 等人,2018a)。此外,由于网络规模的数据集通常在图像中显示标题的一部分作为文本,因此多模态启发式方法(例如文本识别)旨在使用现成的文本识别器消除重叠度高的图像-文本对(Kuang 等人,2021)。这会导致模型学习提取高级视觉语义,而不是专注于光学字符识别,从而防止在以对象为中心和以场景为中心的下游零样本任务上表现不佳(Radenovic 等人,2023a)。
基于预训练 VLMs 的排序:CLIPScore(Hessel 等人,2021;Schuhmann 等人,2021)是最有效的修剪方法之一,它使用预训练的 CLIP 模型计算图像和文本嵌入之间的余弦相似度。然后使用该分数对图像-文本对的对齐进行排序。LAION 过滤(Schuhmann 等人,2021)使用在 4 亿个图像-文本对上预训练的 OpenAI CLIP 模型(Radford 等人,2021)来评估大型网络规模数据集的图像-文本对齐,并过滤掉 CLIPScore 最低的样本。受文本识别(Radenovic 等人,2023a)的启发,T-MARS(Maini 等人,2023)在计算 CLIPScore 之前检测并掩蔽图像中的文本区域,从而产生更准确的对齐分数。Mahmoud 等人(2024)的 Sieve 表明,通过依赖在小型但经过整理的数据集上预训练的生成式图像标注模型,可以最大程度地减少由 CLIPScore 排序导致的误报和漏报。
多样性和平衡:使用多样化且平衡的数据集预训练视觉语言模型可以增强其泛化能力(Radford 等人,2021)。为了创建这样的数据集,DataComp(Gadre 等人,2023)建议对与 ImageNet(Deng 等人,2009)等多样化且经过整理的数据集在语义上相似的图像-文本对进行采样。基于文本的采样保留了标题与 ImageNet 类别之一重叠的图像-文本对。同时,基于图像的采样方法使用 OpenAI CLIP ViT-L/14 视觉编码器对噪声网络规模图像进行编码,并使用 FAISS(Johnson 等人,2019)将图像聚集成 100,000 个组。随后,使用 ImageNet 训练样本的嵌入来选择与每个样本最接近的聚类。虽然这种方法可以产生多样化的数据集,但对与 ImageNet 图像在语义上相似的图像进行采样可能会使 CLIP 模型产生偏差,从而可能限制其对新下游任务的泛化。MetaCLIP(Xu 等人,2024)利用来自维基百科/WordNet 的 500,000 个查询作为元数据来创建预训练数据分布,该分布涵盖了广泛的概念。
他们的“平衡”采样算法(类似于 Radford 等人(2021)中描述的算法)旨在通过将每个查询的样本数量限制为 20,000 来在表示良好的概念和表示不足的概念之间取得平衡。尽管如此,由于网络数据的自然长尾分布,收集一个完全平衡的数据集是不切实际的。因此,所有这些 CLIP 变体在不同的下游视觉概念上仍然表现出不平衡的性能(Parashar 等人,2024)。
拥有广泛的训练数据概念似乎是 VLMs 的“零样本能力”背后的最重要的组成部分之一。实际上,Udandarao 等人(2024)表明,VLMs 的零样本性能主要取决于这些零样本下游概念在训练数据中出现的程度。
3.1.1 使用合成数据改进训练数据
一类研究侧重于通过过滤和合成数据生成来提高 VLMs 训练数据的质量,从而改进标题。具体来说,Bootstrapping Language-Image Pre-training (BLIP)(Li 等人,2022b)通过生成合成样本并过滤掉噪声标题来执行引导。随后,在 Santurkar 等人(2022)中,作者利用 BLIP 来近似标题的描述性,并表明在由 BLIP 生成的连贯且完整的合成标题上训练的模型优于在人工编写的标题上训练的模型。Nguyen 等人(2023)使用大型图像标注模型(如 BLIP2(Li 等人,2023e))用描述性的合成标题替换对齐不良的替代文本标签。他们证明了使用真实和合成标题的混合进行预训练 CLIP 是有效的。但是,他们还表明,在规模上,合成标题提供的改进受到生成标题的多样性有限的限制,而噪声文本标签的多样性很高。最近,Chen 等人(2024)证明,通过使用Large Language-and-Vision Assistant (LLaVA)(Liu 等人,2023d,c,2024a)作为标注模型,可以非常有效地训练文本到图像的生成模型。
受大型扩散模型(Rombach 等人,2022;Dai 等人,2023)的巨大进步的启发,并考虑到在其他应用(如分类(Hemmat 等人,2023;Azizi 等人,2023;Bansal 和 Grover,2023))中使用合成图像样本的潜力,另一类研究是使用来自文本到图像生成模型的生成图像。Tian 等人(2023b)证明了使用合成数据与仅使用合成样本的 CLIP(Radford 等人,2021)和 SimCLR(Chen 等人,2020)相比,性能有所提高。具体来说,他们使用同一文本提示的多个合成样本作为对比表示学习目标的多正样本对。此外,SynCLR(Tian 等人,2023a)和 SynthCLIP(Hammoud 等人,2024)也训练了 VLM,没有任何真实数据点,只利用合成样本。他们使用 LLM 生成标题,然后将标题提供给文本到图像模型,以根据这些标题生成图像。
3.1.2 使用数据增强
我们可以像自监督视觉模型一样利用数据增强吗?SLIP(Mu 等人,2022)通过在视觉编码器上引入一个辅助自监督损失项来解决这个问题。与 SimCLR(Chen 等人,2020)一样,输入图像用于生成两个增强,这些增强创建了一个正样本对,与批次中的所有其他图像进行对比。这种添加的开销相当小,同时提供了一个正则化项,可以改进学习到的表示。但是,仅对视觉编码器使用 SSL 损失并不能完全利用来自文本的重要信号。为此,CLIP-rocket(Fini 等人,2023)建议将 SSL 损失转换为跨模态。特别是,它表明 CLIP 对比损失可以在存在图像-文本对的多个增强的情况下使用,并且优于其他受 SSL 启发的非对比替代方案,例如 Grill 等人(2020),Caron 等人(2020)和 Zbontar 等人(2021)。在 CLIP-rocket 中,输入图像-文本对以非对称的方式进行增强,一个弱增强集和一个强增强集。两个生成的增强对使用标准 CLIP 编码器进行嵌入,然后使用两个不同的投影器投影到多模态嵌入空间。弱增强对的投影器保持与原始 CLIP 中相同,即线性层,而强增强对的投影器是 2 层 MLP,以应对更嘈杂的嵌入。正如 Bordes 等人(2022)所强调的那样,将两个投影器分开至关重要,因为强投影器正在学习更不变的、过于不变的表示,以用于下游任务。在推理时,弱和强学习的表示进行插值以获得单个向量。
3.1.3 交织数据整理
像 Flamingo(Alayrac 等人,2022)和 MM1(McKinzie 等人,2024)这样的自回归语言模型已经表明,在训练期间包含交织的文本和图像数据可以提高模型的少样本性能。用于预训练的交织数据集通常是从互联网上抓取的,并且经过整理以提高质量和安全性。可以使用两种类型的整理策略来收集交织数据集:
自然交织数据:
Open Bimodal Examples from Large fIltered Commoncrawl Snapshots (OBELICS)(Laurençon 等人,2023)数据集是这类数据集的一个很好的例子;OBELICS 通过保留文本和图像在网络文档中共同出现的内在结构和上下文来构建,从而提供对多模态网络内容更真实的表示。使用多个整理步骤来整理此数据集,其中从 common crawl 收集英语数据并进行去重,然后对 HTML 文档进行预处理,识别和保留有用的 DOM 节点,然后对于每个 DOM 节点,我们应用图像过滤以去除徽标,然后应用段落,我们使用各种启发式方法应用文档级文本过滤来处理格式不正确或不连贯的文本。
合成交织数据:MMC4(Zhu 等人,2023b)是这类数据集的一个很好的例子,其中仅文本数据集通过从互联网上收集的图像进行改造,在此过程中,图像与文本根据上下文相关性进行配对,这可以通过计算基于 CLIP 的相似度分数来实现。这种方法提供了一种方法,可以将现有的庞大文本语料库改造为视觉信息,从而扩展其在多模态学习中的效用。虽然这种方法可能缺乏自然交织数据集的上下文细微差别,但它允许从完善的仅文本资源中可扩展地创建多模态数据。
3.1.4 评估多模态数据质量
在 VLMs 方面,一个非常活跃的研究领域是识别用于训练它的基础数据的质量。由于质量是一个主观指标,因此很难预先确定什么构成训练这些模型的良好数据。以前的作品,如 Flamingo(Alayrac 等人,2022),MM1(McKinzie 等人,2024)和 OBELICS(Laurençon 等人,2023)已经证明,高质量的交织多模态数据是这些 VLM 模型获得最佳性能的关键要求,这使得以快速且可扩展的方式量化数据的质量变得至关重要。质量本身可以在多个方面进行评估,包括文本本身的质量、图像本身的质量以及图像和文本之间的对齐信息。像 QuRating(Wettig 等人,2024),Data efficient LMs(Sachdeva 等人,2024)和基于文本质量的修剪(Sharma 等人,2024)等方法已经探索了量化文本数据质量的方法,并使用这些方法以数据高效的方式识别高质量数据子集来训练 LM 模型。类似地,像 VILA(Ke 等人,2023)和 LAION-aesthetics(Schuhmann,2023)等方法试图量化图像的美学质量,以选择高质量的图像数据子集来改进图像生成模型。对于对齐,CLIP 系列方法(Radford 等人,2021;Xu 等人,2024;Gao 等人,2024)一直是评估文本数据相对于提供的图像的一致性的首选模型。尽管在评估文本、图像和对齐质量方面有一些相关的工作,但我们缺乏一种评估多模态和交织数据质量的整体方法,这仍然是一个活跃的研究领域,以进一步改进 VLM 模型的训练。
3.1.5 利用人类专业知识:数据标注的力量
近年来,在视觉语言建模领域,利用人类数据标注的重要性日益显现。这种方法涉及战略性地选择图像,并让人类提供标签或描述,以捕捉视觉元素和语言之间的错综复杂的关系。通过从更微妙和更详细的信息中学习,模型可以更好地理解复杂的场景并生成更准确的描述。尽管有几个流行的多模态数据集可用,例如 OKVQA(Marino 等人,2019),A-OKVQA(Schwenk 等人,2022),Image Paragraph Captioning(Krause 等人,2017),VisDial(Das 等人,2017),Visual Spatial Reasoning(Liu 等人,2023a)和 MagicBrush(Zhang 等人,2024b),但其中许多依赖于较旧的图像基准,如 COCO(Lin 等人,2014)或 Visual Genome(Krishna 等人,2017),这突出了对更多样化和当代图像来源的需求。最近,Urbanek 等人(2023)介绍了 DCI 数据集,其中包含来自 SA-1B 数据集(Kirillov 等人,2023)的一些图像的细粒度人类标注。人类标注数据的局限性在于,获取它通常成本很高,尤其是在请求细粒度标注时。因此,具有高度详细标注的图像数量通常很少,这使得这些数据集通常更适合于评估或微调,而不是用于大规模预训练。
微信公众号“走向未来”专注于人工智能技术、产品和应用,欢迎扫码关注。

3.2 软件
在本节中,我们将讨论一些现有的软件,人们可以利用这些软件来评估和训练 VLMs,以及训练它们所需的资源。
3.2.1 使用现有的公共软件库
存在一些软件,如 OpenCLIP (https://github.com/mlfoundations/open_clip) 或 transformers (https://github.com/huggingface/transformers),它们实现了大多数 VLMs。当进行基准测试或比较不同的模型时,这些工具非常有用。如果一个人的目标是尝试在给定的下游任务上比较不同的预训练 VLM,那么这些软件提供了一个很好的平台来做到这一点。
3.2.2 我需要多少个 GPU?
关于所需计算资源的问题非常重要,因为它将主要决定训练此类模型所需的预算。CLIP(Radford 等人,2021)和 OpenCLIP(Ilharco 等人,2021)已经利用了 500 多个 GPU 来训练他们的模型。当查看此类资源的公共云价格时,它们相当于数十万美元,这对大多数公司或学术实验室来说是无法承受的。但是,当使用正确的成分(例如拥有高质量的数据集,并在使用更大的模型时利用掩蔽策略)时,从头开始在数亿张图像上训练像 CLIP 这样的对比模型不需要超过 64 个 GPU(这应该相当于在计算方面花费大约 10,000 美元)。如果用于训练的 VLM 利用现有的预训练图像或文本编码器或 LLM,那么学习映射的成本应该低得多。
3.2.3 加速训练
最近出现了软件开发,例如 PyTorch 团队推出的 torch.compile(https://pytorch.org/tutorials/intermediate/torch_compile_tutorial.html),它显著加快了模型训练速度。通过使用更高效的注意力机制,xformers 库(Lefaudeux 等人,2022)也经常被用来进一步加速。然而,在训练视觉模型时,有一个方面经常被忽视,那就是数据加载。由于必须加载大型图像小批量,数据加载通常成为一个瓶颈,显著减慢训练速度。此外,由于空间限制,大型数据集通常保存在必须动态解压缩的 tar 文件块中(因此减慢训练速度)。我们主要建议尽可能多地存储未压缩文件以加快训练速度。此外,可以使用Fast Forward Computer Vision (FFCV)库(Leclerc 等人,2023)来创建加载速度更快的数据文件。使用 FFCV 而不是 webdataset 可以显著加快 VLM 训练速度。使用 webdataset 或 FFCV 存储未压缩文件的唯一缺点是,存储成本可能比存储压缩文件更高。但是,由于训练速度会快得多,额外的存储成本应该会很快被所需的计算量减少所抵消。
掩蔽。
掩蔽是快速提高大型模型训练效率的另一种方法。当使用具有数亿或数十亿参数的模型时,单个前向和反向传递的成本可能很高。Li 等人(2023f)表明,通过随机掩蔽图像标记,可以显著加快训练时间,同时提高模型性能。
3.2.4 其他超参数的重要性。
McKinzie 等人(2024)研究了训练 VLMs 的最重要的设计选择,表明图像分辨率、视觉编码器容量和视觉预训练数据是影响模型性能最大的选择。他们还表明,虽然连接模态的方法有很多,但这种选择并不那么重要。作者还讨论了各种类型训练数据的重要性,从仅文本数据到交织数据和图像-标题配对数据,证明了正确的组合在零样本分类和视觉问答任务中都实现了最佳性能。
3.3 使用哪个模型?
正如本介绍的第一部分所强调的那样,训练 VLMs 的方法有很多。其中一些利用简单的对比训练标准,另一些使用掩蔽策略来预测缺失的文本或图像块,而一些模型使用生成范式,如自回归或扩散。还可以利用预训练的视觉或文本主干,如 Llama 或 GPT。在这种情况下,构建 VLM 模型只需要学习 LLM 和视觉编码器表示之间的映射。那么,从所有这些方法中,应该选择哪一种?我们需要像 CLIP 一样从头开始训练视觉和文本编码器,还是从预训练的 LLM(如 Flamingo 或 MiniGPT)开始更好?
3.3.1 何时使用像 CLIP 这样的对比模型?
像 CLIP 这样的对比模型将文本与视觉概念相关联,同时通过将文本和图像表示推向在表示空间中匹配来保持简单的训练范式。通过这样做,CLIP 学习了在图像和文本空间中都具有意义的表示,这使得可以使用单词提示 CLIP 文本编码器,以便我们可以检索映射到相应文本表示的图像。例如,许多数据整理管道,如 MetaCLIP(Xu 等人,2024)使用元数据字符串匹配来构建数据集,以确保每个单词或概念都有足够的图像与之关联。CLIP 模型也是构建更复杂模型的良好基础,尤其是在尝试改进接地时。对于希望尝试其他训练标准或不同模型架构以更好地捕捉关系或更好地理解概念的研究人员来说,CLIP 是一个特别好的起点。但是,应该记住,CLIP 不是一个生成模型,因此无法根据特定图像生成标题。只能从已有的标题列表中检索最佳标题。因此,当前的 CLIP 模型无法用于提供给定图像的高级描述。另一个缺点是,CLIP 通常需要非常大的数据集以及大型批次大小才能提供不错的性能,这意味着 CLIP 通常需要大量资源才能从头开始训练。
3.3.2 何时使用掩蔽?
掩蔽是训练 VLMs 的另一种策略。通过学习从掩蔽的图像和文本中重建数据,可以联合建模它们的分布。与在表示空间中运行的对比模型相比,基于掩蔽的模型可能需要利用解码器将表示映射回输入空间(从而应用重建损失)。训练额外的解码器可能会增加额外的瓶颈,这可能会使这些方法效率低于纯粹的对比方法。但是,优点是不再有批次依赖性,因为每个示例都可以单独考虑(因为我们不需要负样本)。去除负样本可以实现使用更小的迷你批次,而无需微调其他超参数,例如 softmax 温度。许多 VLM 方法利用掩蔽策略与一些对比损失的混合。
3.3.3 何时使用生成模型?
基于扩散或自回归标准的生成模型在根据文本提示生成逼真的图像方面表现出令人印象深刻的能力。大多数关于 VLM 的大规模训练工作也开始整合图像生成组件。一些研究人员认为,能够根据单词生成图像是朝着创建良好世界模型迈出的重要一步,而其他研究人员则认为这种重建步骤是不必要的(Balestriero 和 LeCun,2024)。但是,从应用的角度来看,当模型能够将抽象表示解码到输入数据空间中时,可能更容易理解和评估模型学到了什么。也可以在经过训练的联合嵌入架构之上学习解码器(Bordes 等人,2022)。虽然像 CLIP 这样的模型需要使用数百万个图像数据点进行广泛的 k-NN 评估才能显示与给定词嵌入最接近的图像是什么样子,但生成模型可以直接输出最可能的图像,而无需如此昂贵的管道。此外,生成模型可以学习文本和图像之间的隐式联合分布,这可能比利用预训练的单模态编码器更适合学习良好的表示。但是,它们的训练成本比对比学习对应模型更高。
3.3.4 何时使用预训练主干上的 LLM?
当访问的资源有限时,使用已经预训练的文本或视觉编码器可能是一个不错的选择。在这种情况下,只需要学习文本表示和视觉表示之间的映射。但是,这种方法的主要问题是,VLM 会受到 LLM 潜在幻觉的影响。它也可能受到预训练模型带来的任何偏差的影响。因此,在尝试纠正视觉模型或 LLM 的缺陷时,可能需要额外的开销。有些人可能会认为,利用独立的图像和文本编码器将信息投影到我们可以学习映射的低维流形中很重要,而另一些人可能会认为,联合学习图像和文本的分布很重要。总而言之,当访问的计算资源有限,并且研究人员对学习表示空间中的映射感兴趣时,利用预训练模型很有趣。
3.4 改进接地
接地是 VLM 和生成模型文献中的一个重要挑战。它主要旨在解决模型无法很好地理解文本提示的问题,这会导致忽略提示的一部分,或者产生甚至不是提示的一部分的内容。其中一些挑战与理解关系有关,例如对象在左侧或右侧、否定、计数或理解属性(如颜色或纹理)。改进接地是一个活跃的研究领域,目前还没有一种简单的方法可以解决这个问题。尽管如此,在本节中,我们将介绍一些通常用于改进接地性能的技巧。
3.4.1 使用边界框标注
像 X-VLM(Zeng 等人,2022)这样的模型利用边界框标注,并结合框回归和Intersection over Union (IoU)损失来准确地定位和将视觉概念与其相应的文本描述对齐。通过了解对象在图像上的位置以及与每个对象关联的标题,模型更容易将文本与正确的视觉线索关联起来,从而提高接地。
X-VLM 在一个综合的数据集集合上进行训练,包括 COCO(Lin 等人,2014),Visual Genome(Krishna 等人,2017),SBU 和 Conceptual Captions(Changpinyo 等人,2021),总计多达 1600 万张图像。这个包含边界框标注的广泛训练数据目录使 X-VLM 能够在各种视觉语言任务(如图像-文本检索、视觉推理、视觉接地和图像标注)中胜过现有方法。
一些方法(如 Kosmos-2(Peng 等人,2024))不是使用已经标注的数据,而是依赖于公共模型来创建自己的图像-文本数据集。他们通过首先使用 spaCy(Honnibal 和 Montani,2017)从文本标题中提取名词,然后使用接地模型 GLIP(Li 等人,2022c)来预测与从标题中提取的名词相关的边界框,从而从网络抓取数据中创建网络规模的接地图像-文本对。然后,他们使用 spaCy 提取与给定单词相关的表达式,以便生成可以与检测到的每个边界框关联的标题。这样做可以实现使用非常大型的网络标注数据集。但是,这种方法受到边界框检测接地模型强度的限制。如果这个基础模型在一些罕见的名词或实例上失败,下游模型可能会犯类似的错误。
3.4.2 负标题
对比目标中的负样本已被广泛用于减轻崩溃、增强泛化和区分性特征学习(Chen 等人,2020;Liu 等人,2023c;Grill 等人,2020;He 等人,2020;Caron 等人,2021)。通过将正样本对(相似或相关样本)与负样本对(不相似或不相关样本)进行对比,模型被迫对数据进行细致入微的理解,超越仅仅的表面特征,以掌握区分不同类别或类别的潜在模式。
同样,最近关于 VLMs 的研究表明,类似的技术(负样本)可以被用来减轻视觉语言模型中的各种问题(Yuksekgonul 等人,2023;Li 等人,2021;Goel 等人,2022;Radenovic 等人,2023b)。例如,ARO 基准(Yuksekgonul 等人,2023)评估 VLMs 在将图像与标题正确关联方面的能力,使用负样本测试模型对不正确或无意义配对的理解。这种方法表明,VLMs 可以从接触负样本所培养的细致入微的区分能力中获益匪浅,从而产生更准确、更具上下文意识的模型。
3.5 改进对齐
受语言领域指令微调成功的启发(Chung 等人,2024),视觉语言模型也开始在视觉语言模型中整合指令微调和Reinforcement Learning from Human Feedback (RLHF),以提高多模态聊天能力,并将输出与所需响应对齐。
指令微调涉及在包含指令、输入和所需响应的监督数据上微调视觉语言模型。通常,指令微调数据集比预训练数据小得多——指令微调数据大小范围从几千到十万个样本(有关指令微调的进一步讨论,请参见 Li 等人(2023d))。LLaVa、InstructBLIP(Liu 等人,2023d)和 OpenFlamingo(Awadalla 等人,2023)是三个整合了指令微调的突出视觉语言模型。
RLHF 也旨在使模型输出与人类偏好保持一致。
对于 RLHF,训练奖励模型以匹配人类对人类认为好的或坏的模型响应的偏好。
虽然指令微调需要监督训练样本,而收集这些样本可能很昂贵,但 RLHF 利用辅助奖励模型来模拟人类偏好。
然后,主要模型(无论是仅语言模型还是视觉语言模型)都使用奖励模型进行微调,以使输出与人类偏好保持一致。LLaVa-RLFH 是一个突出的例子,它整合了 RLHF 来改进视觉语言模型的输出与事实信息的对齐(Sun 等人,2023)。
3.5.1 LLaVA 故事
受语言领域指令微调成功的启发,LLaVA(Liu 等人,2023d)是第一个在视觉语言模型中整合指令微调以提高多模态聊天能力的模型之一。
作者为微调生成了 150,000 个合成生成的视觉指令样本。原始 LLava 模型整合了预训练的 Vicuna 语言模型编码器和预训练的 CLIP ViT-L/14 视觉编码器。编码器输出使用线性投影器融合到相同维度的空间中。除了改进的定性聊天交互之外,LLaVA 还显示了在合成指令遵循和 Science QA 基准(Lu 等人,2022)上的改进。
LLaVA 1.5
Liu 等人(2023c)通过使用跨模态全连接多层感知器 (MLP) 层并整合学术 VQA 指令数据来改进 LLava 的指令微调。LLava 1.5 在 600,000 个图像-文本对上进行训练,与其他指令微调模型(如 InstructBLIP 或 Qwen-VL)相比,训练效率更高。训练在大约 8 个 A100 GPU 上大约需要一天时间。LLava 1.5 在一系列学术 VQA 和指令遵循基准上表现良好。
LLaVA-RLHF
由于用于视觉语言模型训练的高质量视觉指令微调数据的稀缺性,VLLMs(如 LLaVA(Liu 等人,2023d))可能会使视觉和语言模态不对齐,并生成幻觉输出。为了解决这个问题,提出了 LLaVA-RLHF(Sun 等人,2023),以使用一种新颖的RLHF 算法——事实增强 RLHF(Factually Augmented RLHF)——来改进多模态对齐。这个想法是基于将 RLHF 从文本领域调整到视觉语言任务,并使用图像标题和真实多项选择题的额外事实信息来增强奖励模型,以减少奖励作弊。LLaVA-RLHF 还使用 GPT4 生成的训练数据和人工编写的图像-文本对来进一步提高其通用能力。在 LLaVA-Bench 上,LLaVA-RLHF 达到了 GPT-4(Achiam 等人,2023)的 94% 性能水平。在 MMHAL-BENCH 上,特别关注惩罚幻觉,LLaVA-RLHF 比基线模型高出 60%。
LLaVA-NeXT (v1.6)
LLaVA-NeXT(Liu 等人,2024a)在几个方面改进了 LLaVA-v1.5。首先,通过将来自完整图像和较小图像块的视觉特征连接起来来提高图像分辨率,这些特征分别通过视觉编码器馈送。其次,视觉指令微调数据混合通过更好的视觉推理、OCR、世界知识和逻辑推理示例得到改进。第三,最大的模型变体使用 340 亿参数的 LLM 主干(Nous-Hermes-2-Yi-34B)。与 CogVLM(Hong 等人,2023;Wang 等人,2023b)或 Yi-VL(AI 等人,2024)等开源多模态 LLM 相比,LLaVA-NeXT 实现了最先进的性能,并缩小了与 Gemini Pro(Reid 等人,2024)等商业模型的差距。
3.5.2 多模态上下文学习
Otter(Li 等人,2023c)表明多模态上下文学习是可能的:提供一些示例(例如,指令-图像-答案元组)作为上下文,模型可以在测试示例中成功遵循指令,而无需额外的微调。这种能力类似于仅文本的 LLM 上下文学习。多模态上下文学习能力可以归因于在最近提出的多模态指令微调数据集 MIMIC-IT(Li 等人,2023b)上进行微调,该数据集包含大约 280 万个包含上下文示例的多模态指令-响应对。MIMIC-IT 中的每个样本都包含上下文指令-图像-答案元组以及一个测试示例(其中给定指令和图像,目标是在测试示例中生成答案)。上下文元组以三种方式之一与测试示例相关:(1)上下文指令相似,但图像不同;(2)图像相同,但指令不同;(3)图像按顺序排列,但指令不同,其中顺序图像取自 Yang 等人(2023)等视频库。在 MIMIC-IT 上微调 OpenFlamingo(Awadalla 等人,2023)会生成模型 Otter,而 Otter 表现出更强的指令遵循能力以及多模态上下文学习能力。
3.6 改进富文本图像理解
理解文本是我们日常生活中视觉感知的关键方面。多模态大语言模型Multimodal Large Language Models (MLLMs)的成功为 VLMs 在零样本任务中处理非凡应用铺平了道路,这些应用被转移到许多现实世界场景中。Liu 等人(2023e)表明,MLLMs 天然地表现出出色的零样本Optical Character Recognition (OCR)性能,无需在 OCR 领域特定数据上明确训练。但是,当遇到数据类型之间复杂的关联关系时,这些模型通常难以解释图像中的文本,这可能是由于其训练数据中自然图像的普遍存在(例如,Conceptual Captions(Changpinyo 等人,2021)和 COCO(Lin 等人,2014)。文本理解和解决这些问题的模型的一些常见(非详尽)挑战:
使用细粒度富文本数据进行指令微调:LLaVAR(Zhang 等人,2023c)
为了解决理解图像中文本细节的问题,LLavaR 使用电影海报和书籍封面等富文本图像来增强当前的视觉指令微调管道。作者使用公开可用的 OCR 工具从 LAION 数据集(Schuhmann 等人,2022)中收集了 422,000 张富文本图像的结果。然后,他们使用识别的文本和图像标题提示仅文本的 GPT-4(Achiam 等人,2023)来生成 16,000 个对话,每个对话都包含针对富文本图像的问答对。通过将这些收集到的数据与以前的多模态指令遵循数据相结合,LLaVAR 模型能够大幅提高 LLaVA 模型(Liu 等人,2023d)的能力。在基于文本的 VQA 数据集上,准确率提高了 20%,在自然图像上略有提高。
处理高分辨率图像中的细粒度文本:Monkey(Li 等人,2023h)
目前,大多数 MM-LLMs 的输入图像分辨率限制为 224 x 224,与它们架构中使用的视觉编码器的输入大小一致。
这些模型难以在复杂的以文本为中心的任务中提取详细信息,例如场景文本为中心的视觉问答 (VQA)、面向文档的 VQA 和关键信息提取 (KIE),这些任务具有高分辨率输入和详细的场景理解。为了解决这些挑战,引入了一种新方法 Monkey(Li 等人,2023h)。
Monkey 的架构旨在通过使用滑动窗口方法以统一的块处理输入图像来增强 LLM 的能力,每个块都与经过良好训练的视觉编码器原始训练中使用的大小相匹配。每个块由静态视觉编码器独立处理,并通过 LoRA 调整和可训练的视觉重采样器进行增强。这使得 Monkey 能够处理高达 1344×896 像素的更高分辨率,从而能够详细捕获复杂的视觉信息。它还采用了一种多级描述生成方法,丰富了场景-对象关联的上下文。这种两部分策略确保更有效地从生成的数据中学习。通过整合这些系统的独特功能,Monkey 提供了一种全面且分层的字幕生成方法,捕获了广泛的视觉细节。
解耦的场景文本识别模块和 MM-LLM:Lumos(Shenoy 等人,2024)
Lumos 提出了一种具有文本理解能力的多模态助手,它利用了设备上和云计算的结合。
Lumos 使用一个解耦的场景文字识别Scene text recognition (STR)模块,然后馈送到多模态 LLM。Lumos 的 STR 模块包含四个子组件:Region of Interest (ROI)检测、文本检测、文本识别和阅读顺序重建。ROI 检测有效地检测视觉中的显着区域,然后将显着区域裁剪为 STR 输入。文本检测以来自 ROI 检测的裁剪图像作为输入,检测单词,并输出每个单词的识别边界框坐标。文本识别以来自 ROI 检测的裁剪图像和来自文本检测的单词边界框坐标作为输入,并返回识别的单词。阅读顺序重建根据布局将识别的单词组织成段落,并在每个段落中按阅读顺序排列。
云端托管了一个多模态 LLM 模块,该模块接收来自 STR 模块的识别文本和坐标。这个解耦的 STR 模块可以在设备上运行,减少了将高分辨率图像传输到云端的功耗和延迟。如上所述,一个关键的挑战是由于 LLM 编码器的限制而无法捕获场景中的细粒度文本。Lumos 的 STR 模块在 3kx4k 大小的图像上运行,这将类似于 Monkey 在复杂的文本理解任务中产生增强的性能。
3.7 参数高效微调
训练 VLMs 在跨域视觉和语言任务中显示出极大的有效性。然而,随着预训练模型规模的不断增长,由于计算限制,微调这些模型的整个参数集变得不切实际。为了解决这一挑战,开发了参数高效微调Parameter-Efficient Fine-Tuning (PEFT)方法来解决与微调大规模模型相关的计算成本高昂问题。这些方法侧重于训练参数子集,而不是整个模型,以适应下游任务。现有的 PEFT 方法可以分为四个主要类别,即低秩适配器Low Rank Adapters (LoRa)方法、基于提示的方法、基于适配器的方法和基于映射的方法。
基于 LoRA 的方法。
LoRA(Hu 等人,2022)被认为是参数微调的流行方法。LoRA 可以应用于纯语言模型和视觉语言模型。已经开发了 LoRA 的几个变体来增强其功能和效率。其中一个变体是 QLoRA(Dettmers 等人,2023),它将 LoRA 与量化主干集成,并能够将梯度反向传播通过冻结的 4 位量化预训练语言模型到 LoRA 中。
另一个变体是 VeRA(Kopiczko 等人,2024),它旨在减少与 LoRA 相比的可训练参数数量,同时保持等效的性能水平。这是通过利用跨所有层共享的单个低秩矩阵对,并学习小的缩放向量来实现的。最后,DoRA(Liu 等人,2024b)将预训练权重分解为两个部分,幅度和方向,用于微调。DoRA 通过实证实验证明了将低秩适应方法从语言模型推广到视觉语言基准的能力。
基于提示的方法。
视觉语言预训练过程涉及在共享特征空间中对齐图像和文本,从而能够通过提示将零样本转移到后续任务。因此,另一种高效微调方法与提示相关联。
Zhou 等人(2022)介绍了上下文优化( Context Optimization,CoOp),这是一种旨在适应大型预训练视觉语言模型(如 CLIP)以用于下游图像识别任务的技术,无需手动提示工程。CoOp 在训练过程中使用可学习向量优化提示的上下文词。该方法提供了两种实现:统一上下文和特定于类的上下文。
来自 11 个数据集的实验结果表明,CoOp 在少样本学习中优于手工制作的提示和线性探测模型。此外,与使用手动提示的零样本模型相比,它表现出更强的域泛化能力。
然后,Jia 等人(2022)提出了视觉提示微调 (VPT),用于适应视觉中的大规模 Transformer 模型。与更新所有主干参数的传统方法相反,VPT 在输入空间中引入了最少数量(不到模型参数的 1%)的可训练参数。这是在保持模型主干冻结的情况下实现的,并且在许多情况下。VPT 表现出与完全微调相当甚至更好的准确率。
基于适配器的方法。
适配器是指添加到预训练网络层之间的新模块(Houlsby 等人,2019)。具体来说,在视觉语言模型领域,CLIP-Adapter(Gao 等人,2024)在视觉或语言分支上使用特征适配器进行微调。它采用了一个额外的瓶颈层来学习新特征,并对原始预训练特征执行残差式特征混合。此外,VL-adapter(Sung 等人,2022)在一个统一的多任务框架内评估了各种基于适配器的方法,涵盖了各种图像-文本和视频-文本基准任务。该研究进一步深入探讨了任务之间权重共享的概念,作为增强这些适配器效率和性能的策略。实证结果表明,将权重共享技术与适配器结合使用可以有效地与完全微调的性能相媲美,同时只需要更新总参数的一小部分(图像-文本任务为 4.18%,视频-文本任务为 3.39%)。
随后,LLaMA-Adapter V2(Gao 等人,2023)提出了一种参数高效的视觉指令模型,该模型增强了大型语言模型的多模态推理能力,而无需大量的参数或多模态训练数据。它建议解锁更多可学习参数(例如,范数、偏差和比例)以及一种早期融合方法,将视觉标记合并到 LLM 层中。与 MiniGPT-4 和 LLaVA 等其他完全微调方法相比,LLaMA-Adapter V2 涉及的额外参数要少得多。
基于映射的方法。
通过适配器或 LoRA 将可训练模块注入预训练模型需要了解网络的架构,以决定在何处插入或调整参数。在 VLMs 的背景下,Mañas 等人(2023)和 Merullo 等人(2022)提出了一种更简单的方法,该方法只需要训练预训练单模态模块(即视觉编码器和 LLM)之间的映射,同时保持它们完全冻结且没有适配器层。此外,这种方法需要更少的可训练参数,并导致更高的数据效率(Vallaeys 等人,2024)。LiMBeR(Merullo 等人,2022)使用一个线性层将视觉特征投影到与 LLM 隐藏状态维度相同的维度。这种投影独立地应用于每个特征向量,这意味着传递到 LLM 的序列长度与视觉特征向量的数量相同,从而增加了训练和推理的计算成本。MAPL(Mañas 等人,2023)设计了一个映射网络,通过将视觉特征向量聚合到更小的集合中来解决这个问题。输入特征向量被投影并连接到一个可学习的查询标记序列,并且只有查询标记的输出被馈送到 LLM。
4 负责任的 VLM 评估方法
由于 VLMs 的主要能力是将文本与图像映射,因此衡量视觉语言能力至关重要,以确保单词实际上映射到视觉线索。早期用于评估 VLMs 的任务是图像字幕和视觉问答Visual Question Answering (VQA)(Antol 等人,2015)。在本节中,我们还将讨论以文本为中心的 VQA 任务,该任务评估模型理解和读取图像中文本的能力。Radford 等人(2021)引入的另一种常见评估方法基于零样本预测,例如 ImageNet(Deng 等人,2009)分类任务。此类分类任务对于评估 VLM 是否具有足够的常识知识非常重要。最近的基准测试,例如 Winoground(Thrush 等人,2022),衡量视觉语言组合推理。由于 VLM 模型已知会显示偏差或幻觉,因此评估这两个组件非常重要。

图 3:评估 VLMs 的不同方法。视觉问答 (VQA) 一直是最常用的方法之一,尽管模型和真实答案通过精确字符串匹配进行比较,这可能会低估模型的性能。推理包括向 VLMs 提供一个字幕列表,并使其从该列表中选择最可能的字幕。此类别中两个流行的基准测试是 Winoground(Diwan 等人,2022)和 ARO(Yuksekgonul 等人,2023)。最近,密集的人工标注可用于评估模型将字幕映射到图像正确部分的能力(Urbanek 等人,2023)。最后,可以使用 PUG(Bordes 等人,2023)等合成数据以不同配置生成图像,以评估 VLM 对特定变化的鲁棒性。
4.1 基准测试视觉语言能力
评估 VLMs 的第一种方法是利用视觉语言基准测试。这些基准测试的设计方式旨在评估 VLMs 是否能够将特定单词或短语与相应的视觉线索相关联。这些基准测试处于 VLM 评估的最前沿,因为它们评估了视觉语言映射学习的程度。从视觉问答到零样本分类,有许多方法经常用于评估 VLMs。其中一些方法侧重于检测简单的视觉线索,例如“图像中是否可见一只狗?”,到更复杂的场景,在这些场景中,我们将尝试评估 VLM 是否能够对诸如“图像中有多少只狗,它们在看什么?”之类的问题给出正确答案。通过从突出显示清晰视觉线索的简单字幕开始,到需要一定程度的空间理解和推理的更复杂字幕,这些基准测试使我们能够评估大多数 VLMs 的优势和劣势。
4.1.1 图像字幕
由 Chen 等人(2015)引入的 COCO 字幕数据集和挑战评估了给定 VLM 生成的字幕质量。通过利用外部评估服务器,研究人员可以将模型生成的字幕发送到服务器,并由服务器使用 BLEU(Papineni 等人,2002)或 ROUGE(Lin,2004)等分数将生成的字幕与一组参考字幕进行比较。但是,此类分数仍然是试图近似这些字幕相似性的启发式方法。许多工作主张放弃 BLEU 等分数,例如 Mathur 等人(2020)。
为了避免必须将字幕与一组参考字幕进行比较的问题,Hessel 等人(2021)引入了 CLIPScore,该分数利用 CLIP 来预测字幕与图像的接近程度。分数越高,字幕越有可能真正描述图像内容。但是,CLIPScore 有一个很大的局限性,那就是所用 CLIP 模型的底层性能。
4.1.2 文本到图像一致性
除了评估为给定图像生成字幕的能力之外,人们可能还想评估在给定字幕的情况下生成图像的能力。
有一些端到端方法使用单个模型来生成一致性分数。尽管最初是为图像字幕提出的,但 CLIPScore 也用于图像生成,以衡量生成的图像与文本提示之间的对齐程度。
Lin 等人(2024b)和 Li 等人(2024a)应用了另一种方法,该方法将文本提示格式化为一个问题(例如,“此图是否显示了 {文本字幕}”),并获得 VQA 模型回答“是”的概率。
还有一些指标利用语言模型 (LM)根据文本字幕生成问题。TIFA(Hu 等人,2023)和 Davidsonian Scene Graph (DSG)(Cho 等人,2024)都使用LM 生成自然语言二元和多项选择问题,以及视觉问答 (VQA)模型来评估问题。DSG 另外解决了 LLM 和 VLM 中的幻觉问题——生成的疑问根据其依赖关系组织成场景图,只有当它所依赖的疑问也正确时,疑问才被视为正确。例如,假设一个 VQA 模型被问到“有车吗?”、“车的颜色是什么?”和“车有几个轮子?”。如果模型错误地回答第一个问题为“没有”,那么其余问题将被视为不正确,无论它们的答案是什么,因为模型没有识别出汽车。VPEval(Cho 等人,2023)是另一个指标,它也生成问题,但不是自然语言,而是视觉程序。这些视觉程序可以通过不同的视觉模块执行,例如计数模块、VQA 模块或Optical Character Recognition (OCR)模块。Lin 等人(2024b)和 Li 等人(2024a)引入了 VQAScore,这是一种用于文本到图像评估的基于 VQA 的方法。他们没有使用 LM 生成问题,而是直接将文本提示传递给 VQA 模型。例如,给定一个提示“一只红色的狗在蓝色花旁边”,VQAScore 计算 VQA 模型在给定问题“此图是否显示一只红色的狗在蓝色花旁边?”的情况下生成“是”的概率。
4.1.3 视觉问答
视觉问答(Visual Question Answering,VQA) 是回答关于图像的自然语言问题。由于其简单性和通用性,VQA 是用于评估 VLMs 的主要任务之一。实际上,大多数 VLM 任务都可以重新表述为 VQA(例如,对于字幕,“图像中有什么?”,对于短语定位,“这个在哪里?”等等)。该任务最初由(Antol 等人,2015)提出,有两种形式:多项选择和开放式答案。基于 VQA 任务的流行基准测试包括 VQAv2(Goyal 等人,2017)、TextVQA(Singh 等人,2019)、GQA(Hudson 和 Manning,2019)、Visual Genome QA(Krishna 等人,2017)、VizWiz-QA(Gurari 等人,2018)、OK-VQA(Marino 等人,2019)、ScienceQA(Lu 等人,2022)、MMMU(Yue 等人,2023)(参见图 3)。VQA 传统上使用 VQA 准确率进行评估,该准确率基于模型生成的候选答案与人类标注的一组参考答案之间的精确字符串匹配。到目前为止,该指标在多项选择和 IID 训练设置中运行良好。但是,该社区正在向生成模型(能够生成自由格式的开放式答案)和OOD(Out-of-distribution)评估(例如,零样本迁移)过渡。在这些新设置中,传统的 VQA 准确率指标过于严格,并且往往会低估当前 VLM 系统的性能(Agrawal 等人,2023)。为了克服这一局限性,一些作品已经诉诸于人工约束(Li 等人,2023e)或改写(Awal 等人,2023)VLM 的输出以匹配参考答案的格式。但是,这排除了对 VLM 的公平比较,因为它们的感知性能在很大程度上取决于答案格式技巧。为了能够对 VLM 进行真实而公平的评估,Mañas 等人(2024)建议利用 LLM 作为 VQA 的评判者。
选择性预测。除了答案正确性之外,评估的另一个维度是 VQA 的选择性预测——VLM 能够在不回答原本会答错的问题的情况下,在它选择回答的问题上取得高准确率。这对于那些准确性至关重要且错误答案可能会误导信任模型的用户来说非常重要。
Whitehead 等人(2022)将此框架形式化为 VQA,根据指定风险(容忍的错误水平)下的覆盖率(回答的问题的比例)以及基于成本的指标(有效可靠性)来定义评估,该指标对错误答案的惩罚大于弃权。弃权的决定可以通过对不确定性度量进行阈值处理来确定,例如直接回答概率、学习的正确性函数(Whitehead 等人,2022;Dancette 等人,2023),或专家模型之间的一致性(例如,Si 等人(2023)在单模态语言空间中)。
4.1.4 以文本为中心的视觉问答
基于文本的 VQA 是一项任务,涉及对图像中文本内容的自然语言查询提供响应。除了理解通用 VQA 中文本和视觉内容之间的相关性之外,这些查询还要求模型 1) 准确地读取场景中的文本,并设计其结构和顺序,以及 2) 推理图像中的文本之间的相互关系以及图像中的其他视觉元素。
以文本为中心的评估可以使用各种任务来完成,例如文本识别、场景文本为中心的视觉问答 (VQA)、面向文档的 VQA、关键信息提取 (KIE) 和手写数学表达式识别 (HMER)。这些任务中的每一个都提出了独特的挑战和要求,全面概述了 LLM 的能力和局限性。
文本识别是Optical Character Recognition (OCR)中的一个基本任务,要求模型准确地识别和转录来自各种来源的文本。场景文本为中心的 VQA 通过要求模型不仅识别场景中的文本,而且还要回答有关它的问题来扩展这一挑战。面向文档的 VQA 通过将结构化文档(例如表格和发票)引入混合中来进一步复杂化。KIE 是一项专注于从文档中提取关键信息的任务,例如姓名、日期或特定值。最后,HMER 是一项专门的任务,涉及识别和转录手写数学表达式,由于手写符号的复杂性和可变性,这是一项特别具有挑战性的任务。一些流行的基准测试包括 IIIT5K(Mishra 等人,2012)、COCOText(Veit 等人,2016)、SVT(Shi 等人,2014)、IC13(Karatzas 等人,2013)用于文本识别,STVQA(Biten 等人,2019)、Text VQA(Singh 等人,2019)、OCR VQA(Mishra 等人,2019)和 EST VQA(Wang 等人,2020)用于场景文本为中心的 VQA,DocVQA(Mathew 等人,2021)、Info VQA(Mathew 等人,2022)和 ChartQA(Masry 等人,2022)用于面向文档的 VQA,SROIE(Huang 等人,2019)、FUNSD(Jaume 等人,2019)和 POIE(Kuang 等人,2023)用于 KIE,以及 HME100k(Yuan 等人,2022)用于 HMER。数据集的构成差异很大,应主要根据评估目的进行选择——一些数据集专注于特定类型的文本(例如手写文本或艺术文本),而另一些数据集则包含多种文本类型。一些数据集专门设计用于挑战模型处理多语言文本、手写文本、非语义文本和数学表达式识别的能力。一些数据集纯粹专注于大量不同的信息图表和表格表示。
4.1.5 零样本图像分类
零样本分类是指在模型没有明确训练的分类任务上评估模型。这应该与少样本学习形成对比,少样本学习需要对感兴趣的下游任务进行少量训练数据样本才能进行模型微调。
Radford 等人(2021)证明,CLIP 的零样本分类性能可以通过不同类型的提示结构显着提高,尤其是在针对特定任务定制时。他们能够在著名的 ImageNet 分类基准测试(Deng 等人,2009)上展示出具有竞争力的性能。这是第一个表明 VLM 方法可能能够与标准分类训练相媲美的作品。除了 ImageNet 之外,通常在其他分类数据集上评估 VLMs,例如 CIFAR10/100(Krizhevsky,2009)、Caltech 101(Li 等人,2022a)、Food101(Bossard 等人,2014)、CUB(Wah 等人,2011)、StanfordCars(Krause 等人,2013)、Eurosat(Helber 等人,2019)、Flowers102(Nilsback 和 Zisserman,2008)、OxfordPets(Parkhi 等人,2012)、FGVC-Aircraft(Maji 等人,2013)和 Pascal VOC(Everingham 等人,2010)。
由于提示工程,例如在人工设计的提示模板中使用概念名称,例如“一张 {类} 的照片”和“{类} 的演示”,可以显着提高零样本性能,最近的研究引入了新方法(Menon 和 Vondrick,2023;Pratt 等人,2023;Parashar 等人,2023),这些方法使用 ChatGPT 等 LLM 自动生成提示,通常包含丰富的视觉描述,例如“一只老虎,它有锋利的爪子”。虽然这些方法采用 CLIP(Radford 等人,2021)最初编写的标签名称,但 Parashar 等人(2024)用其最常用的同义词替换这些名称(例如,用 ATM 替换自动取款机)以提高准确率,而与所采用的提示模板无关。正如 Udandarao 等人(2024)所强调的那样,VLM 的零样本能力主要取决于这些概念是否出现在训练数据中。因此,目前尚不清楚我们是否应该仍然将此类评估视为零样本,因为模型可能已经以某种间接方式接受过训练来解决下游任务。
在Out-Of Distribution (OOD)任务上的泛化。
在 ImageNet 等任务上使用 CLIP 进行零样本评估并取得良好的性能,之所以成为可能,是因为 CLIP 的训练数据足够大,可能包含 ImageNet 数据集中存在的许多概念和类别标签。因此,当存在一些下游任务,其中 CLIP 训练分布可能过于不同时,会导致泛化能力差。Samadh 等人(2023)建议修改测试示例的标记分布,使其与 ImageNet 数据分布一致(因为原始 CLIP 训练数据未知)。他们表明,这种对齐可以帮助提高各种 OOD 基准测试以及不同下游任务的性能。
4.1.6 视觉语言组合推理
最近的一些基准测试引入了人工创建的字幕,这些字幕的设计带有歧义,旨在攻击模型。创建此类字幕的一种简单方法是重新排列真实字幕中的单词。然后,模型根据其从扰动字幕中区分正确字幕的能力进行评估(这使得此评估等同于二元分类问题)。在本节中,我们将介绍一些经常使用的利用此类二元分类设置的基准测试。
Winoground(Thrush 等人,2022)是一项用于评估 VLM 的视觉语言能力的任务。数据集中的每个示例都包含两张图像和两个字幕。每张图像都与一个字幕完全匹配,字幕仅在词序上有所不同。例如,在图 3 中,有两个字幕“一些植物围绕着一个灯泡”和“一个灯泡围绕着一些植物”。
模型的任务是将正确图像-字幕对的得分高于错误对。Diwan 等人(2022)还探讨了 Winoground,并提供了关于为什么这项任务对 VLM 如此具有挑战性的见解。
最近,Attribution, Relation, and Order (ARO)由 Yuksekgonul 等人(2023)引入,以评估 VLM 对关系、属性和顺序的理解。该数据集是使用 GQA、COCO 和 Flickr30k 构建的。然后,通过交换原始字幕中的关系、属性或顺序来生成负字幕。通过这样做,描述“一只马吃草”的字幕变成了“草吃了一只马”(图 3)。然后,模型根据其预测负字幕的概率较低的能力进行评估。与 Winoground 找到与负字幕相对应的真实图像不同,ARO 没有提供真正的“负”图像。这种方法的优点是可以生成很多负字幕;但是,其中一些在现实世界中可能毫无意义。
Hsieh 等人(2023)观察到,最近开发的图像到文本检索基准测试(Yuksekgonul 等人,2023;Zhao 等人,2022;Ma 等人,2023),这些基准测试旨在评估 VLM 的详细组合能力,可以被操纵。这些基准测试确实依赖于程序生成的硬负样本,这些负样本通常由于语法不准确而缺乏逻辑连贯性或流畅性。为了缓解这些问题,Hsieh 等人(2023)建议利用 ChatGPT 生成更合理且语言上更正确的硬负样本。他们将 SUGARCREPE 数据集(Hsieh 等人,2023)划分为类似于 ARO 中采用的方法,以评估不同形式的硬负样本,每个负样本都衡量一个特定的组合方面(例如,属性、关系、对象理解)。
警告!
许多依赖于区分正确字幕和负字幕的二元分类问题的基准测试的一个主要问题是,它们通常不考虑模型对两个字幕输出相同概率的情况。如果模型将两个字幕的信息折叠到相同的表示向量中,则可能会发生这种情况。如果模型输出相同的概率,那么 PyTorch 等框架使用的 argmax 操作将始终返回向量的第一个元素。碰巧许多基准测试将正确字幕作为第一个元素。因此,参数都等于零的模型可以在这些基准测试中达到 100% 的准确率。我们建议添加一个小的 epsilon 随机数或跟踪字幕是否被分配了相同的概率。
4.1.7 密集字幕和裁剪字幕匹配
由于文本标记器,当前一代的 VLM 通常仅限于使用简短的文本描述作为输入。流行的 Clip Tokenizer(用于训练基于 CLIP 的模型)最多生成 77 个标记,相当于 50 个英文单词或一小段文字。即使可以使用很少的单词来总结图像,图像通常比这丰富得多。当使用简短的字幕时,我们丢失了有关背景和我们想要描述的对象的细粒度细节的信息。Densely Captioned Images (DCI)数据集(Urbanek 等人,2023)被引入以提供完整的图像描述。通过使用 Segment Anything(Kirillov 等人,2023)将图像划分为不同的部分,作者要求人类标注者为图像的每个分割部分提供详细的描述。使用这种方法,他们用超过 1000 个单词的字幕标注了 7805 张图像。使用 DCI 数据集,作者在新的裁剪字幕匹配任务上评估了 VLM。对于每张图像,VLM 应该将所有子图像字幕中的正确字幕与正确的子图像匹配。这样做使作者能够评估给定的 VLM 对场景细节的细粒度理解程度。
4.1.8 基于合成数据的视觉语言评估
使用真实数据时遇到的挑战之一是,可能很难找到与负字幕相关的图像。此外,很难通过这些基准测试来区分模型是由于无法识别特定场景中的特定对象而失败,还是由于尽管识别了两个对象,但无法识别它们之间的关系而失败。此外,大多数情况下,描述图像的字幕通常非常简单,并且可能带有歧义或偏差。许多基于 VLM 检索的基准测试依赖于从 COCO 等知名数据集提取的真实图像。但是,使用未为 VLM 评估而设计的真实图像数据集可能会出现问题,因为此类数据集没有提供可以与负字幕相关的图像。例如,“咖啡杯”总是被拍摄在桌子上。因此,VLM 可以利用这种位置偏差来始终预测“咖啡杯在桌子上”的正确正字幕,而无需使用图像信息。
为了避免由真实图像和语言所具有的偏差导致的这种情况,除了负字幕之外,还必须提供相应的图像。在“咖啡杯”场景中,这将对应于将其放置在桌子下方,并评估 VLM 找到正确空间位置的能力。但是,手动将真实物体放置在不同的位置将非常昂贵,因为它需要人工干预。
相比之下,合成图像数据集在设计和评估 VLM 方面具有无与伦比的优势:它们使精确控制每个场景并产生细粒度的真实标签(和字幕)成为可能。使用Photorealistic Unreal Graphics (PUG),Bordes 等人(2023)通过一次添加一个元素来细粒度地构建复杂场景。
通过这样做,作者评估了给定的 VLM 是否能够在给定背景的情况下关联正确的字幕。然后,他们在场景中添加一只动物,并验证 VLM 是否能够在每个背景中检测到这种特定的动物。如果动物是正确的,他们会将其向左或向右移动,以确认 VLM 是否仍然能够找到正确的字幕,指示它是在左边还是右边。作者发现,在评估空间关系时,当前的 VLM 并没有比随机机会表现得更好。
4.2 基准测试 VLM 中的偏差和差异
近年来,偏差在机器学习系统中得到了广泛的研究(Buolamwini 和 Gebru,2018;Corbett-Davies 等人,2017;de Vries 等人,2019)。
现在,我们将讨论基准测试 VLM 中偏差的方法,包括通过模型分类及其嵌入空间分析偏差。
4.2.1 通过分类基准测试偏差
基准测试分类模型中偏差的最常见方法之一是通过分类。
例如,与人相关的属性(例如性别、肤色和种族)相关的偏差通常在对职业和职业进行分类的背景下进行衡量(Gustafson 等人,2023;Agarwal 等人,2021)。
此外,经常评估对暗示有害关联的概念进行的人员分类(Agarwal 等人,2021;Goyal 等人,2022;Berg 等人,2022)。
不太常见,但仍然相关的是,当看似良性的物体和概念(例如服装或运动器材)与来自不同群体的人同时出现时,评估其分类率(Srinivasan 和 Bisk,2021;Agarwal 等人,2021;Hall 等人,2023b)。
使用真实数据。
这些评估通常使用真实数据进行。
例如,Agarwal 等人(2021)对 CLIP 中潜在偏差进行了评估。
他们通过分析包含与种族、性别和年龄相关的群体标签的面部图像的分类率来衡量表示性危害(Karkkainen 和 Joo,2021;Hazirbas 等人,2024),以对“小偷”、“罪犯”和“可疑人物”等类别进行分类。此外,他们还衡量了不同阈值下性别群体之间与服装、外貌和职业相关的标签的分布。在这些实验中,他们发现种族、性别和年龄群体之间存在显着的有害关联和差异模式。
重要的是要注意真实评估数据源中群体之间流行率的差异,因为这可能会影响差异评估。例如,评估数据的标签质量可能会有所不同,某些群体可能会出现潜在偏差,或者群体之间概念分配不一致(Hall 等人,2023a)。
此外,群体之间可能存在分布变化,例如,不同属性的人使用不同的图像来源(Scheuerman 等人,2023)。
使用合成数据。
Smith 等人(2023)证明,可以使用合成、性别平衡的对比集来评估 VLM 中的偏差,这些对比集是使用仅编辑性别相关信息并保持背景固定的扩散模型生成的。类似地,Wiles 等人(2022)使用现成的图像生成和字幕模型研究了模型的失败模式。具体来说,使用生成模型使用真实标签生成合成样本。然后,使用字幕模型对错误分类的样本进行字幕,以生成额外的样本。这将产生模型的人类可解释的失败模式语料库。此外,Li 和 Vasconcelos(2024)提出了一种框架,通过应用因果干预并生成反事实图像-文本对来量化 VLM 中的偏差。这允许测量模型对原始和反事实分布的预测差异。
4.2.2 通过嵌入基准测试偏差
另一种基准测试偏差的方法侧重于 VLM 的嵌入空间。这些方法不评估像分类这样的特定最终任务,而是分析文本和图像表示之间的关系。
这项工作很大程度上建立在 NLP 中的词嵌入分析的基础上。词嵌入关系,如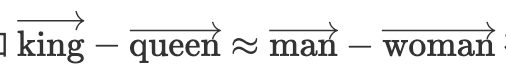 在语义上是有用的;但是,也存在有害的关系,例如
在语义上是有用的;但是,也存在有害的关系,例如 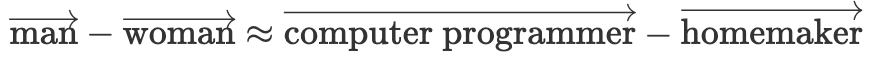 (Bolukbasi 等人,2016)。
(Bolukbasi 等人,2016)。
嵌入空间分析可以揭示在评估任务中难以衡量的学习关系。为了理解这些类型的关系,Ross 等人(2020)引入了两个测试嵌入关联测试,Grounded-WEAT 和 Grounded-SEAT,它们衡量与人类隐式关联中发现的偏差类似的偏差。例如,他们表明,像花朵这样的令人愉快的概念与欧洲美国人姓名和较浅的肤色比与非洲裔美国人和较深的肤色更相关。类似的细微发现是,VLM 将成为美国人与成为白人联系起来(Wolfe 和 Caliskan,2022),并表现出性客体化(Wolfe 等人,2023)。CLIP 的爆炸式增长带来了新的方法,这些方法利用文本和图像嵌入之间的显式映射。当将图像映射到人口统计属性(例如性别、肤色、年龄)的编码以及刻板印象词(例如恐怖分子、首席执行官)时,发现了人口统计偏差(Garcia 等人,2023;Hamidieh 等人,2023)。
4.2.3 语言偏差可能会影响您的基准测试!
随着 VLM 领域的进步,解决通常被忽视但至关重要的多模态基准测试整理挑战至关重要。一个值得注意的例子是具有影响力的视觉问答 (VQA) 基准测试(Antol 等人,2015),该基准测试已知可以通过利用数据集中单模态(语言)偏差的“盲”算法来解决,例如,以“有钟表吗”开头的疑问,其答案为“是”的概率为 98%(Goyal 等人,2017)。换句话说,没有经过仔细整理的多模态基准测试容易受到单模态捷径解决方案的影响。实际上,Lin 等人(2024a)发现,使用 BLIP(Li 等人,2022b)等图像字幕模型估计的盲语言先验(�(text)P(text))在当代图像-文本检索基准测试中表现良好,包括 ARO(Yuksekgonul 等人,2023)、Crepe(Ma 等人,2023)、VL-CheckList(Zhao 等人,2022)和 SugarCrepe(Hsieh 等人,2023)。
相比之下,Winoground(Thrush 等人,2022)和 EqBen(Wang 等人,2023a)等平衡基准测试实际上会惩罚单模态捷径。
4.2.4 评估训练数据中的特定概念如何影响下游性能
最近,Udandarao 等人(2024)表明,训练数据中频繁出现的概念将能够在下游任务中取得良好的性能。但是,如果这些概念不存在或很少见,那么模型在这些概念上的性能就会很差。作者建议找到一个概念列表来描述给定的下游任务(例如,分类任务的类别名称),然后利用识别模型(例如 RAM(Zhang 等人,2023d))来检测训练数据中存在多少这些概念。此类评估近似于 VLM 在训练后能够解决这些下游任务的可能性。
4.3 基准测试幻觉
幻觉是 LLM 的一个主要问题(Huang 等人,2023)。它们通常会以非常高的置信度生成看似真实但实际上是错误的信息。例如,他们可能会争辩说,一个人第一次登上月球是在 1951 年,而真实答案是 1969 年。他们还可以想象从未发生的历史事件。VLM 可能产生与用户要求模型描述的图像无关的文本或字幕。因此,评估 VLM 是否没有产生幻觉是一个非常重要的研究领域。Rohrbach 等人(2018)开发了第一个基准测试(CHAIR),用于字幕中的对象幻觉,在 COCO(Lin 等人,2014)上衡量固定对象集中的幻觉。虽然它仍然很流行,尤其是在评估简短的单句字幕时,但它可能会误导评估来自最近 VLM 的长生成(例如,将假设陈述视为幻觉,或遗漏固定对象集之外的幻觉),并且仅限于 COCO 数据,该数据通常包含在训练集中,并且本身提供了狭隘的评估视角。
相反,POPE(Li 等人,2023g)使用二元投票问题(包括正向问题(使用真实对象)和负向问题(从负向对象中采样))来评估对象幻觉。
最近的努力采用基于模型的方法来扩展评估,例如,Liu 等人(2023b)使用 GPT-4(Achiam 等人,2023)来评估指令遵循(GAVIE),Zhai 等人(2023a)用于在字幕中定位对象幻觉(CCEval),以及 Sun 等人(2023)用于评估 VLM 对针对幻觉的疑问的响应(MMHal-Bench)。此外,始终存在人工评估,正如 Gunjal 等人(2024)使用细粒度字幕注释所证明的那样。
4.4 基准测试记忆
训练数据的潜在记忆已针对单模态模型(如 LLM(Carlini 等人,2021)和扩散模型(Somepalli 等人,2023;Carlini 等人,2023))进行了广泛的研究。对于 VLM,如何衡量记忆更加复杂,主要有两个原因:1)与生成模型不同,CLIP 等联合嵌入 VLM 没有解码器,这使得难以解码模型参数和学习嵌入中记忆的信息。2)对于 CoCa 和 LLaVA 等具有有限生成能力的 VLM,如何暴露跨模态记忆仍然是一个悬而未决的问题,例如,如何探测模型通过文本记忆其训练图像的内容。
Jayaraman 等人(2024)研究了 VLM 在使用其相应字幕进行查询时记忆训练图像中对象的的能力。他们将这种现象称为“似曾相识”记忆,并表明 CLIP 模型可以有效地“记住”训练图像中存在的对象,即使这些对象在字幕中没有描述。为此,作者提出了一种 �k 近邻测试,其中他们利用从基础训练分布中采样的公共图像集,但与训练集没有重叠。对于目标训练字幕,他们在嵌入空间中找到与字幕最接近的 �k 个公共集图像。然后使用这些图像来解码目标训练图像中存在的不同对象。但是,此步骤本身无法区分对象是由于模型记忆推断出来的,还是由于模型从图像-字幕对中学习了通用相关性。为了区分这一点,作者训练了另一个 CLIP 模型(称为参考模型),该模型在训练期间没有看到目标图像-字幕对。然后对该参考模型执行类似的 �k -NN 测试,以评估参考模型推断出的对象。最后,根据目标模型和参考模型的对象检测精度/召回率分数之间的差距来量化“似曾相识”记忆,其中差距越大表示记忆程度越高。
虽然不同的正则化技术对缓解记忆的影响可能不同,但 Jayaraman 等人(2024)发现文本随机化是最有效的正则化技术,它可以显著减少记忆,而不会严重影响模型效用。在这种技术中,在每个训练时期,训练字幕中的随机部分文本标记会被屏蔽。这引入了文本增强,从而降低了模型过度拟合训练字幕与其对应图像之间关联的能力。
4.5 红队攻击
在基础模型的背景下,红队攻击是指试图利用模型的公共接口使其生成一些不希望的输出(Perez 等人,2022)。红队攻击通常包括某种类型的对抗性数据集,旨在引发危害。该数据集将包含一对提示,以及被认为正确的参考答案(例如,拒绝回答),模型将根据其与正确答案的距离进行评分(Vidgen 等人,2023;Bianchi 等人,2024)。
为了使事情具体化,请考虑 VLM 如何使用敏感图像进行提示,然后要求它详细描述该图像。虽然文本提示可能是良性的(“描述图像中的活动”),但输出可能被认为是有害的。Li 等人(2024b)的工作试图从忠实度、隐私、安全性、公平性等方面来描述红队攻击中独特的挑战。
为了预测评估 VLM 中的挑战类型,考虑针对文本到文本和文本到图像模型已经开发的一些红队攻击工作将有所帮助。在语言领域,红队攻击数据集旨在揭示某些危害。这些危害充当许多潜在风险的代理,然后可以将其组织成风险分类法(Weidinger 等人,2022;Sun 等人,2024;Derczynski 等人,2023)。为了组织这些工作,已经开发了排行榜,用于在一系列对抗性任务中对语言模型进行基准测试(Liang 等人,2022;Röttger 等人,2024)。Lee 等人(2024)的文本到图像工作提供了类似的排名工作。为了能够将危害映射到风险,红队攻击工作会确定他们希望减轻的风险定义,然后探测模型以尝试揭示该风险。这些风险(例如,隐私、毒性、偏差)的正式化仍然是一个活跃的研究领域。
在执行红队攻击评估后,可以使用后处理方法或模型微调方法(例如,人类反馈强化学习(Ouyang 等人,2022))来缓解某些风险。
5 将 VLM 扩展到视频
到目前为止,我们的重点是针对静态视觉数据(即图像)进行训练和评估的 VLM。然而,视频数据为模型带来了新的挑战和潜在的新功能,例如理解物体的运动和动态,或在空间和时间上定位物体和动作。文本到视频检索、视频问答和生成迅速成为基本的计算机视觉任务(Xu 等人,2015;Tapaswi 等人,2016;Brooks 等人,2024)。
视频的时间空间会使存储、GPU 内存和训练的难度增加帧率倍数(例如,如果将每帧视为图像,则 24 fps 的视频需要 24 倍的存储/处理)。
这需要在针对视频的 VLM 中进行权衡,例如,以压缩形式(例如,H.264 编码)的视频,在数据加载器中使用即时视频解码器;从图像编码器初始化视频编码器;视频编码器具有空间/时间池化/掩蔽机制(Fan 等人,2021;Feichtenhofer 等人,2022);非端到端 VLM(离线提取视频特征,并训练模型,这些模型使用视频特征而不是像素帧来处理长视频)。与图像-文本模型类似,早期的视频-文本模型从头开始训练视觉和文本组件,使用自监督标准(Alayrac 等人,2016)。但与图像模型相反,对比视频-文本模型并非首选方法,早期融合和视频和文本的时间对齐更受欢迎(Sun 等人,2019),因为与计算视频的全局表示相比,表示中的更多时间粒度更有趣。最近,视频-语言模型观察到与图像-语言模型类似的趋势:预训练的 LLM 被使用并与视频编码器对齐,从而增强了 LLM 对视频理解的能力。视觉指令微调等现代技术也经常被使用并适应视频。
5.1 基于 BERT 的早期视频工作
尽管最初的视频语言方法高度针对它们被设计用来解决的任务(例如视频检索或视频问答),但 VideoBERT(Sun 等人,2019)是第一个成功的视频-语言建模通用方法。与使用对比学习的 CLIP 方法(在图像语言建模中取得成功)相反,VideoBERT 是一种早期融合方法,类似于 Flamingo(Alayrac 等人,2022),其中表示视频字幕对的视觉和文本标记与单个 Transformer 网络融合在一起。视频数据来自 YouTube,来自烹饪教学视频,对齐的文本是使用自动语音识别 (ASR) 获得的。视频逐帧处理,每帧对应一个视觉标记。然后,预训练目标基于流行的 BERT 语言模型,其中一些标记被屏蔽并重建。VideoBERT 展示了强大的对齐能力,是第一个能够在需要生成文本的视频任务中表现良好的模型,例如零样本动作分类和开放式视频字幕。
超越全局视频和文本对齐(其中描述性句子与视频匹配),跨时间的多模态事件表示学习 (MERLOT)(Zellers 等人,2021)实现了视频语言对齐,其中文本与视频在时间上对齐。与在经过整理的烹饪教学视频上训练的 VideoBERT 相反,MERLOT 在一个更大规模的 YouTube 视频数据集上进行训练,该数据集整理程度较低,也更加多样化,其中相应的文本是通过 ASR 获得的。该模型使用以纯自监督方式训练的 Transformer 网络,在局部文本标记和帧视觉标记之间使用对比目标,掩蔽语言建模目标和时间重新排序目标。该模型在当时展示了在问答任务(尤其是视觉常识推理)上的出色能力。首先,它能够将从视频中学到的知识转移到回答关于从图像中接下来会发生什么的问题,这表明视频模型对于理解视觉世界很有用。其次,它能够在广泛的数据集和基准测试中回答来自视频的特别困难的问题。MERLOT 的主要局限性在于它缺乏生成文本的能力,这使其无法展示高级视觉推理能力。
5.2 使用早期融合 VLM 启用文本生成
VideoOFA(Chen 等人,2023c)是一种用于视频到文本生成的早期融合 VLM。许多早期的视频 VLM 要么缺乏生成文本的能力,要么将视频编码器与单独训练的文本解码器结合在一起,导致精度不佳。相反,VideoOFA 提出了一种两阶段预训练框架,将单个生成式图像-文本 VLM 适应视频-文本任务。特别是,VideoOFA 从能够生成文本的图像-文本 VLM 初始化,并在海量图像-文本数据上联合预训练,以学习基本的视觉-语言表示555实际上,VideoOFA 使用 OFA(Wang 等人,2022)模型作为其图像-文本主干。然后,它提出一个中间视频-文本预训练步骤,将主干 VLM 适应视频-文本任务,并学习视频特定概念,例如时间推理。中间预训练阶段包含三个训练目标,所有目标都重新表述为视频到文本的生成任务:视频字幕、视频-文本匹配和帧顺序建模。VideoOFA 在多个视频字幕和视频问答基准测试中进行了评估,与之前的模型相比,性能有所提高。
5.3 使用预训练的 LLM
图像-语言模型逐渐趋向于利用现有 LLM 的强大功能,因为它们能够理解文本。与训练语言模型以与预训练的视觉主干对齐的想法相反,该想法是将视觉主干与现有的 LLM 对齐,通常使用字幕目标。视频模型也遵循相同的趋势,Video-LLaMA(Zhang 等人,2023b)成为一种流行的方法,展示了强大的视频-语言对齐,包括视觉和音频信号。Video-LLaMA 的架构基于 BLIP-2,一个视频 Q-former 和一个音频 Q-former 在 Webvid-2M(一个经过整理的视频数据集)上分别进行训练,以将语言与视频和音频对齐。LLM 是一个 LLaMA 模型,训练目标是字幕损失。作为第二步,该模型在来自 MiniGPT-4、LLaVA 和 VideoChat 的视觉指令数据上进行微调,使其适合人类交互。Video-LLaMA 是一种对话代理,因此没有使用标准基准测试进行评估。该模型可以通过聊天 API 访问,用户可以使用文本提示、视频和图像与模型进行对话,并提出与其相关的疑问。许多后续工作,例如 Video-LLaVA(Lin 等人,2023)进一步探索了 LLM 与视频的对齐。
最近的一个,MiniGPT4-Video(Ataallah 等人,2024)扩展了 MiniGPT-v2,使其能够通过文本输入理解视频。MiniGPT4-Video 采用 MiniGPT-v2 的方案,将每四个相邻的视觉标记连接成一个标记,以减少输入标记的数量,而不会丢失太多信息。除了视觉标记外,还提取了每帧字幕的文本标记,以更好地表示每个视频帧。这种视觉标记和文本标记的混合可以帮助 LLM 更好地理解视频内容。MiniGPT4-Video 的架构
由视觉编码器、单个线性投影层和大型语言模型组成。为了评估 MiniGPT4-Video 的有效性,使用了三种类型的基准测试来展示其在视频理解方面的良好性能,包括 Video-ChatGPT、开放式问题和多项选择题 (MCQ)。MiniGPT4-Video 在 MSVD(Chen 和 Dolan,2011)、MSRVTT(Xu 等人,2016)、TGIF(Li 等人,2016)和 TVQA(Lei 等人,2018)基准测试上始终优于现有最先进的模型,例如 Video-LLaMA(Zhang 等人,2023b),幅度很大。
5.4 评估中的机遇
虽然视频基准测试通常与图像基准测试类似,例如字幕,但视频也为其他类型的评估打开了大门。EgoSchema(Mangalam 等人,2024)等数据集要求模型回答关于长视频的问题,其中必须理解物体/代理之间的交互。这使得评估能够超越描述场景,而这仅凭图像很难做到。类似地,ActivityNet-QA(Yu 等人,2019)、MSVD-QA(Xu 等人,2017)和 MSRVTT-QA(Xu 等人,2017)要求检索相关帧/定位动作以正确回答问题。但是,对于许多问题,查看简单的帧就足以提供准确的答案。例如,展示一场足球比赛并询问“人们在玩什么运动?”并不需要查看单个帧以外的内容。
这引发了一个问题,即视频的时间方面对于解决当前视频基准测试有多必要。
理解视频中动作的语义方面非常重要,但视频也提供了独特的机会来探测模型的推理能力或对世界的理解。
为此,合成数据已被证明在探测基于视频的 VLM 的推理能力方面非常有效。在 Jassim 等人(2023)中,视频的生成方式要么遵循物理定律,要么违反物理定律。例如,突然消失的球违反了时空连续性。然后要求模型判断视频中的元素(例如球的轨迹)是否遵循物理定律。也许令人惊讶的是,VideoLLaMA 或 PandaGPT(Su 等人,2023)等模型并没有超过随机性能,而人类的准确率超过了 80%。这些发现表明,视频 VLM 仍然缺乏一些基本的推理能力,这些能力可以通过合成数据有效地探测。
虽然当前视频 VLM 的能力令人印象深刻,但仍然有机会进一步探测它们的推理能力,而这只有通过视频的时间特性才能实现。
5.5 利用视频数据的挑战
视频-文本预训练的一个挑战是当前在时间空间上的(弱)监督稀缺,VideoPrism(Zhao 等人,2024)说明了这个问题。现有数据(例如,来自互联网)侧重于描述场景的内容,而不是动作或运动,这使得视频模型降级为图像模型。在视频上训练的 CLIP 模型也可能表现出名词偏差(Momeni 等人,2023),这使得建模交互更加困难。这会导致模型在视频上进行训练,但在时间理解方面存在缺陷。生成包含场景内容和时间方面信息的配对视频-字幕数据比描述图像中的场景更复杂(且成本更高)。有一些可能的解决方案。例如,可以使用视频字幕模型生成更多字幕,但这需要一个初始高质量数据集来训练该字幕器。另一个选择是在视频上单独训练视频编码器。这也用于 VideoPrism,因为它限制了不完美字幕的影响。
除了数据之外,另一个挑战是计算。处理视频比处理图像更昂贵,但它是一种更冗余的模态。虽然图像包含大量冗余信息,但视频中两个连续帧的相似度更高。因此,需要更有效的训练协议,例如使用掩蔽,这是一种在基于图像的 VLM 上被证明有效的技术(Li 等人,2023f)。所有这些挑战,无论是关于预训练数据、计算还是评估质量,都指出了通往具有更好世界理解能力的视频 VLM 的有希望的研究方向。
6 结论
将视觉映射到语言仍然是一个活跃的研究领域。从对比方法到生成方法,训练 VLM 的方法有很多。但是,高计算量和数据成本通常是大多数研究人员的障碍。这主要促使人们利用预训练的 LLM 或图像编码器来学习模态之间的映射。无论训练 VLM 的技术是什么,仍然有一些需要牢记的总体注意事项。大规模高质量图像和字幕是推动模型性能的重要因素。改进模型接地并使模型与人类偏好对齐也是提高模型可靠性所必需的步骤。为了评估性能,已经引入了多个基准测试来衡量视觉-语言和推理能力;但是,其中许多基准测试存在严重的局限性,例如,只能通过使用语言先验来解决。将图像绑定到文本并非 VLM 的唯一目标;视频也是一种重要的模态,可以利用它来学习表示。但是,在学习良好的视频表示之前,仍然有许多挑战需要克服。对 VLM 的研究仍然非常活跃,因为这些模型要变得更加可靠,仍然需要许多缺失的组件。
说明
本文来自《An Introduction to Vision-Language Modeling》 , arxiv:2405.17247,点击原文链接可下载原始的英文论文 PDF。
AI大模型学习福利
作为一名热心肠的互联网老兵,我决定把宝贵的AI知识分享给大家。 至于能学习到多少就看你的学习毅力和能力了 。我已将重要的AI大模型资料包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。
因篇幅有限,仅展示部分资料,需要点击下方链接即可前往获取
2024最新版CSDN大礼包:《AGI大模型学习资源包》免费分享
一、全套AGI大模型学习路线
AI大模型时代的学习之旅:从基础到前沿,掌握人工智能的核心技能!

因篇幅有限,仅展示部分资料,需要点击下方链接即可前往获取
2024最新版CSDN大礼包:《AGI大模型学习资源包》免费分享
二、640套AI大模型报告合集
这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。

因篇幅有限,仅展示部分资料,需要点击下方链接即可前往获取
2024最新版CSDN大礼包:《AGI大模型学习资源包》免费分享
三、AI大模型经典PDF籍
随着人工智能技术的飞速发展,AI大模型已经成为了当今科技领域的一大热点。这些大型预训练模型,如GPT-3、BERT、XLNet等,以其强大的语言理解和生成能力,正在改变我们对人工智能的认识。 那以下这些PDF籍就是非常不错的学习资源。

因篇幅有限,仅展示部分资料,需要点击下方链接即可前往获取
2024最新版CSDN大礼包:《AGI大模型学习资源包》免费分享
四、AI大模型商业化落地方案

因篇幅有限,仅展示部分资料,需要点击下方链接即可前往获取
2024最新版CSDN大礼包:《AGI大模型学习资源包》免费分享
作为普通人,入局大模型时代需要持续学习和实践,不断提高自己的技能和认知水平,同时也需要有责任感和伦理意识,为人工智能的健康发展贡献力量。

















 1647
1647

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









