






万字分享多模态大模型OCR工作 OCR VLM
文本OCR任务是目前MLLM领域比较受重视的一个方向,业务场景相对较多,且如果能实现也是对当前OCR pipeline一次很好的变革。很多实验室和企业都有相关的重点工作。
过去的OCR主要是多模块pipeline设计,流程上包括: 元素检测、区域裁剪和字符识别部分。每个模块都容易过拟合,使整个系统产生较高的维护成本。此外,传统的 OCR 方法泛化能力不足,针对不同场景要选择或专门训练相应的模型。
现在就有一批尝试通过VLM范式解决OCR任务的工作。对于VLM来说,OCR任务最突出的特点就是需要高分辨率输入,越大的图片越清晰,能包含的字符也越多。而且OCR任务属于感知任务,不要求有太多reasoning,但需要准确识别每个字符,所以需要的Visual token也很多。所以动态分辨率几乎是标准配置了。而且对应的需要各种visual token 压缩方案。
除了模型方法的不同,还有训练以及数据的不同。首先就是需要大量OCR数据,需要使用各种数据合成。训练上,通用VLM会使用CLIP-like ViT,但CLIP是在caption数据上预训练的,且自然图像的比重大,所以一定需要打开CLIP,在OCR数据上预训练。
下面介绍几篇我看过的工作,主要来自Vary团队(yxmm - 知乎)(Vary、OneChart、Fox),阿里X-plug团队(胡安文 - 知乎、徐海洋-mPLUG - 知乎)(Mplug系列),OCR领域大佬华科大白翔老师(Monkey系列)。
GOT-OCR 2.0(阶跃星辰stepfun,2409)
论文标题:《General OCR Theory: Towards OCR-2.0 via a Unified End-to-end Model》面向OCR2.0时代的通用端到端模型。来自Vary作者团队新作。
目前GitHub上已经6k stars了。
keypoints
-
通用,能端到端解决各种场景的OCR,可以通过简单的提示生成普通或格式化的结果(markdown/tikz/smiles/kern);
-
支持交互式OCR特征,即由坐标或高亮颜色引导的region级识别;
-
支持动态分辨率和多页OCR;
-
轻量化,使用Qwen-0.5B作为解码器,整个模型只有580M,使用80M大小的vision encoder。
-
纯OCR模型,没有什么推理能力。

On the input side, GOT supports various optical image types, such as commonly used photographs and documents. Besides, as a general OCR-2.0 model, GOT can handle more tasks, e.g., sheet music, molecular formulas, easy geometric shapes, charts, etc. Moreover, the model can adapt t
思想
目前的通用MLLM重点在于_推理reasoning_,而非_感知perception_,为了获取来自LLM的收益,经常是将image token对齐到text。但对于OCR这样感知为主的场景,特别是文字密度较大时,只能通过增加image token来提升OCR能力。而且过去的这方面的工作以7b为主,而当需要增加一种语言,或场景的时候往往要重新预训练,这样成本就太高了,所以还要把模型参数量降下来。
针对以上需求,作者提出模型要做的端到端、轻量、且泛用。所以用了很小的vision encoder(80M),但支持1024*1024的图像输入,每个输入图像将被压缩为 256×1024 维 tokens。LLM选用Qwen-2 0.5b,支持 8K 最大长度tokens。

模型和训练
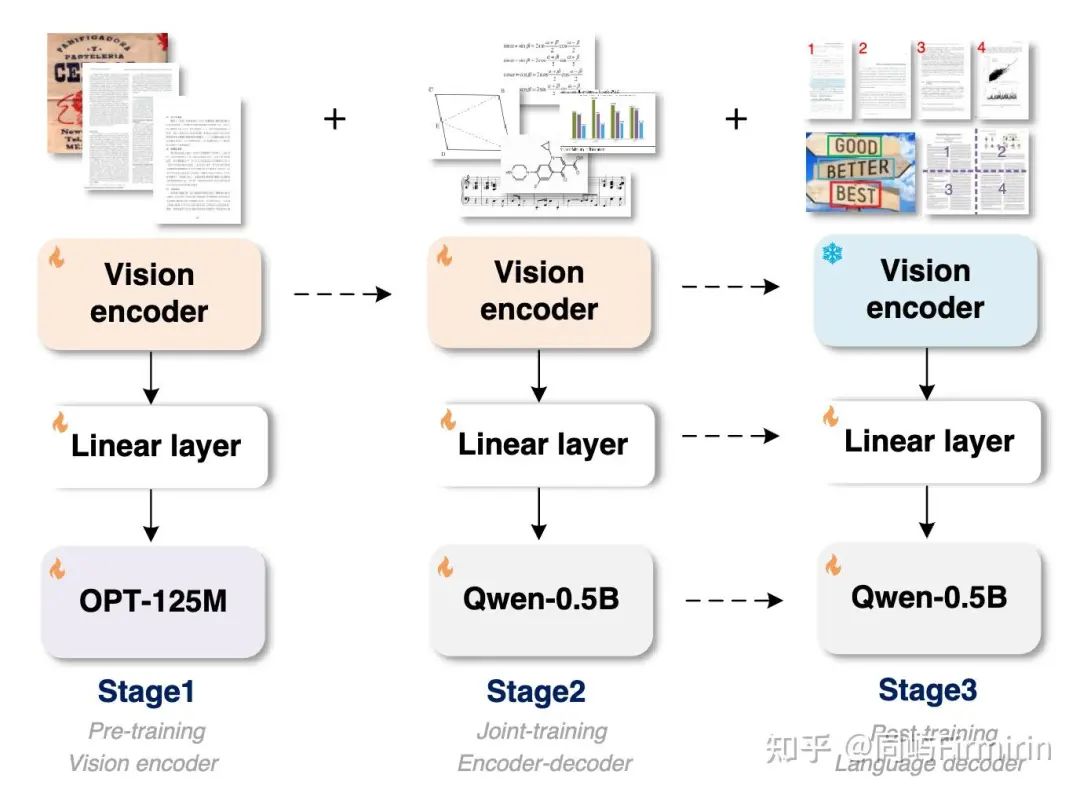
模型架构上分三部分:vision encoder+线性层+LLM。注意这里的encoder是一个80M的小模型,并非CLIP,需要从头训练。
训练分三阶段:
-
进行纯文本识别任务来预训练视觉编码器,为了节省GPU资源选用了125M的小规模进行梯度传播,数据使用scene texts and manual images;
-
二阶段是完整的模型训练,注意线性层也要换新的,使用大量宽泛的OCR数据(甚至有五线谱、化学结构图)进行scale up的训练;
-
三阶段为了进一步拓展模型能力,会有多图输入、region级别的输入、以及带有visual prompt的输入。
下面展开介绍:
1. Pre-train the OCR-earmarked Vision Encoder
受过去VLM工作的启发,vision encoder部分可以使用语言模型进行初始化(如step1所示)。
模型选择了VitDet-80M。因为它的局部注意力可以极大地降低高分辨率图像的计算成本。遵循 Vary-tiny 设置来设计encoder的最后两层,它将 1024×1024×3 输入图像转换为 256×1024 图像标记。然后,这些tokens通过 1024×768 线性层投影到语言模型 (OPT-125M [53]) 的维度中。
step1训练中,对所有大小的图像选择直接resize到1024*1024.
2. Scaling Up the OCR-2.0 Knowledge via Multi-task Joint-training
将一阶段得到的encoder通过一个新的全连接层(纬度1024*1024)接到Qwen2-VL 0.5b。1024*1024的图像最终被压缩为256个tokens再输入到LLM。
3. Customizing New OCR Features by Post-training the Decoder
二阶段训练后GOT已经能进行多场景OCR了。现在只对解码器部分进行后训练来定制GOT以启用三个新特性,即细粒度、多页面和动态分辨率OCR。
数据
一阶段 encoder预训练
使用了大约 5M 的图像-文本对,包括 3M 自然场景文本 OCR 数据(中英文各一半)和 2M 文档 OCR 数据。
对于自然场景数据,分别从Laion-2B和Wukong数据集中采样英文和中文图像。然后,使用PaddleOCR工具捕获这些不同真实场景中的文本。对于GT的设计:去除所有的bbox,按从上到下、从左到右的顺序组合每个文本内容。此外,根据bbox从原始图像中裁剪文本区域,并将其保存为图像切片,从而得到另外1M region级别的数据。
对于文档级数据,我们首先从Common Crawl收集开源pdf样式的文件,并使用Fitz Python包提取相应的密集文本内容。在此过程中,我们获得了1.2M个全页pdf样式的图像-文本对和0.8M个图像切片数据。切片数据(包括行级和段落级)通过解析的边界框从PDF图像中裁剪出来。
二阶段 多任务融合训练
在这一阶段仔细探索了几种合成方法和数据引擎,而不是上面提到的普通OCR数据。
Plain OCR data
上一阶段数据的80%用于这阶段,并追加手写场景的OCR,数据来自Chinese CASIA-HWDB2 [ 1], English IAM [2], and Norwegian NorHand-v3,原数据的line-level slice会被6到8个地组合在一起当作longer-text。
Mathpix-markdown formatted data

作者使用了6种渲染工具用于生成多样的OCR数据
Math formulas:来自在Arxiv上抓取的LATEX源.tex文件,从中提取了大约1M个公式片段。再将公式源转换为Mathpix格式,并使用chrome驱动程序调用Mathpix-markdown-it工具将源呈现为HTML格式。然后将HTML文件转换为svg并将其保存为PNG图像。这种渲染方法比直接使用LATEX快20倍以上。
Molecular formulas:We first download the ChEMBL_ 25 file that contains 2M smile sources. Then we use the Mathpix-markdown-it tool and rdkit.Chem package to gather about 1M of molecular formula image-text pairs.
Table:从抓取的.tex文件中,提取了大约0.3M个表源,并将它们呈现为图像。这次没有使用Mathpix-markdown-it,而是直接使用LATEX作为呈现工具,因为它对高级表的呈现效果更好。
Full page data:使用Nougat,获取到0.5M English markdown PDF-text pairs。还收集了0.5M Chinese markdown pairs。此外,还添加了0.2M 内部数据,这些数据直接使用 Mathpix 进行标注,包括书籍、论文和财务报告。
More general OCR data
乐谱:来自GrandStaff数据集,大约有0.5M样本。
几何图形:几何是vlm的关键能力,是实现AGI的必要步骤。将光学几何元素转换为TikZ[34]文本格式。TikZ包含一些简洁的命令来生成基本的几何元素,可以使用LATEX进行编译。作者采用tikz风格的点和线,用最简单的点线空间关系来构造简单的基本几何形状(如圆、矩形、三角形、组合形状)和简单的函数曲线(如直线、抛物线、椭圆、双曲线等)。通过这种方法,我们获得了大约1M的几何Tikz数据。
chart:这部分任务将图表图像上的视觉知识(例如标题、源、x-title、y-title 和值)转换为具有表/Python-dict 格式的可编辑输出。因为GOT是纯OCR模型不需要考虑理解推理等任务,所以这部分数据选择随机合成,从开放访问的 NLP 语料库中随机抽取实体文本(对于标题、源、x-title、y-tittle 等)。数值是受控分布下的随机数。用Matplotlib和Pyecharts生成了2M的Chart数据。
三阶段 能力增强后训练
细粒度可交互OCR数据
细粒度OCR[20]是由空间坐标或颜色控制的区域级视觉感知,是一种高交互性的特征。用户可以在问题提示中添加框坐标(box-guided OCR)或彩色文本(color-guided OCR),请求在感兴趣区域(RoI)内进行识别,避免输出其他不相关的字符。
对于自然场景细粒度OCR,源图像和注释来自开源数据集,包括RCTW[41]、ReCTS[25]、ShopSign[51]和COCO-Text[44]数据集。上面提到的数据集提供了文本边界框,可以使用它们直接生成细粒度(区域/颜色提示)OCR数据。对于文档细粒度OCR,遵循Fox[20],下载的PDF文件中过滤掉具有扫描格式的OCR,并使用Python包(Fitz/PDFminer)解析剩下的部分。然后记录页面级图像,每行/段落的边界框以及相应的文本,以产生框对应的GT文本。每个坐标值首先被归一化,然后被放大1000倍。对于颜色引导任务,选择最常用的颜色(红、绿、蓝)作为帧颜色,并通过相应的边界框在原始图像上绘制它们。收集了大约60w的样品。
超高分辨率数据
GOT支持1024×1024输入分辨率,这足以用于常用的OCR任务。然而,一些场景有巨大的图像,如两页PDF水平拼接。GOT的动态分辨率在大滑动窗口(1024×1024)下实现,确保模型可以用可接受的tokens数量完成极高分辨率的OCR任务。使用internv1 -1.5[9]裁剪方法,将tile的最大值设置为12。超分辨率图像是用上面提到的单页PDF数据合成的,包括水平拼接和垂直拼接。总共获得了50w对图像-文本。
pdf多页数据
从Mathpix格式的PDF数据中随机抽取2-8页,并将它们连接在一起,形成一个多页OCR任务。每个选定的页面包含少于650个tokens,以确保总长度不超过8K。生成了大约20w的多页OCR数据,其中大部分是在中文和英文页面之间交错的。
实验
结果
大都是SOTA,而且580M打赢几十B的,赢麻了。
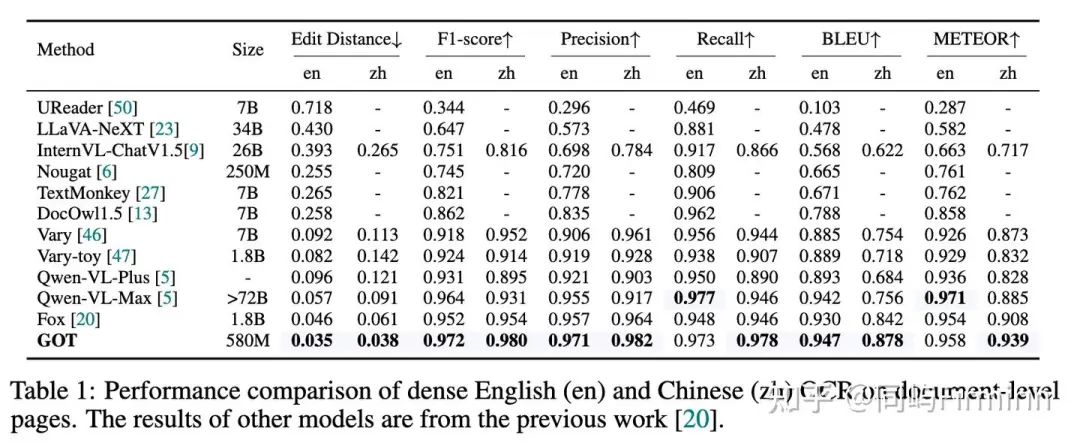
普通文本级别OCR
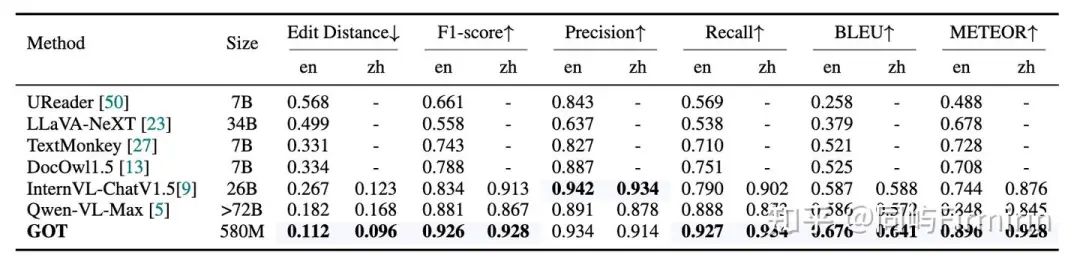
自然场景OCR
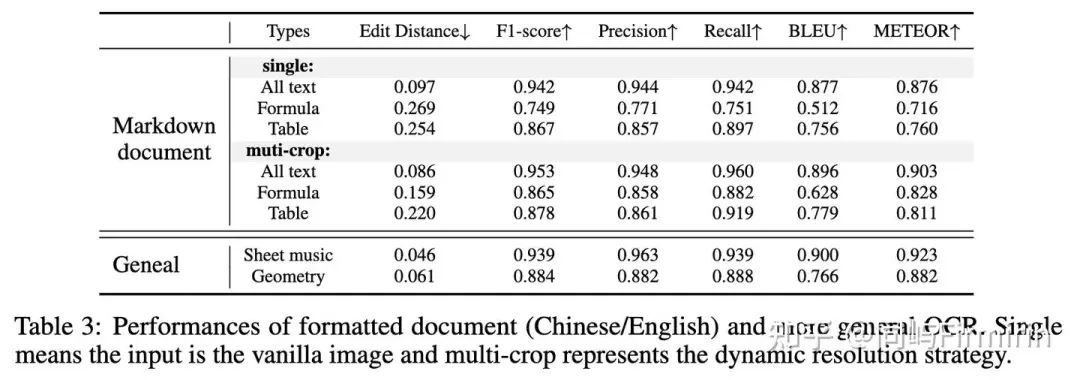
格式化场景OCR
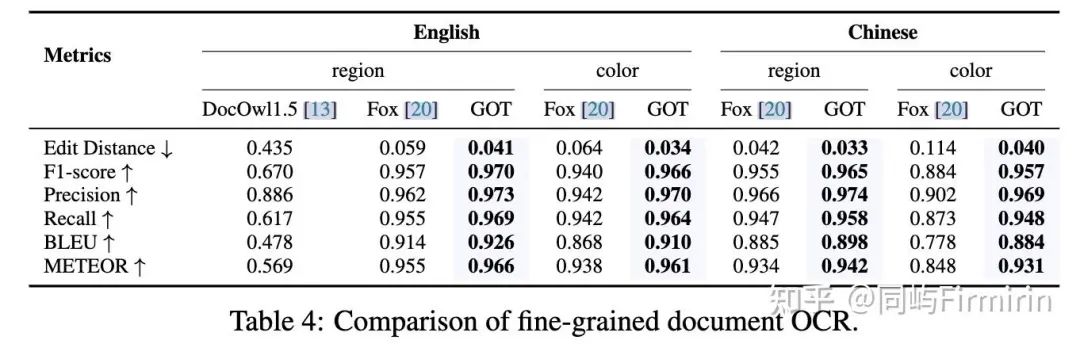
细粒度OCR
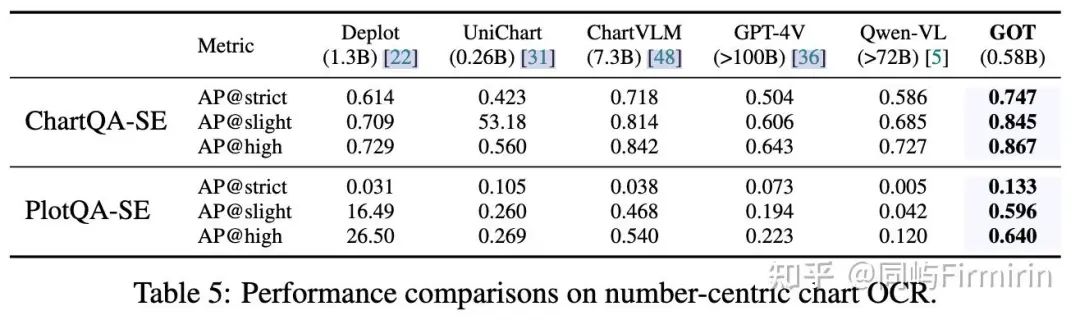
chart OCR
Vary(旷世+中科院)
论文标题:《Vary: Scaling up the Vision Vocabulary for Large Vision-Language Models》
arxiv:Vary: Scaling up the Vision Vocabulary for Large Vision-Language Models
Github:GitHub - Ucas-HaoranWei/Vary: [ECCV 2024] Official code implementation of Vary: Scaling Up the Vision Vocabulary of Large Vision Language Models.
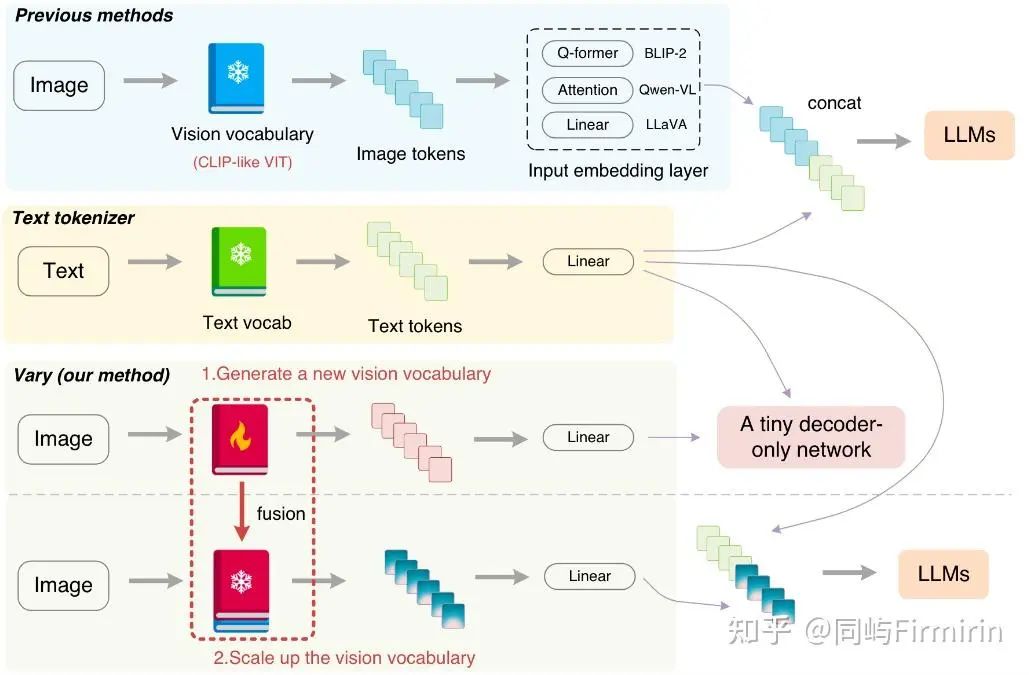
这张图对比了传统的vlm做法和vary
keypoints:
-
提出了视觉词表(vision vocabulary),做法是通过一个小的语言模型作为解码器对CLIP-like ViT进行再训练(在上一篇文章中也有类似做法),利用OCR数据作为正例,自然图像作为负例,得到一个具有新“词表”的ViT;
-
新的ViT与原ViT的输出在concat后再输入到LLM中;
-
数据方面,正例来自作者构造的PDF文档和chart,中英文都有,负例来自COCO
模型方法
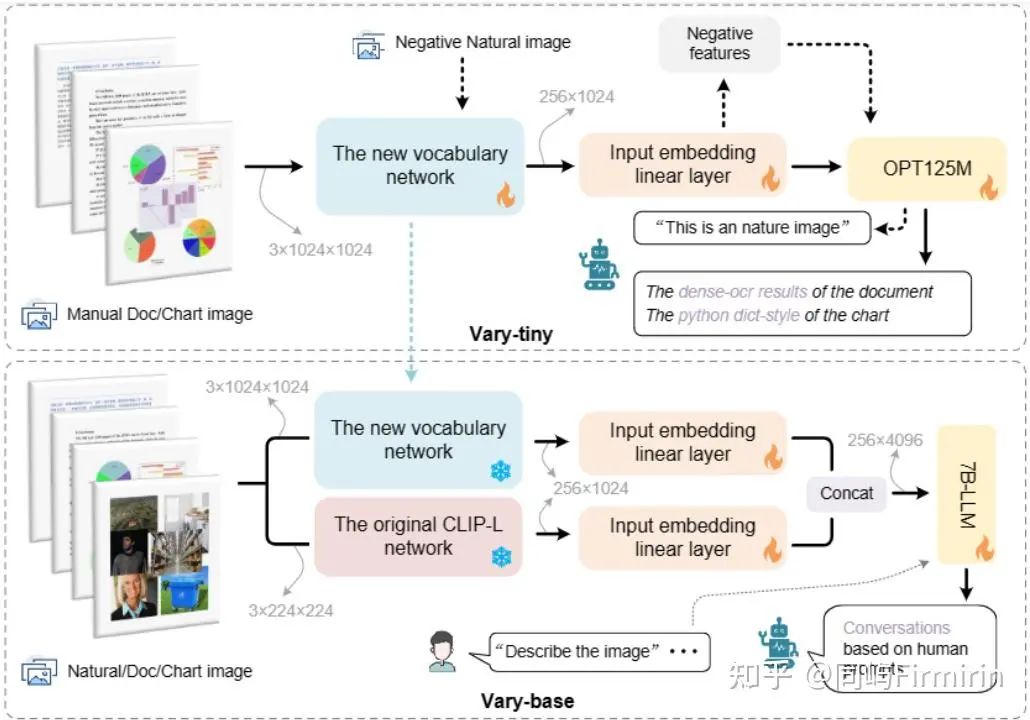
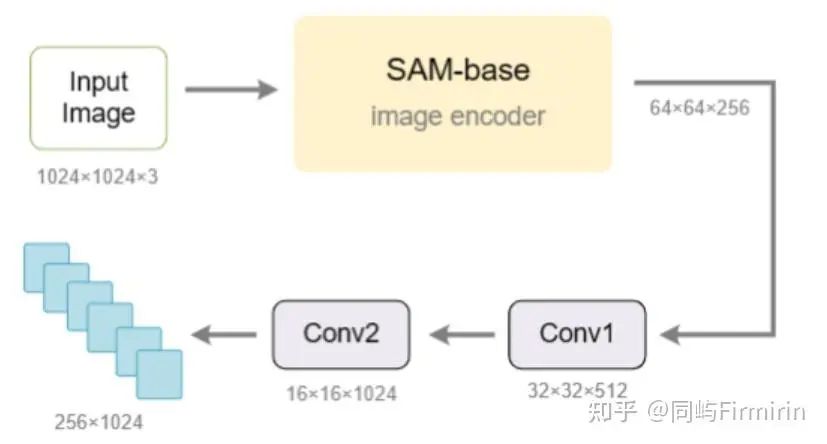
1. Vary-tiny
训练的第一步是构造具有新的vision vocabulary的ViT(作者命名为Vary-tiny)。这里选用了SAM的VIT,连接全连接层与一个文本解码器OPT-125M,这里也可以用更大的LLM;训练数据上构造了所谓的正负样例的图像文本对,正例是需要OCR的图像+OCR结果(包括密级文本,和Python dict-style的chart的结果);负例是来自COCO的图像+文本“This is an natural image”。
2. Vary-base
就是将Vary-tiny与原版CLIP-L ViT并行,二者输出的embedding先输入各自的线性层,再concat后输入LLM,这里Vary-tiny的输入图片分辨率是1024×1024,最后一层输出的特征图尺寸是64×64×256,跟CLIP-L的输出尺寸对不上,因此又加了两个卷积层进行转换。
这一步的训练会冻结两个ViT,放开线性投射层和LLM。数据包含自然场景与OCR场景的VQA。
数据
1. 训练第一步(学习新词表)
文档数据:主要是高分辨率的图像-文本对作数据集的正例,尤其是OCR可以训练模型的细粒度图像感知能力。这块的数据集是作者自建的,收集了arXiv上的PDF文章然后用PyMuPDF提取文本信息以及将每一页转换为图片。构建了1M的中文和1M的英文文档图像-文本对。
图表数据:现有的LVLMs的图表理解能力很差,因此这也是新词表需要重点掌握的知识。作者从网上找了一些语料,分别通过matplotlib和pyecharts绘制图表(中英文各750k),并将文本真实值转换为Python的字典形式。
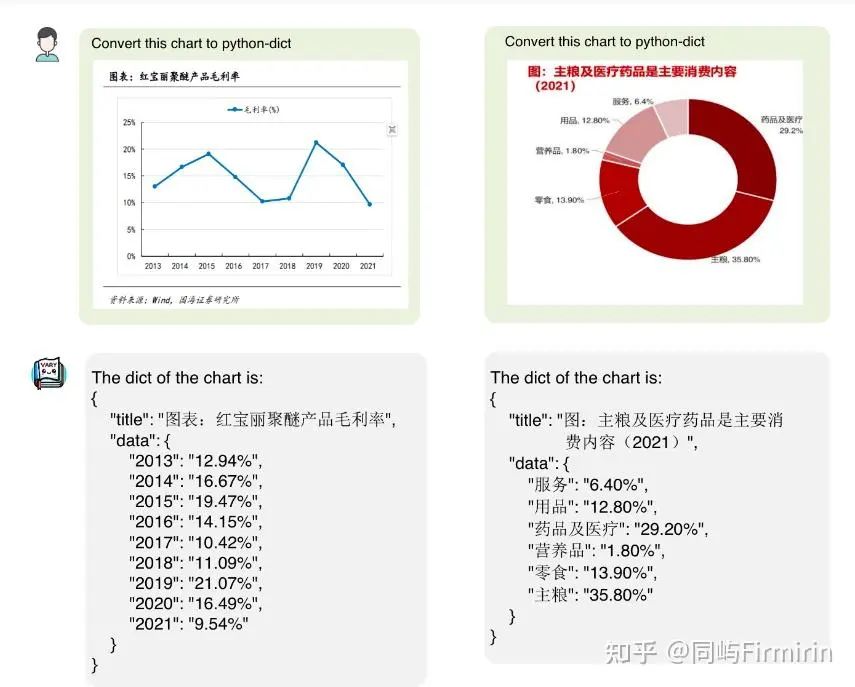
负例的自然图像:对于自然图像数据CLIP处理的非常好,因此需要确保新的词表不会对其造成干扰。因此,作者又从COCO数据集中采样了120k张图片作为负例的图像-文本对,以此来保证新的词表网络能够正确的编码这些自然图像。
2. 训练第二步(合并后训练)
LATEX文档:从arXiv上收集了一些.tex文档,然后提取其中的表格、数学公式和纯文本,通过pdflatex进行重新渲染,得到了50w的英文页面和40w的中文页面。
语义关联图表渲染:利用GPT-4根据相关语料库生成了200k的高质量图表数据用于训练Vary-base。
通用数据:先用从LAION-COCO中采样的4 million样本进行预训练,然后用LLaVA-80k或LLaVA-CC665k以及DocVQA和ChartVQA作为SFT数据集。
格式:<|im_start|>user: “” “texts input”<|im_end|> <|im_start|>assistant: “texts output” <|im_end|>
实验
作者在做个数据集对模型进行了评估,主要包括:
-
做着自己创建的OCR测试集,用以测试模型的细节感知能力;
-
DocVQA和ChartQA,测试模型对下游任务的提升;
-
MMVet,测试模型的通用性能。
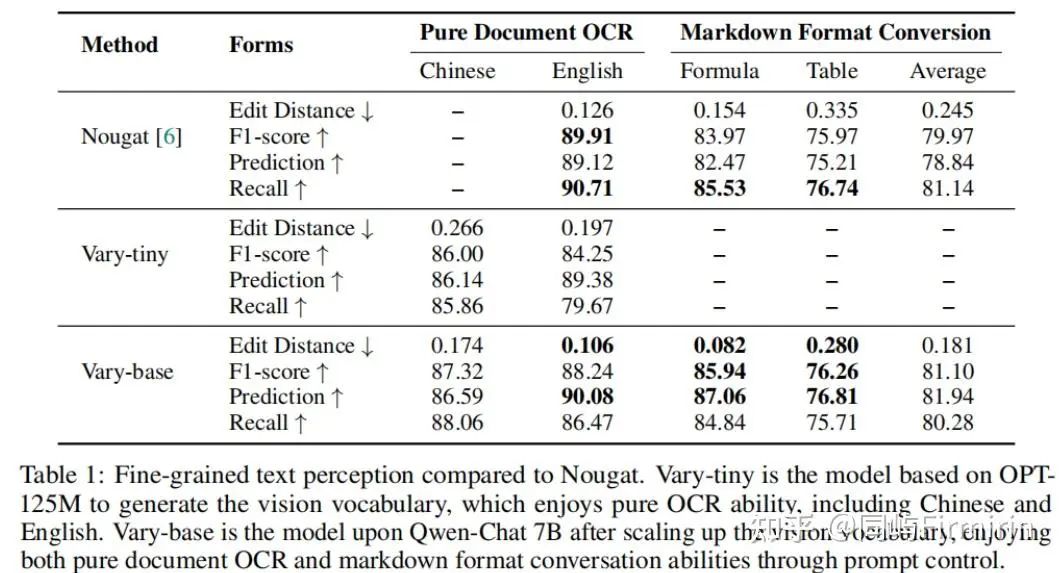
细节感知能力
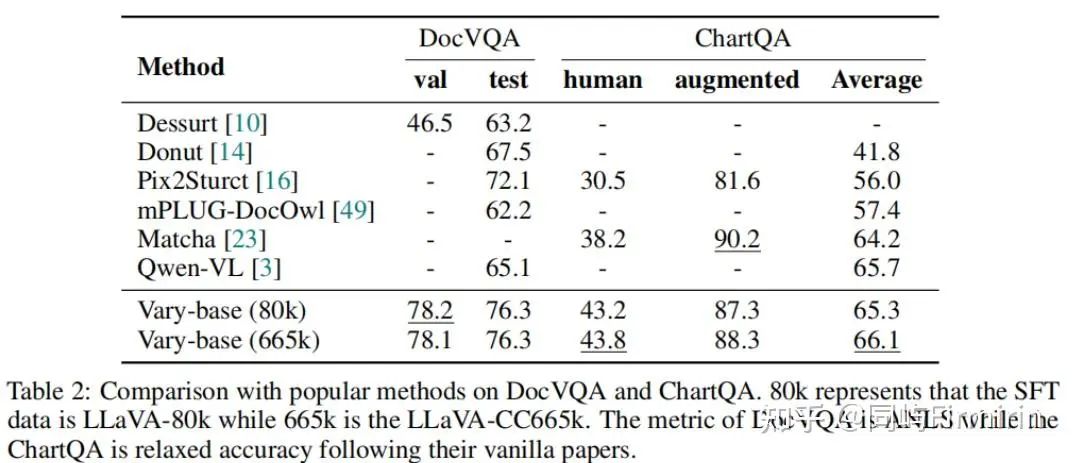
下游任务能力
通用能力,主要是测是否造成了通用场景能力的下降
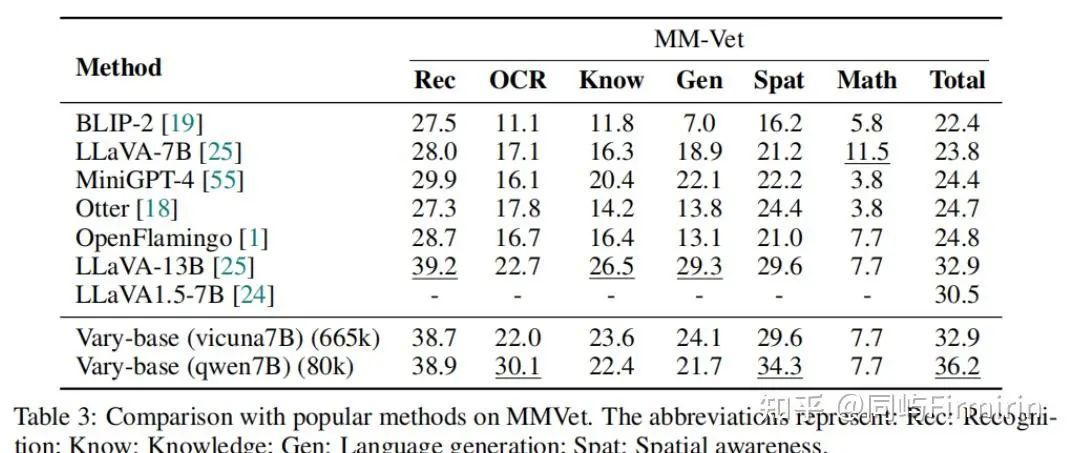
Vary家族
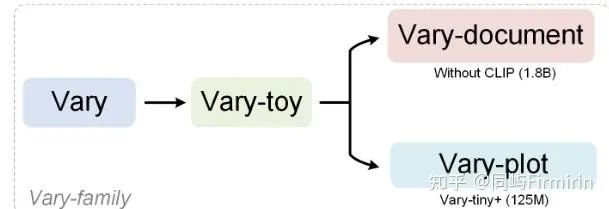
TextMonkey
-
论文链接:https://arxiv.org/abs/2403.04473
-
代码地址:https://github.com/Yuliang-Liu/Monkey
-
标题:《TextMonkey: An OCR-Free Large Multimodal Model for Understanding DocumentTextMonkey: An OCR-Free Large Multimodal Model for Understanding Document》
该系列的还有Monkey和Mini-Monkey。
1. keypoints:
-
Shifted Window Attention:现有的多模态大模型,如 Monkey 和 LLaVA1.6,通过将图像切分为小块来提高输入分辨率。然而这种裁剪策略可能会无意中分割同一个单词,导致语义不连贯。本作采用滑动窗口注意力机制建立了块与块之间的上下文联系,参考了Swin Transformer。
-
Token Resampler:提升分辨率会造成token过长,并存在相当的冗余,作者使用相似度作为依据,选择更重要的tokens。
-
支持文本定位,通过不同的提示词控制模型是否输出带bbox的OCR结果。
2. 模型方法
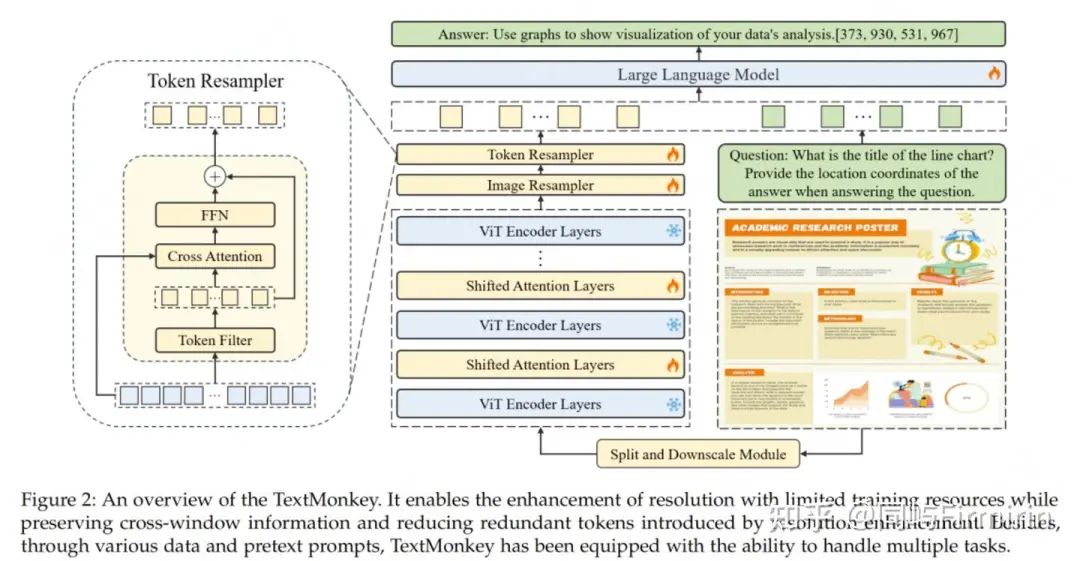
数据前向传播流程:
- 使用 sliding window 将输入图像切分成无重叠的 patches(其实也是 window),patch 大小为 448x448,然后这些 patch 会被进一步细分为 14x14 的更小的 patches,每个小的 patches 被视为一个 token,然后在每个 window 内部使用预训练好的 CLIP model 来提取特征。为了建立不同 window 的连接,在 Transformer block 之间会使用 Shifted Window Attention
2. 为了生成层级式的表示,输入的原图会 resize 到 448x448 大小后输入 CLIP 中来抽取全局特征,并且将全局特征和每个 patch 的特征一起送入 shared image resampler 用于和 language domain 对齐
3. 输入 Token resampler 中,通过压缩 token 的长度来进一步最小化在 language space 中的冗余
4. 将得到的特征和输入的文本问题一起送入 LLM 中,得到最终的回答
2.1 Shifted Window Attention
先将原图划分为不重叠的448 * 448的windows,再对每个window分别应用CLIP ViT 编码。为了合并不同窗口之间的交互并增强图像的上下文理解,会按照类似swin tr的做法,滑动窗口向左上角方向循环移动,从而产生新的窗口。通过掩码机制进行自注意力计算,将自注意力计算限制在新的窗口内。
2.2 Image Resampler
Qwen-VL的cross-attn操作。
2.3 Token Resampler

猜测在扩大图像分辨率之后,视觉部分的 token 也会存在冗余。本文根据以往确定语言元素相似性的方法,对已经映射到语言空间的图像 token 的相似性进行了度量:在图像 Resampler 之后随机选取 20 个有序特征,利用余弦相似性成对比较这些特征的相似性,得到的结果如图 2 所示。颜色越深代表相似性越高,实验发现每个图片的 token 都有一个到几个类似的 token,图片特征中存在冗余。
同时,本文还观察到某些 token 是高度独特的,并且缺乏其他相似的 token,如图中的第四个 token,这表明这个 token 是更为重要的。因此本文选用相似度来度量并识别独特的视觉 token。并提出 Token Resampler 来压缩冗余视觉 token。通过计算每个 token 与其他 token 的相似度,过滤得到最重要(相似度最低)的 K 个 token。同时,为了避免直接丢弃其他 token 造成的信息丢失,这里还会利用过滤得到的 K 个 token 作为查询,并采用交叉注意力机制进一步融合所有特征。
3 数据
3.1 Position-Related Task
为了缓解 LLM 的幻觉问题(可能产生与所提供的图像无关的错误相应),本文旨在增强 LLM 在回复的时候可以分析和结合视觉信息的能力。本文对现有的问答数据集进行了修改:将答案的位置信息集成到答案本身中,为了保持直接对话的原始能力,还保留了原始的问答任务。
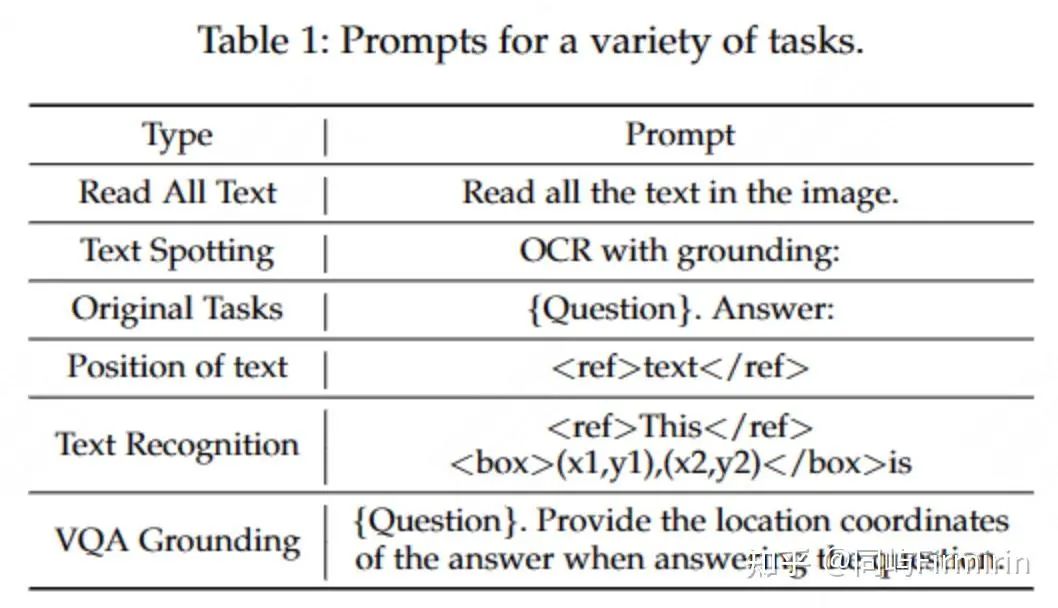
为了标准化不同比率地图像,使用 (0,1000) 的尺度来表示位置信息。因此在分辨率为 HxW 的图像中,文本坐标 (x, y) 将归一化为 [x/H*1000] , y 也一样。
3.2 Dataset Construction
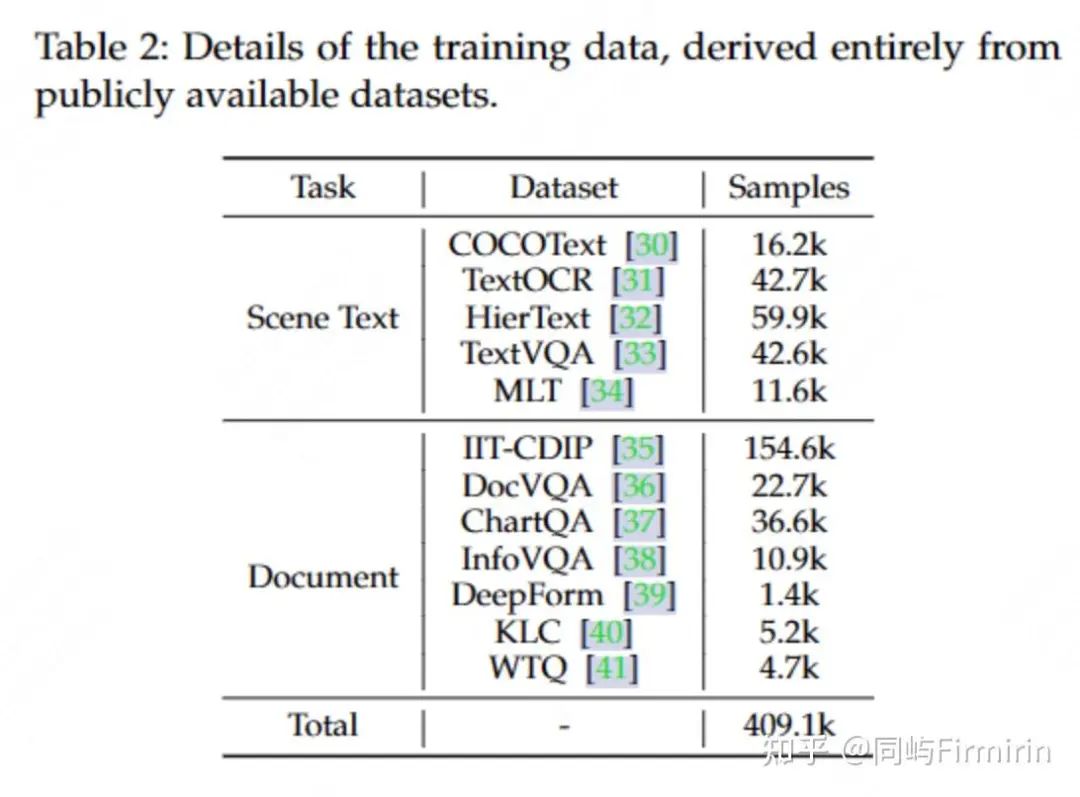
实验
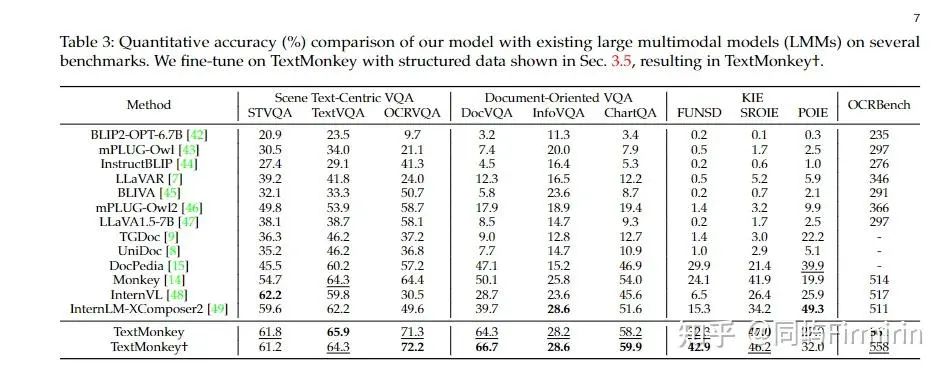
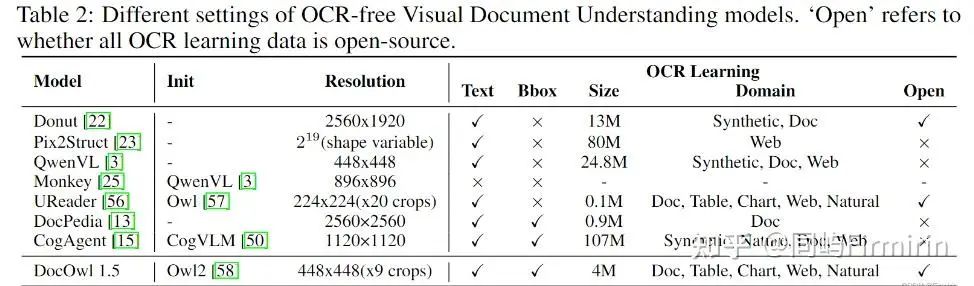
mPLUG-DocOwl 1.5(阿里xPLUG)
Arxiv:arXiv reCAPTCHA
标题:mPLUG-DocOwl 1.5: Unified Structure Learning for OCR-free Document Understanding
项目:mPLUG-DocOwl/DocOwl1.5 at main · X-PLUG/mPLUG-DocOwl · GitHub
Keypoints
-
跨模态(图、表、pdf等)的统一文档结构学习;
-
H-Reducer:用卷积层聚合水平相邻的视觉特征,更好地保持视觉和语言特征对齐过程中的结构和空间信息;
-
开源了几个OCR数据集,包括一个4M规模的多样化OCR数据集,包含多种场景的OCR以及文本Grounding;
-
系列只支持英文。
模型与训练
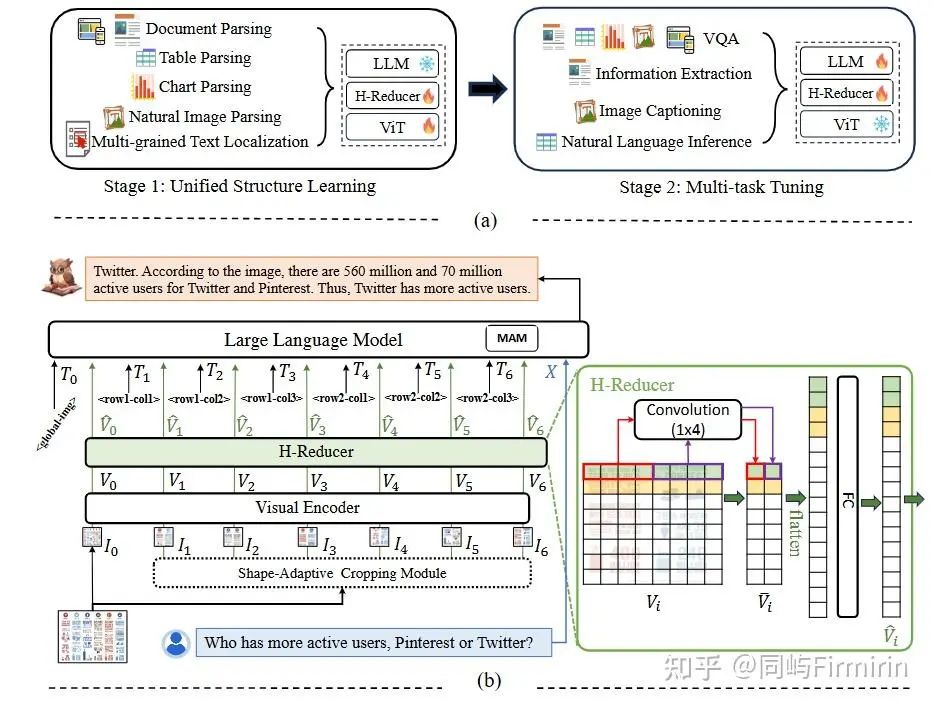
模型方法
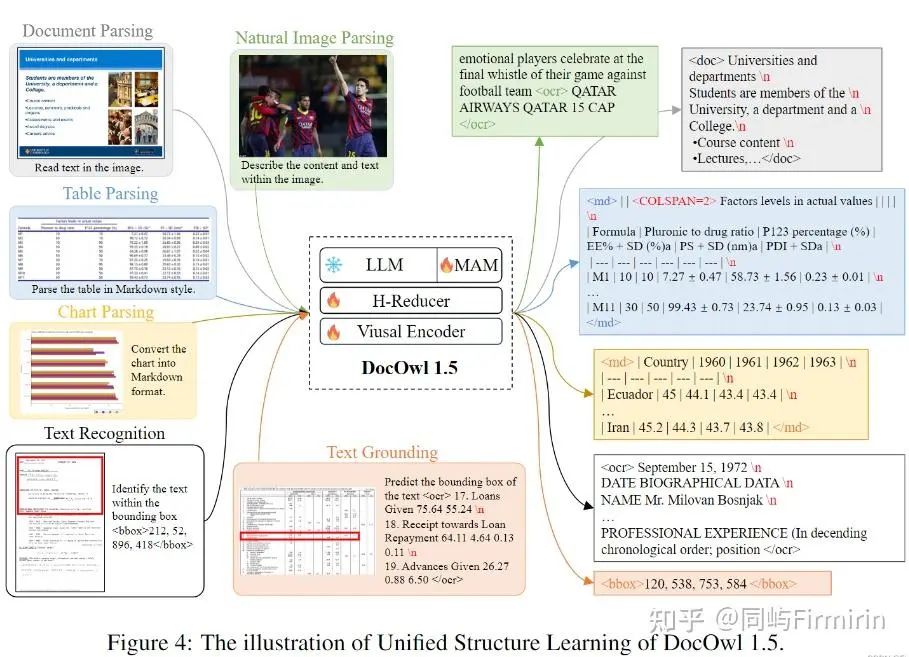
高分辨率图像编码
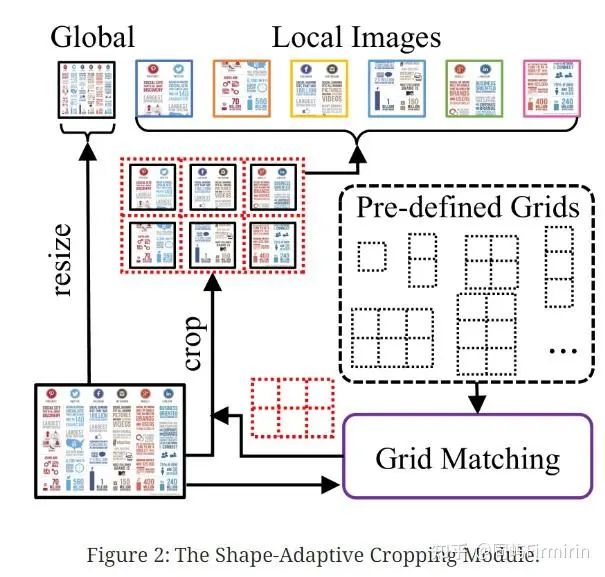
沿用前身工作Ureader的做法,属于无参做法,预设一组不同长宽比的Gird(每个Gird由若干448x448的块构成),选择跟输入图像长宽比最接近且对原图分辨率最接近的Gird,将原图resize为Gird大小,再按Grid切图。切好的子图分别输入ViT编码得到Token。具体做法可参考博客:[论文] UReader - 知乎。
H-Reducer
多模态大型语言模型有两种流行的vision-to-text方式:MLP和可学习查询的交叉注意力模块。作者认为这两种方式不能适应于高分辨率的富文本信息的图片。前者在处理高分辨率图像时token太长,后者减少视觉序列的长度到可学习查询的数量,但在语义融合过程中可能会丢失空间信息。
作者设计了H-Reducer,它不仅减少了视觉序列长度,而且保留了空间信息。
由卷积层组成,以减少序列长度,全连接层将视觉特征投影到语言嵌入空间。由于文档图像中的大多数文本信息从左到右排列,因此水平文本信息在语义上通常是连贯的。因此,卷积层中的内核大小和步幅大小设置为 1x4 以集成水平 4 个视觉特征。
为了表征裁剪图像在原图的位置,只需在每个裁剪图像的视觉特征之前添加特殊的文本标记“<rowx_coly>”,其中 x 和 y 分别代表行和列索引。全图的索引为“<global_img>”,避免了引入额外的参数。

MAM
沿用mPLUG-Owl2做法,在LLM中使用Modality-adaptive Module(MAM)来更好的区分视觉的和文本的输入。有点像MoE,visual和text的输入会用不同的linear layers作为kv projection。
训练
2阶段训练,第一阶段冻结LLM,第二阶段冻结ViT。
数据
分两步,先做统一结构学习(PT),再做SFT。
统一结构学习 Unified Structure Learning
一般的多模态大模型使用图像-文本对进行学习。使用这些大模型参数初始化只能继承shallow的文本识别能力,但远不具备从各种各样的富文本图像中理解复杂文本以及结构信息的能力。
为了使模型获得这种能力,作者设计了覆盖5个domain的统一结构学习(Unified Structure Learning),包括结构解析化任务(natural images, documents, tables, charts, and webpages)。和多粒度文字定位任务(multi-grained text localization tasks)。
构造的数据集:Struct4M。
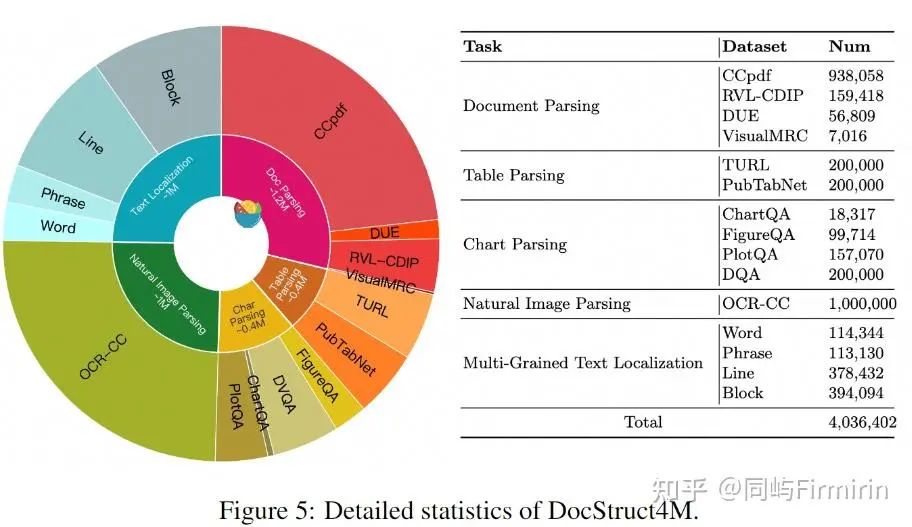
5种结构解析工作,主要是在OCR标注中加入表示文档结构的信息,包括:
Document Parsing文档解析:在文档或网页中,文本之间的水平和垂直距离形成了主要的布局信息。因此,为了使结构感知解析任务适用于大多数文档和网页,作者在文本序列中添加额外的’\n’和空格来表示不同的线和水平距离,水平距离越大,空格越多。
Table Parsing表格解析:遵循Markdown的主要语法,用’|‘和换行符(’\n’)表示表结构。为了表示跨越多行和多列的单元格,在值之前添加了特殊的文本标记’<COLSPAN=x>‘和’<ROWSPAN=y>’
Chart Parsing图表解析:仍然使用了Markdown代码来表示图表的数据。
Natural Image Parsing自然图像解析:与上述以文本为主导的图像不同,自然图像的语义是自然物与场景文本的结合。作者通过拼接通用caption和OCR文本来构造。
多粒度文本定位
对于可视化文档理解,结构感知解析任务主要侧重于根据整体结构组织文本,而忽略了特定文本与局部位置之间的对应关系。将文本与图像中的具体位置联系起来是视觉文档的另一种基本结构理解能力。
为了支持文本位置学习,我们设计了两个对称的任务,即多粒度文本grounding和多粒度文本识别。前者预测给定文本的边界框,后者给定边界框后识别框中文本。
四种粒度是:
word:边界框的最小粒度,仅指1个单词。为了确保单词可见并且答案是唯一的,太小的单词(归一化面积< 0.001)和在同一图像中出现多次的单词被排除在候选词之外
phrase:由同一行内的多个相邻单词组成
line:通过垂直距离判断为水平平行的文本
block:多个line组成,2行到总长度的一半不等。
SFT
通过统一结构学习,模型可以很好地理解各种文档图像的结构,但不能按照用户的指令去做不同类型的任务,例如指定信息提取。

使用的文档带有详细推理解释的指令微调训练集。 DocReason25K中的问题来源于DocVQA, InfographicsVQA, WikiTableQuestions, VisualMRC, ChartQA以及TextVQA。 DocReason25K中的详细推理解释由GPT3.5或GPT4V产生,并通过和人工标注的简单回复进行对比来过滤错误的答案。
与基准数据集中的原始问题相比,DocReason25K中的问题增加了“'Answer the question with detailed explanation”的提示。与基准数据集中的原始问题相比,DocReason25K中的问题增加了“'Answer the question with detailed explanation”的提示。
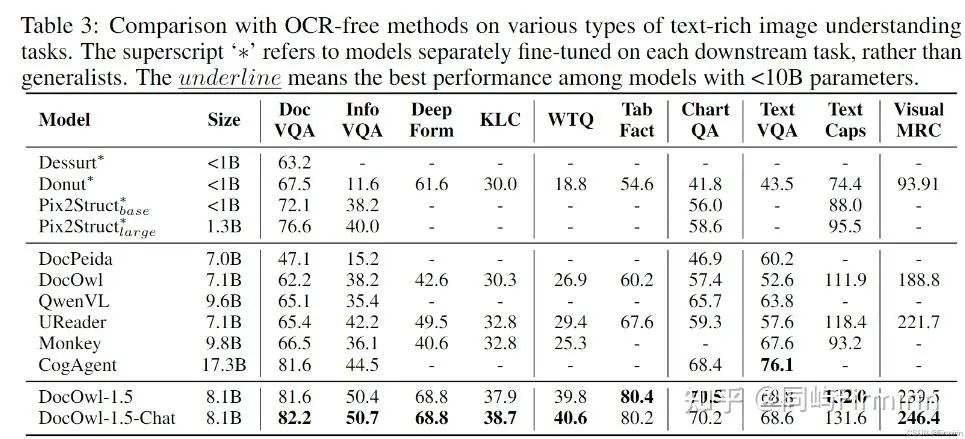
实验
mPLUG-DocOwl 2(阿里xPLUG)
Arxiv:arXiv reCAPTCHA
标题:mPLUG-DocOwl2: High-resolution Compressing for OCR-free Multi-page Document Understanding
项目:mPLUG-DocOwl/DocOwl2 at main · X-PLUG/mPLUG-DocOwl · GitHub
keypoints:
-
在1.5版本上增加了多页OCR能力;
-
从1.5的稠密visual token方案改变为稀疏visual token,一页OCR只需要324 tokens;
模型方法
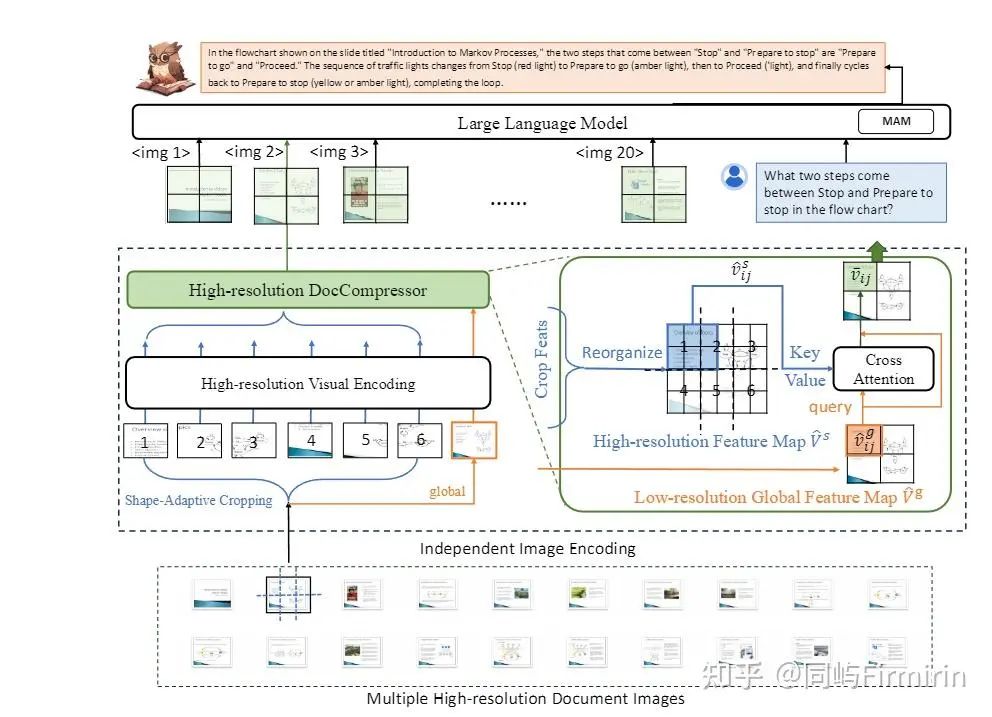
模型整体延续了DocOwl 1.5的结构,对于每一张高清文档图片会采用Shape-adaptive Cropping模块进行切片,同时将原图放缩为一个低分辨率全局图,随后每个切片和全局图会单独经过High-resolution Visual Encoding进行编码,包括ViT提取特征,以及H-Reducer水平合并4个特征并将纬度对齐到LLM。之后,DocOwl2采用High-resolution DocCompressor对视觉特征进行压缩。
压缩方案简单来说就是用global图的一块作为query,对应的local图作为kv,作cross-attn。
考虑到同一个布局单元的文字信息语义连贯,更容易进行语义总结,作者希望进行文档图片特征压缩的时候以布局相关特征作为指导。低分辨率全局图上文字难以辨认但布局信息得到保留,因此作者采用低分辨率的全局图片特征作为压缩指导(query),以高分辨率切片特征作为压缩对象(key/value),通过cross-attention进行压缩。
此外,低分辨率全局图片的每一个特征只编码了部分区域的布局信息,如果让每个低分辨率特征都关注所有高分辨率特征不仅增加压缩难度,而且大大增加了计算复杂度。
为此,作者对于每一个query都从切片特征中挑选了相对位置一致的一组高分辨率特征作为压缩对象,其数量和切片的数量一致,并可能来自不同的切片。经过该压缩模块之后,任意形状的文档图片的token数量都缩减为了全局图片的token数量。DocOwl2的单个切片以及全局图片都采用了504x504的分辨率,因此,最终单个文档图片的token数量为(504x504)/(14x14)/4=324个。
模型训练
初始化:
LLM:mPLUG-Owl2
ViT:CLIP ViT/L-14
DocCompressor:2 layers of cross attention
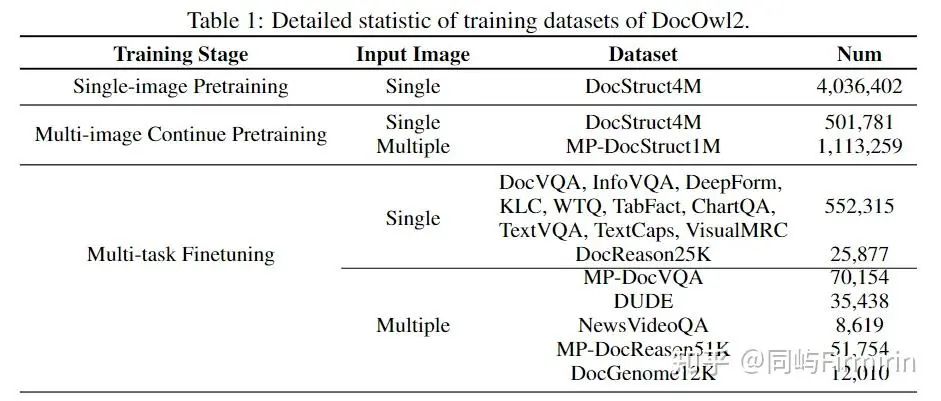
DocOwl2由3个阶段进行训练:单页预训练,多页预训练,以及多任务指令微调。
S1:为了充分训练模型对于文档图片的压缩以及信息的保留能力,单页预训练采用了DocOwl1.5的结构化解析数据DocStruct4M,其任务为输入文档图片,解析出图片中所有的文字信息。tuned:MAM、ViT、DocCompressor、H-Reducer。
S2:之后,为了训练模型区分多页文档特征的能力,多页预训练阶段设计了Multi-page Text Parsing任务和Multi-page Text Lookup任务。前者对于多页文档图片,要求模型解析指定的1-2页的文字内容,后者则给定文字内容,要求模型给出文字所在的页码。并引入自建开源数据集MP-DocStruct1M。tuned:MAM、DocCompressor、H-Reducer
S3:经过两轮预训练之后,作者整合了单页文档理解和多页文档理解的问答数据进行联合训练。即包含简洁回复,又包含给出具体解释和答案依据的指令微调数据。Tuned:all parameters except VIT。
实验
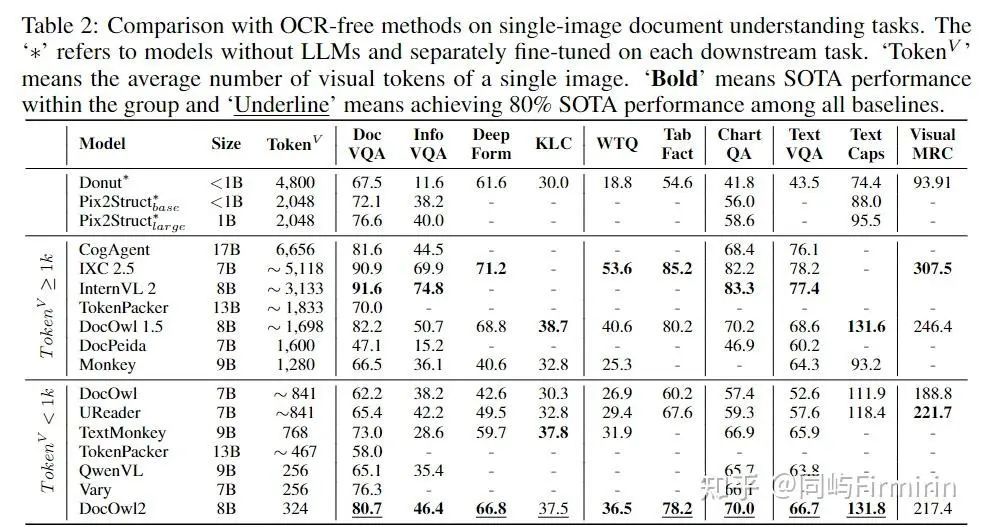
重点关注OCR相关任务的能力,以及token消耗。
AI大模型学习路线
如果你对AI大模型入门感兴趣,那么你需要的话可以点击这里大模型重磅福利:入门进阶全套104G学习资源包免费分享!
扫描下方csdn官方合作二维码获取哦!

这是一份大模型从零基础到进阶的学习路线大纲全览,小伙伴们记得点个收藏!

第一阶段: 从大模型系统设计入手,讲解大模型的主要方法;
第二阶段: 在通过大模型提示词工程从Prompts角度入手更好发挥模型的作用;
第三阶段: 大模型平台应用开发借助阿里云PAI平台构建电商领域虚拟试衣系统;
第四阶段: 大模型知识库应用开发以LangChain框架为例,构建物流行业咨询智能问答系统;
第五阶段: 大模型微调开发借助以大健康、新零售、新媒体领域构建适合当前领域大模型;
第六阶段: 以SD多模态大模型为主,搭建了文生图小程序案例;
第七阶段: 以大模型平台应用与开发为主,通过星火大模型,文心大模型等成熟大模型构建大模型行业应用。
100套AI大模型商业化落地方案

大模型全套视频教程

200本大模型PDF书籍

👉学会后的收获:👈
• 基于大模型全栈工程实现(前端、后端、产品经理、设计、数据分析等),通过这门课可获得不同能力;
• 能够利用大模型解决相关实际项目需求: 大数据时代,越来越多的企业和机构需要处理海量数据,利用大模型技术可以更好地处理这些数据,提高数据分析和决策的准确性。因此,掌握大模型应用开发技能,可以让程序员更好地应对实际项目需求;
• 基于大模型和企业数据AI应用开发,实现大模型理论、掌握GPU算力、硬件、LangChain开发框架和项目实战技能, 学会Fine-tuning垂直训练大模型(数据准备、数据蒸馏、大模型部署)一站式掌握;
• 能够完成时下热门大模型垂直领域模型训练能力,提高程序员的编码能力: 大模型应用开发需要掌握机器学习算法、深度学习框架等技术,这些技术的掌握可以提高程序员的编码能力和分析能力,让程序员更加熟练地编写高质量的代码。
LLM面试题合集

大模型产品经理资源合集

大模型项目实战合集

👉获取方式:
😝有需要的小伙伴,可以保存图片到wx扫描二v码免费领取【保证100%免费】🆓


















 1259
1259

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









