










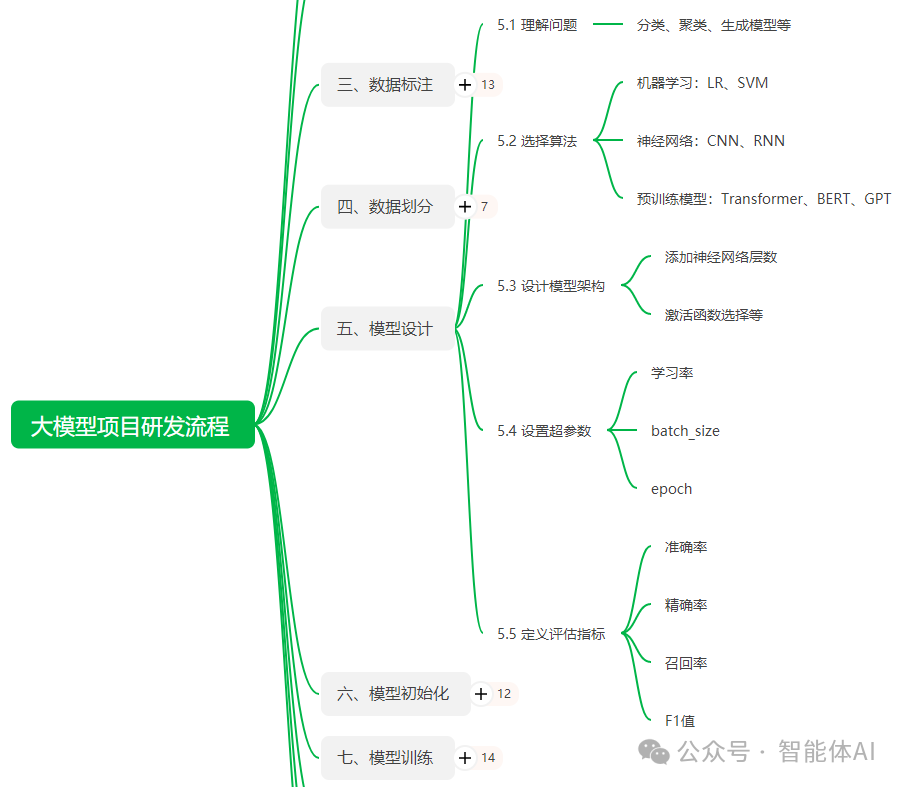
模型设计是大模型项目研发的核心环节,它决定了模型的性能、效果以及在实际场景中的适用性。设计一个高效的模型不仅要求对算法的精通,还需要全面理解问题背景、合理调整模型架构和参数,并构建科学的评估体系。本文将深入探讨大模型项目研发流程中的模型设计,从技术细节到常见问题及其解决方案,帮助读者全方位理解如何设计高效的大模型。
一、理解问题
在设计模型之前,最重要的一步是理解所要解决的问题。问题类型决定了模型设计的方向,并影响后续的算法选择和架构搭建。以下是几种常见的问题类型:
1. 分类问题
分类问题是指将输入的数据分配到预定义的类别中。常见应用场景包括垃圾邮件检测、图片分类、情感分析等。分类问题通常通过监督学习来解决,根据类别的数量可以分为二分类和多分类问题。
技术要点:
-
数据标签的准备:分类任务依赖于充分标注的数据集,标签质量直接影响模型表现。
-
类别不平衡:对于类别分布不均衡的分类任务,可能需要采取重采样或调整损失函数等策略。
2. 聚类问题
聚类问题是无监督学习的一种,模型根据数据的相似性将其分为若干组(簇)。聚类常用于客户细分、推荐系统和异常检测等场景。
技术要点:
-
选择合适的相似性度量:常见的相似性度量包括欧氏距离、余弦相似度等,根据数据特征的不同选择合适的度量方式。
-
确定簇的数量:有些算法(如K均值聚类)需要预先指定簇的数量,这一决定通常需要基于数据的探索性分析。
3. 生成问题
生成模型旨在学习数据的分布并生成新的样本。生成对抗网络(GAN)和自回归模型(如GPT)是典型的生成模型。生成模型应用广泛,从图像生成到自然语言生成,再到语音合成。
技术要点:
- 模式崩溃问题:在GAN中,生成的样本有时会缺乏多样性,这被称为模式崩溃。可以通过模型结构改进或优化算法来缓解这一问题。
常见问题及解决方案
-
问题**:**问题定义不明确。如果问题没有准确的定义,可能会导致后续模型的设计偏离初衷。
解决方案:与业务团队或客户反复沟通,确保问题理解到位,并通过明确的指标来量化目标。
-
问题**:**对问题的理解不够深入,导致模型设计偏差。
解决方案:确保充分理解问题背景,进行深入的数据探索和业务调研,明确模型的目标和限制条件。
-
问题**:**类别不平衡影响分类模型的性能。
解决方案:使用加权损失函数、SMOTE等数据平衡技术,或者在模型评估时引入F1值等适应不平衡数据的指标。
二、选择算法
在理解了问题之后,接下来就是选择合适的算法。不同的问题类型和数据特征需要不同的算法,以下是几类常见的算法及其适用场景:
1. 传统机器学习算法
-
逻辑回归(LR):适用于二分类问题,尤其是当我们需要解释模型输出时,逻辑回归因其简单性和可解释性而备受青睐。
-
支持向量机(SVM):适用于高维数据的分类任务,能够通过最大化分类边界来提升模型的泛化能力。
2. 神经网络算法
-
卷积神经网络(CNN):主要用于图像处理任务,通过卷积层提取空间特征,广泛应用于计算机视觉领域。
-
循环神经网络(RNN):用于处理序列数据,尤其适合自然语言处理和时间序列预测。LSTM和GRU是RNN的变种,能有效解决梯度消失问题。
3. 预训练模型
-
Transformer:基于自注意力机制,广泛应用于自然语言处理任务,特别适合处理长文本的依赖关系。
-
BERT:双向编码表示模型,擅长处理需要上下文理解的任务,如阅读理解、情感分析等。
-
GPT:生成式预训练模型,擅长文本生成任务,能够生成连贯且有逻辑的长篇文本。
常见问题及解决方案
-
问题:算法选择不当,导致模型表现不佳。
解决方案:根据数据特性和任务需求选择合适的算法,通常需要通过实验来比较不同算法的表现,从而选择最优方案。
-
问题:算法复杂度过高,训练时间过长。
解决方案:尝试使用简化版的模型或基于数据的重要特征进行降维,利用并行计算或分布式计算框架加速训练。
三、设计模型架构
在选择好算法后,设计模型的具体架构是实现模型性能的关键。模型的深度、宽度、激活函数等设计细节会直接影响模型的表现。
1. 深度和宽度的设计
神经网络的层数和每层的节点数直接影响模型的容量。深层网络能够捕捉到更复杂的特征,但也增加了过拟合的风险。
-
深度网络:深层网络有助于处理复杂任务,但如果训练数据不足,可能会导致过拟合。因此,在增加层数的同时,可以考虑正则化方法来缓解过拟合。
-
宽度设计:在某些任务中,增加网络的宽度比增加深度更有效,尤其是当特征非常丰富时。
2. 激活函数的选择
激活函数引入了非线性,使得神经网络能够学习复杂的映射关系。常见的激活函数包括:
-
ReLU(线性修正单元):最常用的激活函数,具有计算简单、速度快的特点,适用于大多数深度学习任务。
-
Sigmoid:适合输出概率值的任务,但在深层网络中容易出现梯度消失问题。
-
Softmax:用于多分类问题,将输出转化为概率分布。
常见问题及解决方案
-
问题:过多的层数或参数导致模型过拟合。
解决方案:采用Dropout、L2正则化等方法防止过拟合,或使用早停法(Early Stopping)避免过度训练。
-
问题:激活函数选择不当,影响模型的训练效率。
解决方案:根据任务类型选择合适的激活函数,如对于深层网络可以使用ReLU或其变种(如Leaky ReLU、PReLU)来加速训练。
四、设置超参数
超参数的选择对模型的训练效果有着至关重要的影响。常见的超参数包括学习率、批次大小和训练轮次等。
1. 学习率(Learning Rate)
学习率决定了每次权重更新的步伐。学习率过大会导致模型无法收敛,过小则训练时间过长。
- 建议:通常使用自适应学习率算法(如Adam)自动调整学习率,或采用学习率衰减策略(如Learning Rate Decay)逐步降低学习率。
2. 批次大小(Batch Size)
Batch Size指每次权重更新时使用的样本数量。较大的Batch Size通常能加快训练速度,但需要更多的显存。
- 建议:在计算资源允许的情况下,优先选择较大的Batch Size,因为它有助于减少梯度更新的噪声,提升模型的稳定性。
3. 训练轮次(Epoch)
Epoch表示模型遍历整个数据集的次数。过少的Epoch可能导致欠拟合,而过多的Epoch则可能导致过拟合。
- 建议:可以使用早停法,当模型在验证集上的性能不再提升时停止训练,避免过拟合的发生。
常见问题及解决方案
-
问题:超参数调整不当,影响模型的训练效果。
解决方案:使用网格搜索(Grid Search)、随机搜索(Random Search)或贝叶斯优化等方法,系统地调整超参数,确保找到最佳配置。
五、定义评估指标
为了科学地评估模型的表现,必须设置合适的评估指标。不同任务需要不同的指标,常见的评估指标包括准确率、精确率、召回率和F1值。
1. 准确率(Accuracy)
准确率是最常用的评估指标,适用于类别分布较均衡的分类任务。
2. 精确率(Precision)
精确率衡量的是在所有预测为正类的样本中,实际为正类的比例。适用于需要减少误报的场景。
3. 召回率(Recall)
召回率是指实际为正类的样本中,被模型正确预测的比例。对于重视找到所有正类样本的任务,召回率更为重要。
4. F1值
F1值是精确率和召回率的调和平均数,适用于类别不平衡的数据集,能够在综合考虑精确率和召回率的同时提供平衡的评估。
常见问题及解决方案
-
问题:仅使用准确率作为评估指标时,数据不平衡可能导致误导性结果。
解决方案:根据任务场景选择合适的评估指标,尤其在不平衡数据上,推荐使用F1值或结合多个指标进行评估。
六、总结
本文详细探讨了大模型项目中的模型设计环节。模型设计需要全面理解问题、选择合适的算法、设计模型架构、设置超参数并定义科学的评估指标。希望通过本文的讲解,读者能够在实际项目中更好地进行模型设计和优化。未来的文章将继续探讨模型调试、优化以及部署的最佳实践。
一、全套AGI大模型学习路线
AI大模型时代的学习之旅:从基础到前沿,掌握人工智能的核心技能!

因篇幅有限,仅展示部分资料,需要点击下方链接即可前往获取
2024最新版CSDN大礼包:《AGI大模型学习资源包》免费分享
二、640套AI大模型报告合集
这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。

因篇幅有限,仅展示部分资料,需要点击下方链接即可前往获取
2024最新版CSDN大礼包:《AGI大模型学习资源包》免费分享
三、AI大模型经典PDF籍
随着人工智能技术的飞速发展,AI大模型已经成为了当今科技领域的一大热点。这些大型预训练模型,如GPT-3、BERT、XLNet等,以其强大的语言理解和生成能力,正在改变我们对人工智能的认识。 那以下这些PDF籍就是非常不错的学习资源。

因篇幅有限,仅展示部分资料,需要点击下方链接即可前往获取
2024最新版CSDN大礼包:《AGI大模型学习资源包》免费分享
四、AI大模型商业化落地方案

因篇幅有限,仅展示部分资料,需要点击下方链接即可前往获取
2024最新版CSDN大礼包:《AGI大模型学习资源包》免费分享
作为普通人,入局大模型时代需要持续学习和实践,不断提高自己的技能和认知水平,同时也需要有责任感和伦理意识,为人工智能的健康发展贡献力量。

















 813
813

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









