






听说过“多模态”吗?没听过就OUT啦!这可是网络安全领域的新晋网红。今天,咱们就来扒一扒这“多模态大模型后训练”的底裤,保证让你看完直呼内行!
大语言模型(LLMs)那可是相当聪明,能玩转各种任务,不用特意训练。但它们有个小缺陷,就是不太懂“多模态”的梗。啥是多模态?简单说,就是视觉、听觉、文本等等一起上,信息量更大!所以,为了让LLM更懂世界,就有了多模态大型语言模型(MLLMs)。
不过,这MLLMs也不是十全十美,在真实性、安全性、推理能力上还有点小问题。咋办?对齐算法来也!专门解决这些“疑难杂症”。
这篇文章要搞啥大事情?
简单来说,就是给网络安全多模态大型语言模型(MLLMs)的对齐算法来个大盘点!主要解决这几个问题:
- 对齐算法用在哪? 别慌,咱们把这些算法分分类,让你一看就懂,秒懂它们各自的用武之地。
- 对齐数据集怎么建? 数据可是AI的粮食!咱们来聊聊数据来源、模型响应、偏好注释这些关键因素,再扒一扒现有数据集的优缺点。
- 对齐算法咋评估? 别光说不练!文章整理了各种评估标准,教你如何科学评价这些算法的水平。
- 未来往哪走? 剧透一下未来发展方向,比如视觉信息整合、LLM对齐经验借鉴,以及MLLM作为智能体的机遇与挑战。
总而言之,这篇文章就是想帮你吃透网络安全多模态对齐算法,让学术界和工业界的小伙伴们都能更好地应用它们,一起推动这个领域的发展!
应用场景大揭秘:从通用到专业,一个都不能少!
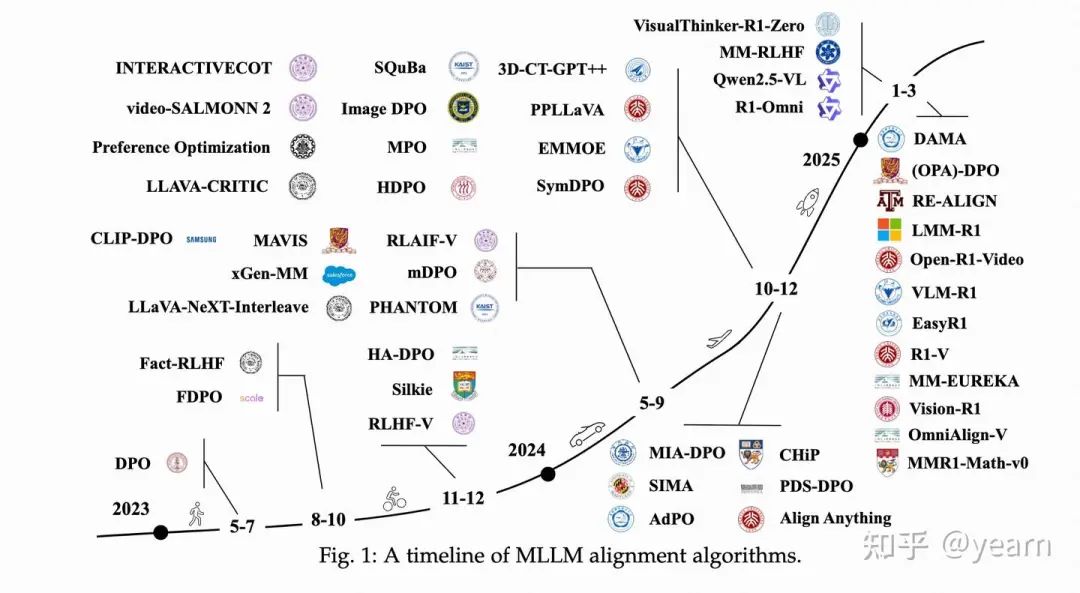
1. 应用场景分层解读
网络安全多模态大语言模型(MLLM)对齐算法的应用场景,可以分为三个层次:
- 通用图像理解: 主要目的是减少幻觉,提高模型在对话、推理等方面的表现。
- 多图像、视频和音频: 专门处理复杂的多模态数据,重点是减少幻觉,提高模型能力。
- 扩展应用: 把MLLM应用到特定领域,比如医学、数学推理、安全系统等,根据领域需求进行优化。
2. 通用图像理解与多模态的那些事
通用图像理解:不止于“看图说话”
MLLM对齐算法最初是为了解决多模态系统中的幻觉问题。但现在发现,它还能提升模型的安全性、对话能力、推理能力等等。
减少幻觉:让模型说真话
- Fact-RLHF: 第一个多模态RLHF算法,用人工标注的数据训练奖励模型,还加入了各种惩罚机制,防止模型胡说八道。
- DDPO: 提高更正数据的权重,让模型更重视正确的信息。
- HA-DPO: 让MLLM自己生成图像描述,然后用GPT-4来验证,再对样本进行重写,减少幻觉。
- mDPO: 引入视觉损失函数,解决模型忽视视觉信息的问题,避免模型“选择性失明”。
提升综合能力:全方位发展才是王道
- Silkie: 收集各种指令数据集,用GPT-4V评估,为DPO提供偏好数据。
- CLIP-DPO: 利用CLIP分数标注数据,提升幻觉减缓和零样本分类任务的表现。
- SIMA: 让模型自我评估生成的响应,提升多图像任务的表现。
- MM-RLHF: 通过更多样的数据和算法,进一步提升alignment的效果。
多模态O1发展:新思路,新方向
DeepSeek-R1的流行给MLLM社区带来了新的灵感。
- LMM-R1: 使用纯文本数学数据集,通过RLOO训练,在多模态数学基准上取得了改进。
- Open-R1-Video: 利用GRPO方法提升模型在视频领域的表现。
- VLM-R1: 应用R1方法处理指代表达理解任务,扩展了多模态推理能力。
3. 多图像、视频和音频:更复杂的挑战
- 多图像任务: MLLM在多图像理解方面常常遇到困难,MIA-DPO通过构建多图像偏好数据来解决,效果不错。
- 视频任务: 视频理解更复杂,DPO和交错视觉指令的结合,能有效提升视频任务的处理能力,比如LLaVA-NeXT-Interleave方法。
- 音频任务: 音频-视觉理解存在音频盲视问题,Video-SALMONN 2通过引入音频-视觉对齐机制,成功解决。
4. 扩展多模态应用:专业领域,量身定制
- 医学应用: 3D-CT-GPT++通过优化医学影像分析,减少诊断误差,达到临床级别准确性。
- 数学应用: MAVIS方法改进视觉数学问题解决框架,提高MLLM在数学推理中的表现。
- 安全性: AdPO和VLGuard等方法,通过优化训练数据和模型结构,提高模型鲁棒性,应对对抗性攻击。
- 代理和智能系统: INTERACTIVECOT和EMMOE方法,通过动态优化推理流程和分解任务,提高MLLM在嵌入式智能中的表现,尤其是在复杂决策过程中。
总结一下: 我们深入剖析了网络安全多模态大语言模型的各种应用场景,从通用图像理解到特定领域应用,展示了如何通过优化对齐算法来减少幻觉,提升模型在不同任务中的综合能力。特别是视频、音频、医学、数学等复杂领域,MLLM的潜力无限!
温馨提示: 以下表格总结了目前alignment策略常见的损失函数形式,方便大家参考。

MLLM对齐数据:AI的粮食,怎么种才好?
划重点:数据集的重要性
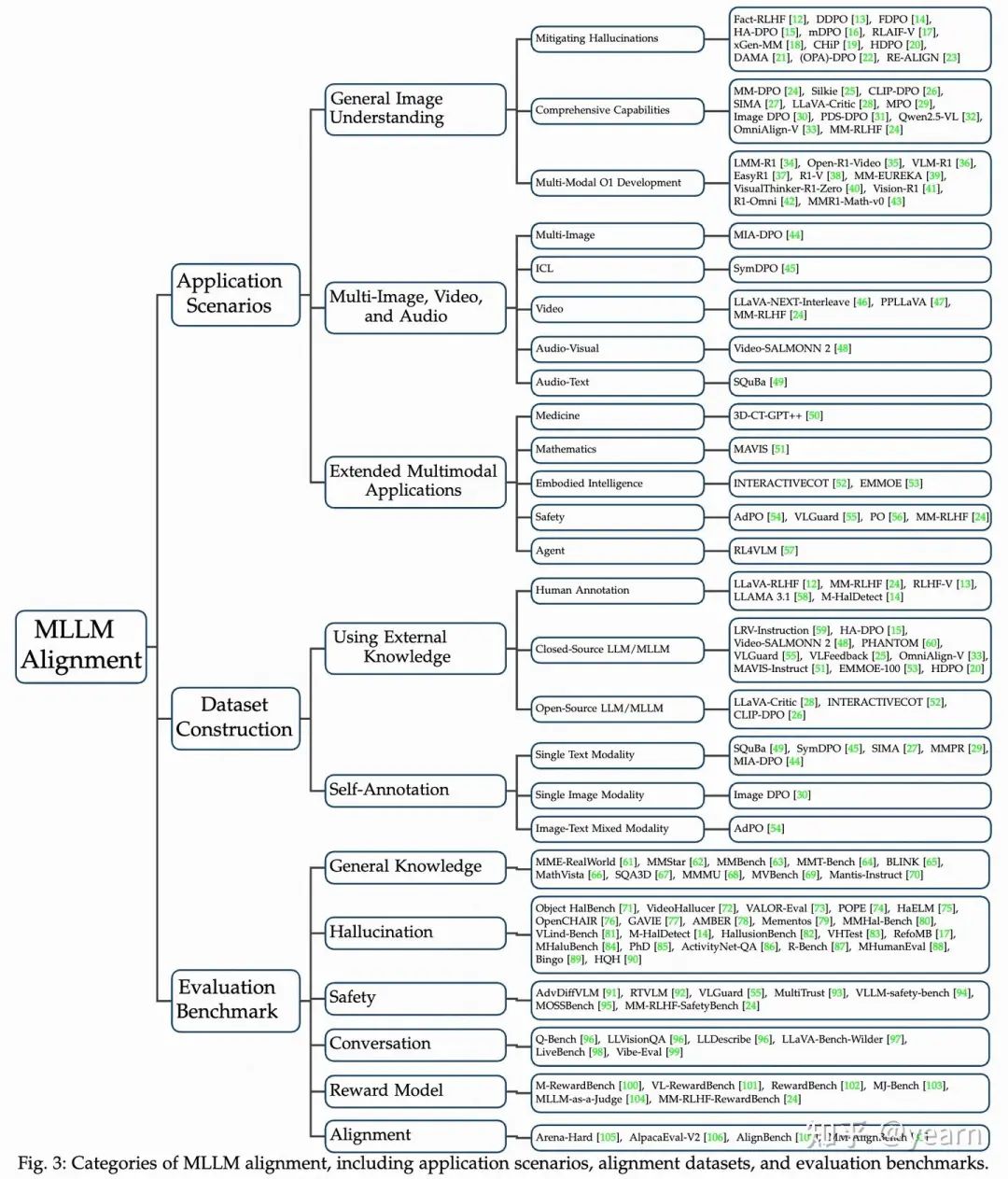
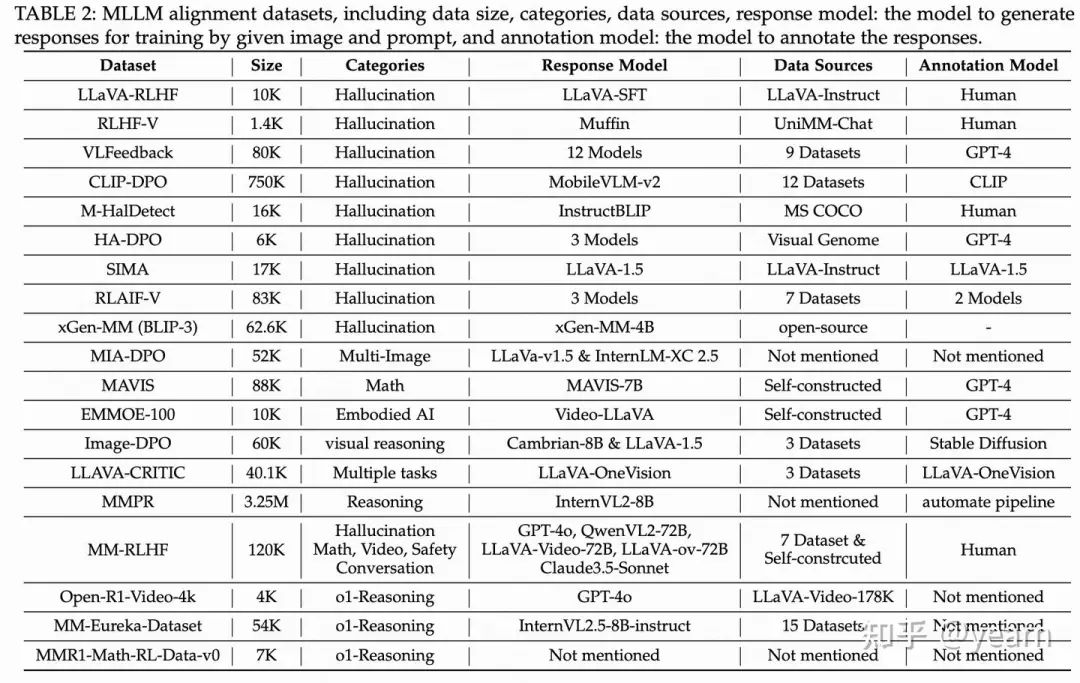
在网络安全多模态大型语言模型(MLLM)的研究中,对齐数据集是重中之重!构建多模态数据集需要大量的数据来源、生成方法和注释技术。研究者们对不同构建方法进行了分类,大致分为引入外部知识的数据集和依赖自我标注的数据集。
外部知识 vs. 自我标注:各有千秋
我们对现有MLLM对齐数据集进行了全面的分类与分析,主要关注以下几个方面:
1. 引入外部知识的数据集:
- 人工注释: 质量高,但成本也高,还可能存在主观性。
- 闭源LLM/MLLM: 比如GPT-4系列,可以大规模构建数据集,降低成本。
2. 自我标注的数据集:
- 单一文本模态: 比如SQuBa,用微调后的模型生成负样本,进行DPO对比。
- 单一图像模态: 比如Image DPO,通过对图像进行扰动,构建DPO偏好对。
- 图像-文本混合模态: 比如AdPO,构建原始/对抗图像及其模型响应的偏好对。
3. 数据质量和规模的平衡:
文章还讨论了如何平衡数据质量、规模与成本的关系,并展望了未来自动化数据增强技术的潜力,特别是如何利用自我标注方法提升数据质量。
实验告诉你:数据集构建的那些坑
- 数据集规模与质量的平衡: 引入外部知识的数据集质量高,但成本也高。自我标注的方法可以大规模生成数据,但质量较低,可能存在分布偏移问题。
- 自动化增强的潜力: 随着技术发展,自我标注方法有望解决当前数据质量低的问题,提高数据的多样性和可信度。
总结: 数据集的构建方法和质量控制是影响MLLM对齐效果的关键因素。未来研究应该关注如何在保证数据质量的同时,降低成本并提高数据集的规模。
模型评估:是骡子是马,拉出来溜溜!
现有的MLLM对齐评估基准被分为六个关键维度:通用知识、幻觉、安全性、对话、奖励模型、与人类偏好的对齐。
六大维度,全面评估
- 通用知识: 评估基础能力,比如MME-RealWorld、MMMU、MMStar等。
- 幻觉: 衡量生成内容与事实的一致性,比如Object HalBench、VideoHallucer、VALOR-Eval等。
- 安全性: 评估响应中降低风险的能力,比如AdvDiffVLM、RTVLM、VLGuard等。
- 对话: 测试模型是否能输出用户要求的内容,比如Q-Bench、LLVisionQA、LLDescribe等。
- 奖励模型: 评估奖励模型的表现,比如M-RewardBench、MJ-Bench、MM-RLHF-RewardBench等。
- 与人类偏好的对齐: 评估模型与人类价值观的对齐程度,比如Arena-Hard、AlpacaEval-V2、MM-AlignBench等。
总而言之: 这些评估基准旨在提高模型在实际场景中的鲁棒性,为开发更可靠的多模态系统提供指导。
未来工作与挑战:路漫漫其修远兮
随着网络安全多模态大型语言模型(MLLM)的迅速发展,将它们与人类偏好对齐已经成为研究的重点。但是,前方还有不少拦路虎:
挑战一:数据!数据!还是数据!
高质量和多样化数据集的稀缺问题仍然是老大难。
挑战二:视觉信息利用不足
很多方法主要依赖文本来构建正负样本,忽略了多模态数据的全部潜力,这可不行!
挑战三:缺乏全面的评估标准
当前的方法通常只在特定类型的基准上进行验证,普适性难以评估,需要更全面的评估方法。
未来方向:借鉴LLM和智能体研究
通过借鉴LLM后期训练策略和智能体研究的进展,可以揭示现有MLLM对齐方法中的局限,并克服这些挑战。
数据挑战:质量和覆盖范围是关键
- 高质量数据稀缺: 获取和注释多模态数据比LLM更复杂。
- 覆盖范围不足: 现有数据集在涵盖多样化多模态任务方面存在不足,需要构建一个涵盖广泛任务的综合数据集。
利用视觉信息进行对齐:三种方法,各有优劣
- 使用破损或无关图像作为负样本: 可以减少幻觉,提高鲁棒性,但缺乏质量度量,计算成本高。
- 基于破损图像生成新的问题和答案: 增加了文本比较的多样性,但生成额外负样本增加了计算开销。
- 使用像CLIP这样的余弦相似度度量来评估文本-图像匹配: 有助于减少数据噪声,但评分质量依赖于评估模型质量,可能受到模型偏见的影响。
综合评估:不能只看一面
未来的研究应采用更全面的评估方法,跨更广泛的任务评估对齐方法,以更好地展示其普适性和有效性。
全模态对齐:不仅仅是图像和文本
Align-anything开创了通过多模态数据集“align-anything-200k”实现全模态对齐的研究,涵盖了文本、图像、音频和视频。未来,超越图像/文本领域的对齐算法设计,尤其是针对其他模态的对齐,将是一个关键的趋势。
MLLM推理:从LLM中汲取灵感
LLM推理增强研究表明,强化学习算法和偏好数据对于提高LLM在复杂问题求解、长时上下文理解和生成任务中的表现至关重要。
- (1) 数据:规模与质量,效率至上
- 数据集逐渐达到百万样本规模。
- 采用“少即是多”的对齐,用最少的高质量数据激活预训练能力。
- (2) 优化框架:在线强化学习,多阶段优化
- 在线强化学习(RL)逐渐成为主流方法,缓解了分布偏移。
- 多阶段、协作优化已成为主流方法。
- 强化学习算法不断发展,朝着更高效的方向前进。
LLM对齐的启示:他山之石,可以攻玉
- 提高训练效率: 是否可以利用类似SimPO的无参考方法进一步提升训练效率?
- 减轻过度优化/奖励黑客问题: 通过平衡的训练数据集、早停、正则化技术等策略来应对。
MLLM作为智能体:未来可期,挑战犹存
MLLM结合了LLM强大的推理能力和处理多种模态数据的能力,在处理复杂的现实任务中具有很大优势。但是,仍然需要解决以下问题:
- 多智能体协作: 缺乏成熟的解决方案。
- 鲁棒性: 尚未得到系统验证,需引入对抗性鲁棒性测试和保障技术。
- 安全性: 引入更多复杂组件增加了安全风险,需要探索多种安全保护机制。
**总结:多模态大模型后训练的道路还很长,充满了挑战,但也充满了机遇。只有不断探索和创新,才能真正发挥MLLM的潜力,让AI更好地服务于人类!
*************************************2025最新版CSDN大礼包:《AGI大模型学习资源包》免费分享***************************************
一、2025最新大模型学习路线
一个明确的学习路线可以帮助新人了解从哪里开始,按照什么顺序学习,以及需要掌握哪些知识点。大模型领域涉及的知识点非常广泛,没有明确的学习路线可能会导致新人感到迷茫,不知道应该专注于哪些内容。
我们把学习路线分成L1到L4四个阶段,一步步带你从入门到进阶,从理论到实战。

L1级别:AI大模型时代的华丽登场
L1阶段:我们会去了解大模型的基础知识,以及大模型在各个行业的应用和分析;学习理解大模型的核心原理,关键技术,以及大模型应用场景;通过理论原理结合多个项目实战,从提示工程基础到提示工程进阶,掌握Prompt提示工程。

L2级别:AI大模型RAG应用开发工程
L2阶段是我们的AI大模型RAG应用开发工程,我们会去学习RAG检索增强生成:包括Naive RAG、Advanced-RAG以及RAG性能评估,还有GraphRAG在内的多个RAG热门项目的分析。

L3级别:大模型Agent应用架构进阶实践
L3阶段:大模型Agent应用架构进阶实现,我们会去学习LangChain、 LIamaIndex框架,也会学习到AutoGPT、 MetaGPT等多Agent系统,打造我们自己的Agent智能体;同时还可以学习到包括Coze、Dify在内的可视化工具的使用。

L4级别:大模型微调与私有化部署
L4阶段:大模型的微调和私有化部署,我们会更加深入的探讨Transformer架构,学习大模型的微调技术,利用DeepSpeed、Lamam Factory等工具快速进行模型微调;并通过Ollama、vLLM等推理部署框架,实现模型的快速部署。

整个大模型学习路线L1主要是对大模型的理论基础、生态以及提示词他的一个学习掌握;而L3 L4更多的是通过项目实战来掌握大模型的应用开发,针对以上大模型的学习路线我们也整理了对应的学习视频教程,和配套的学习资料。
二、大模型经典PDF书籍
书籍和学习文档资料是学习大模型过程中必不可少的,我们精选了一系列深入探讨大模型技术的书籍和学习文档,它们由领域内的顶尖专家撰写,内容全面、深入、详尽,为你学习大模型提供坚实的理论基础。(书籍含电子版PDF)

三、大模型视频教程
对于很多自学或者没有基础的同学来说,书籍这些纯文字类的学习教材会觉得比较晦涩难以理解,因此,我们提供了丰富的大模型视频教程,以动态、形象的方式展示技术概念,帮助你更快、更轻松地掌握核心知识。

四、大模型项目实战
学以致用 ,当你的理论知识积累到一定程度,就需要通过项目实战,在实际操作中检验和巩固你所学到的知识,同时为你找工作和职业发展打下坚实的基础。

五、大模型面试题
面试不仅是技术的较量,更需要充分的准备。
在你已经掌握了大模型技术之后,就需要开始准备面试,我们将提供精心整理的大模型面试题库,涵盖当前面试中可能遇到的各种技术问题,让你在面试中游刃有余。

因篇幅有限,仅展示部分资料,需要点击下方链接即可前往获取
*************************************2025最新版CSDN大礼包:《AGI大模型学习资源包》免费分享*************************************

















 8673
8673

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









