







chainlit+langchain 实现智能知识问答
1. 业务场景
我们将结构化和非结构化数据,经过一定处理后放到向量数据库中,作为我们的语意检索源,检索与用户问题相似度较高的向量片段作为数据源,输入给llm,让LLM(大模型)理解给出的数据源内容,并从中组织答案。
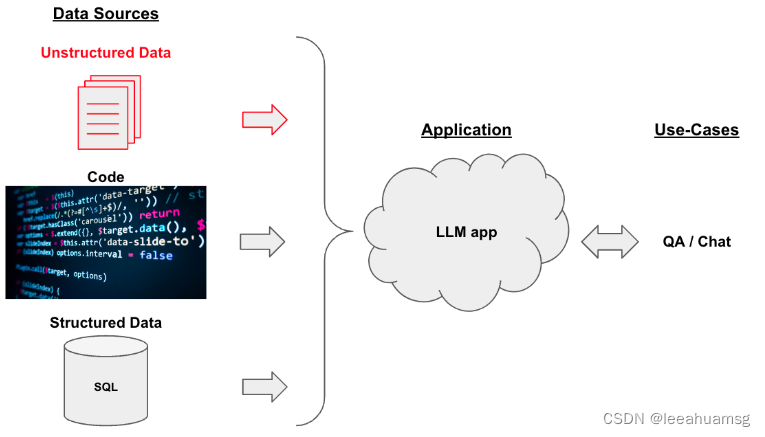
2. 简要处理步骤
- 加载文档
- 将文档分片
- embedding 分片内容并存储
- 检索问题,将问题转成向量,找到相似度较高的几个片段
- 将片段组装成prompt的的内容,提交给LLM
- LLM理解内容并组织语言输出问题答案
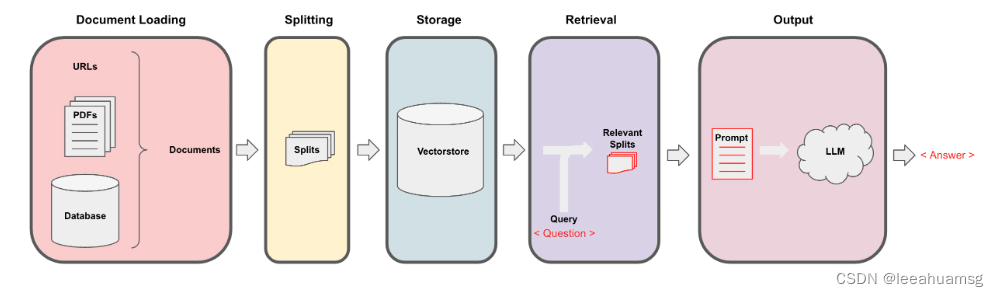
结下来,我们就去实现这个功能。
3 . 环境依赖
- chainlit 快速生成对话UI
- langchain 模型开发框架,目前最流行的大模型应用开发框架
- openai openAI模型库
- chromdb 向量数据库
- python 3.9
pip install openai chromedb chainlit
pip install 'langchain[all]'
4. 加载文档
4.1 准备检索内容
因为内容较多embedding会比较费账号,所以我就百度搜了个特斯拉的简介
将百科内容放到tesla文件中,内容如下:

# 将你准备好的文本放到当前文件目录下的doc目录下,我的文档名字叫tesla
from langchain.document_loaders import TextLoader
loader = TextLoader("doc/tesla")
data = loader.load()
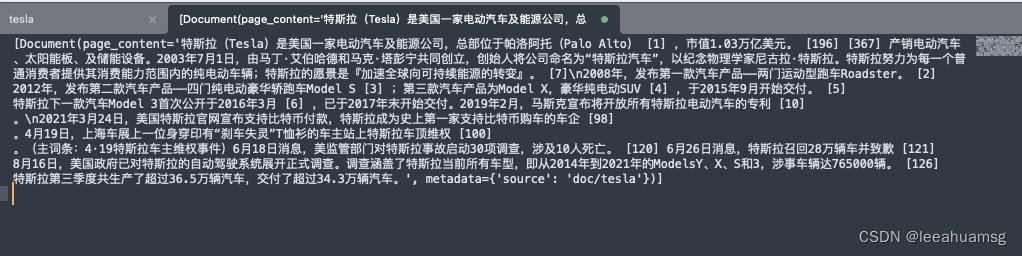
文件文档化之后的结构为:
4.2 将文档进行分块
from langchain.text_splitter import RecursiveCharacterTextSplitter
# chunk_size 分块大小 chunk_overlap 分块重叠量
text_splitter = RecursiveCharacterTextSplitter(chunk_size = 30, chunk_overlap = 0)
all_splits = text_splitter.split_documents(data)
文档分块后的数据为:

4.3 分块embedding存储,也就是让openai帮我转成向量
from langchain.embeddings import OpenAIEmbeddings
from langchain.vectorstores import Chroma
import os
# 如果没有的话,可以联系我帮你搞一个
os.environ["OPENAI_API_KEY"] = "你的openapikey"
vectorstore = Chroma.from_documents(documents=all_splits, embedding=OpenAIEmbeddings())
4.4 初始化LLM并运行
from langchain.chains import RetrievalQA
from langchain.prompts import PromptTemplate
from langchain.chat_models import ChatOpenAI
template = """Use the following pieces of context to answer the question at the end.
If you don't know the answer, just say that you don't know, don't try to make up an answer.
Use three sentences maximum and keep the answer as concise as possible.
Always say "thanks for asking!" at the end of the answer.
{context}
Question: {question}
Helpful Answer:"""
QA_CHAIN_PROMPT = PromptTemplate.from_template(template)
llm = ChatOpenAI(model_name="gpt-3.5-turbo", temperature=0)
qa_chain = RetrievalQA.from_chain_type(
llm,
retriever=vectorstore.as_retriever(),
chain_type_kwargs={"prompt": QA_CHAIN_PROMPT},
chain_type="stuff"
)
result = qa_chain({"query": question})
result["result"]
运行结果:

至此 langchain 实现文本检索和调用大模型的过程全部完成了,现在我们将上述代码和chainlit集成起来,实现一个有界面的对话。
from langchain import PromptTemplate, OpenAI, LLMChain
import chainlit as cl
from langchain.document_loaders import WebBaseLoader
from langchain.indexes import VectorstoreIndexCreator
from langchain.text_splitter import RecursiveCharacterTextSplitter
import os
os.environ["OPENAI_API_KEY"] = "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"
from langchain.document_loaders import TextLoader
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain.embeddings import OpenAIEmbeddings
from langchain.vectorstores import Chroma
from langchain.chains import RetrievalQA
from langchain.prompts import PromptTemplate
from langchain.chat_models import ChatOpenAI
#加载文档
loader = TextLoader("doc/tesla")
data = loader.load()
#文档分块
text_splitter = RecursiveCharacterTextSplitter(chunk_size = 30, chunk_overlap = 0)
all_splits = text_splitter.split_documents(data)
文本块embedding之后存储到向量数据库
vectorstore = Chroma.from_documents(documents=all_splits, embedding=OpenAIEmbeddings())
创建对话提案
template = """Use the following pieces of context to answer the question at the end.
If you don't know the answer, just say that you don't know, don't try to make up an answer.
Use three sentences maximum and keep the answer as concise as possible.
Always say "谢谢提问!" at the end of the answer.
{context}
Question: {question}
Helpful Answer:"""
@cl.on_chat_start
def main():
# 构建模型链实例
QA_CHAIN_PROMPT = PromptTemplate.from_template(template)
llm = ChatOpenAI(model_name="gpt-3.5-turbo", temperature=0)
# 初始化调用链
qa_chain = RetrievalQA.from_chain_type(
llm,
retriever=vectorstore.as_retriever(),
chain_type_kwargs={"prompt": QA_CHAIN_PROMPT},
chain_type="stuff"
)
# 保存模型链实例到用户session
cl.user_session.set("llm_chain", qa_chain)
@cl.on_message
async def main(message: str):
# 最新的版本这个地message的类型变成了cl.Message
# 用户输入内容需要从message.content 内获取
message_str = ''
# 处理用户业务逻辑
if isinstance(message,str):
message_str = message
print('ok')
if isinstance(message,cl.Message):
message_str = message.content
print(f'receive: {message.content}')
# 如果是最新的版本,
# 从用户会话中获取模型链实例
qa_chain = cl.user_session.get("llm_chain")
# 异步调用模型链
result = qa_chain({"query": message_str})
# 在这里可以做任何处理
print(f'ask:{message_str}, answer:{result["result"]}')
# "res" is a Dict. For this chain, we get the response by reading the "text" key.
# This varies from chain to chain, you should check which key to read.
await cl.Message(content=result["result"]).send()
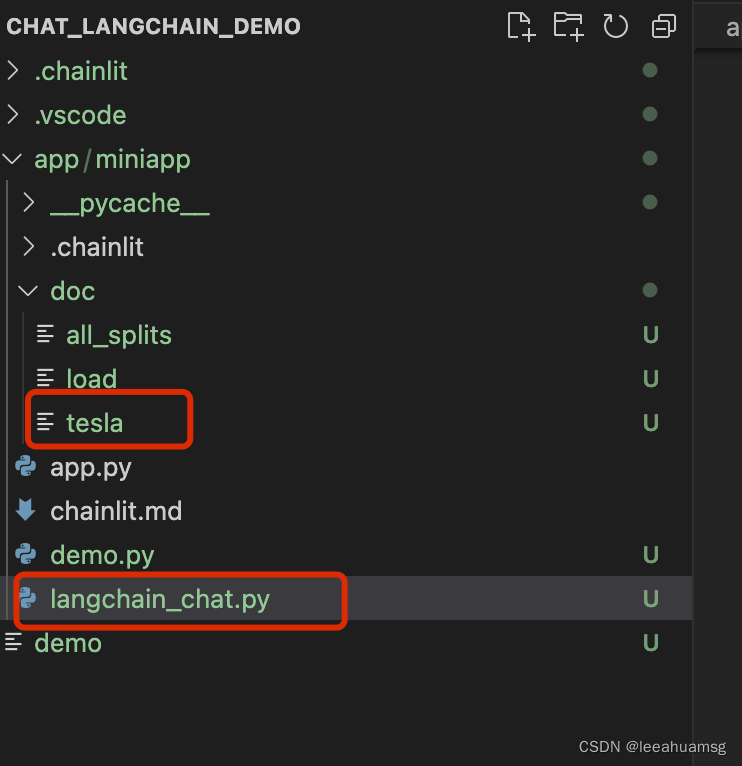
文件目录结构如下:
运行起来:
chainlit run langchain_chat.py -w
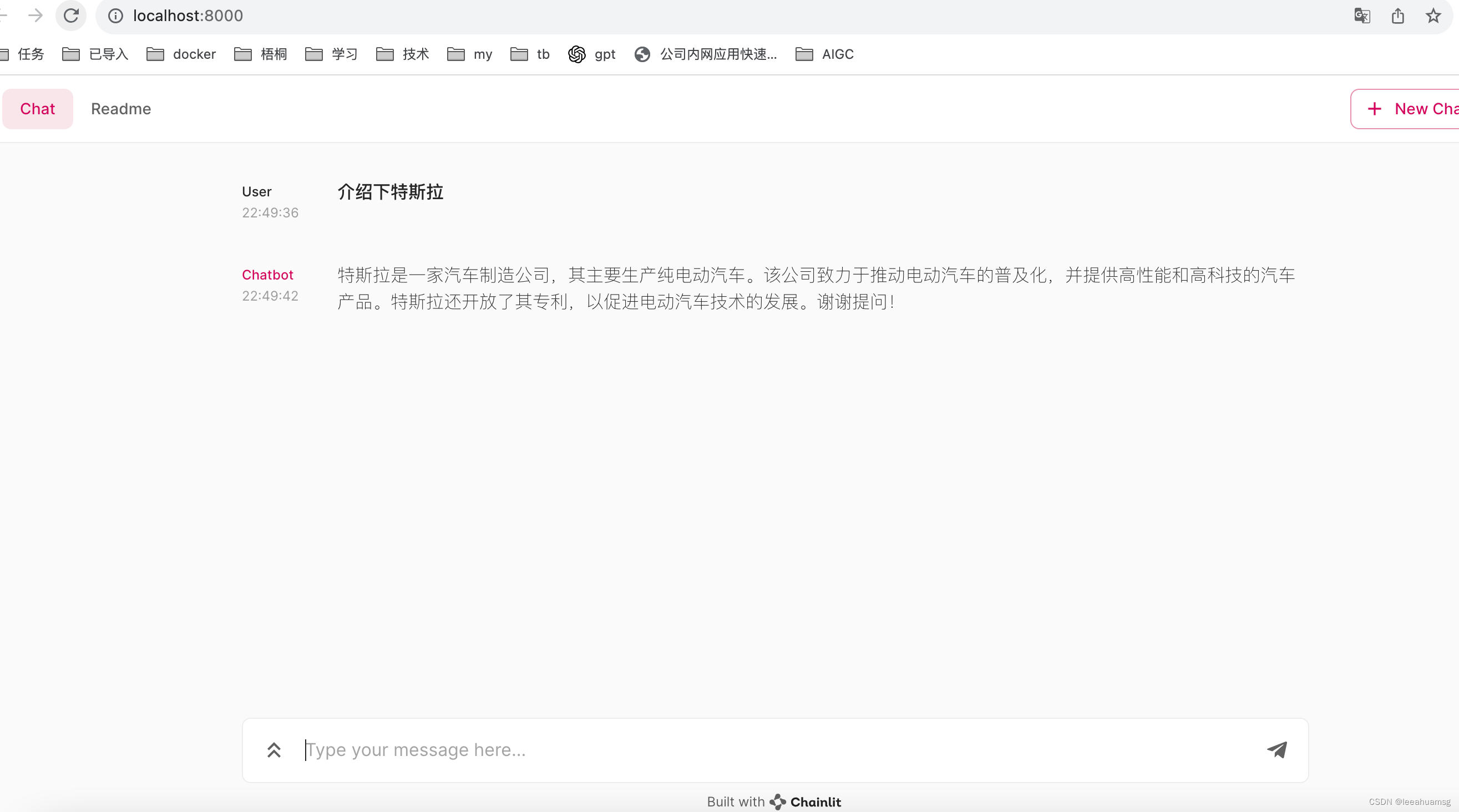
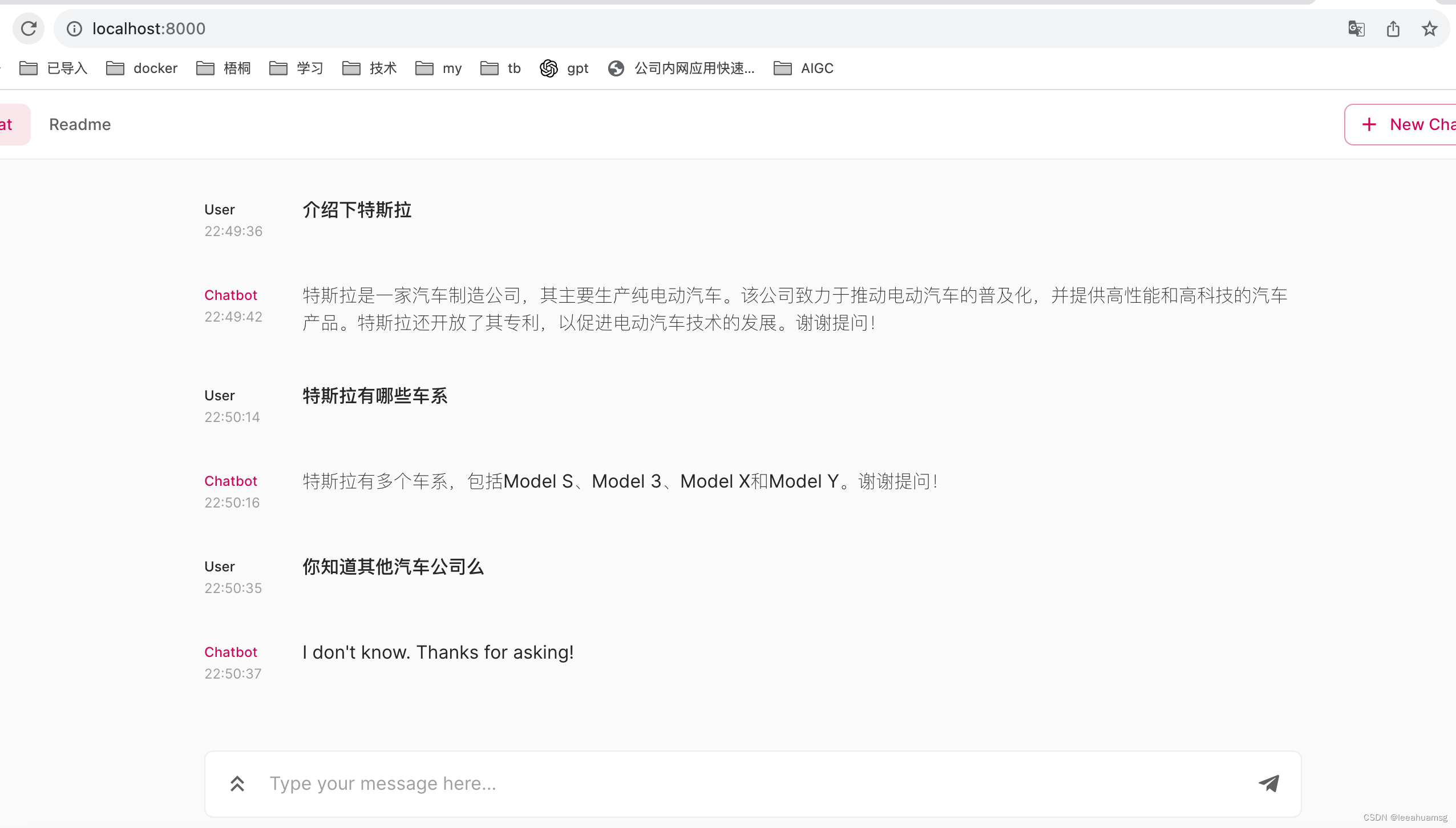
启动完成:

访问: http://localhost:8000
好啦,本篇到此就全部完成了,要是大家在做的过程中遇到什么问题可以加我微信(leeahuamsg), 备注AIGC,一起探讨哈,接下来我会继续用langchain实现一个智能聊天机器人。

















 2457
2457

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









