






在实际数据分析和处理过程中,我们可能需要灵活对分组数据进行聚合操作。这个时候,我们就需要用到用户自定义函数(User-Defined Functions,UDFs)。
使用用户自定义函数进行聚合
使用用户自定义函数聚合时的性能,通常比不上使用GroupBy的pandas内置方法。所以,在我们使用用户自定义函数的时候,可以考虑将复杂的操作分解为使用内置方法的操作链。
我们先来看一个例子

通过kind列进行分组,把分组后的height列,先转换为int整形,最后通过sum进行加总聚合操作。
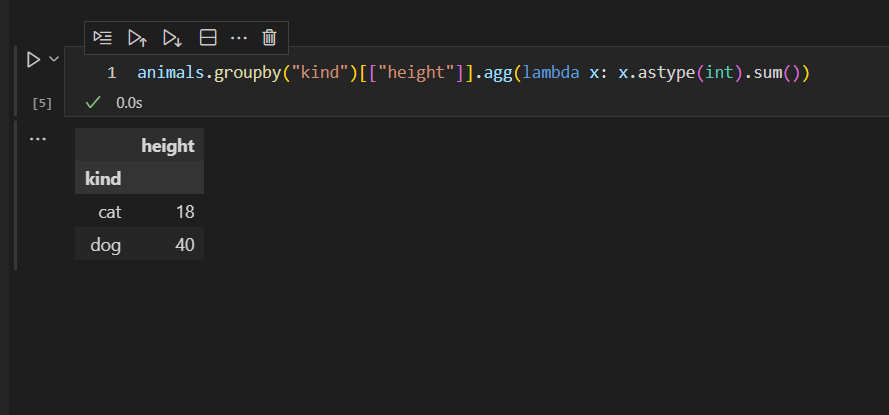
注意,这里是int整形,没有小数部分,所以结果是一个整数值。
同时应用多个聚合函数
我们可以在分组完成后,同时使用多个聚合函数,来快速计算得到我们所需的各种统计数据,并且一次性呈现出来。
我们来看以下例子
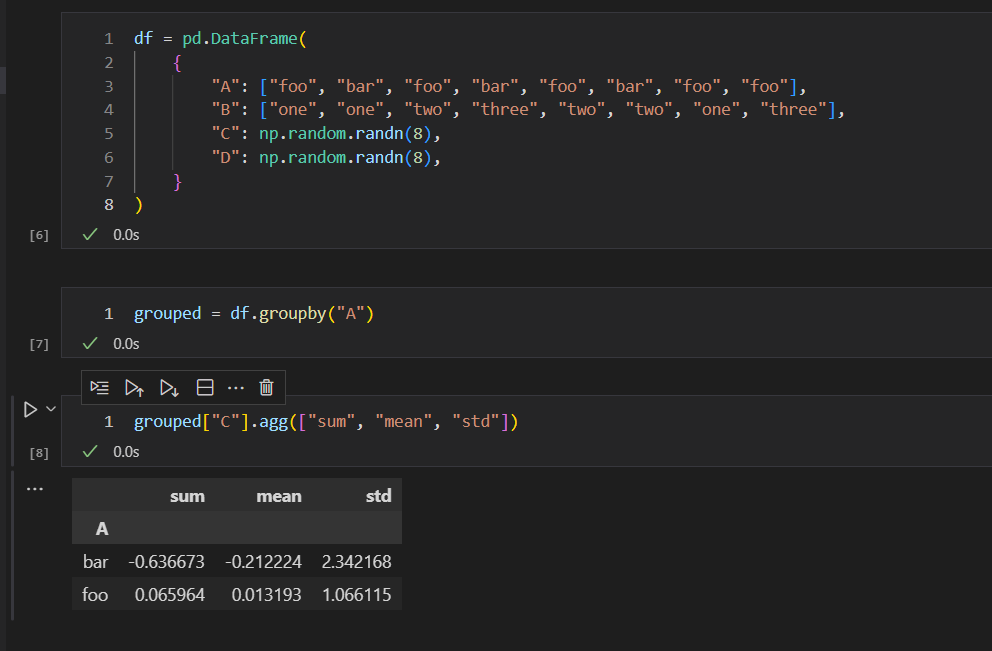
上述操作过程中,先通过A列进行分组,然后在各个子分组数据集中,通过C列计算总和,均值,标准差,三个统计量。
我们还可以对各个子分组数据集中的多列,进行多个聚合操作,如下所示。
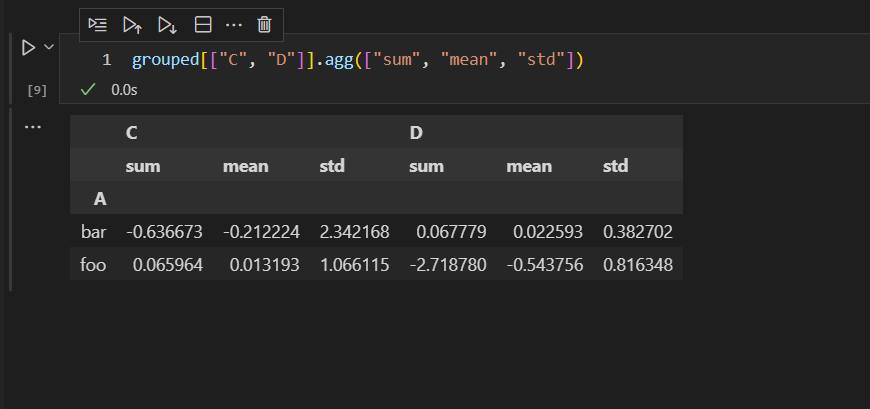
这个过程表示,通过A列分组之后,在得到的各个子分数数据集中,同时计算C列和D列的总和,均值,标准差,三个统计量。
命名聚合
如果我们需要自定义聚合函数的列名的话,可以使用命名聚合操作,也就是改变聚合结果的列名。
还是以animals数据集为例。

这里,我们通过命名聚合函数NamedAgg,对height列进行min最小值的聚合操作,结果数据集的列名,设置为min_height。
也可以使用以下的简化语句

得到的结果是一样的,只是省略参数的赋值过程。如果是对命名聚合操作不熟悉的数据分析人员,建议还是使用上面参数赋值完整的程序语句。
如果只对分组后的数据,各个子分组数据集中,单个数据列进行聚合的话,可以使用下面的命名聚合语句。

这是一个链式语句,从左到右分别是,先对animals数据集,通过kind列进行分组。在分组完成后的各个子分组数据集中,通过height列,进行min和max的聚合操作,最后把min和max聚合操作的结果数据列,改名为min_height和max_height。
对分组数据不同的列应用不同的聚合函数
我们可以通过一个字典数据结构,传入我们需要聚合操作的列名和聚合函数,完成对分组后的子分组数据集,不同的列,进行不同的聚合操作。
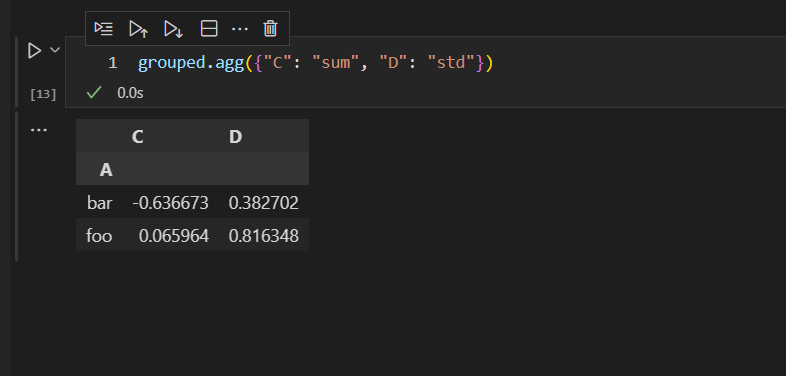
这样,我们就可以灵活的,对C列进行数据汇总的聚合操作,对D列进行计算标准差的操作。
总结
以上,就是我们关于GroupBy分组聚合数据的所有内容。GroupBy的知识内容,在实际中用处非常大,运用的时候较多。我们很多的实际当中的业务问题,或者是数据分析问题,都需要先对原始数据集进行GroupBy的分组和聚合操作。
通过GroupBy对数据的处理,可以让我们得到所需的子分组数据集,再对子分组数据集,进行一些业务处理,或者是数据处理的操作,比如说聚合操作,这样,基本上可以解决我们很大一部分的数据分析和处理问题。
















 637
637

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











