






论文
1 Introduction
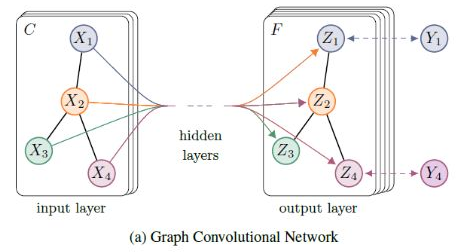
· STEP:Spatial Temporal Graph Convolutional Networks for Emotion Perception from Gaits(基于步态的情感感知的时空图卷积网络)
· 步态被认为是包含了情绪信息的一种非语言线索,步态被定义为人体关节的失序运动(主要是平移与旋转)。
· 步态情绪识别面临的限制:大量标记数据集的缺失
网络结构组成:分类器(情绪分类) + 生成器(生成标记的情绪数据集)
① 一个端到端的STEP网络用于提取步态情绪特征,其将深度学习特征与情感特征结合形成混合特征

② 通过引入CVAE来生成更多标记的步态数据集,从而训练网络防止过拟合,提高预测精度

③ 造了个新的数据集E-Gait

2 Related Work
· 主流的情绪识别方式有基于人脸表情的情绪识别与基于语音的情绪识别,延伸方法有基于深度学习方法以及交叉模式等。
· PCA、SVM等方法也被用于进行步态情绪识别。
· 在步态生成的方法中,常见的方法有GAN与VAE。在本文中,我们将步态建模为骨骼图,并在VAE中使用时空图卷积生成合成步态
3 BackGround
此处对文章涉及的技术背景进行简单论述,不细展开。
3.1 GNN(图神经网络)
原理:GNN是一种基于图的特征网络,通过聚合各结点之间的信息(每个结点与其他相邻结点的信息传播,通过迭代更新达到一个稳定状态)达到提取特征的目的 ,从而进行分类、回归等任务。
首先,多层感知机隐藏层的计算形式为:H = σ(XW),X为特征矩阵,X为参数矩阵;而在GNN中,隐藏层的计算形式为:H = σ(AXW),其中A是邻接矩阵。
小细节:A矩阵应该是邻接矩阵加上单位矩阵E,否则在聚合过程中会丢失本结点的特征,同时出现梯度爆炸
结点v的隐藏层状态h_v表示为:
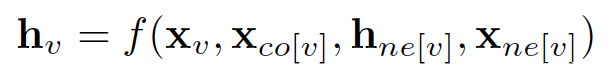

上图公式中,结点的隐藏特征h会随着迭代不断聚合其邻接点的特征从而发生变化,而相连边特征x是网络需要学习的参数之一。f的本质就是一个前馈神经网络(需要保证压缩映射,可以利用不动点理论迭代模型,此处不展开),把每个邻居结点的特征、隐藏状态、每条相连边的特征以及结点本身的特征简单拼接在一起,在经过前馈神经网络后做一次简单的加和:
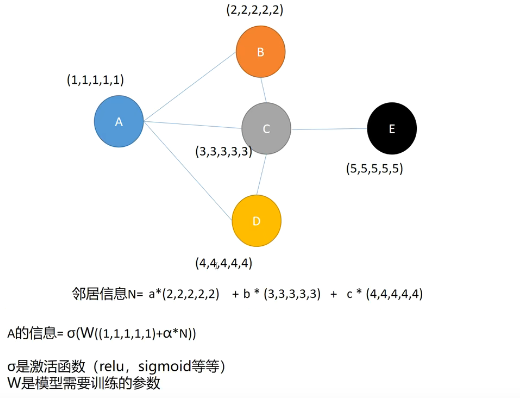
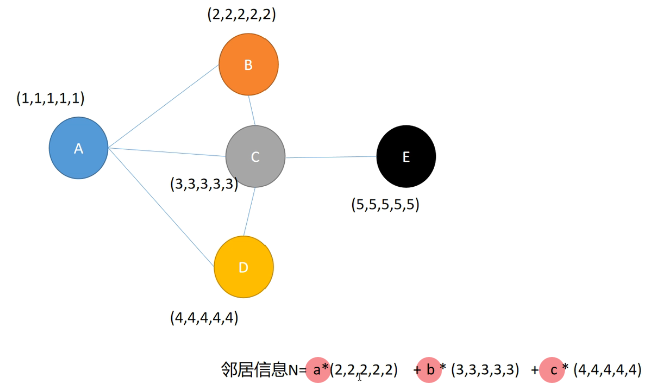
上图的a,b,c可以由人为设定,也可以由网络学习。而GCN的提出正是将a,b,c等看做一个卷积核W,用于学习相关参数。
对于经典的结点二分类问题,可以将loss函数定义为:
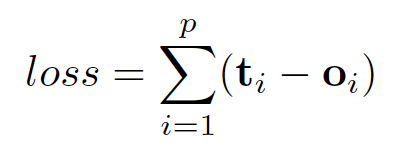
总结:GNN是一个图形状的前馈神经网络,GNN与传统前馈网络不同的是,它的所有结点都是隐藏层,也都有对应的输出(不分层),而前馈网络中间的隐藏层特征并不需要被利用,只利用到最后一层,同时隐藏层是分层的。
3.2 GCN(图卷积神经网络)
原理:GCN是一种特殊的GNN,它利用卷积算子进行信息汇聚。它解决的问题的**“GNN中a,b,c的值的设定问题”**:
GCN的隐藏层公式为:
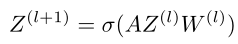
· Z(l+1):第l+1层的输入
· A:邻接矩阵 + 单位矩阵
· Z(l):第l层的输入
· W:第l层与第l+1层之间的权重矩阵,类似于CNN中的卷积核
· 初始输入X:初始结点的特征矩阵,Z(0) = X(第一层的输入)
· W的个数K:类似于卷积核个数,F×D input,卷积后 K×F×D output
更广泛地,以下公式引入了度矩阵D波浪(度数矩阵 + 单位矩阵),用于表示结点与结点之间的度关系:

GCN与CNN的图解类比:
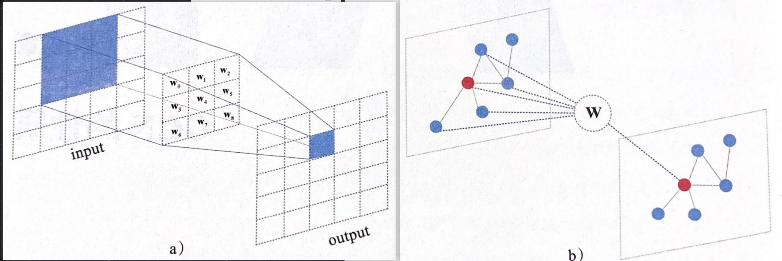
特别的,在GCN中,若想把图结构当做图像输入到CNN会遇到卷积核的大小不固定的问题(每个结点的邻接点数目不同)。
因此,GCN作者采用了使用同一个向量与中心点邻域内的所有点上的特征向量计算内积并将结果求均值的方式,使得卷积核的参数可以确定为一个固定长度的向量(与特征向量维度相同),可以运用于任意连接方式的图结构中。
3.3 ST-GCN(时空图卷积神经网络)
原理:ST-GCN被提出用于视频中人的行为识别,视频中人的骨架图被视为一个Graph。
视频本质是帧的序列,帧与帧之间包含了时序信息。ST中的S,Spatial即骨架模型,可以单独看做关键点之间的空间边;T,Temporal即不同帧之间骨架关键点的变化,可以单独看做关键点之间的时序边。由此一来便可以经过一个GCN网络进行特征提取,其中每个关键点的特征就是这个顶点所代表的的关节的3D位置。
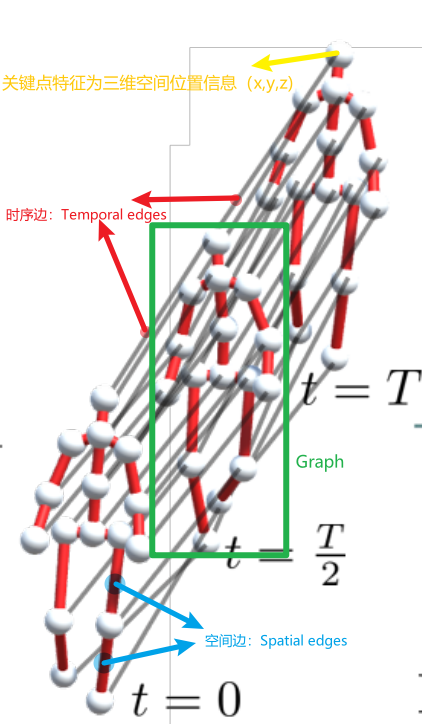
需要进行说明的是:在空间域中,ST-GCN使用的是传统的GCN;而在时间域中,ST-GCN使用的是TCN。
什么是TCN?TCN实际上就是一个一维卷积。卷积的维度是时间维度,卷积核一行多列,针对单个关节结点进行卷积运算,如下图:
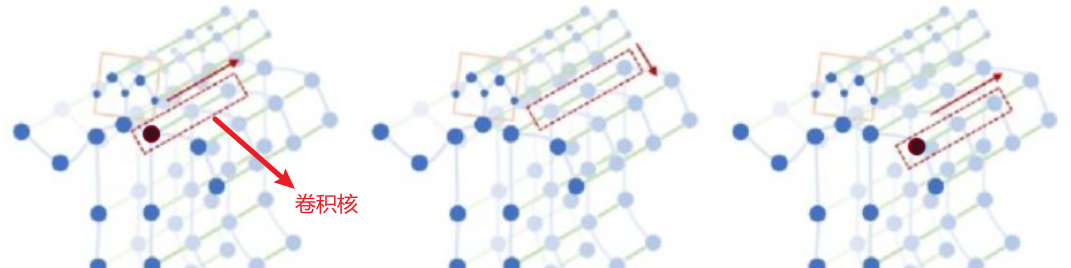
对于GCN,进行卷积操作时是采用求平均,但是平均方法不一定能准确建模结点间的关系。ST-GCN做了如下的改进:
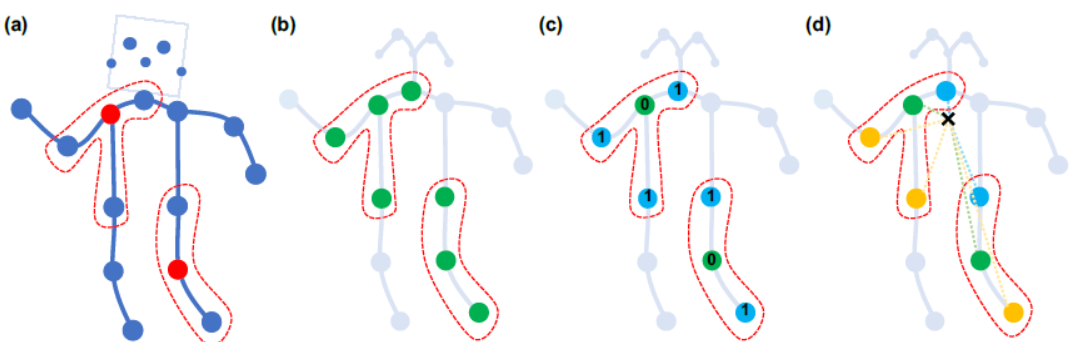
对于感受野都是离中心点距离D = 1的范围,选择卷积核则是将同范围的点进行分类:
(b)中心点和相连的点同样的权重,这里只有一种权重(传统的GCN)
(c)中心点和相连的点采用不同的权重,这里有两种权重
(d)分为三种点,一是源点,二是近心点,三是远心点,这里说的是离人体重心近的点和远的点,所以有三种权重(ST-GCN改进)
3.4 VAE(变分自编码器)
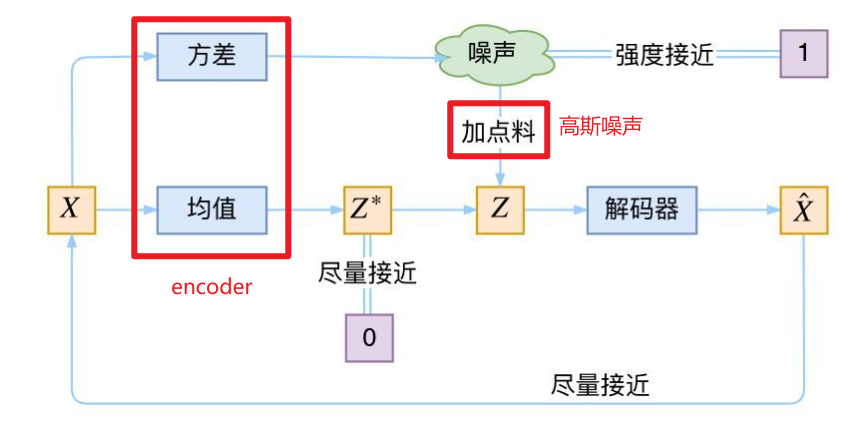
原理:VAE是一个基于贝叶斯定律的编码器-解码器结构,用于生成数据。编码器将训练数据训练为一个潜在的低维分布空间,再从改低维分布中随机抽样经过解码器生成与训练数据尽可能相似的合成数据。
VAE的本质是在常规的自编码器的基础上添加了“高斯噪声”,使得解码器对噪声具有更好的鲁棒性。VAE包含两个编码器,一个用于生成均值为0的低维嵌入(正则化),一个计算方差(动态调节噪声的强度,当编码器训练较好时加大噪声强度,反之减少从而方便训练)。
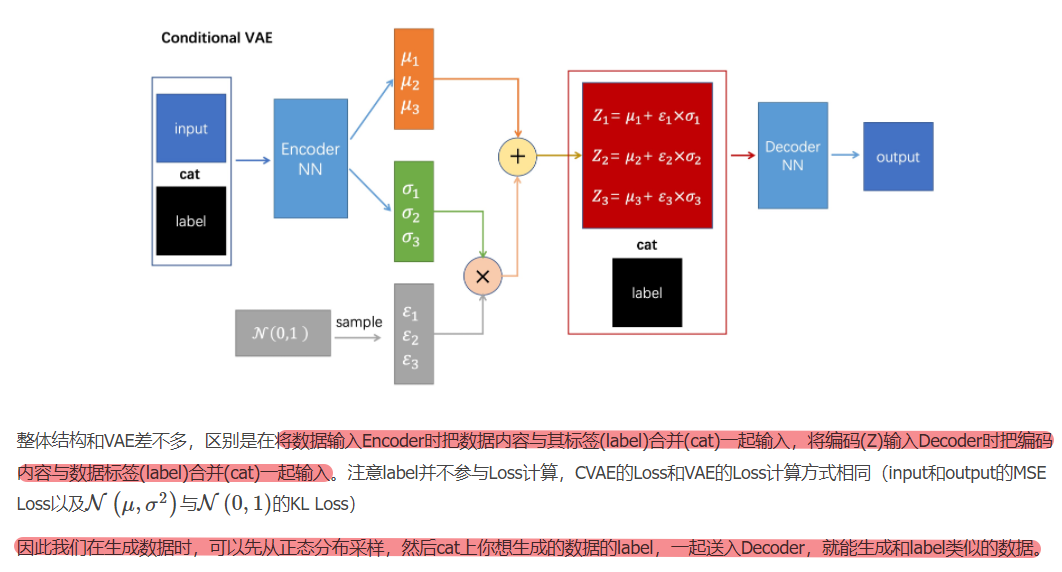
3.5 CVAE(有条件变分自编码器)
原理:对于不同的分类,CVAE的编码器将学习不同的分布,并从不同的分布中随机取样通过解码器生成与该分类尽可能相似的合成数据。在本文中,利用GCN作为CVAE的主干网络(编码器与解码器),用于生成不同情绪分类的步态数据。
4 STEP
4.1 人体骨架获取
利用SOTA的视频人体骨架提取方法3D-pose提取人体关节骨架图。其中,为了确保生成模型不会生成外部均值的数据,在其中添加了view normalization。

4.2 生成网络STEP-Gen
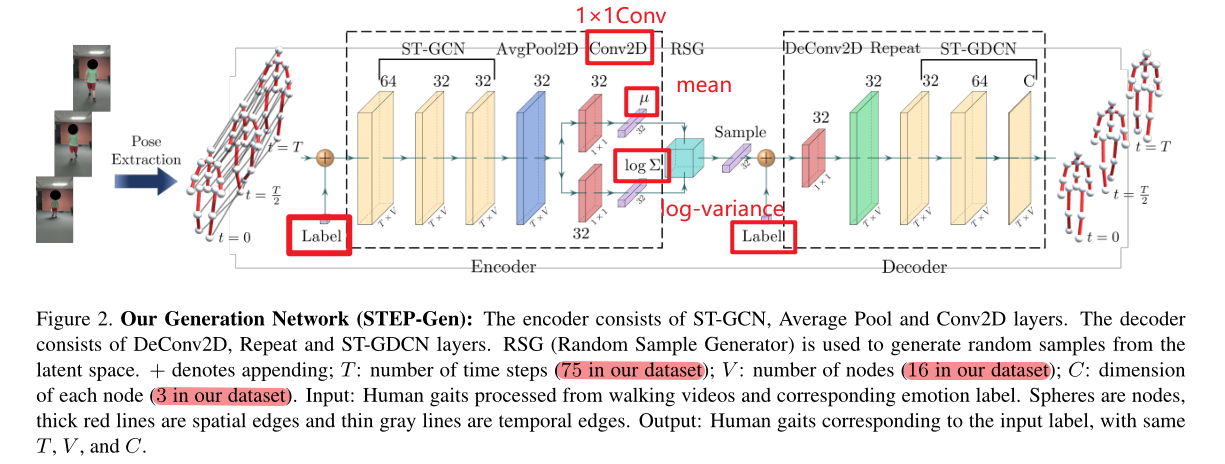
如图所示,文章的CVAE采用ST-GCN作为encoder与decoder,并且合并上label从而可以生成不同类别的步态数据。其中, log-variance是对数方差。(注:ST-GCN每层后都有ReLU激活函数,整个网络除了全连接层以外均有BatchNorm,高斯分布)
损失函数(因为基准CVAE并没有考虑时序信息的能力,因此文章对loss进行了修改从而对时序信息进行考虑):
① 基准损失:
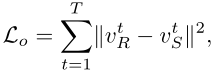
② “push-pull” regularization:
· push:保证生成数据与真实数据尽可能相同,即具有尽可能相同的关节运动速度与加速度。运动速度与加速度损失:
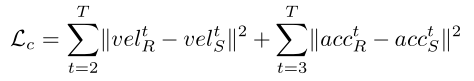
· pull:随着帧数增加,关节点位置的偏移误差随之增加。为了减小这种误差引入了“锚帧”的概念,选取了第一帧、中间帧以及最后一帧作为锚帧,进行误差损失计算。锚帧损失:
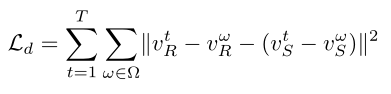
因此,生成器的总损失为:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-wnrwH1xo-1645784463615)(D:\Typora\images\image-20220220133745239.png)]
4.3 分类网络STEP

· 第一个Softmax的数据即为STEP-baseline的输出。
· 先前研究发现,步态的一些情感特征对于情绪预测十分重要,因此STEP网络即利用baseline的输出加上affective features。

5 其他
5.1 训练细节

5.2 数据集
① E-Gait:2177真实步态+1000生成步态
② 自己搜集342真实步态并打标签
③ MOCAP Dataset的1835个无标签数据集,并打标签
代码
待更新…














 540
540











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









