






论文
1 Introduction
Ordinal Distribution Regression for Gait-based Age Estimation:基于步态的年龄估计的序次分布回归
文章指出,许多的步态年龄识别方法护士了年龄标签之间的顺序关系,然而这是年龄估计的重要线索。针对该问题,有学者提出了ranking-based的方法(将有序回归分解为一系列二元分类,利用交叉熵优化),但这种方法中同一个交叉熵loss会出现不同的分布:
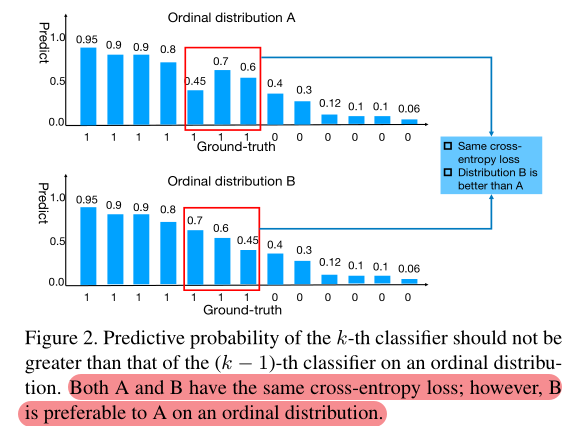
文章亮点:
① 继承了人脸年龄识别任务,将年龄识别的有序回归分别为一系列二元分类的子问题
② 提出ODL(顺序分布损失),并利用了squared Earth mover’s distance
③ 提出了全局局部通道网络,也是我们的重点关注点

2 Proposed Method
2.1 Ordinal regression
非重点探讨内容
2.2 GL-CNN
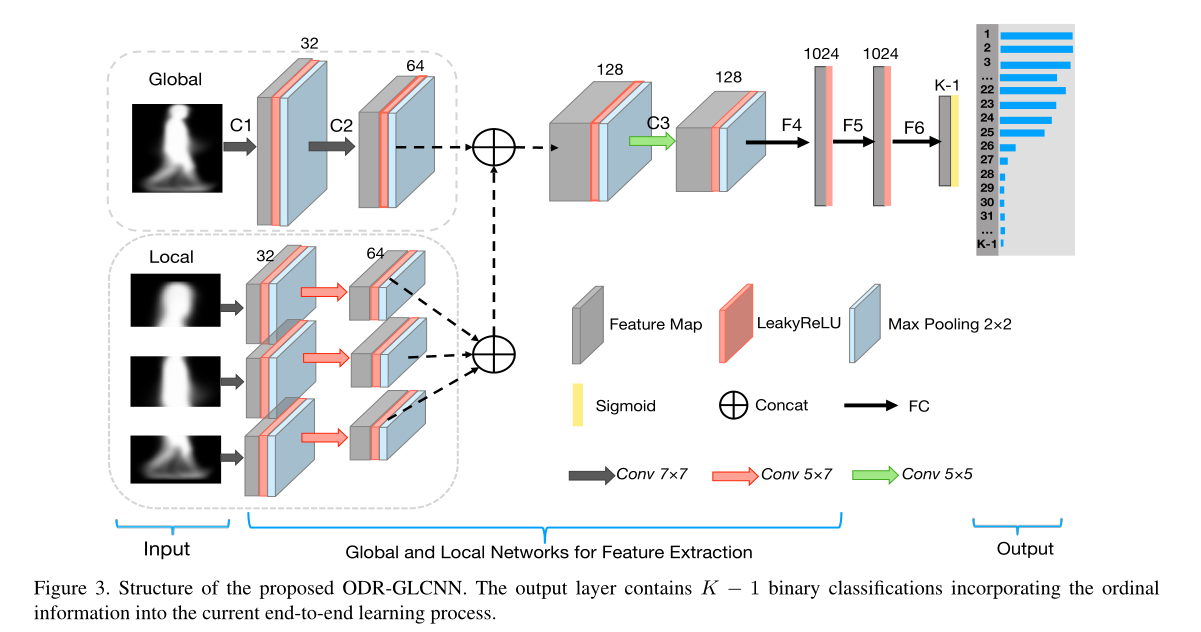
类似于GaitPart,分成了三个部分分别进行局部卷积,类似于焦点卷积。
代码
GaitORD核心代码复现:
'''basic block'''
import torch.nn as nn
from torch.nn import functional as F
import torch
# Global
class BasicConv2d(nn.Module):
def __init__(self, in_channels, out_channels, kernel_size, padding):
super(BasicConv2d, self).__init__()
self.conv = nn.Conv2d(in_channels, out_channels, kernel_size, padding=padding, stride=1)
self.pooling = nn.MaxPool2d(kernel_size=2, stride=2)
def forward(self, x):
x = self.conv(x)
x = F.leaky_relu(x, inplace=True)
x = self.pooling(x)
return x
# Local
class PartConv2d(nn.Module):
def __init__(self, in_channels, out_channels, kernel_size, padding):
super(PartConv2d, self).__init__()
self.out_channels = out_channels
self.pooling = nn.MaxPool2d(kernel_size=2, stride=2)
self.conv = nn.Sequential(
nn.Conv2d(in_channels, out_channels, kernel_size=kernel_size, padding=padding),
nn.LeakyReLU(),
nn.MaxPool2d(kernel_size=2, stride=2)
)
def forward(self, x):
batch, c, h, w = x.size()
part_list = []
if h == 32:
part_list = [6, 12, 15]
elif h == 64:
part_list = [10, 24, 30]
elif h == 128:
part_list = [22, 48, 58]
x_head = x[:, :, 0:part_list[0], :]
x_body = x[:, :, part_list[0]:part_list[0]+part_list[1], :]
x_foot = x[:, :, part_list[0]+part_list[1]:part_list[0]+part_list[1]+part_list[2], :]
x_head = self.conv(x_head)
x_body = self.conv(x_body)
x_foot = self.conv(x_foot)
output = torch.cat([x_head, x_body, x_foot], 2)
return output
class SetBlock(nn.Module):
def __init__(self, forward_block):
super(SetBlock, self).__init__()
self.forward_block = forward_block
def forward(self, x):
n, s, c, h, w = x.size()
x = self.forward_block(x.view(-1, c, h, w))
_, c, h, w = x.size()
return x.view(n, s, c, h, w)
'''Backbone'''
import torch.nn as nn
import torch
from torch.nn import functional as F
from model.network.Basic_Blocks import BasicConv2d, PartConv2d
class GEINet(nn.Module):
def __init__(self):
super(GEINet, self).__init__()
# Global_Conv
self.gl_conv1 = BasicConv2d(1, 32, 7, 3)
self.gl_conv2 = BasicConv2d(32, 64, 7, 3)
# Local_Conv
self.lc_conv1 = PartConv2d(1, 32, 7, 3)
self.lc_conv2 = PartConv2d(32, 64, (5, 7), (2, 3))
# Conv
self.conv = BasicConv2d(128, 128, 5, 2)
# 线性层
self.linear_layer1 = nn.Linear(128 * 8 * 5, 1024)
self.linear_layer2 = nn.Linear(1024, 1024)
self.linear_age = nn.Linear(1024, 100)
self.linear_gender = nn.Linear(1024, 2)
for m in self.modules():
if isinstance(m, (nn.Conv2d, nn.Conv1d)):
nn.init.xavier_uniform_(m.weight.data)
elif isinstance(m, nn.Linear):
nn.init.xavier_uniform_(m.weight.data)
nn.init.constant(m.bias.data, 0.0)
elif isinstance(m, (nn.BatchNorm2d, nn.BatchNorm1d)):
nn.init.normal_(m.weight.data, 1.0, 0.02)
nn.init.constant_(m.bias.data, 0.0)
def _make_layer(self, block, inplanes, planes, blocks):
layers = []
for _ in range(0, blocks):
layers.append(block(inplanes, planes))
return nn.Sequential(*layers)
def forward(self, x):
x_gl = self.gl_conv1(x)
x_gl = self.gl_conv2(x_gl)
x_lc = self.lc_conv1(x)
x_lc = self.lc_conv2(x_lc)
x = torch.cat([x_gl, x_lc], 1)
x = self.conv(x)
x = x.reshape(x.shape[0], 128 * 8 * 5)
x = self.linear_layer1(x)
x = F.leaky_relu(x, inplace=True)
x = F.dropout(x, 0.5)
x = self.linear_layer2(x)
x = F.leaky_relu(x, inplace=True)
x = F.dropout(x, 0.5)
x = ... # 后续线性层














 1070
1070











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









