






什么是大模型
大模型 Large Language Model 缩写 LLM
通常是指那些具有大量参数和复杂结构的机器学习模型。这些模型的特点包含高参数数量、高计算复杂性和高数据消耗。它通过对大量数据的学习,能够实现对复杂任务的高效处理
大家熟悉的ChatGTP就是一个基于大模型(GTP-3.5, GTP-4)的对话产品,国内外常用的大模型有以下:
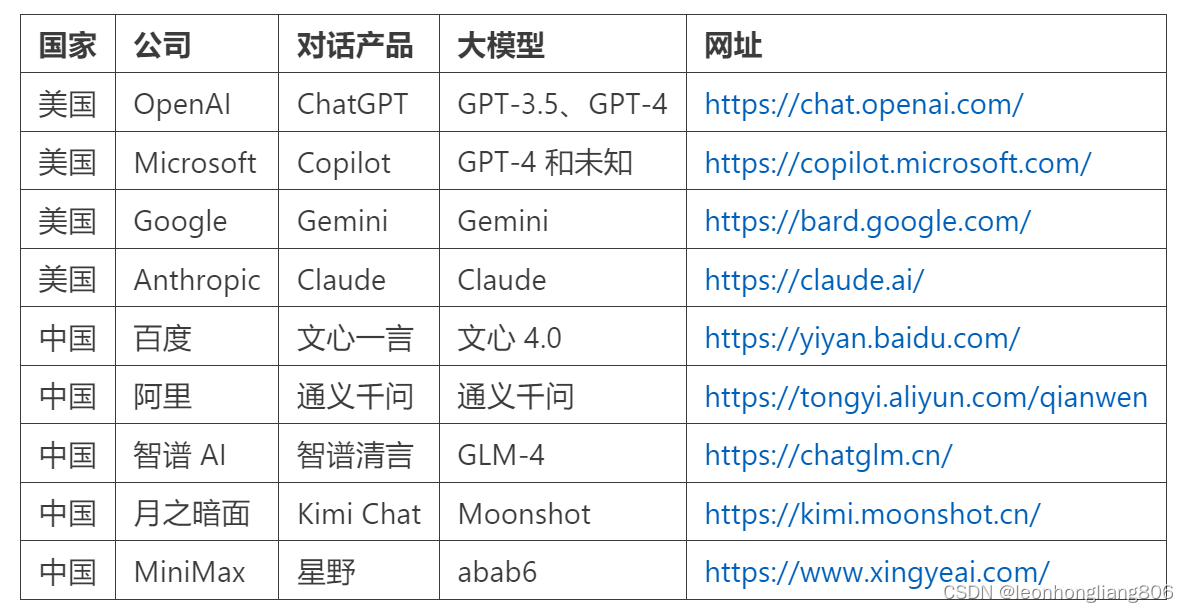
大模型能做什么
我们多多少少应该都和上述一些大模型对话产品聊过天,但是,千万别以为大模型只是聊天机器人,他的能量,远不止于此,它还可以写文案,写小说,写PPT,画图(midjunery,stable diffusion),做视频,编代码(通义灵码),等等
简单来说:
- 大模型就是一个函数,给输入,生成输出
- 任何可以用语言描述的问题,都可以输入给大模型,就能生成问题的结果
它可能解决一切问题,所以是通用人工智能,也就是AGI(Artificial General Intelligence)
AGI时代,AI将无处不在,主流预测AGI时代将在3-5年内来临
大模型现况
当前已经有很多企业在引入大模型来降本增效,期望利用各种AI自动化代替人工,裁员降本或提高效率。自媒体上也有各种神化AI或各种岗位会被AI取代的传言来制造焦虑,实际上目前通用人工智能还不能达到老板们所期待的高度,是无法完成一个完整的工作链路的,更实际的是提高某个生产环节的效率
大模型是怎么生成结果的
通俗原理
根据上下文,猜下一个词的概率

略深一点的通俗原理
大模型的两个核心过程:
训练
- 大模型阅读了人类说过的所有的话。这就是机器学习
- 训练过程会把不同 token 同时出现的概率存入神经网络文件。保存的数据就是参数,也叫权重
推理
- 我们给推理程序若干 token,程序会加载大模型权重,算出概率最高的下一个 token 是什么
- 用生成的 token,再加上上文,就能继续生成下一个 token。以此类推,生成更多文字
再深一层的原理
这套生成机制的内核叫「Transformer 架构」。Transformer 仍是主流,但其实已经不是最先进的了。

附上transformer的代码,仅有短短400多行!你敢信
import os
import time
import math
import json
import joblib
import random
import argparse
import numpy as np
import tensorflow as tf
from tqdm import tqdm
from functools import partial
from sklearn.utils import shuffle
from sklearn.metrics import accuracy_score
from opt import adam, warmup_cosine, warmup_linear, warmup_constant
from datasets import rocstories
from analysis import rocstories as rocstories_analysis
from text_utils import TextEncoder
from utils import encode_dataset, flatten, iter_data, find_trainable_variables, convert_gradient_to_tensor, shape_list, ResultLogger, assign_to_gpu, average_grads, make_path
def gelu(x):
return 0.5*x*(1+tf.tanh(math.sqrt(2/math.pi)*(x+0.044715*tf.pow(x, 3))))
def swish(x):
return x*tf.nn.sigmoid(x)
opt_fns = {
'adam':adam,
}
act_fns = {
'relu':tf.nn.relu,
'swish':swish,
'gelu':gelu
}
lr_schedules = {
'warmup_cosine':warmup_cosine,
'warmup_linear':warmup_linear,
'warmup_constant':warmup_constant,
}
def _norm(x, g=None, b=None, e=1e-5, axis=[1]):
u = tf.reduce_mean(x, axis=axis, keep_dims=True)
s = tf.reduce_mean(tf.square(x-u), axis=axis, keep_dims=True)
x = (x - u) * tf.rsqrt(s + e)
if g is not None and b is not None:
x = x*g + b
return x
def norm(x, scope, axis=[-1]):
with tf.variable_scope(scope):
n_state = shape_list(x)[-1]
g = tf.get_variable("g", [n_state], initializer=tf.constant_initializer(1))
b = tf.get_variable("b", [n_state], initializer=tf.constant_initializer(0))
return _norm(x, g, b, axis=axis)
def dropout(x, pdrop, train):
if train and pdrop > 0:
x = tf.nn.dropout(x, 1-pdrop)
return x
def mask_attn_weights(w):
n = shape_list(w)[-1]
b = tf.matrix_band_part(tf.ones([n, n]), -1, 0)
b = tf.reshape(b, [1, 1, n, n])
w = w*b + -1e9*(1-b)
return w
def _attn(q, k, v, train=False, scale=False):
w = tf.matmul(q, k)
if scale:
n_state = shape_list(v)[-1]
w = w*tf.rsqrt(tf.cast(n_state, tf.float32))
w = mask_attn_weights(w)
w = tf.nn.softmax(w)
w = dropout(w, attn_pdrop, train)
a = tf.matmul(w, v)
return a
def split_states(x, n):
x_shape = shape_list(x)
m = x_shape[-1]
new_x_shape = x_shape[:-1]+[n, m//n]
return tf.reshape(x, new_x_shape)
def merge_states(x):
x_shape = shape_list(x)
new_x_shape = x_shape[:-2]+[np.prod(x_shape[-2:])]
return tf.reshape(x, new_x_shape)
def split_heads(x, n, k=False):
if k:
return tf.transpose(split_states(x, n), [0, 2, 3, 1])
else:
return tf.transpose(split_states(x, n), [0, 2, 1, 3])
def merge_heads(x):
return merge_states(tf.transpose(x, [0, 2, 1, 3]))
def conv1d(x, scope, nf, rf, w_init=tf.random_normal_initializer(stddev=0.02), b_init=tf.constant_initializer(0), pad='VALID', train=False):
with tf.variable_scope(scope):
nx = shape_list(x)[-1]
w = tf.get_variable("w", [rf, nx, nf], initializer=w_init)
b = tf.get_variable("b", [nf], initializer=b_init)
if rf == 1: #faster 1x1 conv
c = tf.reshape(tf.matmul(tf.reshape(x, [-1, nx]), tf.reshape(w, [-1, nf]))+b, shape_list(x)[:-1]+[nf])
else: #was used to train LM
c = tf.nn.conv1d(x, w, stride=1, padding=pad)+b
return c
def attn(x, scope, n_state, n_head, train=False, scale=False):
assert n_state%n_head==0
with tf.variable_scope(scope):
c = conv1d(x, 'c_attn', n_state*3, 1, train=train)
q, k, v = tf.split(c, 3, 2)
q = split_heads(q, n_head)
k = split_heads(k, n_head, k=True)
v = split_heads(v, n_head)
a = _attn(q, k, v, train=train, scale=scale)
a = merge_heads(a)
a = conv1d(a, 'c_proj', n_state, 1, train=train)
a = dropout(a, resid_pdrop, train)
return a
def mlp(x, scope, n_state, train=False):
with tf.variable_scope(scope):
nx = shape_list(x)[-1]
act = act_fns[afn]
h = act(conv1d(x, 'c_fc', n_state, 1, train=train))
h2 = conv1d(h, 'c_proj', nx, 1, train=train)
h2 = dropout(h2, resid_pdrop, train)
return h2
def block(x, scope, train=False, scale=False):
with tf.variable_scope(scope):
nx = shape_list(x)[-1]
a = attn(x, 'attn', nx, n_head, train=train, scale=scale)
n = norm(x+a, 'ln_1')
m = mlp(n, 'mlp', nx*4, train=train)
h = norm(n+m, 'ln_2')
return h
def embed(X, we):
we = convert_gradient_to_tensor(we)
e = tf.gather(we, X)
h = tf.reduce_sum(e, 2)
return h
def clf(x, ny, w_init=tf.random_normal_initializer(stddev=0.02), b_init=tf.constant_initializer(0), train=False):
with tf.variable_scope('clf'):
nx = shape_list(x)[-1]
w = tf.get_variable("w", [nx, ny], initializer=w_init)
b = tf.get_variable("b", [ny], initializer=b_init)
return tf.matmul(x, w)+b
def model(X, M, Y, train=False, reuse=False):
with tf.variable_scope('model', reuse=reuse):
we = tf.get_variable("we", [n_vocab+n_special+n_ctx, n_embd], initializer=tf.random_normal_initializer(stddev=0.02))
we = dropout(we, embd_pdrop, train)
X = tf.reshape(X, [-1, n_ctx, 2])
M = tf.reshape(M, [-1, n_ctx])
h = embed(X, we)
for layer in range(n_layer):
h = block(h, 'h%d'%layer, train=train, scale=True)
lm_h = tf.reshape(h[:, :-1], [-1, n_embd])
lm_logits = tf.matmul(lm_h, we, transpose_b=True)
lm_losses = tf.nn.sparse_softmax_cross_entropy_with_logits(logits=lm_logits, labels=tf.reshape(X[:, 1:, 0], [-1]))
lm_losses = tf.reshape(lm_losses, [shape_list(X)[0], shape_list(X)[1]-1])
lm_losses = tf.reduce_sum(lm_losses*M[:, 1:], 1)/tf.reduce_sum(M[:, 1:], 1)
clf_h = tf.reshape(h, [-1, n_embd])
pool_idx = tf.cast(tf.argmax(tf.cast(tf.equal(X[:, :, 0], clf_token), tf.float32), 1), tf.int32)
clf_h = tf.gather(clf_h, tf.range(shape_list(X)[0], dtype=tf.int32)*n_ctx+pool_idx)
clf_h = tf.reshape(clf_h, [-1, 2, n_embd])
if train and clf_pdrop > 0:
shape = shape_list(clf_h)
shape[1] = 1
clf_h = tf.nn.dropout(clf_h, 1-clf_pdrop, shape)
clf_h = tf.reshape(clf_h, [-1, n_embd])
clf_logits = clf(clf_h, 1, train=train)
clf_logits = tf.reshape(clf_logits, [-1, 2])
clf_losses = tf.nn.sparse_softmax_cross_entropy_with_logits(logits=clf_logits, labels=Y)
return clf_logits, clf_losses, lm_losses
def mgpu_train(*xs):
gpu_ops = []
gpu_grads = []
xs = (tf.split(x, n_gpu, 0) for x in xs)
for i, xs in enumerate(zip(*xs)):
do_reuse = True if i > 0 else None
with tf.device(assign_to_gpu(i, "/gpu:0")), tf.variable_scope(tf.get_variable_scope(), reuse=do_reuse):
clf_logits, clf_losses, lm_losses = model(*xs, train=True, reuse=do_reuse)
if lm_coef > 0:
train_loss = tf.reduce_mean(clf_losses) + lm_coef*tf.reduce_mean(lm_losses)
else:
train_loss = tf.reduce_mean(clf_losses)
params = find_trainable_variables("model")
grads = tf.gradients(train_loss, params)
grads = list(zip(grads, params))
gpu_grads.append(grads)
gpu_ops.append([clf_logits, clf_losses, lm_losses])
ops = [tf.concat(op, 0) for op in zip(*gpu_ops)]
grads = average_grads(gpu_grads)
grads = [g for g, p in grads]
train = opt_fns[opt](params, grads, lr, partial(lr_schedules[lr_schedule], warmup=lr_warmup), n_updates_total, l2=l2, max_grad_norm=max_grad_norm, vector_l2=vector_l2, b1=b1, b2=b2, e=e)
return [train]+ops
def mgpu_predict(*xs):
gpu_ops = []
xs = (tf.split(x, n_gpu, 0) for x in xs)
for i, xs in enumerate(zip(*xs)):
with tf.device(assign_to_gpu(i, "/gpu:0")), tf.variable_scope(tf.get_variable_scope(), reuse=True):
clf_logits, clf_losses, lm_losses = model(*xs, train=False, reuse=True)
gpu_ops.append([clf_logits, clf_losses, lm_losses])
ops = [tf.concat(op, 0) for op in zip(*gpu_ops)]
return ops
def transform_roc(X1, X2, X3):
n_batch = len(X1)
xmb = np.zeros((n_batch, 2, n_ctx, 2), dtype=np.int32)
mmb = np.zeros((n_batch, 2, n_ctx), dtype=np.float32)
start = encoder['_start_']
delimiter = encoder['_delimiter_']
for i, (x1, x2, x3), in enumerate(zip(X1, X2, X3)):
x12 = [start]+x1[:max_len]+[delimiter]+x2[:max_len]+[clf_token]
x13 = [start]+x1[:max_len]+[delimiter]+x3[:max_len]+[clf_token]
l12 = len(x12)
l13 = len(x13)
xmb[i, 0, :l12, 0] = x12
xmb[i, 1, :l13, 0] = x13
mmb[i, 0, :l12] = 1
mmb[i, 1, :l13] = 1
xmb[:, :, :, 1] = np.arange(n_vocab+n_special, n_vocab+n_special+n_ctx)
return xmb, mmb
def iter_apply(Xs, Ms, Ys):
fns = [lambda x:np.concatenate(x, 0), lambda x:float(np.sum(x))]
results = []
for xmb, mmb, ymb in iter_data(Xs, Ms, Ys, n_batch=n_batch_train, truncate=False, verbose=True):
n = len(xmb)
if n == n_batch_train:
res = sess.run([eval_mgpu_logits, eval_mgpu_clf_loss], {X_train:xmb, M_train:mmb, Y_train:ymb})
else:
res = sess.run([eval_logits, eval_clf_loss], {X:xmb, M:mmb, Y:ymb})
res = [r*n for r in res]
results.append(res)
results = zip(*results)
return [fn(res) for res, fn in zip(results, fns)]
def iter_predict(Xs, Ms):
logits = []
for xmb, mmb in iter_data(Xs, Ms, n_batch=n_batch_train, truncate=False, verbose=True):
n = len(xmb)
if n == n_batch_train:
logits.append(sess.run(eval_mgpu_logits, {X_train:xmb, M_train:mmb}))
else:
logits.append(sess.run(eval_logits, {X:xmb, M:mmb}))
logits = np.concatenate(logits, 0)
return logits
def save(path):
ps = sess.run(params)
joblib.dump(ps, make_path(path))
def log():
global best_score
tr_logits, tr_cost = iter_apply(trX[:n_valid], trM[:n_valid], trY[:n_valid])
va_logits, va_cost = iter_apply(vaX, vaM, vaY)
tr_cost = tr_cost/len(trY[:n_valid])
va_cost = va_cost/n_valid
tr_acc = accuracy_score(trY[:n_valid], np.argmax(tr_logits, 1))*100.
va_acc = accuracy_score(vaY, np.argmax(va_logits, 1))*100.
logger.log(n_epochs=n_epochs, n_updates=n_updates, tr_cost=tr_cost, va_cost=va_cost, tr_acc=tr_acc, va_acc=va_acc)
print('%d %d %.3f %.3f %.2f %.2f'%(n_epochs, n_updates, tr_cost, va_cost, tr_acc, va_acc))
if submit:
score = va_acc
if score > best_score:
best_score = score
save(os.path.join(save_dir, desc, 'best_params.jl'))
argmax = lambda x:np.argmax(x, 1)
pred_fns = {
'rocstories':argmax,
}
filenames = {
'rocstories':'ROCStories.tsv',
}
label_decoders = {
'rocstories':None,
}
def predict():
filename = filenames[dataset]
pred_fn = pred_fns[dataset]
label_decoder = label_decoders[dataset]
predictions = pred_fn(iter_predict(teX, teM))
if label_decoder is not None:
predictions = [label_decoder[prediction] for prediction in predictions]
path = os.path.join(submission_dir, filename)
os.makedirs(os.path.dirname(path), exist_ok=True)
with open(path, 'w') as f:
f.write('{}\t{}\n'.format('index', 'prediction'))
for i, prediction in enumerate(predictions):
f.write('{}\t{}\n'.format(i, prediction))
if __name__ == '__main__':
parser = argparse.ArgumentParser()
parser.add_argument('--desc', type=str)
parser.add_argument('--dataset', type=str)
parser.add_argument('--log_dir', type=str, default='log/')
parser.add_argument('--save_dir', type=str, default='save/')
parser.add_argument('--data_dir', type=str, default='data/')
parser.add_argument('--submission_dir', type=str, default='submission/')
parser.add_argument('--submit', action='store_true')
parser.add_argument('--analysis', action='store_true')
parser.add_argument('--seed', type=int, default=42)
parser.add_argument('--n_iter', type=int, default=3)
parser.add_argument('--n_batch', type=int, default=8)
parser.add_argument('--max_grad_norm', type=int, default=1)
parser.add_argument('--lr', type=float, default=6.25e-5)
parser.add_argument('--lr_warmup', type=float, default=0.002)
parser.add_argument('--n_ctx', type=int, default=512)
parser.add_argument('--n_embd', type=int, default=768)
parser.add_argument('--n_head', type=int, default=12)
parser.add_argument('--n_layer', type=int, default=12)
parser.add_argument('--embd_pdrop', type=float, default=0.1)
parser.add_argument('--attn_pdrop', type=float, default=0.1)
parser.add_argument('--resid_pdrop', type=float, default=0.1)
parser.add_argument('--clf_pdrop', type=float, default=0.1)
parser.add_argument('--l2', type=float, default=0.01)
parser.add_argument('--vector_l2', action='store_true')
parser.add_argument('--n_gpu', type=int, default=4)
parser.add_argument('--opt', type=str, default='adam')
parser.add_argument('--afn', type=str, default='gelu')
parser.add_argument('--lr_schedule', type=str, default='warmup_linear')
parser.add_argument('--encoder_path', type=str, default='model/encoder_bpe_40000.json')
parser.add_argument('--bpe_path', type=str, default='model/vocab_40000.bpe')
parser.add_argument('--n_transfer', type=int, default=12)
parser.add_argument('--lm_coef', type=float, default=0.5)
parser.add_argument('--b1', type=float, default=0.9)
parser.add_argument('--b2', type=float, default=0.999)
parser.add_argument('--e', type=float, default=1e-8)
args = parser.parse_args()
print(args)
globals().update(args.__dict__)
random.seed(seed)
np.random.seed(seed)
tf.set_random_seed(seed)
logger = ResultLogger(path=os.path.join(log_dir, '{}.jsonl'.format(desc)), **args.__dict__)
text_encoder = TextEncoder(encoder_path, bpe_path)
encoder = text_encoder.encoder
n_vocab = len(text_encoder.encoder)
(trX1, trX2, trX3, trY), (vaX1, vaX2, vaX3, vaY), (teX1, teX2, teX3) = encode_dataset(rocstories(data_dir), encoder=text_encoder)
n_y = 2
encoder['_start_'] = len(encoder)
encoder['_delimiter_'] = len(encoder)
encoder['_classify_'] = len(encoder)
clf_token = encoder['_classify_']
n_special = 3
max_len = n_ctx//2-2
n_ctx = min(max([len(x1[:max_len])+max(len(x2[:max_len]), len(x3[:max_len])) for x1, x2, x3 in zip(trX1, trX2, trX3)]+[len(x1[:max_len])+max(len(x2[:max_len]), len(x3[:max_len])) for x1, x2, x3 in zip(vaX1, vaX2, vaX3)]+[len(x1[:max_len])+max(len(x2[:max_len]), len(x3[:max_len])) for x1, x2, x3 in zip(teX1, teX2, teX3)])+3, n_ctx)
trX, trM = transform_roc(trX1, trX2, trX3)
vaX, vaM = transform_roc(vaX1, vaX2, vaX3)
if submit:
teX, teM = transform_roc(teX1, teX2, teX3)
n_train = len(trY)
n_valid = len(vaY)
n_batch_train = n_batch*n_gpu
n_updates_total = (n_train//n_batch_train)*n_iter
X_train = tf.placeholder(tf.int32, [n_batch_train, 2, n_ctx, 2])
M_train = tf.placeholder(tf.float32, [n_batch_train, 2, n_ctx])
X = tf.placeholder(tf.int32, [None, 2, n_ctx, 2])
M = tf.placeholder(tf.float32, [None, 2, n_ctx])
Y_train = tf.placeholder(tf.int32, [n_batch_train])
Y = tf.placeholder(tf.int32, [None])
train, logits, clf_losses, lm_losses = mgpu_train(X_train, M_train, Y_train)
clf_loss = tf.reduce_mean(clf_losses)
params = find_trainable_variables('model')
sess = tf.Session(config=tf.ConfigProto(allow_soft_placement=True))
sess.run(tf.global_variables_initializer())
shapes = json.load(open('model/params_shapes.json'))
offsets = np.cumsum([np.prod(shape) for shape in shapes])
init_params = [np.load('model/params_{}.npy'.format(n)) for n in range(10)]
init_params = np.split(np.concatenate(init_params, 0), offsets)[:-1]
init_params = [param.reshape(shape) for param, shape in zip(init_params, shapes)]
init_params[0] = init_params[0][:n_ctx]
init_params[0] = np.concatenate([init_params[1], (np.random.randn(n_special, n_embd)*0.02).astype(np.float32), init_params[0]], 0)
del init_params[1]
if n_transfer == -1:
n_transfer = 0
else:
n_transfer = 1+n_transfer*12
sess.run([p.assign(ip) for p, ip in zip(params[:n_transfer], init_params[:n_transfer])])
eval_mgpu_logits, eval_mgpu_clf_losses, eval_mgpu_lm_losses = mgpu_predict(X_train, M_train, Y_train)
eval_logits, eval_clf_losses, eval_lm_losses = model(X, M, Y, train=False, reuse=True)
eval_clf_loss = tf.reduce_mean(eval_clf_losses)
eval_mgpu_clf_loss = tf.reduce_mean(eval_mgpu_clf_losses)
n_updates = 0
n_epochs = 0
if dataset != 'stsb':
trYt = trY
if submit:
save(os.path.join(save_dir, desc, 'best_params.jl'))
best_score = 0
for i in range(n_iter):
for xmb, mmb, ymb in iter_data(*shuffle(trX, trM, trYt, random_state=np.random), n_batch=n_batch_train, truncate=True, verbose=True):
cost, _ = sess.run([clf_loss, train], {X_train:xmb, M_train:mmb, Y_train:ymb})
n_updates += 1
if n_updates in [1000, 2000, 4000, 8000, 16000, 32000] and n_epochs == 0:
log()
n_epochs += 1
log()
if submit:
sess.run([p.assign(ip) for p, ip in zip(params, joblib.load(os.path.join(save_dir, desc, 'best_params.jl')))])
predict()
if analysis:
rocstories_analysis(data_dir, os.path.join(submission_dir, 'ROCStories.tsv'), os.path.join(log_dir, 'rocstories.jsonl'))
Transformer 解读
transformer是一种在自然语言处理中广泛使用的神经网络结构,它通过自注意力(self-attention)机制有效的捕捉上下文信息,处理长距离依赖关系,并实现并行计算。GTP模型采用transformer结构作为基础,从而在处理文本任务时表现出优越性能。
下图就是transformer的框架,左边是一个编码器模型,右边是一个解码器模型
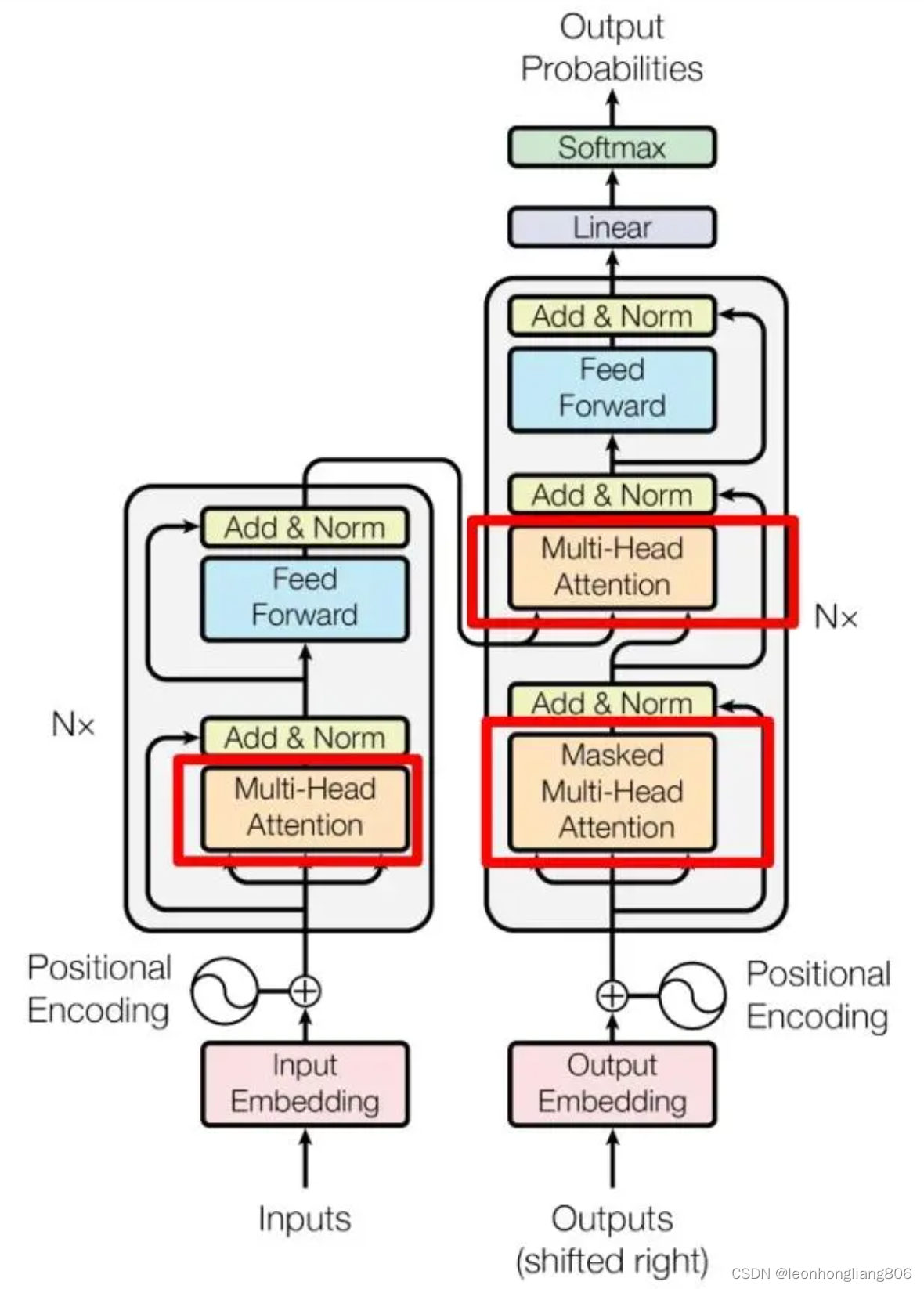
编码器接收输入,将输入拆分成一个个token,通过计算将结果给到解码器,解码器再经过复杂计算输出可能的结果token
与RNN(循环神经网络)相比,transformer更适合GPU并行
编码器和解码器的核心有两个:注意力机制和自注意力机制,它们使得模型更加聪明
注意力机制
对于计算机来说,想要表达一个东西的重要程度,最直观的方式就是用数字来表示。如果一个数越大,可以认为它越重要,Attention就是这样的。在一些任务中,我们会通过矩阵的数学运算得到某两个东西之间的值,它反映了这两个东西之间的相关程度,或者说“注意程度”,这个值就是注意力权重。再把这个注意力权重乘上对应的值就得到了某个东西关注另一个东西的程度,这就是注意力分数。计算机就是通过这个分数实现注意力机制的
自注意力机制
自注意力机制是注意力机制的变体,其减少了对外部信息的依赖,更擅长捕捉数据或特征的内部相关性
大模型应用技术架构
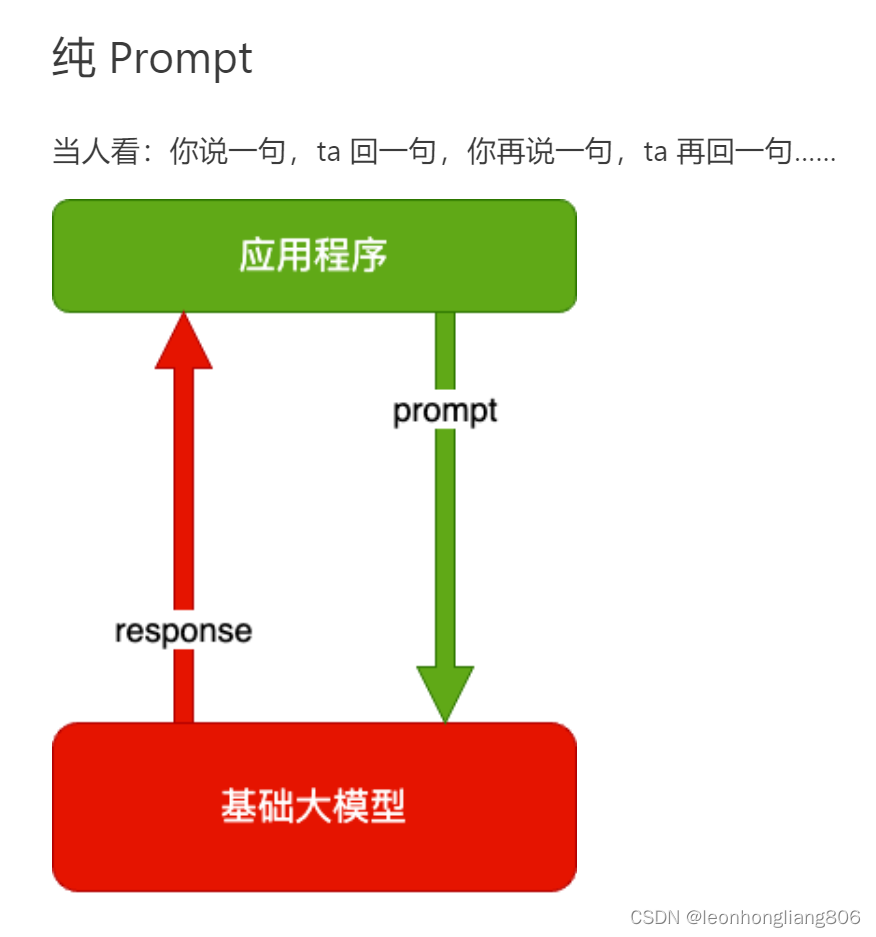
- 仅通过提示词与大模型交互得到结果
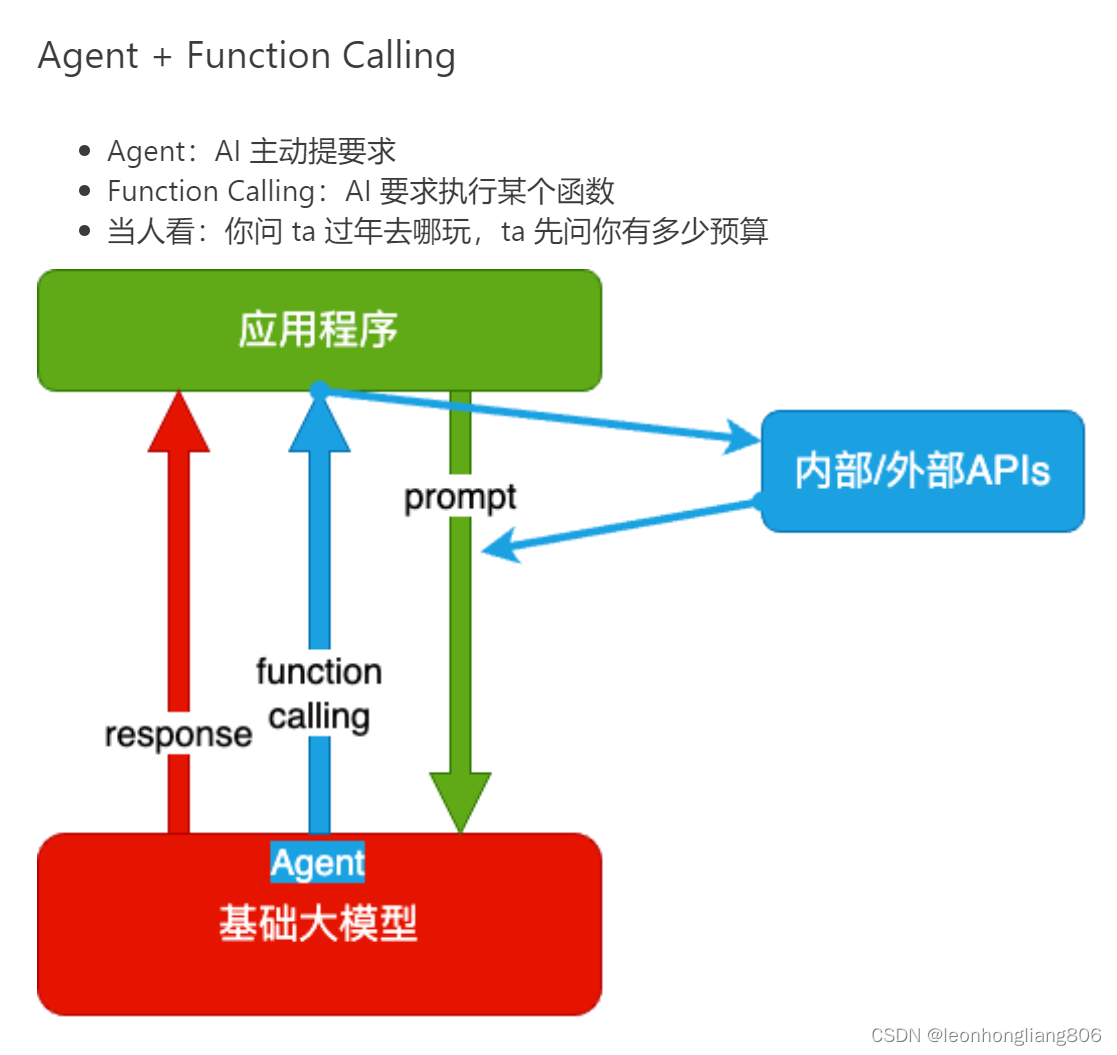
- 通过function calling在交互过程中调用内部或外部API获得额外的知识
- 对接向量数据库,存储专业或垂直领域知识,在向量数据库中找到专业的知识再结合输出
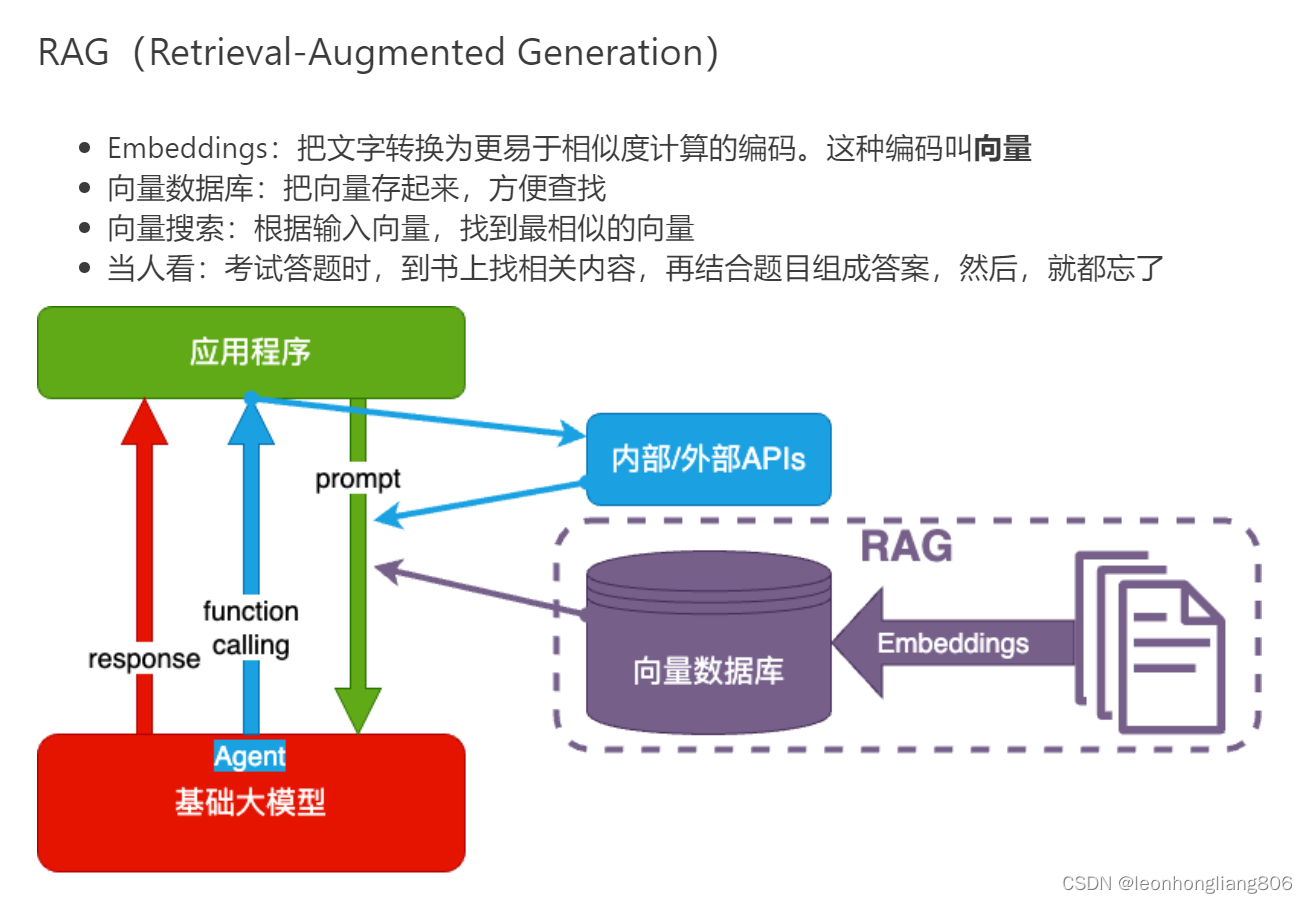
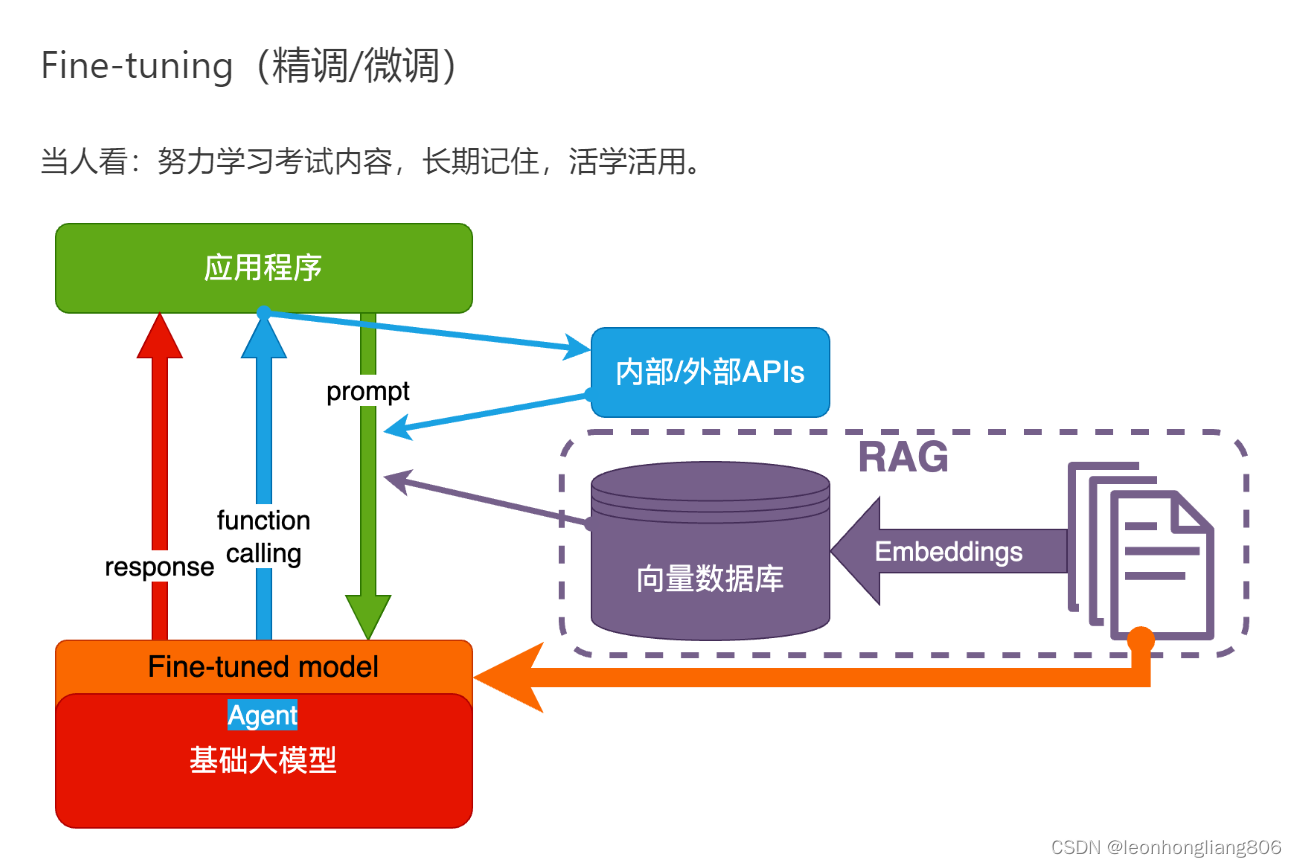
- 通过fine-tuning训练基础大模型,让大模型学习并记住专业或垂直领域知识















 3万+
3万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









